

De Elastic Stack (voorheen bekend als de ELK Stack) is een krachtige oplossing voor gecentraliseerde logging. Het is een verzameling open-source software ontwikkeld door Elastic. Hiermee kunnen beheerders logs doorzoeken, analyseren en visualiseren die vanuit elke bron in elk formaat zijn gegenereerd. Het is een praktijk die bekend staat als gecentraliseerde logging. Gecentraliseerde logging kan erg handig zijn bij het opsporen van problemen met servers en applicaties, omdat het mogelijk maakt om vanaf één plek door alle logs te zoeken. Het kan ook helpen bij het identificeren van problemen op meerdere servers door de logs op een specifiek tijdstip te correleren.
In deze handleiding leest u hoe u de Elastic Stack installeert op Ubuntu 18.04. Volg eerst onze handleiding om eenvoudig uw Ubuntu-server op CloudSigma te installeren.
De Elastic Stack op Ubuntu
De Elastic Stack bestaat uit de volgende componenten:
- Elasticsearch: Een gedistribueerde RESTful zoekmachine. Het slaat alle verzamelde gegevens op.
- Logstash: Het gegevensverwerkingsonderdeel van de Elastic Stack. Het stuurt inkomende gegevens naar Elasticsearch.
- Kibana: Een webinterface die functies biedt voor zoeken en logvisualisatie.
- Beats: Een lichtgewicht datatransmitter met één specifiek doel. Het kan gegevens van talloze machines naar Logstash of Elasticsearch sturen.
U moet elk component van de stack handmatig installeren.
Vereisten
Voordat u doorgaat met de installatie van de Elastic Stack, moet aan verschillende systeemvereisten worden voldaan:
- Hardwarevereisten:
- CPU: 2 CPU's (toegankelijk voor een niet-root sudo-gebruiker)
- RAM: 4GB
- OpenJDK 11 (de nieuwste Java LTS-release). Raadpleeg onze handleiding over het instellen van Java op Ubuntu 18.04.
- om dit te installeren. Nginx met de juiste configuraties. U kunt onze handleiding voor het installeren van Nginx op Ubuntu 18.04 volgen om dit in te stellen.
Houd er rekening mee dat de hoeveelheid opslagruimte afhangt van het aantal logs dat moet worden verzameld en opgeslagen. Daarnaast verwerkt de Elastic Stack ook waardevolle informatie over de server. Om de gegevensoverdracht veilig te houden, raden we ten zeerste aan om een TLS/SSL-certificaat te configureren. Volg deze handleiding om een gratis SSL-certificaat op uw Nginx-server te verkrijgen.
Naast een gecodeerde server zijn ook de volgende stappen vereist:
- Een FQDN (fully qualified domain name). In deze handleiding is dit <domain>.
- Beide DNS-records van de volgende domeinen verwijzen naar de server.
- Een A-record met <domain> die naar het openbare IP-adres van de server verwijst.
- Een A-record met www.<domain> die naar het openbare IP-adres van de server verwijst.
De Elastic Stack installeren
-
Elastic-repository configureren
De componenten van de Elastic Stack zijn niet rechtstreeks beschikbaar in de officiële Ubuntu-repository. Gelukkig staat Ubuntu 3e-partij repositories toe om pakketten te installeren. Voor ons doel voegen we de Elastic-pakketrepository toe. De repository biedt de nieuwste pakketupdates van alle Elastic-pakketten. Alle Elastic-pakketten zijn ondertekend met de Elasticsearch-ondertekeningssleutel om pakketspoofing te voorkomen. Voeg eerst de sleutel toe aan de Ubuntu-sleutelring:
|
1 |
curl -fsSL https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add - |
Voeg vervolgens de Elastic-bronnenlijst toe onder de map “sources.list.d”. Dit is de speciale map die APT gebruikt om naar nieuwe bronnen te zoeken:
|
1 |
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list |
Werk ten slotte de APT-cache bij:
|
1 |
sudo apt update |
Volgens de officiële documentatie wordt aanbevolen om elk van de componenten te installeren in de volgorde die in deze handleiding wordt getoond. Dit zorgt ervoor dat de componenten waarvan elk product afhankelijk is, zich op de juiste plaats bevinden.
