

Web scraping, web crawling, web harvesting of webdata-extractie zijn synoniemen die verwijzen naar het minen van gegevens van webpagina's op het internet. Webscrapers of webcrawlers zijn tools die programmatisch webpagina's doorlopen en de vereiste gegevens extraheren. Deze gegevens, die meestal bestaan uit grote hoeveelheden tekst, kunnen worden gebruikt voor analytische doeleinden, om producten te begrijpen of om iemands nieuwsgierigheid naar een bepaalde webpagina te bevredigen.
Als u zich afvraagt hoe u te werk kunt gaan bij web crawling, laten we u de basisprincipes van web scraping zien aan de hand van een eenvoudige dataset. U zou de tutorial moeten kunnen volgen, ongeacht uw niveau van programmeerervaring. Voor het praktische voorbeeld gebruiken we onze CloudSigma-blog. We zullen proberen informatie te verzamelen over de tutorials op onze blogpagina. Tegen de tijd dat u de conclusie van deze tutorial leest, beschikt u over een werkende webscraper gemaakt met Python 3 die verschillende pagina's op onze blogsectie crawlt en vervolgens de gegevens op uw scherm weergeeft.
Met de kennis van het maken van deze basis-webscraper kunt u hierop voortbouwen en uw eigen webscrapers maken. Dit wordt leuk, laten we beginnen!
Vereisten
Dit is een praktische tutorial, dus u moet een lokale ontwikkelomgeving voor Python 3 hebben om deze goed te kunnen volgen. Eerst kunt u onze tutorial raadplegen over hoe u Python 3 installeert en een lokale programmeeromgeving instelt op Ubuntu.
Scrapy
Web scraping omvat twee stappen: de eerste stap is het vinden en downloaden van webpagina's, de tweede stap is het doorlopen van en het extraheren van informatie uit die webpagina's.
Er zijn verschillende manieren en bibliotheken die kunnen worden gebruikt om vanaf nul een webscraper te bouwen in veel programmeertalen. Dit kan echter in de toekomst problemen opleveren wanneer uw webscraper complex wordt, of wanneer u meerdere pagina's met verschillende instellingen en patronen tegelijk moet crawlen. Het kan een behoorlijk zware taak zijn om uit te zoeken hoe u uw gescrapete gegevens kunt transformeren tussen verschillende formaten zoals CSV, XML of JSON.
Hoewel sommigen de uitdaging van het vanaf nul bouwen van hun eigen webscraper kunnen waarderen, is het beter om het wiel niet opnieuw uit te vinden en deze in plaats daarvan te bouwen op een bestaande bibliotheek die al deze problemen oplost. We zullen gebruikmaken van Scrapy, een Python-bibliotheek, samen met Python 3 om de webscraper in deze tutorial te implementeren. Scrapy is een open-source tool en een van de meest populaire en krachtige Python-bibliotheken voor web scraping. Scrapy is gebouwd om enkele van de algemene functionaliteiten af te handelen die alle scrapers zouden moeten hebben. Op deze manier hoeft u het wiel niet opnieuw uit te vinden wanneer u een webcrawler wilt implementeren. Met Scrapy wordt het proces van het bouwen van een scraper eenvoudig en leuk.
Scrapy is beschikbaar via PyPi, algemeen bekend als pip – de Python Package Index. PyPi is een repository in het bezit van de community die de meeste Python-pakketten host. Wanneer u Python 3 installeert en instelt op uw lokale ontwikkelomgeving, wordt pip ook geïnstalleerd, dat u kunt gebruiken om Python-pakketten te installeren.
