

このチュートリアルでは、Kubernetes クラスターを一から Ansible および Kubeadm を使用してセットアップし、さらにコンテナ化された Nginx アプリケーションをデプロイする方法を説明します。
はじめに
Kubernetes(k8sまたは“kube”とも呼ばれます)は、コンテナ化されたアプリケーションのデプロイ、管理、スケーリングに関連する多くの手動プロセスを自動化する、オープンソースのコンテナオーケストレーションプラットフォームです。Kubernetesには、急速に成長しているオープンソースコミュニティがあり、プロジェクトに積極的に貢献しています。次のブログ記事をご覧になり、Kubernetesプラットフォームの基本.
Kubeadmは、APIサーバー、コントローラーマネージャー、Kube DNSなどの複数の統合された要素、パーツ、部品を構成するツールです。また、インストールの自動化にも役立ちます。ただし、ユーザーの作成や、オペレーティングシステムレベルの依存関係のインストールとその構成は処理せず、インフラストラクチャのプロビジョニングを行うことはできません。
Ansibleは、ソフトウェアのプロビジョニングとアプリケーションのデプロイを行うためのオープンソースツールです。Saltstackは、イベント駆動型のIT自動化用オープンソースソフトウェアです。これら2つのツールを使用することで、追加のクラスターの作成や既存のクラスターの再作成におけるエラーの発生を抑えることができ、これらの事前タスクに使用できます。
目標:
クラスターには、次の物理リソースが含まれます。
1. 1つのマスターノード:
マスターノードは、一連 of ワーカーノード(ワークロードの実行環境)を制御および管理するノードであり、Kubernetesにおけるクラスターを象徴するものです。また、トリガーされたイベントに対して適切なアクションを決定するためのノードのリソース計画も保持します。これは、etcdを実行します。これは、ワーカーノードにワークロードをスケジュールするコンポーネント間でクラスターデータを保持および管理するために使用される、オープンソースの分散キーバリューストアです。
たとえば、スケジューラーは、新しくスケジュールされたPODをどのワーカーノードでホストするかを決定します。
2. 2つのワーカーノード:
ワーカーノードは、スケジューリングが完了した後は、マスターノードがダウンしても割り当てられた作業を継続するノードです。ワーカーノードは、ワークロード(つまり、コンテナ化されたアプリケーションやサービス)が実行されるサーバーです。また、ワーカーを追加することでクラスターの容量を増やすこともできます。
このチュートリアルを完了すると、クラスター内のサーバーにアプリケーションを実行するのに十分なCPUおよびRAMリソースがあると仮定して、ワークロード(つまり、コンテナ化されたアプリケーションやサービス)を実行する準備が整った、完全に機能するクラスターが構築されます。クラスターのセットアップが正常に完了すると、ほぼすべての従来のUNIXアプリケーションを実行できます。Webアプリケーション、データベース、デーモン、コマンドラインツールなど、クラスター上でコンテナ化することが可能です。
クラスター自体は、各ノードで約300〜500MBのメモリと10%のCPUを消費します。
前提条件:
- ローカルのLinuxマシンにSSHキーペアがあり、SSHキーの使用方法を理解している必要があります。ただし、これまでにSSHキーを使用したことがない場合は、次のチュートリアルを参照して、ローカルマシンにSSHキーをセットアップしてください。.
- それぞれ少なくとも4GBのRAMと4つのvCPUを搭載し、Ubuntu 18.04を実行している3台のサーバー。SSHキーペアを使用して、rootユーザーとして各サーバーにSSH接続できる必要があります。次のチュートリアルに従ってUbuntuサーバーをインストールしてください.
- ローカルマシンにAnsibleがインストールされていること。
- また、Ansibleプレイブックに精通している必要があります。
- また、Dockerイメージからコンテナを起動する方法を知っておく必要があります。復習が必要な場合は、Ubuntu 18.04にDockerをインストールして使用する方法の「ステップ5 — UbuntuでのDockerイメージの操作」を参照してください。
ステップ 1 — ワークスペースディレクトリとAnsibleインベントリファイルのセットアップ
まず、ローカルマシンにAnsibleをセットアップする必要があります。これにより、リモートサーバーでコマンドを実行できるようになります。また、手動でのデプロイ作業を自動化することで、その労力を軽減できます。このために、一時的なデジタルストレージ領域(ワークスペース)として機能するディレクトリをローカルマシンに作成する必要があります。
ディレクトリを作成したら、hosts 各サーバーのIPアドレスとグループに関するすべての情報を保存するためのファイルです。これにより、インベントリ情報を内部に保存できます。前述のように、3台のサーバー(マスター1台、ワーカー2台)が存在します。マスターサーバーはマスターとなり、IPは master_ip. と表示されます。残りの2台のサーバーはワーカーとなり、IPは worker_1_ip および worker_2_ip.