-
Elasticsearch installeren en configureren
Zodra de Elastic-repository is geconfigureerd, is APT gereed om alle Elastic-pakketten te downloaden en te installeren. Voer de volgende opdracht uit om Elasticsearch te installeren:
|
1 |
sudo apt install elasticsearch |
Nu kunt u Elasticsearch configureren. Het bestand “elasticsearch.yml” biedt configuratieopties voor clusters, nodes, paden, netwerken, geheugen, gateway en andere. De meeste hiervan zijn vooraf geconfigureerd in het bestand. Open vervolgens het Elasticsearch-configuratiebestand met een teksteditor naar keuze:
|
1 |
sudo vim /etc/elasticsearch/elasticsearch.yml |
Elasticsearch luistert overal naar poort 9200. We raden aan om de toegang van buitenaf tot Elasticsearch te beperken om te voorkomen dat buitenstaanders de gegevens lezen of de Elasticsearch-clusters uitschakelen via de REST-API. Om de toegang tot Elasticsearch te beperken en de beveiliging te verbeteren, verwijdert u het commentaarteken voor de volgende regel en vervangt u de waarde ervan:
|
1 |
network.host: localhost |
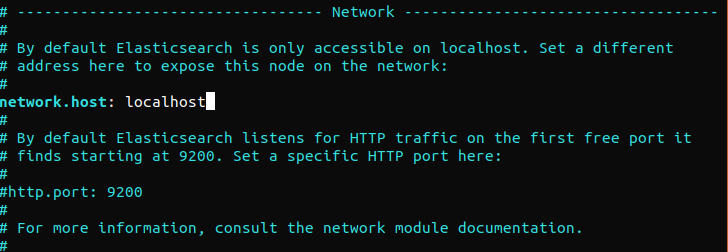
Als Elasticsearch naar een specifiek IP-adres moet luisteren, vervang dan “localhost” door het doel-IP-adres. Dit is de minimale configuratievereiste voordat u Elasticsearch uitvoert. Sla het configuratiebestand op en sluit het. Start vervolgens de Elasticsearch-service. Het kan even duren voordat Elasticsearch is opgestart:
|
1 |
sudo systemctl start elasticsearch |
Daarna moet u ervoor zorgen dat Elasticsearch telkens start wanneer de server opstart:
|
1 |
sudo systemctl enable elasticsearch |
Het volgende commando controleert of de Elasticsearch-service actief is. Het enige wat hiervoor nodig is, is het verzenden van een HTTP-verzoek:
|
1 |
curl -X GET "localhost:9200" |
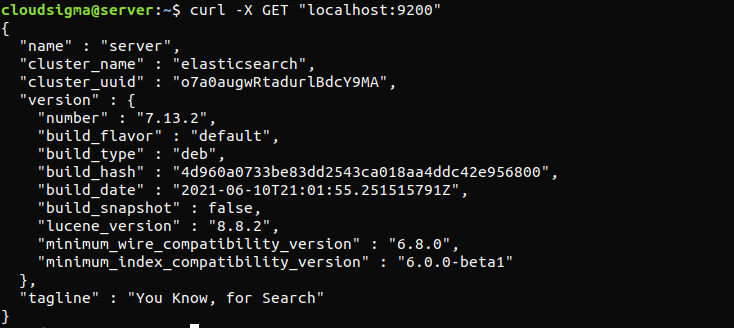
Het antwoord zal er ongeveer zo uitzien. Het is een antwoord dat basisinformatie over de lokale node toont.
