

企業は大量のデータを意味し、それがデータの取り扱いや管理の問題をより困難にしています。伝統的に、業界は何十年もの間RDBMSシステムを使用してきましたが、21世紀のビッグデータの到来により、大規模な非構造化および半構造化データ向けにNoSQL(Not only SQL)データベースが登場しました。
この記事では、MongoDBクラスターをセットアップします。
MongoDBは、提供される高い拡張性と柔軟性により広く使用されている、無料かつオープンソースのNoSQLドキュメントデータベースです。
本番環境にMongoDBを導入するには、レプリカセット(Replica Sets)を使用することをお勧めします。レプリカセットは、リレーショナル世界におけるマスタ/スレーブ構成に相当するMongoDBの機能ですが、対照的に、すべてが組み込まれているため、セットアップは非常に簡単です。レプリカセットの詳細については、以下を参照してください。TutorialsPoint’sによるレプリケーションプロセスの定義.
MongoDBクラウドサーバークラスターの計画
3ノードのクラスターを作成します。どのノードもプライマリ(つまりマスター)サーバーになる可能性があるため、それらに同等のリソースを割り当てることが重要です。これらのノードまたはマシンは任意のオペレーティングシステムで動作しますが、このチュートリアルではUbuntu 18.04 LTSを使用します。CloudSigma’sのライブラリからプリインストールされたイメージをアタッチしてセットアップする方法については、以下を参照してください。このチュートリアル.
レプリカセットの本来の目的は、単一ノードがダウンしてもクラスターが存続することであるため、すべてのサーバーが同じ物理ホスト上に存在すると、あまり意味がありません。幸いなことに、CloudSigmaは以下と呼ばれる機能を提供しています。アベイラビリティグループ。これは、3つのサーバーすべてを異なるグループにグループ化するようシステムに指示できることを意味します。そうすることで、それらが同じ物理ホスト上に配置されることはなくなります。これや、その他のセキュリティおよびビジネス継続性機能に関する詳細情報は、以下で確認できます。こちら.
また、64ビット版のLinuxを使用することも重要です。その理由は単純に、MongoDBが32ビットシステムではうまく動作しないためです(詳細については、以下を参照してください。こちら).
クラウドへのMongoDBのインストール
このセクションは非常に簡単です。事前設定されたもののいずれかを使用するか、Ubuntu 18.04イメージを使用するか、ご自身でインストールしてください。
CPU、RAM、およびディスクの構成は本当に個別であり、負荷によって異なります。小規模なインストールの場合は、4 GHz CPU、4 GB RAM、および10 GBディスク(システム用)で十分なはずです。ドライブをアタッチするときは、必ずVirtIOを使用していることを確認してください。IDEを使用すると、パフォーマンスが大幅に低下します。また、レプリカセットを作成するため、すべてのノード(およびアプリサーバー)が同じVLAN上にある必要があります。
他の多くのクラウドベンダーとは異なり、パフォーマンスを向上させるためにストレージをRAID10などで構成する必要はありません。多くのお客様が報告しているように、CloudSigmaでSSDと磁気ディスクの両方を使用することで、すぐに素晴らしいパフォーマンスを得ることができます。
それでも、MongoDBのデータは別のドライブに保存することをお勧めします。その理由は単純に、ある時点でファイルシステム全体の最適化を行いたくないような、特定のファイルシステム最適化を行う必要が生じる可能性があるためです。
これを念頭に置くと、サーバーのセットアップ後にこのドライブを追加するのが最も簡単です。今のところは、システムインストールだけに集中しましょう。ご自身でインストールする場合(事前設定されたシステムを使用しない場合)は、ブートメニューでF4キーを押し、以下を選択することをお勧めします。「最小限の仮想マシンのインストール(Install a minimal virtual machine)」.