Stap 1: Hoe u een eenvoudige webscraper bouwt
Voer eerst de volgende opdracht uit om Scrapy te installeren:
|
1 |
pip install scrapy |
Optioneel kunt u de officiële installatie-instructies van Scrapy volgen vanaf de documentatiepagina. Als u Scrapy met succes hebt geïnstalleerd, maakt u een map voor het project met een naam naar keuze:
|
1 |
mkdir cloudsigma-crawler |
Navigeer naar de map en maak het hoofdbestand voor de code aan. Dit bestand zal alle code voor deze tutorial bevatten:
|
1 |
touch main.py |
Als u wilt, kunt u het bestand maken met uw teksteditor of IDE in plaats van de bovenstaande opdracht.
Open vervolgens het bestand en laten we beginnen met het maken van een basis-scraper die Scrapy gebruikt. We maken een Python-klasse die scrapy.Spider uitbreidt, een basis-spiderklasse van Scrapy. Deze klasse heeft twee vereiste attributen zoals hieronder gedefinieerd:
- name — een stringnaam om de spider te identificeren (u kunt een naam naar keuze invoeren).
- start_urls — een array met een lijst met URL's om vanaf te crawlen. We beginnen met één URL.
Voeg het volgende codefragment toe aan het geopende bestand om de basisspider te maken:
|
1 2 3 4 5 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] |
Hieronder vindt u een uitleg van elke regel code:
De eerste regel importeert Scrapy, waardoor we de verschillende klassen kunnen gebruiken die het pakket biedt.
In de volgende regel breiden we de Spider-klasse uit die door Scrapy wordt geleverd en maken we een subklasse genaamd CloudSigmaCrawler. Door een klasse (Spider) uit te breiden, krijgen we toegang tot de eigenschappen van de klasse die we nu in onze code kunnen gebruiken. In dit geval heeft de Spider-klasse methoden en gedragingen die bepalen hoe URL's moeten worden gevolgd en hoe gegevens van webpagina's moeten worden geëxtraheerd. De klasse weet echter niet welke URL's moeten worden gevolgd of welke gegevens moeten worden geëxtraheerd. Door deze uit te breiden, kunnen we de vereiste informatie aan de methoden verstrekken. Lees verder voor meer informatie over subclassing en uitbreiding Objectgeoriënteerde programmeerprincipes.
In onze CloudSigmaCrawler definiëren we de vereiste attributen. Eerst geven we onze spider de naam cloudsigma_crawler. Vervolgens geven we een enkele URL op om mee te starten: https://blog.cloudsigma.com/blog/. Als u deze URL opent, komt u op pagina 1 van de CloudSigma-blog met een aantal van de vele handleidingen.
Tijd om de scraper te testen. U heeft een paar opties. Als u bijvoorbeeld een IDE gebruikt, zoals de PyCharm community edition van JetBrains, heeft deze waarschijnlijk een knop waarop u kunt klikken om het script uit te voeren. Een andere optie is de typische manier te volgen om Python-bestanden vanaf de opdrachtregel uit te voeren: python pad/naar/bestand.py, of py pad/naar/bestand.py. Een andere optie is Scrapy's command-line interface. Scrapy wordt geleverd met een eigen command-line interface om te helpen bij het starten van een scraper. Voer de volgende opdracht in om de scraper te starten:
|
1 |
scrapy runspider main.py |
Afhankelijk van de bibliotheekversie van Scrapy die u hebt geïnstalleerd, zou u een uitvoer moeten zien die lijkt op het volgende:
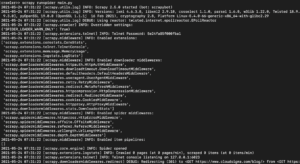
Zoals u kunt zien, is de uitvoer vrij lang, dus we hebben er slechts enkele delen uitgekozen. Dit is wat er gebeurde toen u de opdracht uitvoerde:
- De scraper is geïnitialiseerd. Daarom heeft deze extra componenten en extensies geladen die nodig zijn voor het volgen en lezen van gegevens van URL's.
- Door de URL te gebruiken die in de start_urls-lijst is opgegeven, heeft de scraper de HTML van de pagina opgehaald. Dit is een vergelijkbaar proces als dat de browser volgt bij het openen van webpagina's.