Het Kibana-dashboard installeren en configureren
Kibana is rechtstreeks beschikbaar vanuit de Elastic-repository. Let op dat u Kibana pas moet installeren nadat u al Elasticsearch heeft geïnstalleerd. Ervan uitgaande dat de repository al beschikbaar is, kan APT Kibana rechtstreeks ophalen en installeren:
|
1 |
sudo apt install kibana |
Schakel na de installatie de Kibana-service in en start deze:
|
1 2 |
sudo systemctl enable kibana sudo systemctl start kibana |
Standaard is Kibana geconfigureerd om alleen naar “localhost” te luisteren. Voor externe toegang is de configuratie van een reverse proxy vereist. Hier zal Nginx de reverse proxy zijn. Gebruik het commando openssl om een admin-Kibana-gebruiker aan te maken. Dit wordt het gebruikersaccount voor toegang tot de Kibana-webinterface. In dit voorbeeld is de gebruikersnaam “kibana_admin”. Om een betere beveiliging te garanderen, raden we aan een niet-standaard gebruikersnaam te gebruiken. Het volgende commando maakt een admin-gebruiker aan voor Kibana. De gebruikersnaam en het wachtwoord worden gegenereerd en opgeslagen in het bestand “htpasswd.users”. Nginx moet worden geconfigureerd om deze gebruikersnaam en dit wachtwoord te gebruiken:
|
1 |
echo "kibana_admin:`openssl passwd -apr1`" | sudo tee -a /etc/nginx/htpasswd.users |
Voer een wachtwoord in en bevestig dit bij de prompt. Dit wachtwoord is belangrijk voor de toegang tot de Kibana-interface. Daarna moet u een Nginx-serverblokbestand aanmaken. Ter demonstratie gebruiken we example.com. Dit kan ook een andere beschrijvende naam zijn. Als er FQDN- en DNS-records voor de server zijn geconfigureerd, kan de bestandsnaam ook naar de FQDN worden vernoemd:
|
1 |
sudo vim /etc/nginx/sites-available/example.com |
Als er al inhoud in staat, verwijder deze dan en vervang deze door de volgende regels code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
server { listen 80; server_name example.com; auth_basic "Beperkte toegang"; auth_basic_user_file /etc/nginx/htpasswd.users; location / { proxy_pass http://localhost:5601; proxy_http_version 1.1; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection 'upgrade'; proxy_set_header Host $host; proxy_cache_bypass $http_upgrade; } } |
Sla het bestand op en sluit het. Maak een symbolische koppeling van de nieuwe configuratie in de map “sites-enabled”. Als er al een koppeling met dezelfde bestandsnaam bestaat, is deze stap mogelijk niet nodig:
|
1 |
sudo ln -s /etc/nginx/sites-available/example.com /etc/nginx/sites-enabled/example.com |
Het volgende commando vraagt Nginx om te controleren of er syntaxfouten zijn:
|
1 |
sudo nginx -t |
Als er een syntaxprobleem is, zorg er dan voor dat de inhoud van het bestand correct is geplaatst. Start vervolgens de Nginx-service opnieuw op:
|
1 |
sudo systemctl restart nginx |
Zeg tegen UFW om verbindingen met Nginx toe te staan:
|
1 |
sudo ufw allow 'Nginx Full' |
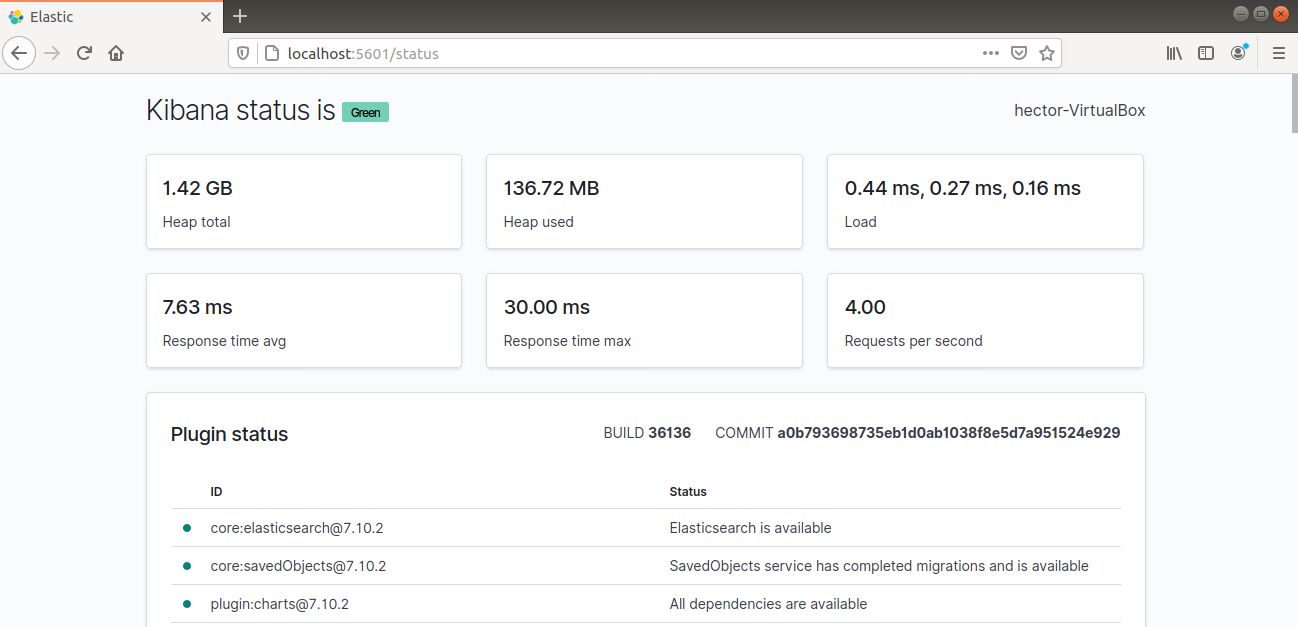
Kibana zou nu toegankelijk moeten zijn via de FQDN of het openbare IP-adres van de Elastic Stack-server. Controleer de statuspagina van de Kibana-server:
