

Deze handleiding helpt u bij het opzetten van een Kubernetes cluster vanaf nul met behulp van Ansible en Kubeadm en het vervolgens implementeren van een in een container geplaatste Nginx applicatie hiermee.
Inleiding
Kubernetes (ook bekend als k8s of “kube”) is een open-source container-orchestratieplatform dat veel van de handmatige processen automatiseert die komen kijken bij het implementeren, beheren en schalen van in containers geplaatste applicaties. Kubernetes heeft een snelgroeiende open-source community die actief bijdraagt aan het project. Bekijk onze blogpost die u introduceert in alles wat u moet weten over de basisprincipes van het Kubernetes-platform.
Kubeadm is een tool die verschillende geïntegreerde elementen, onderdelen en stukken configureert, zoals de API-server, Controller Manager en Kube DNS. Het helpt ook bij het automatiseren van de installatie. Het maakt echter geen gebruikers aan, regelt de installatie van afhankelijkheden op besturingssysteemniveau en hun configuratie niet, en kan uw infrastructuur niet inrichten.
Ansible is een open-source tool voor software-inrichting en applicatie-implementatie. Saltstack is open-source software voor IT-automatisering aangestuurd door gebeurtenissen. Dit zijn de twee tools die het maken van extra clusters of het opnieuw maken van bestaande clusters minder foutgevoelig maken en kunnen worden gebruikt voor deze voorbereidende taken.
Doelen:
Uw cluster zal de volgende fysieke bronnen bevatten:
1. Eén master node:
Een master node is een node die een set worker nodes (workloads runtime) bestuurt en beheert en lijkt op een cluster in Kubernetes. Het bevat ook het bronnenplan van de node om de juiste actie te bepalen voor de geactiveerde gebeurtenis. Het draait etcd, een open-source gedistribueerde sleutel-waardewinkel die wordt gebruikt om clustergegevens vast te houden en te beheren tussen componenten die workloads plannen naar worker nodes.
De scheduler zou bijvoorbeeld uitzoeken welke worker node een nieuw geplande POD zal hosten.
2. Twee worker nodes:
Worker nodes zijn de nodes die doorgaan met hun toegewezen werk, zelfs als de master node uitvalt zodra de planning is voltooid. Worker nodes zijn de servers waarop uw workloads (d.w.z. in containers geplaatste applicaties en services) zullen draaien. U kunt de capaciteit van het cluster ook vergroten door workers toe te voegen.
Zodra u deze handleiding hebt voltooid, beschikt u over een volledig functioneel cluster dat klaar is om workloads (d.w.z. in containers geplaatste applicaties en services) uit te voeren, op voorwaarde dat de servers in het cluster voldoende CPU- en RAM-bronnen hebben om uw applicaties uit te voeren. Nadat u het cluster met succes hebt opgezet, kunt u vrijwel elke traditionele UNIX-applicatie uitvoeren. Deze kan in een container op uw cluster worden geplaatst, inclusief webapplicaties, databases, daemons en opdrachtregelprogramma's.
Het cluster zelf verbruikt ongeveer 300-500 MB geheugen en 10% CPU op elke node.
Vereisten:
- U moet een SSH-sleutelpaar op uw lokale Linux-machine hebben en weten hoe u SSH-sleutels moet gebruiken. Als u echter nog niet eerder SSH-sleutels hebt gebruikt, kunt u deze handleiding bekijken om u te helpen SSH-sleutels in te stellen op uw lokale machine.
- Drie servers met Ubuntu 18.04 met elk ten minste 4 GB RAM en 4 vCPU's. U moet via SSH kunnen inloggen op elke server als de root-gebruiker met uw SSH-sleutelpaar. Volg deze handleiding om uw Ubuntu-server te installeren.
- Ansible geïnstalleerd op uw lokale machine.
- U moet ook bekend zijn met Ansible playbooks.
- U moet ook weten hoe u een container start vanaf een Docker-image. Kijk naar “Stap 5 — Werken met Docker-images in Ubuntu” in Docker installeren en gebruiken op Ubuntu 18.04 als u een opfriscursus nodig heeft.
Stap 1 — De werkruimtemap en het Ansible-inventarisbestand instellen
U moet eerst Ansible instellen op uw lokale machine. Dit helpt u bij het uitvoeren van opdrachten op uw externe server. Het vergemakkelijkt ook de handmatige implementatie-inspanning door deze te automatiseren. Hiervoor moet u een map op uw lokale machine maken die zal dienen als uw tijdelijke digitale opslagruimte (Werkruimte).