- Na het ophalen van de HTML wordt deze doorgegeven aan de parse-methode die we nog niet hebben gedefinieerd. Voorlopig doet deze niets, dus de spider sluit gewoon af zonder enige verwerking uit te voeren. In de volgende stap zullen we het gedrag van de parse-methode definiëren.
Stap 2: Gegevens extraheren uit een pagina
In stap 1 hebben we alleen een basis-scraper geïmplementeerd die een HTML-pagina ophaalt, maar daarna niets doet. In dit gedeelte geven we instructies voor het extraheren van gegevens. Op de CloudSigma Blog-pagina waarvan we gegevens willen extraheren, zijn er enkele dingen die u kunt opmerken, zoals:
- De header, aanwezig op alle pagina's.
- Het navigatiemenu en het zoekfiltervak.
- De daadwerkelijke lijst met handleidingen in een grid-indeling.
Het bekijken van de broncode van de HTML-pagina die u wilt scrapen, geeft u een algemeen idee van de structuur van de pagina. Dit helpt u bij het schrijven van een scraper. U kunt de broncode bekijken door met de rechtermuisknop op de pagina te klikken en Broncode weergeven te selecteren, of door op Ctrl + U te drukken. Hier is een fragment van de broncode:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
<body> <div id="x-iso-container" class="x-iso-container x-iso-container-posts cols-3"> <article id="post-51691" class="post-51691 post type-post status-publish format-standard has-post-thumbnail hentry category-blog-posts category-tutorials tag-apache tag-certbot tag-cloud-guide tag-cloud-tutorial tag-https tag-lets-encrypt tag-ssl tag-ssl-certification tag-tutorial tag-ubuntu"> <div class="entry-wrap"> <header class="entry-header"> <h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Permalink naar: "Apache beveiligen met Let’s Encrypt op Ubuntu 18.04"">Beveiligen van Apache met Let’s Encrypt op Ubuntu 18.04</a> </h2> </header> <div class="entry-content excerpt"> <p>Website- en gegevensbeveiliging zijn onderwerpen die niet lichtvaardig kunnen worden opgevat. Zeer gevoelige informatie, die onder meer financiële gegevens en privégegevens van klanten omvat, is altijd onderweg tussen de computer van de gebruiker en uw website. Als u dit feit in overweging neemt, is het niet moeilijk in te zien waarom onbeveiligde websites kunnen leiden tot een inbreuk die uw bedrijf ernstige schade kan toebrengen. Er zijn een … </p> <div><a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="more-link">Lees meer</a></div> </div> </div> ... </article> </div> </body> |
Zoals u kunt zien, is elke bloghandleiding ingesloten in een HTML-tag genaamd <article>. Het scrapen van de pagina omvat twee stappen. De eerste stap is het ophalen van elke bloghandleiding door te kijken naar de delen van de pagina die de gegevens bevatten die we willen hebben. De volgende stap is het extraheren van de gewenste gegevens uit elke handleiding die door de HTML-tag wordt geïdentificeerd.
Scrapy identificeert de op te halen gegevens op basis van de selectors die u opgeeft. We kunnen selectors gebruiken om een of meer elementen op een pagina te vinden en de gegevens binnen die elementen op te halen. Scrapy biedt ondersteuning voor XPath en CSS selectors.