|
1 |
http://<server_ip>:5601/status |
Logstash installeren en configureren
Hoewel Beats rechtstreeks gegevens naar de database van Elasticsearch’s kan sturen, wordt het aanbevolen om Logstash te gebruiken voor het verwerken van de gegevens. Logstash kan de gegevens verzamelen en converteren naar een gemeenschappelijk formaat voordat ze naar een andere database worden geëxporteerd. Voer het volgende APT-commando uit om Logstash te installeren:
|
1 |
sudo apt install logstash |
Zodra de installatie is voltooid, is het tijd om Logstash te configureren. De configuratiebestanden van Logstash hebben de JSON-indeling. Je kunt ze allemaal vinden in de map “/etc/logstash/conf.d”. Het is handig om Logstash te zien als een pijplijn die aan de ene kant gegevens opneemt, deze verwerkt en naar de bestemming verzendt. Een Logstash-pijplijn vereist twee verplichte elementen – input en output met één optioneel element – filter. De input-plugin neemt de gegevens op, de filter plugin verwerkt de gegevens, en de output plugin schrijft de gegevens naar de bestemming. Het volgende commando maakt een configuratiebestand aan dat Logstash instelt voor Filebeat-input:
|
1 |
sudo vim /etc/logstash/conf.d/02-beats-input.conf |
Voer de volgende input-configuratie in. Deze beschrijft een beats-input die luistert op poort 5044 via TCP:
|
1 2 3 4 5 |
input { beats { port => 5044 } } |
De volgende stap is het maken van een configuratiebestand met de naam “10-syslog-filter.conf”. We zullen dit gebruiken om een filter in te stellen voor syslogs (systeemlogboeken):
|
1 |
sudo vim /etc/logstash/conf.d/10-syslog-filter.conf |
Voer de volgende syslog-configuratiecode in. Deze code is rechtstreeks beschikbaar in de Elastic-handleiding. Deze code legt de input-configuratie voor Logstash uit:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
input{ beats{ port => 5044 host => "0.0.0.0" } } filter { if [fileset][module] == "system" { if [fileset][name] == "auth" { grok { match => { "message" => ["%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: %{DATA:[system][auth][ssh][event]} %{DATA:[system][auth][ssh][method]} for (invalid user )?%{DATA:[system][auth][user]} from %{IPORHOST:[system][auth][ssh][ip]} port %{NUMBER:[system][auth][ssh][port]} ssh2(: %{GREEDYDATA:[system][auth][ssh][signature]})?", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: %{DATA:[system][auth][ssh][event]} user %{DATA:[system][auth][user]} from %{IPORHOST:[system][auth][ssh][ip]}", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: Did not receive identification string from %{IPORHOST:[system][auth][ssh][dropped_ip]}", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sudo(?:\[%{POSINT:[system][auth][pid]}\])?: \s*%{DATA:[system][auth][user]} :( %{DATA:[system][auth][sudo][error]} ;)? TTY=%{DATA:[system][auth][sudo][tty]} ; PWD=%{DATA:[system][auth][sudo][pwd]} ; USER=%{DATA:[system][auth][sudo][user]} ; COMMAND=%{GREEDYDATA:[system][auth][sudo][command]}", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} groupadd(?:\[%{POSINT:[system][auth][pid]}\])?: new group: name=%{DATA:system.auth.groupadd.name}, GID=%{NUMBER:system.auth.groupadd.gid}", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} useradd(?:\[%{POSINT:[system][auth][pid]}\])?: new user: name=%{DATA:[system][auth][user][add][name]}, UID=%{NUMBER:[system][auth][user][add][uid]}, GID=%{NUMBER:[system][auth][user][add][gid]}, home=%{DATA:[system][auth][user][add][home]}, shell=%{DATA:[system][auth][user][add][shell]}$", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} %{DATA:[system][auth][program]}(?:\[%{POSINT:[system][auth][pid]}\])?: %{GREEDYMULTILINE:[system][auth][message]}"] } pattern_definitions => { "GREEDYMULTILINE"=> "(.|\n)*" } remove_field => "message" } date { match => [ "[system][auth][timestamp]", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ] } geoip { source => "[system][auth][ssh][ip]" target => "[system][auth][ssh][geoip]" } } else if [fileset][name] == "syslog" { grok { match => { "message" => ["%{SYSLOGTIMESTAMP:[system][syslog][timestamp]} %{SYSLOGHOST:[system][syslog][hostname]} %{DATA:[system][syslog][program]}(?:\[%{POSINT:[system][syslog][pid]}\])?: %{GREEDYMULTILINE:[system][syslog][message]}"] } pattern_definitions => { "GREEDYMULTILINE" => "(.|\n)*" } remove_field => "message" } date { match => [ "[system][syslog][timestamp]", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ] } } } } |
Het volgende configuratiebestand gaat over de uitvoer. Open een nieuw bestand genaamd “30-elasticsearch-output.conf”:
|
1 |
sudo vim /etc/logstash/conf.d/30-elasticsearch-output.conf |
Voer de volgende code in. Deze code legt de uitvoerconfiguratie uit aan Logstash:
|
1 2 3 4 5 6 7 |
output { elasticsearch { hosts => ["localhost:9200"] manage_template => false index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}" } } |
Test de Logstash-configuratie. Voer vervolgens het volgende commando uit:
|
1 |
sudo -u logstash /usr/share/logstash/bin/logstash --path.settings /etc/logstash -t |
Als er geen fout is, zal Logstash het volgende succesbericht afdrukken. Als het niet succesvol was, zorg er dan voor dat alle configuratiebestanden de juiste codes bevatten. Start en activeer ten slotte de Logstash-service:
|
1 2 |
sudo systemctl start logstash sudo systemctl enable logstash |
Nu Logstash succesvol draait en volledig is geconfigureerd, gaan we Filebeat installeren.
Filebeat installeren en configureren
De Elastic Stack maakt gebruik van data shippers, bekend als “Beats”, voor het verzamelen van gegevens uit verschillende bronnen en het transporteren daarvan naar Logstash/Elasticsearch. Hier is een korte lijst van de beschikbare Beats van Elastic:
- Filebeat: Logbestanden verzamelen/verzenden.
- Metricbeat: Metrieken verzamelen/verzenden van systemen en services.
- Packetbeat: Netwerkgegevens verzamelen/analyseren.
- Winlogbeat: Windows-gebeurtenislogboeken verzamelen.
- Auditbeat: Linux audit framework-gegevens verzamelen en bestandsintegriteit bewaken.
- Heartbeat: Services bewaken op hun beschikbaarheid.