ローカルマシンのホームディレクトリに、~/kube-cluster という名前のディレクトリを作成し、cdコマンドを使用してそのディレクトリに移動する必要があります:
|
1 2 |
mkdir ~/kube-cluster cd ~/kube-cluster |
The ~/kube-cluster ディレクトリは、kubeadmを使用してKubernetesクラスターを作成するためのすべてのローカルコマンドを実行する、一時的なデジタルストレージ領域(ワークスペース)として機能するようになります。このディレクトリにはすべてのAnsibleプレイブックが含まれ、チュートリアルの残りの部分で使用されます。
Hostsファイルの作成
次のファイル ~/kube-cluster/hosts を、nano またはお好みのテキストエディタを使用して作成します:
|
1 |
nano ~/kube-cluster/hosts |
次に、クラスターの論理構造に関する情報を指定する以下のテキストを追加する必要があります:
|
1 2 3 4 5 6 7 8 9 |
[masters] master ansible_host=master_ip ansible_user=root [workers] worker1 ansible_host=worker_1_ip ansible_user=root worker2 ansible_host=worker_2_ip ansible_user=root [all:vars] ansible_python_interpreter=/usr/bin/python3 |
前述のように、このインベントリファイルは、サーバーのIPアドレスと各サーバーが属するグループに関するすべての情報を保存するのに役立ちます。~/kube-cluster/hosts がインベントリファイルになり、(masters および workers) は、クラスターの論理構造を指定するために追加した2つのAnsibleグループになります。
この Master グループは、Ansibleがrootユーザーとしてリモートコマンドを実行することを指定するグループです。また、マスターノードのIP(master_ip)も“master”というサーバーエントリによってリストされます。同様に、Workers グループには、ワーカーサーバー用の2つのエントリ(worker_1_ip および worker_2_ip)があり、これらも ansible_user をrootとして指定しています。
ファイルの最後の行は、Ansibleの管理操作にリモートサーバーのPython 3インタプリタを使用するように指示しています。最後に、テキストを追加した後にファイルを保存して閉じる必要があります。ワークスペースディレクトリとAnsibleインベントリファイルを設定したら、次のステップであるオペレーティングシステムレベルの依存関係のインストールと構成設定の作成に進みましょう。
ステップ 2 — すべてのリモートサーバーでの非rootユーザーの作成
このステップでは、すべてのサーバーにsudo権限を持つ非rootユーザーを作成し、非特権ユーザーとして手動でSSH接続できるようにする方法を学びます。
これは、クラスターの維持のために頻繁に実行される操作に役立ちます。さらに、このステップにより、タスクをより正確に、エラーを少なく実行できるようになり、重要なファイルを意図せず変更または削除する可能性が低くなります。rootが所有するファイルの設定を変更したり、top/htop などのコマンドでシステム情報を表示したり、実行中のコンテナの一覧を表示したりする場合、次のステップがすべてのタスクを実行するのに役立ちます。
プレイブックの作成
ワークスペースに ~/kube-cluster/initial.yml という名前のファイルを作成します:
|
1 |
nano ~/kube-cluster/initial.yml |
次に、以下のプレイを追加する必要があります。Ansibleにおけるプレイとは、特定のサーバーやグループを対象に実行される一連のステップの集まりです。プレイブックには1つまたは複数のプレイを含めることができます。
以下のプレイは、非rootのsudoユーザーを作成します:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