Zodra u een map hebt gemaakt, maakt u een hosts bestand om alle informatie over de IP-adressen en groep van elke server op te slaan. Het helpt u de inventarisinformatie hierin op te slaan. Zoals eerder vermeld, zijn er drie servers: één master en twee workers. De masterserver is de master met een IP-adres dat wordt weergegeven als master_ip. De andere twee servers zijn workers en hebben de IP-adressen worker_1_ip en worker_2_ip.
U moet een map maken met de naam ~/kube-cluster in de thuismap van uw lokale machine en ga naar de map met behulp van het cd-commando:
|
1 2 |
mkdir ~/kube-cluster cd ~/kube-cluster |
De ~/kube-cluster map zal nu fungeren als de tijdelijke digitale opslagruimte (werkruimte) waarin u alle lokale commando's uitvoert voor het maken van een Kubernetes-cluster met behulp van kubeadm. De map zal al uw Ansible-playbooks bevatten en worden gebruikt voor de rest van de handleiding.
Hosts-bestand maken
Maak een bestand met de naam ~/kube-cluster/hosts met behulp van nano of uw favoriete tekstverwerker:
|
1 |
nano ~/kube-cluster/hosts |
Nu moet u de volgende tekst toevoegen, die informatie bevat over de logische structuur van uw cluster:
|
1 2 3 4 5 6 7 8 9 |
[masters] master ansible_host=master_ip ansible_user=root [workers] worker1 ansible_host=worker_1_ip ansible_user=root worker2 ansible_host=worker_2_ip ansible_user=root [all:vars] ansible_python_interpreter=/usr/bin/python3 |
Zoals vermeld, helpt dat inventarisbestand u bij het opslaan van alle informatie over de IP-adressen van uw servers en de groepen waartoe elke server behoort. ~/kube-cluster/hosts zal uw inventarisbestand zijn en (masters en workers) zijn de twee Ansible-groepen die u eraan hebt toegevoegd om de logische structuur van uw cluster te specificeren.
De Master groep is de groep die specificeert dat Ansible externe commando's moet uitvoeren als de root-gebruiker. Het vermeldt ook het IP-adres van de master-node (master_ip) dat kan worden vermeld door de serveringang genaamd “master”. Evenzo heeft de Workers groep twee vermeldingen voor de worker-servers (worker_1_ip en worker_2_ip) die ook de ansible_user als root specificeren.
De laatste regel van het bestand vertelt Ansible om de Python 3-interpreters van de externe servers te gebruiken voor de beheerbewerkingen. Ten slotte moet u het bestand opslaan en sluiten nadat u de tekst hebt toegevoegd. Na het instellen van de werkruimtemap en het Ansible-inventarisbestand, gaan we verder met de volgende stap: het installeren van afhankelijkheden op besturingssysteemniveau en het maken van configuratie-instellingen.
Stap 2 — Een niet-rootgebruiker maken op alle externe servers
In deze stap leert u hoe u op alle servers een niet-rootgebruiker met sudo-privileges maakt, zodat u handmatig via SSH kunt inloggen als een niet-geprivilegieerde gebruiker.
Dit kan be nuttig zijn voor veelvuldig uitgevoerde bewerkingen voor het behoud van een cluster. Bovendien helpt deze stap u om de taak nauwkeuriger en minder foutgevoelig uit te voeren, waardoor de kans op het onbedoeld wijzigen of verwijderen van belangrijke bestanden afneemt. Als u de configuratie wilt wijzigen van bestanden die eigendom zijn van root of systeeminformatie wilt bekijken met commando's zoals top/htop en een lijst met actieve containers wilt bekijken, helpt de volgende stap u bij het uitvoeren van al deze taken.
Het playbook maken
Maak een bestand met de naam ~/kube-cluster/initial.yml in de werkruimte:
|
1 |
nano ~/kube-cluster/initial.yml |
Vervolgens moet u de volgende play toevoegen. Een play in Ansible is een verzameling uit te voeren stappen die gericht zijn op specifieke servers en groepen. Een playbook kan één of meerdere plays bevatten.