Voor deze handleiding hebben we Filebeat nodig om lokale logbestanden naar de Elastic Stack te verzenden. Installeer eerst Filebeat:
|
1 |
sudo apt install filebeat |
Je kunt nu Filebeat configureren. Eerst moet het verbinding maken met Logstash. We gebruiken de voorbeeldconfiguratie die met Filebeat wordt meegeleverd. Open het configuratiebestand in een teksteditor. Let op: omdat het bestand in YAML-indeling is, is een juiste inspringing belangrijk:
|
1 |
sudo vim /etc/filebeat/filebeat.yml |
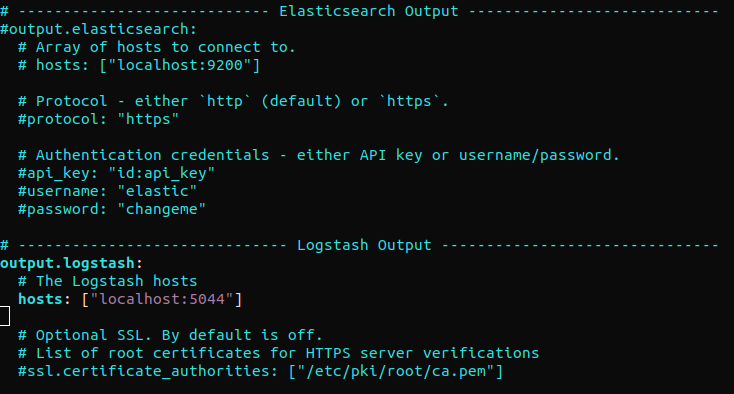
Zoek de sectie “output.elasticsearch” op en zet de volgende regels in commentaar. Dit configureert Filebeat om gebeurtenissen rechtstreeks naar Elasticsearch/Logstash te sturen voor verdere verwerking. Ga vervolgens naar de sectie “output.logstash.” Haal daarna de volgende regels uit commentaar:
|
1 2 3 4 5 6 7 |
#output.elasticsearch: # Array van hosts om mee te verbinden. # hosts: ["localhost:9200"] output.logstash: # De Logstash-hosts hosts: ["localhost:5044"] |
Filebeat ondersteunt modules die de functionaliteit ervan kunnen uitbreiden. In deze handleiding gebruiken we de systeemmodule die logs verzamelt en analyseert die zijn gegenereerd door de systeemlogboekservice van veelvoorkomende Linux-distributies. Schakel de Filebeat-systeemmodule in:
|
1 |
sudo filebeat modules enable system |
Het volgende Filebeat-commando geeft een lijst van alle ingeschakelde en uitgeschakelde modules:
|
1 |
sudo filebeat modules list |
Standaard is Filebeat ingesteld om de standaardpaden voor syslog- en autorisatielogs te volgen. De parameters van de modules zijn beschikbaar in het configuratiebestand “/etc/filebeat/modules.d/system.yml”.
De volgende stap is het laden van de index-sjabloon in Elasticsearch. Een Elasticsearch-index duidt op een verzameling documenten die vergelijkbare kenmerken delen. Elke index heeft een naam. De naam is vereist bij het uitvoeren van verschillende bewerkingen daarin. De index-sjabloon wordt automatisch toegepast telkens wanneer een nieuwe index wordt gegenereerd. Laad vervolgens de sjabloon:
|
1 |
sudo filebeat setup --template -E output.logstash.enabled=false -E 'output.elasticsearch.hosts=["localhost:9200"]' |