- hosts: all become: yes tasks: - name: 作成する the 'ubuntu' ユーザー user: name=ubuntu append=yes state=present createhome=yes shell=/bin/bash - name: 許可する 'ubuntu' to 持たせる パスワードなしの sudo lineinfile: dest: /etc/sudoers line: 'ubuntu ALL=(ALL) NOPASSWD: ALL' validate: 'visudo -cf %s' - name: 設定する up 認証済み キー 用 the ubuntu ユーザー authorized_key: user=ubuntu key="{{item}}" with_file: - ~/.ssh/id_rsa.pub |
以下は、このプレイブックが行う処理の内訳です:
- このプレイブックは、非ルートユーザーである
ubuntu. - パスワードの入力を求められることなく
sudoコマンドを実行する必要があるため、このプレイではsudoersファイルを設定して、ubuntuユーザーがそれを実行できるようにします。 - 上記のタスクの主な目的は、各サーバーに
ubuntuユーザーとしてSSH接続できるようにすることです。このプレイブックは、ローカルマシンの公開鍵(通常は~/.ssh/id_rsa.pub)を、リモートのubuntuユーザーの認証済みキーリストに追加します。
テキストを追加したら、ファイルを保存して閉じる必要があります。
プレイブックの実行
その後、ローカルマシンで以下を実行するだけで、非ルートユーザーであるubuntuを作成するプレイブックを実行できます:
|
1 |
ansible-playbook -i hosts ~/kube-cluster/initial.yml |
このコマンドの実行にはしばらく時間がかかります。完了すると、以下のような出力が表示されます:
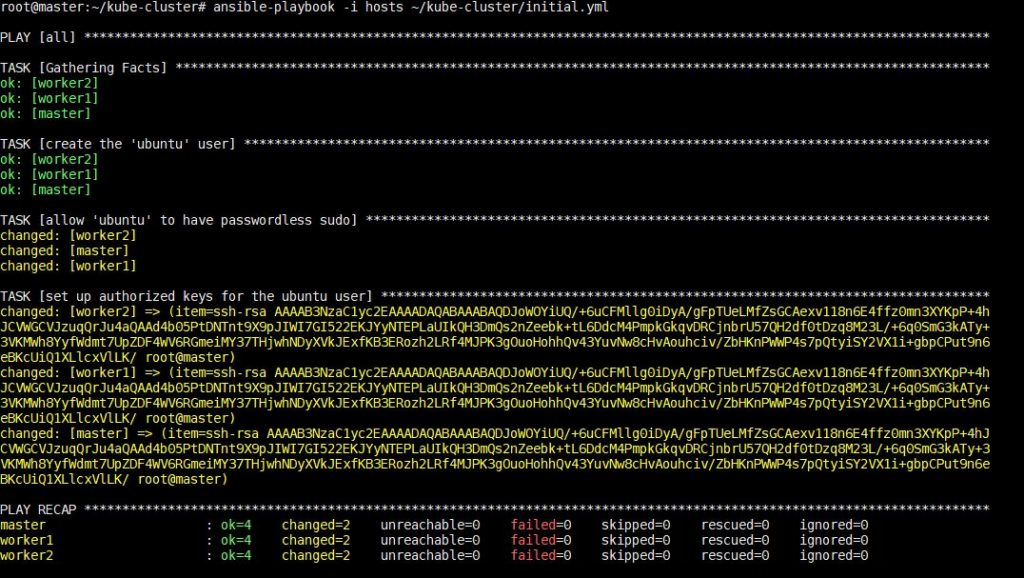
このステップが完了したら、次のステップでKubernetes固有の依存関係のインストールに進むことができます。
ステップ3 — Kubernetesの依存関係のインストール
このステップでは、Ubuntuのパッケージマネージャーを使用して、Kubernetesに必要なオペレーティングシステムレベルのパッケージをインストールする方法を学びます。
これらのパッケージは以下の通りです:
- Docker:Dockerは、Dockerコンテナを構築、配布、実行するためのプラットフォームおよびツールです。次のチュートリアル「パブリッククラウド上のUbuntuにDockerをインストール&操作する方法」に従うことで、Dockerを簡単にセットアップできます。ただし、rkt などの他のランタイムのサポートも、Kubernetesで活発に開発されています。
Kubeadm: kubeadm は、実用最小限のクラスターを起動して実行するために必要なアクションを実行するCLIツールです。これにより、標準的な方法でクラスターのさまざまなコンポーネントをインストールおよび構築できます。kubelet: kubelet は、各ノードで実行され、ノードレベルの操作を処理する主要な“ノードエージェント”です。kubectl: kubectl も、クラスターと通信し、そのAPIサーバーを介してコマンドを発行するCLIツールです。
プレイブックの作成
ワークスペースに ~/kube-cluster/kube-dependencies.yml という名前のファイルを作成します:
|
1 |
nano ~/kube-cluster/kube-dependencies.yml |
次に、以下のプレイをファイルに追加して、サーバーにこれらのパッケージをインストールする必要があります:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