De volgende play maakt een niet-root sudo-gebruiker aan:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
- hosts: all become: yes tasks: - name: creëer de 'ubuntu' gebruiker user: name=ubuntu append=yes state=present createhome=yes shell=/bin/bash - name: sta toe 'ubuntu' om te hebben wachtwoordloze sudo lineinfile: dest: /etc/sudoers line: 'ubuntu ALL=(ALL) NOPASSWD: ALL' validate: 'visudo -cf %s' - name: stel in geautoriseerde sleutels voor de ubuntu gebruiker authorized_key: user=ubuntu key="{{item}}" with_file: - ~/.ssh/id_rsa.pub |
Hieronder volgt een overzicht van wat ons playbook doet:
- Dit playbook maakt de non-root gebruiker
ubuntu. - Omdat u
sudo-commando's moet uitvoeren zonder wachtwoordprompt, zal deze play hetsudoers-bestand configureren om deubuntu-gebruiker toe te staan dit te doen. - Het hoofddoel van de bovenstaande taak was om u in staat te stellen via SSH in te loggen op elke server als een
ubuntu-gebruiker. Dit playbook voegt de openbare sleutel van uw lokale machine (meestal~/.ssh/id_rsa.pub) toe aan de externeubuntu-gebruiker’s lijst met geautoriseerde sleutels.
Nu moet u, na het toevoegen van de tekst, het bestand opslaan en sluiten.
Het playbook uitvoeren
Daarna moeten we ons playbook uitvoeren dat de non-root gebruiker ubuntu zal aanmaken door simpelweg het volgende uit te voeren op lokale machines:
|
1 |
ansible-playbook -i hosts ~/kube-cluster/initial.yml |
De uitvoering van dit commando zal enige tijd duren, waarna u de volgende uitvoer zult zien:
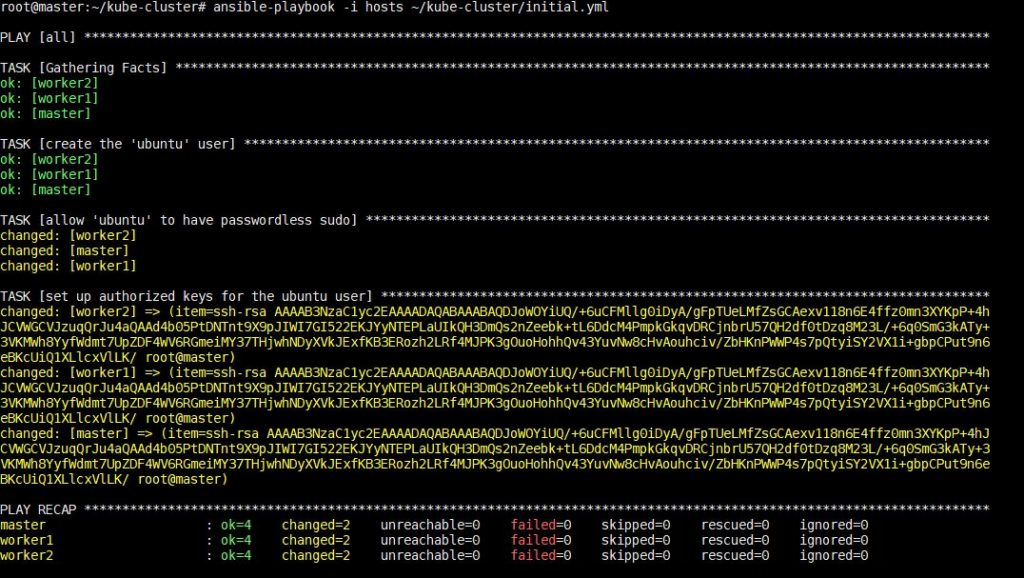
Nadat deze stap is voltooid, kunt u in de volgende stap overgaan tot het installeren van Kubernetes-specifieke afhankelijkheden.
Stap 3 — Kubernetes’-afhankelijkheden installeren
In deze stap leert u hoe u de pakketten op besturingssysteemniveau die vereist zijn voor Kubernetes installeert met de pakketbeheerder van Ubuntu.
Deze pakketten zijn:
- Docker: Docker is een platform en tool voor het bouwen, distribueren en uitvoeren van Docker-containers. U kunt Docker eenvoudig instellen door onze handleiding te volgen over hoe u Docker installeert & beheert op Ubuntu in the public cloud. De ondersteuning voor andere runtimes zoals rkt is echter in actieve ontwikkeling in Kubernetes.
Kubeadm: kubeadm is een CLI-tool die de acties uitvoert die nodig zijn om een minimaal levensvatbaar cluster operationeel te krijgen. Dat helpt u bij het op een standaard manier installeren en bouwen van verschillende componenten van het cluster.kubelet: De kubelet is de primaire “node agent” die op elke node draait en bewerkingen op node-niveau afhandelt.kubectl: kubectl is ook een CLI-tool die met uw cluster communiceert en commando's verzendt via de API-server.