Filebeat bevat standaard een voorbeeld-dashboard voor Kibana. Dit helpt om Filebeat-gegevens in Kibana te visualiseren. Voordat je het dashboard gebruikt, is het echter noodzakelijk om het indexpatroon aan te maken en de dashboards in Kibana te laden. Terwijl de dashboards worden geladen, neemt Filebeat contact op met Elasticsearch voor versie-informatie. Om dashboards te laden terwijl Logstash is ingeschakeld, is het vereist dat de Logstash-output is uitgeschakeld en de Elasticsearch-output is ingeschakeld. Het volgende commando doet dit:
|
1 |
sudo filebeat setup -e -E output.logstash.enabled=false -E output.elasticsearch.hosts=['localhost:9200'] -E setup.kibana.host=localhost:5601 |
Ten slotte kun je Filebeat starten:
|
1 2 |
sudo systemctl start filebeat sudo systemctl enable filebeat |
Nu is het tijd om de Elastic Stack-configuratie te testen. Als deze correct is geconfigureerd, ziet de uitvoer er ongeveer zo uit:
|
1 |
curl -XGET 'http://localhost:9200/filebeat-*/_search?pretty' |
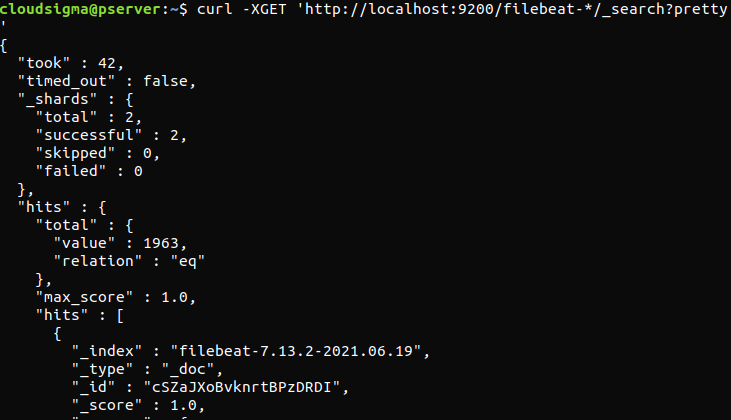
Als de uitvoer in totaal 0 resultaten (hits) meldt, laadt Elasticsearch geen logs onder de index waarnaar we hebben gezocht. Dit geeft aan dat er een fout in de configuratie zat. Als de uitvoer was zoals verwacht, is de Elastic Stack succesvol geconfigureerd.
Overzicht Kibana-dashboards
Nu is het tijd om de Kibana-webinterface te verkennen die we al hebben geïnstalleerd. Open eerst het Kibana-dashboard. Dit bevindt zich op de FQDN of het openbare IP-adres van de Elastic Stack-server:
|
1 |
http://<server_ip>:5601 |
Voer de inloggegevens in die we eerder hebben gegenereerd. Zodra je bent ingelogd, ziet het dashboard er als volgt uit:
Selecteer in de linkernavigatiebalk “Discover.” Selecteer vervolgens het patroon “filebeat-*”. Dit toont alle logs die de afgelopen 15 minuten zijn verzameld. Het is mogelijk om logs te doorzoeken en te bladeren en het dashboard aan te passen:
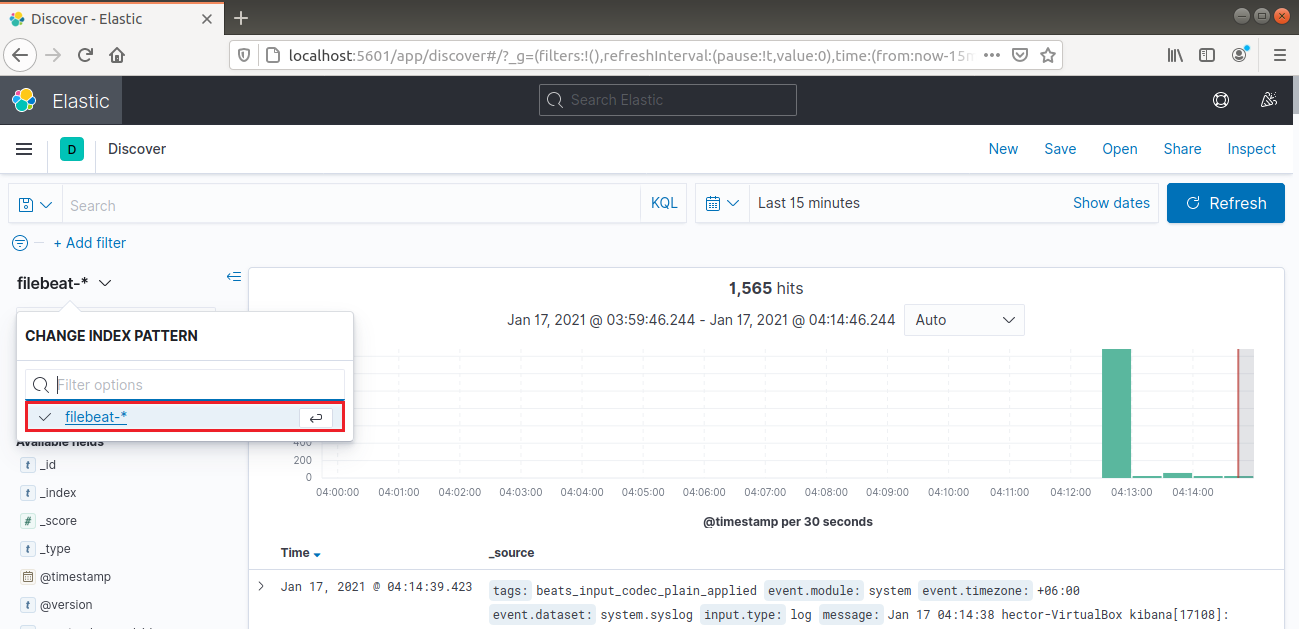
Ga in de linkernavigatiebalk naar Dashboard >> Filebeat System. Hier zijn alle voorbeelddashboards van de systeemmodule van Filebeat beschikbaar.