- hosts: all become: yes tasks: - name: インストール Docker apt: name: docker.io state: present update_cache: true - name: インストール APT Transport HTTPS apt: name: apt-transport-https state: present - name: 追加 Kubernetes apt-key apt_key: url: https://packages.cloud.google.com/apt/doc/apt-key.gpg validate_certs: false state: present - name: 追加 Kubernetesの APT リポジトリ apt_repository: repo: deb http://apt.kubernetes.io/ kubernetes-xenial main state: present filename: 'kubernetes' - name: インストール kubelet apt: name: kubelet=1.16.0-00 state: present update_cache: true - name: インストール kubeadm apt: name: kubeadm=1.16.0-00 state: present - hosts: master become: yes tasks: - name: インストール kubectl apt: name: kubectl=1.16.0-00 state: present force: yes |
プレイブックの最初のプレイは以下を行います:
- このプレイは、オペレーティングシステムレベルのパッケージ、およびコンテナランタイムである Docker – のインストールに役立ちます。
- 以下をインストールします:
apt-transport-https。これにより、外部の HTTPS ソースを APT ソースリストに追加できるようになります。 - キー検証のために Kubernetes APT リポジトリの apt-key を追加します。
- Kubernetes APT リポジトリをリモートサーバーの APT ソースリストに追加します。
- 以下をインストールします:
kubeletおよびkubeadm.
2 番目のプレイは、kubectl をマスターノードにインストールすることを含む、重要かつ単独のタスクを実行します。テキストを追加したら、ファイルを保存して閉じる必要があります。
プレイブックの実行
その後、ローカルマシンで以下を実行するだけで、プレイブックを実行できます。
|
1 |
ansible-playbook -i hosts ~/kube-cluster/kube-dependencies.yml |
このコマンドの実行にはしばらく時間がかかります。その後、次の出力が表示されます。
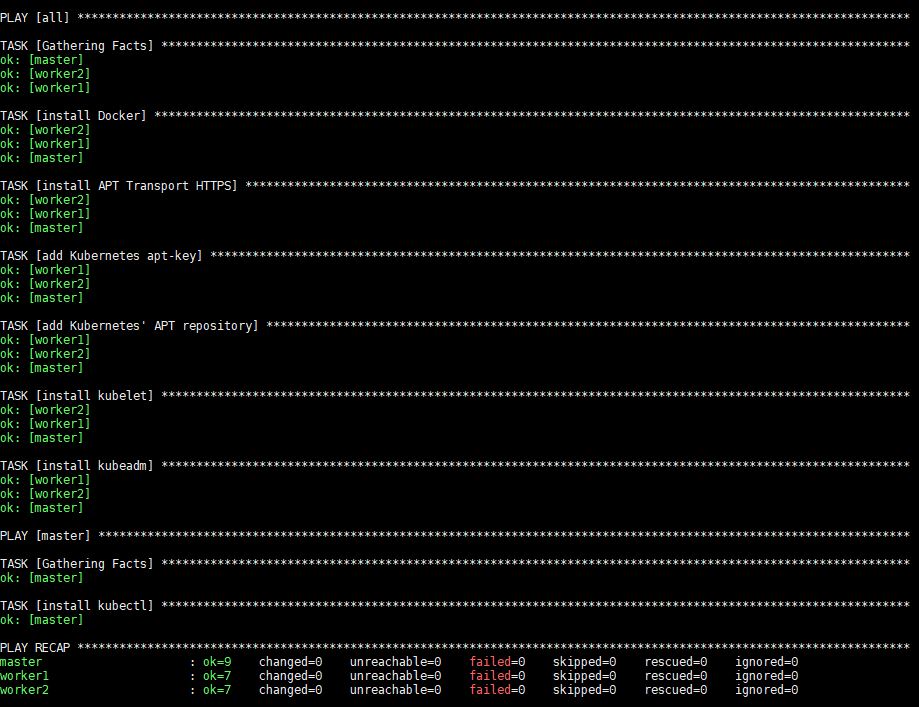
実行後、Docker、kubeadm および kubelet がすべてのリモートサーバーにインストールされます。kubectl は必須のコンポーネントではなく、クラスターコマンドを実行するためにのみ必要です。このコンテキストでは、kubectl コマンドをマスターからのみ実行するため、マスターノードにのみインストールするのが合理的です。ただし、kubectl コマンドをマスターからのみ実行するため、マスターノードにのみインストールするのが合理的です。ただし、kubectl コマンドは、任意のワーカーノード、またはインストールされてクラスターを指すように設定されている任意のマシンから実行できます。
すべてのシステム依存関係がインストールされました。マスターノードをセットアップし、クラスターを初期化しましょう。
ステップ 4 — マスターノードのセットアップ
このステップでは、次のようないくつかの概念について学びます:Pod および Pod ネットワークプラグイン。マスターノードをセットアップすると、クラスターにこれら両方が含まれるようになるためです。
Pod は、Kubernetes においてデプロイ可能な最小かつ最も基本的なオブジェクトです。Pod には、Docker コンテナなどの 1 つ以上のコンテナが含まれます。Pod が複数のコンテナを実行する場合、それらのコンテナは単一のエンティティとして管理され、Pod’のリソースを共有します。
各 Pod は独自の IP アドレスを持ち、あるノード上の Pod は、その Pod’の IP を使用して別のノード上の Pod にアクセスできる必要があります。ただし、Pod 間の通信はより複雑です。あるノード上の Pod から別のノード上の Pod へトラフィックを透過的にルーティングできる、別のコンポーネントが必要になります。この機能には Pod ネットワークプラグインが使用されます。多くの Pod ネットワークプラグインが利用可能ですが、ここでは Flannel を使用します。これは安定していて効率的な選択肢だからです。