Het playbook maken
Maak een bestand genaamd ~/kube-cluster/kube-dependencies.yml in de werkruimte:
|
1 |
nano ~/kube-cluster/kube-dependencies.yml |
Nu moet u de volgende plays aan het bestand toevoegen om deze volgende pakketten op uw servers te installeren:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
- hosts: all become: yes tasks: - name: installeer Docker apt: name: docker.io state: present update_cache: true - name: installeer APT Transport HTTPS apt: name: apt-transport-https state: present - name: voeg Kubernetes apt-key toe apt_key: url: https://packages.cloud.google.com/apt/doc/apt-key.gpg validate_certs: false state: present - name: voeg Kubernetes' APT-repository toe apt_repository: repo: deb http://apt.kubernetes.io/ kubernetes-xenial main state: present filename: 'kubernetes' - name: installeer kubelet apt: name: kubelet=1.16.0-00 state: present update_cache: true - name: installeer kubeadm apt: name: kubeadm=1.16.0-00 state: present - hosts: master become: yes tasks: - name: installeer kubectl apt: name: kubectl=1.16.0-00 state: present force: yes |
De eerste play in het playbook doet het volgende:
- Deze play helpt je bij het installeren van pakketten op besturingssysteemniveau, Docker – de container-runtime.
- Het installeert
apt-transport-https, waarmee je externe HTTPS-bronnen kunt toevoegen aan je APT-bronnenlijst. - Voegt de apt-key van de Kubernetes APT-repository toe voor sleutelverificatie.
- Voegt de Kubernetes APT-repository toe aan de APT-bronnenlijst van je externe servers.
- Installeert
kubeletenkubeadm.
De tweede play voert een belangrijke en op zichzelf staande taak uit, waaronder het installeren van kubectl op je master-node. Sla nu, na het toevoegen van de tekst, het bestand op en sluit het.
Het playbook uitvoeren
Daarna moeten we ons playbook uitvoeren door simpelweg het volgende uit te voeren op lokale machines:
|
1 |
ansible-playbook -i hosts ~/kube-cluster/kube-dependencies.yml |
De uitvoering van deze opdracht zal enige tijd duren, waarna je de volgende uitvoer zult zien:
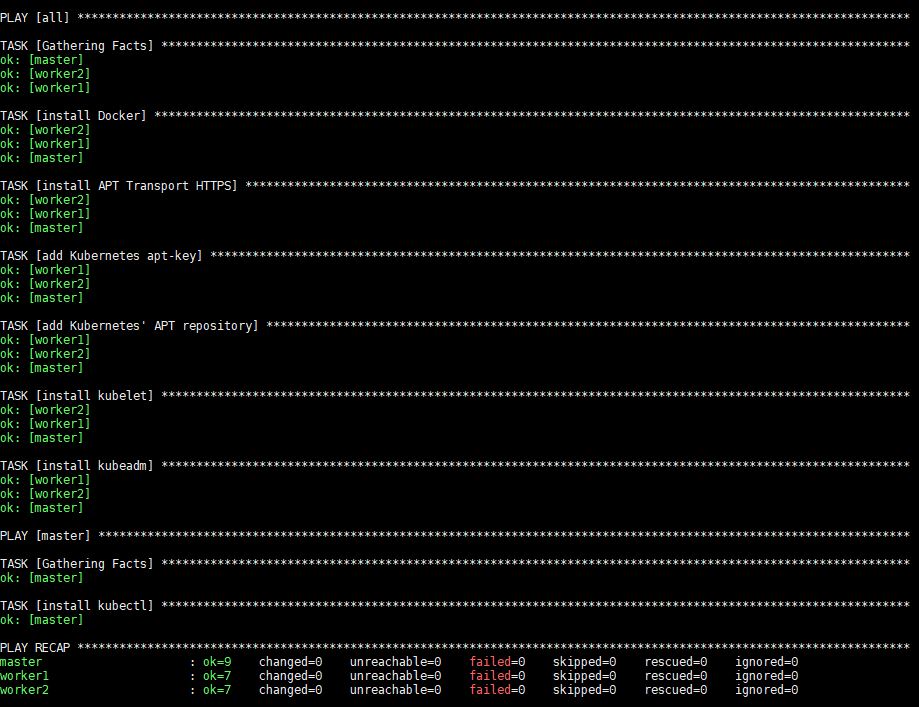
Na de uitvoering zijn Docker, kubeadm en kubelet geïnstalleerd op alle externe servers. Kubectl is geen vereist onderdeel en is alleen nodig voor het uitvoeren van clusteropdrachten. Het is in deze context logisch om dit alleen op de master-node te installeren, aangezien je kubectl opdrachten alleen vanaf de master zult uitvoeren. Let er echter wel op dat kubectl commando's kunnen worden uitgevoerd vanaf elk van de worker-nodes of vanaf elke machine waarop het kan worden geïnstalleerd en geconfigureerd om naar een cluster te verwijzen.