以下の仕様で3台のマシンを作成しています。
- CPU: 4 GHz
- RAM: 4 GB
- SSD: 10 GB (Ubuntu 18.04 LTS), 20 GB (追加ドライブ)
SSDの部分に記載されているように、Ubuntu 18.04 LTSがインストールされた10 GBのドライブをアタッチしています。
さらに、MongoDBデータを保存するために、20 GBの別の空のドライブを一緒にアタッチしています。このサイズは使用状況に大きく依存しますが、小規模なシステムであれば20GBで十分でしょう。ただし、保存するデータ量を予測するのが難しい場合もあるため、以下を使用します。LVM。これにより、後から別のドライブを簡単に追加して、最初からやり直すことなくボリュームを拡張できます。あるいは、単一のドライブを使用して、後で以下を使用してスケールアップすることもできます:resize2fs。
ディスクを追加するには、‘Drives’セクションに移動し、上部にある‘Create a new drive’アイコンをクリックして、新しいディスクに名前を付け、サイズを20 GBに設定します。保存したら、アタッチしたい個別のマシンに移動し、そのマシンの詳細のドライブセクションで‘Attach a drive’をクリックして、ディスクを選択します。
3台のマシンが用意できたので、MongoDBのデータストレージ用に追加した予備のディスクを各マシンにマウントします。このディスクはパーティションとして追加することをお勧めします。パーティショニングを使用すると、オペレーティングシステムが各領域の情報を個別に管理できるようになります。ディスクをパーティションとして追加するために、まずマシンにアタッチされているすべてのディスクを確認します。そのために、次のコマンドを実行します:
|
1 |
fdisk -l |
コマンドを実行すると、マシン上のディスクとデバイスを示す出力が表示されます。
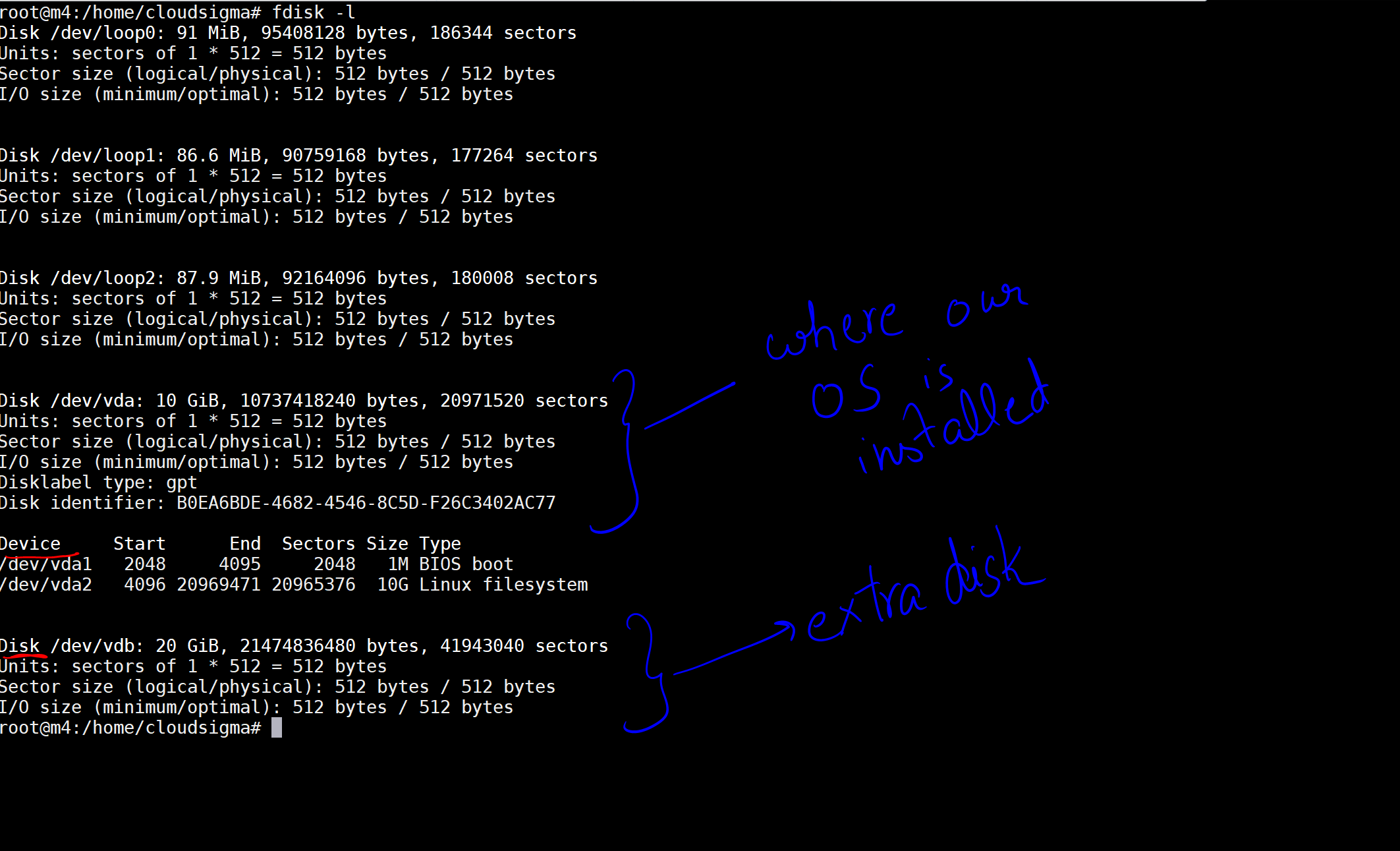
画像では、OSがインストールされているディスクとして10 GBのディスクをマークしています。そして、新しくアタッチされた20 GBの別のディスクがあります。ディスクの場所は /dev/vdb です。次のコマンドを使用して、このディスクにパーティションを作成できます:
|
1 |
sudo fdisk /dev/vdb |
これにより、ディスクパーティショニング機能を提供するコマンドラインユーティリティであるfdiskユーティリティが開き、ディスク上にパーティションを作成できます。“Command (m for help):”というプロンプトが表示されるので、そこに n を入力して新しいパーティションを作成し、その後はEnterキーを押し続けてデフォルト値を受け入れます。パーティションが作成されたら、w を入力して変更を書き込みます。以下のようになります:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
コマンド (m 用 ヘルプ): <strong>n</strong> パーティション タイプ p プライマリ (0 プライマリ, 0 拡張, 4 空き) e 拡張 (コンテナ 用 論理 パーティション) 選択 (デフォルト p): 使用中 デフォルト 応答 p. パーティション 番号 (1-4, デフォルト 1): 最初の セクター (2048-41943039, デフォルト 2048): 最後の セクター, +セクター または +サイズ{K,M,G,T,P} (2048-41943039, デフォルト 41943039): 作成されました a 新規 パーティション 1 の タイプ 'Linux' および の サイズ 20 GiB. コマンド (m 用 ヘルプ): <strong>w</strong> その パーティション テーブル が 変更 されました. 呼び出し中 ioctl() して 再-読み込み パーティション テーブル. 同期中 ディスク. |
これにより、タイプ‘Linux’、サイズ20 GiB of の新しいパーティション1が作成されました。パーティションが作成されたので、LVMプールを作成しましょう:
|
1 2 3 |