プレイブックの作成
ローカルマシンに master.yml という名前の Ansible プレイブックを作成します:
|
1 |
nano ~/kube-cluster/master.yml |
さらに、クラスターを初期化して Flannel をインストールするために、次のプレイをファイルに追加する必要があります:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
- hosts: master become: yes tasks: - name: クラスターを初期化する shell: kubeadm init --pod-network-cidr=10.244.0.0/16 >> cluster_initialized.txt args: chdir: $HOME creates: cluster_initialized.txt become: yes become_user: root - name: kube .ディレクトリの作成 become: yes become_user: ubuntu file: path: $HOME/.kube state: directory mode: 0755 - name: admin.conf.をユーザーの kube 設定に'コピー するconfig copy: src: /etc/kubernetes/admin.conf dest: /home/ubuntu/.kube/config remote_src: yes owner: ubuntu - name: Pod ネットワークのインストール become: yes become_user: ubuntu shell: kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/2140ac876ef134e0ed5af15c65e414cf26827915/Documentation/kube-flannel.yml >> pod_network_setup.txt args: chdir: $HOME creates: pod_network_setup.txt |
このプレイの内訳は以下の通りです:
- このプレイの最初のタスクは、以下を実行してクラスターをセットアップします:
kubeadm init。ポッドのIPが割り当てられるプライベートサブネットを指定するために、次の引数を渡します:--pod-network-cidr=10.244.0.0/16。Flannelはデフォルトで上記のサブネットを使用します。これを使用して、kubeadmに同じサブネットを使用するように指示します。 - 2番目のタスクは、次の場所に
.kubeディレクトリを作成するために使用されます:/home/ubuntu。クラスターへの接続に必要な管理者キーファイルやクラスターのAPIアドレスなどの設定情報は、このディレクトリに保持されます。 - 3番目のタスクは、
/etc/kubernetes/admin.confから生成されたファイルを、kubeadm init非ルートユーザーのホームディレクトリにコピーするために使用されます。これにより、kubectlを使用して、新しく作成されたクラスターにアクセスできるようになります。 - 最後のタスクは、
kubectl applyを実行してFlannel.kubectl apply -f descriptor.[yml|json]は、kubectlに、次のファイルで記述されているオブジェクトを作成するように指示する構文です:descriptor.[yml|json]ファイル。kube-flannel.ymlファイルには、クラスター内にFlannelをセットアップするために必要なオブジェクトの記述が含まれています。
テキストを追加したら、ファイルを保存して閉じる必要があります。
プレイブックの実行
その後、ローカルマシンで以下を実行するだけで、プレイブックを実行できます。
|
1 |
ansible-playbook -i hosts ~/kube-cluster/master.yml |