Gezien de broncode die we eerder hebben bekeken, lijken CSS-selectors eenvoudiger te zijn. Dit is dan ook de optie die we zullen kiezen, omdat het ons helpt alle handleidingen op de pagina te vinden. In de HTML-broncode is elke handleiding gespecificeerd binnen de CSS-klasse genaamd post. CSS-klassenamen worden meestal geïdentificeerd met .klasse_naam (punt klasse_naam). Daarom zullen we .post gebruiken voor onze CSS-selector. In de broncode van onze main.py scraper geven we de .post-klasse door aan het response-object, zodat uw bestand er nu als volgt uitziet:
|
1 2 3 4 5 6 7 8 9 10 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): pass |
Dit codefragment haalt alle tutorials op de pagina met de opgegeven start_urls op en doorloopt de tutorials om gegevens te extraheren. In de volgende stap wil je deze gegevens extraheren en weergeven. Als je de broncode van de CloudSigma-blog nogmaals bekijkt, zul je zien dat de titel van elke tutorial is opgeslagen in een <a>-tag die zich in een <h2>-tag bevindt, bijvoorbeeld:
|
1 2 3 4 5 |
<h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Permalink naar: "Securing Apache with Let’s Encrypt on Ubuntu 18.04"">Securing Apache with Let’s Encrypt on Ubuntu 18.04</a> </h2> |
Elk tutorial-object waar we doorheen lopen bevat een CSS-methode waaraan we een selector kunnen doorgeven om onderliggende elementen te lokaliseren en te extraheren. Voor dit voorbeeld willen we de titel extraheren die is ingesloten in de <a>-tag. Deze tag bevindt zich in de <h2>-tag in de .entry-header-class in de .entry-wrap-class. We kunnen deze CSS-selectors doorgeven aan de objectmethode om de titel te extraheren, pas de code aan zodat deze er als volgt uitziet:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), } |
De afsluitende komma na extract_first() is geen typefout, aangezien we hieronder nog meer code zullen toevoegen.
Enkele punten om op te letten in de bovenstaande broncode zijn:
- ::text toegevoegd aan de selector – dit is een CSS-pseudo-selector die de code opdracht geeft om de tekst binnen de tag op te halen en niet de tag zelf.
- extract_first() methode-aanroep binnen het object – geeft de code opdracht om alleen het eerste element te kiezen dat overeenkomt met de selector. Hierdoor krijgen we een string in plaats van een lijst met elementen.
Sla vervolgens het bestand op en voer de code uit door de volgende opdracht in je terminal in te voeren:
|
1 |
scrapy runspider main.py |
In de uitvoer zou je de titels van de tutorials moeten zien:
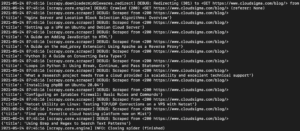
We kunnen dit blijven uitbreiden door meer selectors toe te voegen om andere details over een tutorial te verkrijgen, zoals de URL van de tutorial, de uitgelichte afbeelding en het bijschrift.
Laten we de HTML-code voor een enkele tutorial nog eens bekijken:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
<body> <div id="x-iso-container" class="x-iso-container x-iso-container-posts cols-3"> <article id="post-51691" class="post-51691 post type-post status-publish format-standard has-post-thumbnail hentry category-blog-posts category-tutorials tag-apache tag-certbot tag-cloud-guide tag-cloud-tutorial tag-https tag-lets-encrypt tag-ssl tag-ssl-certification tag-tutorial tag-ubuntu"> <div class="entry-featured"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="entry-thumb" title="Permalink naar: "Securing Apache with Let’s Encrypt on Ubuntu 18.04""> <img width="1000" height="522" src="data:image/svg+xml,%3Csvg%20xmlns='http://www.w3.org/2000/svg'%20viewBox='0%200%201000%20522'%3E%3C/svg%3E" class="attachment-entry-fullwidth size-entry-fullwidth wp-post-image" alt="Let’s Encrypt" loading="lazy" data-lazy-srcset="/media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04.jpg 1000w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-300x157.jpg 300w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-768x401.jpg 768w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-610x318.jpg 610w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-100x52.jpg 100w" data-lazy-sizes="(max-width: 1000px) 100vw, 1000px" data-lazy-src="/media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04.jpg"/> </a> </div> <div class="entry-wrap"> <header class="entry-header"> <h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Permalink naar: "Beveiligen van Apache met Let’s Encrypt op Ubuntu 18.04"">Beveiligen van Apache met Let’s Encrypt op Ubuntu 18.04</a> </h2> </header> <div class="entry-content excerpt"> <p>Website- en gegevensbeveiliging zijn onderwerpen die niet lichtvaardig kunnen worden opgevat. Zeer gevoelige informatie die onder andere financiële gegevens en privégegevens van klanten omvat, is altijd onderweg tussen de computer van de gebruiker en uw website. Als u dit feit in overweging neemt, is het niet moeilijk in te zien waarom onbeveiligde websites kunnen leiden tot een inbreuk die uw bedrijf ernstige schade kan toebrengen. Er zijn een … </p> <div><a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="more-link">Lees meer</a></div> </div> </div> </article> </div> </body> |
We willen proberen de gemarkeerde delen te extraheren, d.w.z. de URL van de tutorial, de uitgelichte afbeelding en het bijschrift.