Alle systeemafhankelijkheden zijn nu geïnstalleerd. Laten we de master-node instellen en het cluster initialiseren.
Stap 4 — De master-node instellen
In deze stap leert u een aantal concepten kennen, zoals Pods en Pod-netwerkplug-ins aangezien uw cluster beide zal bevatten zodra u uw master-node hebt ingesteld.
Pods zijn de kleinste, meest elementaire implementeerbare objecten in Kubernetes. Pods bevatten een of meer containers, zoals Docker-containers. Wanneer een Pod meerdere containers uitvoert, worden de containers als één entiteit beheerd en delen ze de bronnen van de Pod’s.
Elke pod heeft zijn eigen IP-adres, en een pod op de ene node moet toegang kunnen krijgen tot een pod op een andere node met behulp van het IP-adres van de pod’s. De communicatie tussen pods is echter complexer. Er is een afzonderlijk component nodig dat verkeer transparant kan routeren van een pod op de ene node naar een pod op een andere. Pod-netwerkplug-ins worden voor deze functionaliteit gebruikt. Er zijn veel pod-netwerkplug-ins beschikbaar, maar we zullen een Flannel gebruiken omdat dit een stabiele en efficiënte optie is.
Het playbook maken
Maak een Ansible-playbook met de naam master.yml op uw lokale machine:
|
1 |
nano ~/kube-cluster/master.yml |
Daarnaast moet u de volgende play aan het bestand toevoegen om het cluster te initialiseren en Flannel te installeren:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
- hosts: master become: yes tasks: - name: initialiseer het cluster shell: kubeadm init --pod-network-cidr=10.244.0.0/16 >> cluster_initialized.txt args: chdir: $HOME creates: cluster_initialized.txt become: yes become_user: root - name: maak .kube map become: yes become_user: ubuntu file: path: $HOME/.kube state: directory mode: 0755 - name: kopieer admin.conf naar gebruiker's kube-config copy: src: /etc/kubernetes/admin.conf dest: /home/ubuntu/.kube/config remote_src: yes owner: ubuntu - name: installeer Pod-netwerk become: yes become_user: ubuntu shell: kubectl apply -f https:https://raw.githubusercontent.com/coreos/flannel/2140ac876ef134e0ed5af15c65e414cf26827915/Documentation/kube-flannel.yml >> pod_network_setup.txt args: chdir: $HOME creates: pod_network_setup.txt |
Hier is een overzicht van deze play:
- De eerste taak in deze play zal de cluster opzetten door het uitvoeren van
kubeadm init. Om het private subnet te specificeren waaraan de pod-IP's worden toegewezen, geven we het argument door--pod-network-cidr=10.244.0.0/16. Flannel gebruikt standaard het bovenstaande subnet. We gebruiken dit omkubeadmte vertellen dat het hetzelfde subnet moet gebruiken. - De tweede taak wordt gebruikt voor het maken van een
.kubedirectory op/home/ubuntuConfiguratie-informatie zoals de admin-sleutelbestanden, die vereist zijn om verbinding te maken met de cluster en het API-adres van de cluster, zal in deze directory worden opgeslagen. - De derde taak wordt gebruikt voor het kopiëren van het
/etc/kubernetes/admin.confbestand dat is gegenereerd doorkubeadm initnaar de thuismap van je niet-rootgebruiker. Hiermee kun jekubectlgebruiken om toegang te krijgen tot de nieuw gemaakte cluster. - De laatste taak voert
kubectl applyuit omFlannel.kubectl apply -f descriptor.[yml|json]is de syntaxis omkubectlte vertellen dat het de objecten moet maken die zijn beschreven in hetdescriptor.[yml|json]bestand. Hetkube-flannel.ymlbestand bevat de beschrijvingen van objecten die vereist zijn voor het configureren vanFlannelin the cluster.
Nu moet je, na het toevoegen van de tekst, het bestand opslaan en sluiten.