このコマンドの実行にはしばらく時間がかかります。その後、次の出力が表示されます。
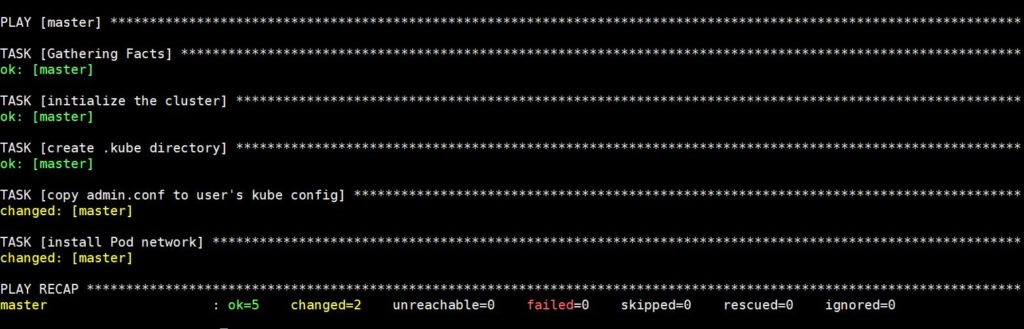
マスターノードのステータスを確認するために、次のコマンドでSSH接続します。
|
1 |
ssh ubuntu@master_ip |
マスターノードに入ったら、以下を実行します:
|
1 |
kubectl get nodes |
これで、次の出力が表示されます。

上記の出力が表示されれば、マスターノードによるすべてのセットアップタスクが完了し、Ready状態になってワーカーノードの受け入れとタスクの実行を開始できる状態になったと宣言できます。これで、ローカルマシンからワーカーを追加できます。
ステップ 5 — ワーカーノードのセットアップ
マスターノードを設定した後は、次のステップであるワーカーノードのセットアップに進むことができます。クラスターへのワーカーノードの追加は、各ワーカーサーバーで単一のコマンドを実行するだけで簡単に行えます。このコマンドには、IPアドレス、マスターのAPIサーバーのポート、セキュアトークンなどの重要な情報が含まれています。ただし、すべてのノードがクラスターに参加できるわけではなく、セキュアトークンを渡したノードのみがクラスターに参加できることに注意してください。
プレイブックの作成
このコマンドは、ワークスペースに戻り、次の名前のプレイブックを作成するのに役立ちます:workers.yml:
|
1 |
nano ~/kube-cluster/workers.yml |
クラスターにワーカーを追加するために、ファイルに次のテキストを追加します:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
- hosts: master become: yes gather_facts: false tasks: - name: get join command shell: kubeadm token create --print-join-command register: join_command_raw - name: set join command set_fact: join_command: "{{ join_command_raw.stdout_lines[0] }}" - hosts: workers become: yes tasks: - name: join cluster shell: "{{ hostvars['master'].join_command }} >> node_joined.txt" args: chdir: $HOME creates: node_joined.txt |
プレイブックの処理内容は以下の通りです。上記のコードには2つのプレイがあります。
- 最初のプレイは、ワーカーノードで実行する必要があるジョインコマンドを取得するために使用されます。コマンドの形式は次のようになります。
kubeadm join --token sha256:<hash><token><master-ip>:<master-port> --discovery-token-ca-cert-hash sha256:<hash>;。タスクは正しいトークンとハッシュ値を取得する必要があります。正しい入力を取得すると、タスクはそれをファクトとして設定し、2番目のプレイがその情報にアクセスできるようにします。 - 2番目のプレイは、単一のタスクを実行するためだけに記述されています – すべてのワーカーノードでジョインコマンドを実行するだけで、2つのワーカーノードをクラスターの一部にします。
テキストを追加した後、ファイルを保存して閉じる必要があります。
プレイブックの実行
その後、ワーカーマシンで次のコマンドを実行してプレイブックを実行する必要があります。
|
1 |
ansible-playbook -i hosts ~/kube-cluster/workers.yml |
このコマンドの実行にはしばらく時間がかかります。その後、以下のような出力が表示されます。
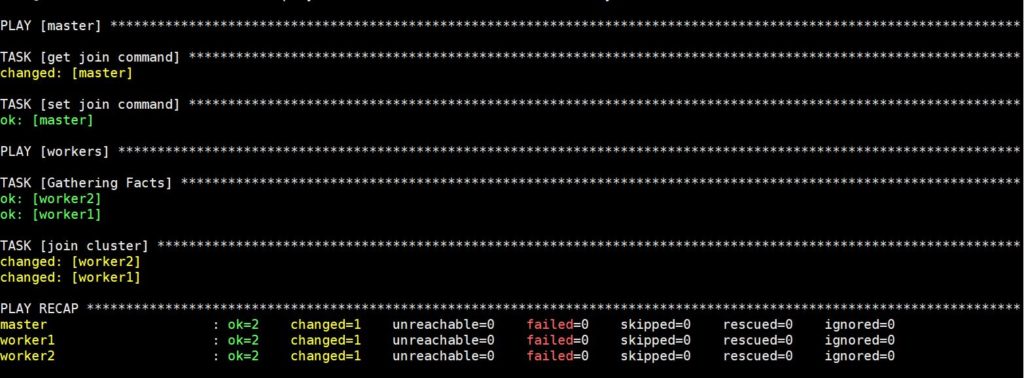
これで、Kubernetesクラスターのセットアップが完全に完了し、ワーカーがワークロードを実行できる状態になりました。次のステップに進む前に、クラスターが計画通りに動作しているか確認しましょう。
ステップ 6 — クラスターの検証