- In het bovenstaande codefragment is de afbeelding voor de blog opgeslagen in het data-lazy-src-attribuut van een img-tag binnen een <a>-tag binnen een div-tag aan het begin van de blogtutorial. We kunnen een CSS-selector gebruiken om de waarde op te halen, net zoals we deden met de tutorialtitels.
- Het verkrijgen van de URL van de tutorial is eenvoudig, aangezien we de <a>-tag binnen het <div>-element hebben.
- Het bijschrift bevindt zich binnen de <p>-tag die zich binnen de <div>-tag bevindt.
We zullen de CSS-klassen gebruiken om te krijgen wat we willen. Laten we de code zo aanpassen dat deze er als volgt uitziet:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), 'caption': tutorial.css(CAPTION_SELECTOR).extract_first(), } |
Sla de wijzigingen op en voer de code uit met het volgende commando:
|
1 |
scrapy runspider main.py |
Je zult meer gegevens in de uitvoer zien, zoals de URL, afbeelding en het bijschrift dat we hebben toegevoegd:

Dat is alles voor het crawlen van een enkele pagina. Laten we nu kijken hoe we een scraper kunnen maken die links volgt.
Stap 3: Hoe je meerdere pagina's crawlt
Tot nu toe hebben we een scraper gemaakt die gegevens van een enkele pagina kan ophalen. We willen echter meer dan dat. Je wilt een spider die programmatisch links kan volgen en gegevens van meerdere pagina's van een website kan extraheren.
Als je naar de onderkant van de CloudSigma-blogpagina gaat, zie je de pagineringslinks en een kleine pijl die naar rechts wijst en de volgende pagina aangeeft. Hier is het HTML-codefragment:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<div class="x-pagination"> <ul class="center-list center-text"> <li><span class="pages">Pagina 1 van 45</span></li> <li></li> <li><span class="current">1</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/2/" class="single_page" title="2">2</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="single_page" title="3">3</a></li> <li><span class="expand">...</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/45/" class="last" title="Laatste pagina">45</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/2/" class="prev-next hidden-phone">→</a></li> </ul> </div> |
Het fragment toont verschillende paginanavigatielinks binnen <li>-tags, onder de <div>-tag met de .x-pagination CSS-klasse. Onze focus ligt op de link die naar de volgende pagina verwijst. Deze bevindt zich in de <a>-tag van de laatste <li> in de <ul>-tag.