sudo pvcreate /dev/vdb1 sudo vgcreate mongodb /dev/vdb1 sudo lvcreate -n db -L 19.5g mongodb |
パーティションサイズが20gであるため、‘19.5g’と入力しました。次に、以下のコマンドを実行してディスクの名前を確認します:
|
1 |
fdisk -l | grep mongo | awk '{print $2'} |
その後、次のコマンドを使用してext4方式でディスクをフォーマットします:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
sudo mkfs.ext4 /dev/mapper/mongodb-db 出力: root@m4:/home/cloudsigma# sudo mkfs.ext4 /dev/mapper/mongodb-db mke2fs 1.44.1 (24-Mar-2018) 作成中 ファイルシステム を 5217280 4k ブロック および 1305600 iノード ファイルシステム UUID: 695a62e6-021d-4fc0-945c-cc51a92d86da スーパーブロック バックアップ 格納 上 ブロック: 32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208, 4096000 割り当て中 グループ テーブル : 完了 書き込み中 iノード テーブル : 完了 作成中 ジャーナル (32768 ブロック ): 完了 書き込み中 スーパーブロック および ファイルシステム アカウンティング 情報 : 完了 |
次に、ディスクをマウントする場所と、MongoDBデータを保存するフォルダーを作成しましょう。
|
1 |
sudo mkdir -p /mongodb/data |
マウントする新しいディスクに関するエントリをfstabに追加するには、以下のコマンドを直接使用できます。
|
1 |
echo -e "` blkid | grep mongodb | awk {'print $2'}`\t/mongodb\text4 auto,noexec,rw,sync,nouser\t0\t0" >> /etc/fstab |
このコマンドでは、blkid は、各ディスクのUUID(Universally Unique Identifier:汎用一意識別子)を提供します。ここでは、MongoDBディスク用のUUIDをgrepで抽出し、このUUIDをマウントフォルダーの場所、ファイルシステムタイプ、およびディスクのその他のオプションとそれぞれ組み合わせています。この行を/etc/fstabに追加します。これを行わないと、ディスクのマウント時にエラーが発生します。エントリは次のようになります。
UUID=”695a62e6-021d-4fc0-945c-cc51a92d86da” /mongodb ext4 auto,noexec,rw,sync,nouser 0 0
これで、/mongodbの場所にディスクをマウントできます。
|
1 |
sudo mount /mongodb |
MongoDBのインストール
システムの準備が整ったので、MongoDBのインストールに進みましょう。Ubuntu独自のレポジトリでもMongoDBのバージョンが提供されていますが、代わりに公式のMongoDBバージョンを使用することをお勧めします。その理由は、Ubuntuのレポジトリはリリースがかなり遅れているため、MongoDBを最大限に活用したい場合は、公式リリースを利用する必要があるからです。
MongoDBは独自のレポジトリを提供しているため、これをシステムに追加するだけで、通常通りMongoDBをインストールできます。手順は以下の通りです。
まず、パッケージ管理システムで使用される公開鍵をインポートします。
|
1 |
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 9DA31620334BD75D9DCB49F368818C72E52529D4 |
次に、リストファイルを作成します。これにはMongoDBがあるレポジトリが含まれるため、システムはそこからダウンロードできます。
|
1 |