In het volgende voorbeeld worden verschillende statistieken gedetailleerd op basis van de syslog-berichten:
Het kan ook rapporteren welke gebruikers commando's hebben uitgevoerd met sudo:
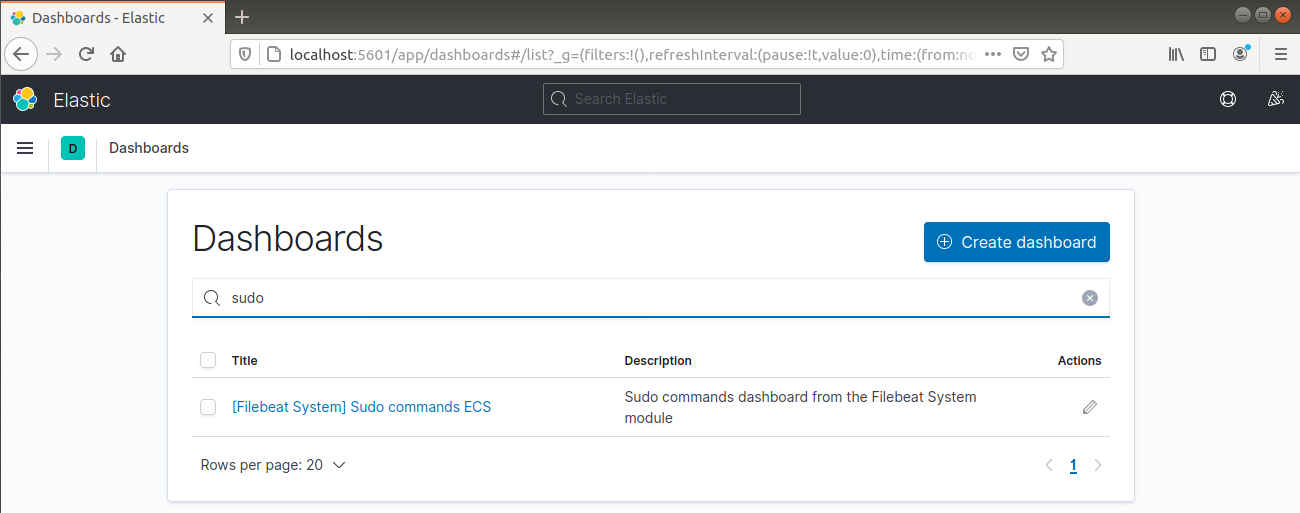
Ten slotte biedt Kibana je de mogelijkheid om vele andere functionaliteiten te verkennen, zoals grafieken maken en filteren, dus voel je vrij om dit zelf te ontdekken.
Tot slot
De Elastic Stack is een krachtige oplossing voor het analyseren van systeemlogs. Houd er rekening mee dat hoewel alle logs of geïndexeerde gegevens naar Logstash kunnen worden verzonden met behulp van Beats, het nuttiger wordt wanneer het wordt geparseerd en gestructureerd via Logstash-filters.
Veel computerplezier!
Reacties
Nog geen reacties. Wees de eerste.