De Playbook uitvoeren
Daarna moet je onze playbook uitvoeren door simpelweg het volgende uit te voeren op lokale machines:
|
1 |
ansible-playbook -i hosts ~/kube-cluster/master.yml |
Het uitvoeren van deze opdracht zal enige tijd duren, waarna je de volgende uitvoer zult zien:
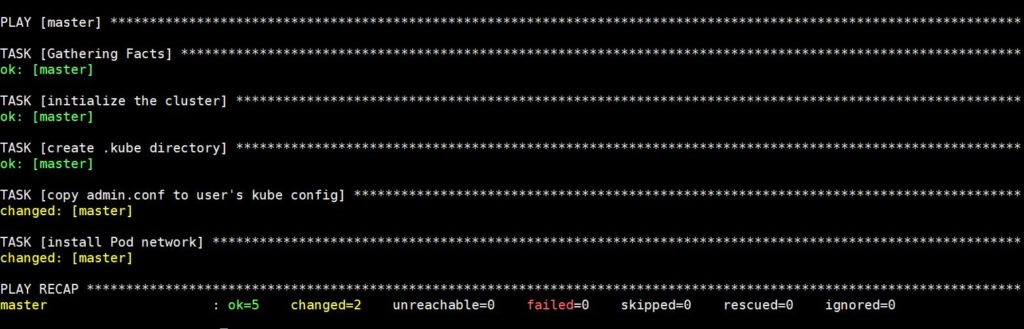
Maak nu verbinding via SSH met de volgende opdracht om de status van de master-node te controleren:
|
1 |
ssh ubuntu@master_ip |
Eenmaal in de master-node, voer je het volgende uit:
|
1 |
kubectl get nodes |
Je ziet nu de volgende uitvoer:

Bij het ontvangen van de bovenstaande uitvoer kun je vaststellen dat alle configuratietaken zijn voltooid door de master-node en dat deze worker-nodes kan gaan accepteren en taken kan gaan uitvoeren zodra deze de status Ready (Gereed) bereikt. Je kunt nu de workers toevoegen vanaf je lokale machine.
Stap 5 — De Worker-nodes configureren
Na het instellen van de master-node kunnen we nu overgaan naar onze volgende stap: het configureren van de worker-nodes. Het toevoegen van worker-nodes aan de cluster kan eenvoudig worden gedaan door een enkele opdracht uit te voeren op elke worker-server. De belangrijke informatie zoals het IP-adres, de poort van de API-server van de master en een beveiligingstoken zijn in deze opdracht opgenomen. Houd er echter rekening mee dat niet alle nodes lid kunnen worden van de cluster; alleen de nodes die het beveiligingstoken doorgeven, kunnen lid worden van de cluster.
De playbook maken
Deze opdracht helpt je terug te navigeren naar je werkruimte en een playbook te maken met de naam workers.yml:
|
1 |
nano ~/kube-cluster/workers.yml |
Voeg de volgende tekst toe aan het bestand om de workers aan de cluster toe te voegen:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
- hosts: master become: yes gather_facts: false tasks: - name: get join command shell: kubeadm token create --print-join-command register: join_command_raw - name: set join command set_fact: join_command: "{{ join_command_raw.stdout_lines[0] }}" - hosts: workers become: yes tasks: - name: join cluster shell: "{{ hostvars['master'].join_command }} >> node_joined.txt" args: chdir: $HOME creates: node_joined.txt |
Dit is wat het playbook doet. Er zijn twee plays in de bovenstaande code:
- De eerste play wordt gebruikt om het join-commando op te halen dat op de worker-nodes moet worden uitgevoerd. Het formaat van het commando is:
kubeadm join --token sha256:<hash><token><master-ip>:<master-port> --discovery-token-ca-cert-hash sha256:<hash>;. De taak moet de juiste token- en hash-waarden ophalen. Zodra deze de juiste invoer heeft, stelt de taak dit in als een 'fact' zodat de tweede play toegang heeft tot die informatie. - De tweede play is alleen geschreven om een enkele taak uit te voeren – om de twee worker-nodes deel te laten uitmaken van het cluster door simpelweg het join-commando uit te voeren op alle worker-nodes.
Na het toevoegen van de tekst moet u het bestand opslaan en sluiten.