echo "deb [ arch=amd64 ] https://repo.mongodb.org/apt/ubuntu bionic/mongodb-org/4.0 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-4.0.list |
ここで、変更を反映するためにローカルパッケージデータベースを更新します。
|
1 |
sudo apt-get update |
これで、次のコマンドを使用してパッケージをインストールできます。
|
1 |
sudo apt-get install -y mongodb-org |
各マシンにMongoDBをインストールしました。
|
1 |
sudo service mongod start |
これでMongoDBが起動し、作成されたドライブ上にデータが保存されます。高負荷や多数の接続が予想される場合は、ulimit の値を引き上げる必要がある場合があります。
データについてさらに深い洞察を得たい場合は、MongoDBの MMS に登録することもできます。これはMongoDB向けの無料のクラウドベースの監視サービスです。
MongoDBクラウド用のレプリカセットの作成
次に、レプリカセットを作成しましょう。その前に、各マシンが相互に通信できることを確認する必要があります。この目的のために、/etc/hostsにこれらのエントリを追加します。
|
1 2 3 |
IP-1 m1.mongo.cluster m1 IP-2 m2.mongo.cluster m2 IP-3 m3.mongo.cluster m3 |
検証のために、ホスト名を使用してマシンにpingを送信してみることができます。したがって、マシン1のIPがIP-1(たとえば213.189.123.12)である場合、次のように書く代わりに、
|
1 |
ping 123.189.123.12 |
次のように書きます。
|
1 2 3 |
ping m1.mongo.cluster または ping m1. |
ファイアウォールを有効にしている場合(有効にすることを強くお勧めします)、ノードが内部インターフェース上のポート28017および27017でTCPトラフィックを送受信できることを確認してください。
次に、各マシンで、以下のコマンドを使用してmongodサービスを起動します。
マシンm1の場合、
|
1 |
mongod --dbpath /mongodb/data --replSet rs0 --bind_ip localhost,m1.mongo.cluster |
次に、マシンm2の場合、
|
1 |
mongod --dbpath /mongodb/data --replSet rs0 --bind_ip localhost,m2.mongo.cluster |
マシンm3の場合、
|
1 |
mongod --dbpath /mongodb/data --replSet rs0 --bind_ip localhost,m3.mongo.cluster |
ここで、
mongod はサービスの名前です
dbpath はデータベースディレクトリの場所です
replSet はレプリケーションセットの名前です。同じレプリカセット内の各マシンで同じである必要があります
bind_ip は、それを実行しているマシンのホスト名です。
mongodサービスを起動したら、プライマリサーバー(私の場合はm1を選択しました)に移動し、mongoを実行します。
|
1 |
mongo |
これによりMongoDBターミナルが起動します。ターミナルで、以下のコマンドを使用してreplicaSetを初期化します。デフォルト設定でreplicaSetが作成されます。
|
1 |
rs.initiate() |
それでは、次のコマンドを使用して、他の2つのマシンをレプリカとして追加しましょう:
|
1 2 |
rs.add("m2.mongo.cluster") rs.add("m3.mongo.cluster") |
次のコマンドを使用してステータスを監視できます:
|
1 |
rs.status() |
これだけです。これで、CloudSigma’sの非常に高速なクラウド上でMongoDBクラスターが稼働しているはずです。
コメント
コメントはまだありません。最初のコメントを投稿しましょう。