セットアップ中にクラスターが失敗するケースがあります。マスターとワーカーの間のネットワークエラーや、ノードの問題が原因である可能性があります。そのため、アプリケーションをスケジュールする前にクラスターを検証し、不具合が発生していないことを確認する必要があります。このためには、マスターノードからクラスターの現在の状態を確認し、ノードが準備完了(Ready)状態であることを確認する必要があります。ノードの準備ができていない場合や、接続が切断された場合は、次のコマンドで接続を再開できます。
|
1 |
ssh ubuntu@master_ip |
クラスターのステータスを取得するには、次のコマンドを使用します。
|
1 |
kubectl get nodes |
このコマンドの実行にはしばらく時間がかかります。その後、以下のような出力が表示されます。

クラスターの一部であるすべてのノードが準備完了(Ready)状態であるかどうかを確認する必要があります。一部のノードがNot Ready を STATUS としている場合、ワーカーノードのセットアップがまだ完了していないことを示しています。ただし、kubectl get nodes を再実行して更新された出力を確認する前に、さらに5〜10分待つ必要があります。一部のノードが依然としてNot Ready をステータスとして表示している場合は、前の手順を確認してコマンドを再実行する必要があります。ノードのSTATUSの値がReadyである場合のみ、それらはクラスターの一部であり、ワークロードを実行する準備ができています。ステップ6を正常に実行すると、クラスターの検証は完了です。それでは、クラスター上にサンプルのNginxアプリケーションをスケジュールしてみましょう。
ステップ 7 — クラスター上でのアプリケーションの実行
デプロイメントの作成
クラスターの作成に成功したら、コンテナ化された任意のアプリケーションをクラスターにデプロイできます。マスターノード内にいる場合は、他のコンテナ化されたアプリケーションに対して以下のコマンドを使用できます。次に、以下のコマンドを実行して、nginx :
|
1 |
kubectl create deployment nginx --image=nginx |
Dockerイメージ名と関連するフラグ(ポートやボリュームなど)を変更する必要があります。わかりやすくするために、デプロイメントとサービスを使用してNginxをデプロイし、アプリケーションがクラスターにどのようにデプロイされるかを確認できます。
ある Kubernetes deployment は、アプリケーションに宣言的なアップデートを提供する Kubernetes のリソースオブジェクトです。デプロイメントを使用すると、コンテナイメージ、レプリカ、アップデート戦略など、アプリケーションのライフサイクルを記述できます。デプロイメントは、意図した数の Pod が常に実行され、利用可能であることを保証します。クラスターの稼働中に Pod がクラッシュした場合、再度起動されます。アップデートプロセスも完全に記録され、一時停止、継続、以前のバージョンへのロールバックのオプションとともにバージョン管理されます。Nginx という名前のデプロイメントを作成する上記のコマンドは、Docker レジストリの Nginx Docker イメージから 1 つのコンテナを持つ Pod をデプロイするのに役立ちます。
NodePort の設定
次に、作成する必要があるのは NodePort. NodePort は、クラスターのすべてのノードで開いているポートです。Kubernetes は、NodePort へのインバウンドトラフィックを、アプリケーションが別のノードで実行されている場合でも、サービスに透過的にルーティングします。このために、次のコマンドを使用して、アプリをパブリックに公開する Nginx という名前の NodePort リソースを作成できます。
|
1 |
kubectl expose deploy nginx --port 80 --target-port 80 --type NodePort |
サービスは、それらの Pod へのインターフェースを公開する役割を担うもう 1 つの Kubernetes オブジェクトであり、クラスター内から、または外部プロセスとサービス間のネットワークアクセスを可能にします。これは、Pod にアクセスするための単一の IP アドレスと DNS 名を提供する、Pod の上部にある抽象化として定義できます。サービスを使用すると、ロードバランシングの設定を非常に簡単に管理できます。