Het playbook uitvoeren
Daarna moeten we ons playbook uitvoeren door het volgende commando uit te voeren op de worker-machines:
|
1 |
ansible-playbook -i hosts ~/kube-cluster/workers.yml |
De uitvoering van dit commando zal enige tijd duren, waarna u de volgende uitvoer zult zien:
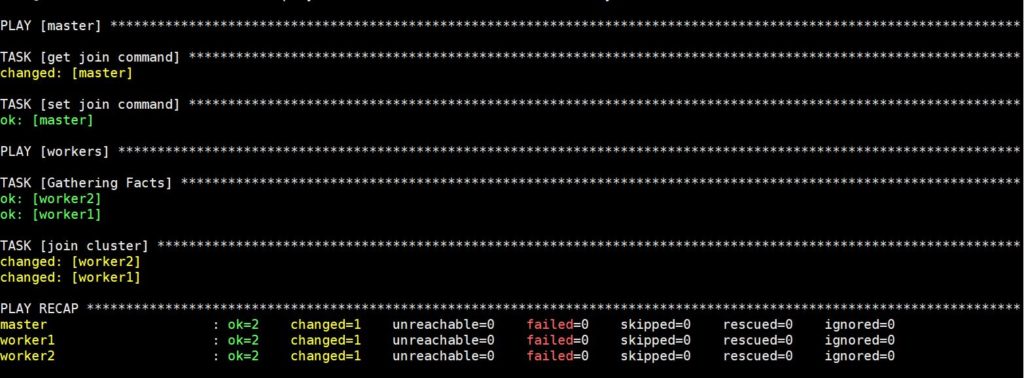
Nu is uw Kubernetes-cluster volledig ingericht en functioneel, en zijn de workers klaar om workloads uit te voeren. Voordat we naar de volgende stap gaan, controleren we of het cluster naar behoren werkt.
Stap 6 — Het cluster verifiëren
Er kunnen situaties zijn waarin een cluster mislukt tijdens de installatie. Dit kan te wijten zijn aan een netwerkfout tussen de master en de worker, of een probleem met een node. We moeten het cluster dus verifiëren voordat we applicaties inplannen en ervoor zorgen dat er geen storingen optreden. Hiervoor moet u de huidige status van het cluster controleren vanaf de master-node om er zeker van te zijn dat de nodes gereed zijn. U kunt de verbinding herstellen met het volgende commando als de nodes niet gereed zijn of als de verbinding is verbroken:
|
1 |
ssh ubuntu@master_ip |
Gebruik de volgende commando's om de status van het cluster op te vragen:
|
1 |
kubectl get nodes |
De uitvoering van dit commando zal enige tijd duren, waarna u de volgende uitvoer zult zien:

U moet controleren of alle nodes die deel uitmaken van het cluster zich in de status 'ready' bevinden. Als een paar nodes Not Ready hebben als STATUS, geeft dit aan dat de worker-nodes hun installatie nog niet hebben voltooid. Voordat u echter opnieuw kubectl get nodes uitvoert en de bijgewerkte uitvoer controleert, moet u nog vijf tot tien minuten wachten. Als sommige nodes nog steeds Not Ready als hun status tonen, moet u de vorige stappen controleren en de commando's opnieuw uitvoeren. Alleen als de nodes de waarde Ready hebben voor STATUS, maken ze deel uit van het cluster en zijn ze klaar om workloads uit te voeren. Na het succesvol uitvoeren van de 6e stap is uw cluster nu geverifieerd. Laten we nu een voorbeeld van een Nginx-applicatie inplannen op het cluster.
Stap 7 — Een applicatie uitvoeren op het cluster
Deployment maken
Na het succesvol aanmaken van het cluster kunt u elke gecontaineriseerde applicatie op uw cluster implementeren. U kunt de onderstaande commando's gebruiken voor andere gecontaineriseerde applicaties als u zich op de master-node bevindt. Voer vervolgens het volgende commando uit om een deployment te maken met de naam nginx :
|
1 |
kubectl create deployment nginx --image=nginx |
U moet de naam van de Docker-image en eventuele relevante vlaggen (zoals poorten en volumes) wijzigen. Om het herkenbaar te houden, kunt u Nginx implementeren met behulp van deployments en services om te zien hoe applicaties op het cluster kunnen worden geïmplementeerd.
Een Kubernetes-deployment is een resource-object in Kubernetes dat declaratieve updates voor applicaties biedt. Een deployment stelt u in staat om de levenscyclus van een applicatie te beschrijven, zoals container-image, replica's en de updatestrategie. Een deployment zorgt ervoor dat het gewenste aantal pods te allen tijde actief en beschikbaar is. Als een pod crasht tijdens de levensduur van het cluster, wordt deze opnieuw opgestart. Het updateproces wordt ook volledig vastgelegd en is voorzien van versies met opties om te pauzeren, door te gaan en terug te draaien naar eerdere versies. De bovenstaande opdracht om een deployment met de naam Nginx te maken, helpt u bij het implementeren van een pod met één container uit de Nginx Docker Image van het Docker-register.