De link die naar de volgende pagina verwijst, heeft de .prev-next-klasse binnen de <a>-tag, zoals te zien is in het bovenstaande fragment. Als je echter naar de volgende pagina gaat, zul je ook merken dat de links naar de vorige en volgende pagina deze CSS-klasse hebben. Kijk eens naar dit fragment voor Pagina 2:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<div class="x-pagination"> <ul class="center-list center-text"> <li><span class="pages">Pagina 2 van 45</span></li> <li><a href="https://blog.cloudsigma.com/blog/" class="prev-next hidden-phone">←</a></li> <li><a href="https://blog.cloudsigma.com/blog/" class="single_page" title="1">1</a></li> <li><span class="current">2</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="single_page" title="3">3</a></li> <li><span class="expand">...</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/45/" class="last" title="Laatste pagina">45</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="prev-next hidden-phone">→</a></li> </ul> </div> |
Als we de Scrapy extract_first() methode gebruiken, zal deze op de eerste pagina werken. Wanneer deze de volgende pagina bereikt, zal deze de eerste link met de .prev-next klasse kiezen, die in het bovenstaande fragment naar de eerste pagina verwijst. Dit zal resulteren in een lus. Daarom zullen we de Scrapy extract() methode gebruiken. Deze methode extraheert alle elementen die overeenkomen met een use-case en plaatst ze in een array. Uit deze array kunnen we het laatste element kiezen dat de daadwerkelijke link bevat die naar de volgende pagina verwijst. Pas je code aan zodat deze er als volgt uitziet:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), } NEXT_PAGE_SELECTOR = '.x-pagination > ul.center-list > li > a.prev-next::attr("href")' next_page = response.css(NEXT_PAGE_SELECTOR).extract() if next_page: yield scrapy.Request( response.urljoin(next_page[-1]), callback=self.parse ) |
Laten we de code voor de selectie van next_page doorlopen.
We definiëren eerst een selector voor de links naar de volgende en vorige pagina. Vervolgens gebruiken we de extract()-methode om de URL's te extraheren en in een array te plaatsen. De variabele next_page zal een array zijn met twee elementen zoals:
|
1 |
next_page = [prev_page_url, next_page_url] |
Omdat we naar de volgende pagina navigeren, kiezen we het laatste element in de array. Next_page[-1] kiest het laatste element in de array.
Het if-blok controleert of de variabele next_page een waarde heeft en roept vervolgens de methode scrapy.Request() aan. In onze code instrueren we deze methode om de pagina met de opgegeven URL te crawlen en deze terug te sturen naar de methode parse(), zodat we deze kunnen parsen om de gegevens te extraheren en het proces voor de volgende pagina te herhalen. Dit proces wordt herhaald totdat er geen link naar de volgende pagina meer wordt gevonden, of liever gezegd, als het blok faalt, stopt het.
Sla je code op en voer deze uit. Je zult merken dat de iteratie door de pagina's blijft lopen naarmate er meer pagina's worden gevonden om te scrapen. Dit is hoe je een scraper definieert die links op een website volgt. Ons voorbeeld is vrij eenvoudig. We gaan alleen naar een pagina, zoeken de link naar de volgende pagina en herhalen het proces. In andere use cases wil je misschien tags of links volgen die naar externe bronnen verwijzen en meer. Hier is de volledige broncode voor de basis webscraper in Python 3:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), 'caption': tutorial.css(CAPTION_SELECTOR).extract_first(), } NEXT_PAGE_SELECTOR = '.x-pagination > ul.center-list > li > a.prev-next::attr("href")' next_page = response.css(NEXT_PAGE_SELECTOR).extract() if next_page: yield scrapy.Request( response.urljoin(next_page[-1]), callback=self.parse ) |
Conclusie
In deze handleiding hebben we een eenvoudige webscraper gebouwd die de CloudSigma-blog directory kan crawlen en wat informatie over de bloghandleidingen kan weergeven in slechts ongeveer 27 regels code.
Dit is natuurlijk mogelijk omdat we het hebben gebouwd op de Scrapy Python-bibliotheek. Dit is slechts een basis die je moet helpen complexere scrapers te bouwen die meer tags, zoekresultaten van websites en meer volgen. Je kunt de officiële documentatie van Scrapy bekijken voor meer informatie over het werken met Scrapy.
Veel computerplezier!
Reacties
Nog geen reacties. Wees de eerste.