次のコマンドを実行します:
|
1 |
kubectl get services |
これにより、以下のようなテキストが出力されます:

出力を取得した後、Kubernetes は自動的に 30000 より大きいランダムなポートを割り当てると同時に、割り当てられたポートが他のサービスによってすでにバインドされていないことを確認します。上記の出力の 3 行目は、Nginx が実行されているポートを取得するのに役立ちます。
動作していることを確認するには、ローカルマシンのブラウザから http://worker_1_ip:nginx_port または http://worker_2_ip:nginx_port にアクセスしてください。Nginx のおなじみのウェルカムページが表示されます。
デプロイメントの削除
Nginx アプリケーションを削除する場合は、まずマスターノードから nginx サービスを削除する必要があります:
|
1 |
kubectl delete service nginx |
アプリケーションが最終的に削除されたことを確認するには、次のコマンドを実行する必要があります:
|
1 |
kubectl get services |
次の出力が表示されます:

その後、次のコマンドを使用してデプロイメントを削除する必要があります:
|
1 |
kubectl delete deployment nginx |
このコマンドを使用して、デプロイメントが最終的に削除されたかどうかを確認できます:
|
1 |
kubectl get deployments |
![]()
結論:
このチュートリアルは、Kubeadm と Ansible を使用して Ubuntu 18.04 上にクラスターを適切にセットアップするのに役立ちます。クラスターがセットアップされたので、独自のアプリケーションやサービスのデプロイを簡単に開始できます。
プロセスのガイドとなる詳細情報が含まれるリンクのリストは次のとおりです:
- アプリケーションの Docker 化 – このリンクには、Docker を使用してアプリケーションをロードする方法を説明する例が含まれています。PostgreSQL や CouchDB サービスの Docker 化などがあります。
- Pod の概要 – このリンクには、Pod の使用方法、Pod の機能、および Pod が他の Kubernetes オブジェクトとどのように関連しているかについての詳細が示されています。Pod は Kubernetes の重要な部分であるため、これらを理解することはタスクを成功させるのに役立ちます。
- デプロイメントの概要 – デプロイメントについて学ぶのに役立ちます。デプロイメントは、Pod と ReplicaSet に宣言的なアップデートを提供します。デプロイメントのアップデート、ロールオーバー、およびロールバックの方法を学びます。
- サービスの概要 -このリンクは、Kubernetes クラスターで頻繁に使用されるもう 1 つのオブジェクトであるサービスについて説明します。Kubernetes におけるサービスとは、Pod の論理的なセットと、それらにアクセスするためのポリシーを定義する抽象化です。ステートレスアプリケーションとステートフルアプリケーションの両方を実行するには、サービスの種類とそれらが持つオプションを理解することが不可欠です。
さらに、DockerやKubernetesに焦点を当てた他のチュートリアルも、こちらのブログでご覧いただけます。:
- Kubernetesについて知る
- Dockerリソースのクリーンアップ – イメージ、コンテナ、ボリューム
- CloudSigmaでDockerを実行する方法(CloudInitを使用)更新版
- CentOS 7へのDockerのインストールとセットアップ
- パブリッククラウド上のUbuntuでDockerをインストール&操作する方法
他にも、以下のような多くの重要な概念があります。例えば、ボリューム, Ingress、そしてSecretなどがあり、これらは本番アプリケーションをデプロイする際に使用できます。
快適なコンピューティングを!
コメント
コメントはまだありません。最初のコメントを投稿しましょう。