NodePort instellen
Vervolgens moeten we een NodePort. NodePort is een open poort op elk knooppunt van uw cluster. Kubernetes stuurt inkomend verkeer op de NodePort transparant door naar uw service, zelfs als uw applicatie op een ander knooppunt draait. Hiervoor kunnen we deze opdracht gebruiken om een NodePort-resource genaamd Nginx te maken die de app openbaar beschikbaar maakt:
|
1 |
kubectl expose deploy nginx --port 80 --target-port 80 --type NodePort |
Een service is een ander Kubernetes-object dat verantwoordelijk is voor het blootstellen van een interface aan die pods, wat netwerktoegang mogelijk maakt van binnen het cluster of tussen externe processen en de service. Het kan worden gedefinieerd als een abstractie bovenop de pod die een enkel IP-adres en DNS-naam biedt waarmee pods toegankelijk zijn. Met een service is het heel eenvoudig om de load balancing-configuratie te beheren.
Voer de volgende opdracht uit:
|
1 |
kubectl get services |
Dit zal tekst uitvoeren die vergelijkbaar is met de volgende:

Na het verkrijgen van de uitvoer zal Kubernetes automatisch een willekeurige poort toewijzen die groter is dan 30000 , terwijl er ook voor wordt gezorgd dat de toegewezen poort niet al door een andere service is bezet. De derde regel van de bovenstaande uitvoer helpt u de poort te achterhalen waarop Nginx draait.
Om te controleren of het werkt, bezoekt u http://worker_1_ip:nginx_port of http://worker_2_ip:nginx_port via een browser op uw lokale machine. U ziet de bekende welkomstpagina van Nginx.
Deployment verwijderen
Als u de Nginx-applicatie wilt verwijderen, moet u eerst de nginx service van de master-node verwijderen:
|
1 |
kubectl delete service nginx |
Om te controleren of de applicatie definitief is verwijderd, moet u deze opdracht uitvoeren:
|
1 |
kubectl get services |
U krijgt de volgende uitvoer:

Daarna moet u de deployment verwijderen met de volgende opdracht:
|
1 |
kubectl delete deployment nginx |
U kunt deze opdracht gebruiken om te controleren of de deployment definitief is verwijderd:
|
1 |
kubectl get deployments |
![]()
Conclusie:
Deze handleiding helpt u om op de juiste manier een cluster op te zetten op Ubuntu 18.04 met behulp van Kubeadm and Ansible. Nu uw cluster is opgezet, kunt u eenvoudig beginnen met het implementeren van uw eigen applicaties en services.
Hier is een lijst met links met aanvullende details die u door het proces zullen leiden:
- Applicaties dockeriseren – Deze link bevat voorbeelden die u laten zien hoe u applicaties laadt met behulp van Docker. Zoals het dockeriseren van PostgreSQL, een CouchDB-service, enz.
- Pod-overzicht – Deze link toont details over het gebruik van een pod, de werking van pods en hoe pods zich verhouden tot andere Kubernetes-objecten. Pods zijn een belangrijk onderdeel van Kubernetes, dus als u ze begrijpt, helpt dat u om te slagen in uw taak.
- Deployments-overzicht – Dit helpt u meer te leren over deployments. Een deployment biedt declaratieve updates voor Pods en ReplicaSets. U leert hoe u een deployment kunt bijwerken, overdragen en terugdraaien.
- Services-overzicht - Deze link leidt u door services, een ander veelgebruikt object in Kubernetes-clusters. Een service in Kubernetes is een abstractie die een logische set Pods definieert en een beleid waarmee u ze kunt openen. Het begrijpen van de typen services en de opties die ze hebben, is essentieel voor het draaien van zowel stateless als stateful applicaties.
Neem bovendien een kijkje bij onze andere tutorials over Docker en Kubernetes die je kunt vinden op onze blog:
- Kennismaken met Kubernetes
- Docker-resources opschonen – Images, containers en volumes
- Hoe Docker te draaien op CloudSigma (met CloudInit) Geüpdatet
- Docker installeren en instellen op CentOS 7
- Hoe je Docker installeert & beheert op Ubuntu in de publieke cloud
Er zijn ook veel andere belangrijke concepten zoals Volumes, Ingresses, en Secrets die je kunt gebruiken bij het implementeren van productie-applicaties.
Veel computerplezier!
Reacties
Nog geen reacties. Wees de eerste.