

ウェブスクレイピング、ウェブクローリング、ウェブハーベスティング、またはウェブデータ抽出は、インターネット上のウェブページからデータをマイニングする行為を指す同義語です。ウェブスクレイパーやウェブクローラーは、プログラムによってウェブページを巡回し、必要なデータを抽出するツールです。通常は大量のテキストデータであるこれらのデータは、分析目的、製品の理解、または特定のウェブページに対する好奇心を満たすために使用できます。
ウェブクローリングをどのように始めればよいか疑問に思っている方のために、シンプルなデータセットを使ってウェブスクレイピングの基本を紹介します。プログラミングの専門知識のレベルに関係なく、このチュートリアルを進めることができるはずです。実践的な例として、当社のCloudSigma blogを使用します。ブログページにあるチュートリアルに関する情報を取得してみます。このチュートリアルの結論を読む頃には、Python 3で作成された、ブログセクションの複数のページをクロールし、そのデータを画面に表示する、機能するウェブスクレイパーが完成しているはずです。
この基本的なウェブスクレイパーの作成で得た知識を活用して、それを拡張し、独自のウェブスクレイパーを作成できます。きっと楽しいはずです。始めましょう!
前提条件
これは実践的なチュートリアルであるため、スムーズに進めるには Python 3 のローカル開発環境が必要です。まず、UbuntuにPython 3をインストールし、ローカルプログラミング環境をセットアップする方法.
Scrapy
ウェブスクレイピングには2つのステップがあります。最初のステップはウェブページを見つけてダウンロードすること、2番目のステップはそれらのウェブページをクロールして情報を抽出することです。
多くのプログラミング言語で、ウェブスクレイパーをゼロから構築するために使用できる方法やライブラリは数多くあります。しかし、将来的にウェブスクレイパーが複雑になったり、異なる設定やパターンの複数のページを同時にクロールする必要が生じたりした場合、問題が発生する可能性があります。スクレイピングしたデータを CSV、XML、JSON などの異なるフォーマット間で変換する方法を考えるのは、かなり骨の折れる作業になるかもしれません。
ゼロから独自のウェブスクレイパーを構築することに挑戦したい人もいるかもしれませんが、車輪の再発明は避け、それらの問題をすべて処理してくれる既存のライブラリの上に構築する方が賢明です。このチュートリアルでは、ウェブスクレイパーを実装するために、Scrapy(Pythonライブラリ)とPython 3を使用します。Scrapyはオープンソースのツールであり、最も人気があり強力なPythonウェブスクレイピングライブラリの1つです。Scrapyは、すべてのスクレイパーが備えるべき一般的な機能の一部を処理するように構築されています。これにより、ウェブクローラーを実装したいときに、毎回車輪の再発明をする必要がなくなります。Scrapyを使用すると、スクレイパーの構築プロセスが簡単で楽しいものになります。
Scrapyは、一般にpip(Python Package Index)として知られるPyPiから入手できます。PyPiは、ほとんどのPythonパッケージをホストするコミュニティ所有のリポジトリです。ローカル開発環境にPython 3をインストールしてセットアップすると、pipもインストールされ、これを使用してPythonパッケージをインストールできます。
ステップ1:シンプルなウェブスクレイパーの構築方法
まず、Scrapyをインストールするには、次のコマンドを実行します:
|
1 |
pip install scrapy |
必要に応じて、ドキュメントページのScrapy公式インストール手順に従うこともできます。Scrapyのインストールに成功したら、任意の名前を使用してプロジェクト用のフォルダを作成します:
|
1 |
mkdir cloudsigma-crawler |
フォルダに移動し、コードのメインファイルを作成します。このファイルには、このチュートリアルのすべてのコードが保存されます:
|
1 |
touch main.py |
必要に応じて、上記のコマンドの代わりにテキストエディタやIDEを使用してファイルを作成することもできます。
次に、ファイルを開き、Scrapyを使用する基本的なスクレイパーの作成から始めましょう。Scrapyの基本的なスパイダークラスであるscrapy.Spiderを拡張するPythonクラスを作成します。このクラスには、以下で定義する2つの必須属性があります:
- name — スパイダーを識別するための文字列の名前(任意の名前を入力できます)。
- start_urls — クロール元のURLのリストを含む配列。まずは1つのURLから開始します。
開いたファイルに次のコードスニペットを追加して、基本的なスパイダーを作成します:
|
1 2 3 4 5 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] |
以下は、各行のコードの説明です:
最初の行はScrapyをインポートしており、これによりパッケージが提供するさまざまなクラスを使用できるようになります。
次の行では、Scrapyが提供するSpiderクラスを拡張し、CloudSigmaCrawlerというサブクラスを作成します。クラス(Spider)を拡張することで、そのクラスのプロパティにアクセスできるようになり、コード内で使用できるようになります。この場合、Spiderクラスには、URLを追跡し、ウェブページからデータを抽出する方法を定義するメソッドと動作が含まれています。ただし、どのURLを追跡すべきか、どのデータを抽出すべきかは認識していません。これを拡張することで、必要な情報をメソッドに提供できます。サブクラス化と拡張について詳しく知るには、以下を読み進めてください。オブジェクト指向プログラミングの原則.
CloudSigmaCrawlerでは、必要な属性を定義します。まず、スパイダーにcloudsigma_crawlerという名前を付けます。次に、開始する単一のURLを指定します:https://blog.cloudsigma.com/blog/。このURLを開くと、多くのチュートリアルの一部が含まれているCloudSigmaブログのページ1に移動します。
スクレイパーをテストする時間です。いくつかのオプションがあります。たとえば、IDEを使用している場合、PyCharm community edition(開発元:JetBrains)などには、クリックするだけでスクリプトを実行できるボタンが用意されているはずです。もう1つのオプションは、コマンドラインからPythonファイルを実行する一般的な方法に従うことです:python path/to/file.py、または py path/to/file.py。さらに別のオプションは、Scrapyのコマンドラインインターフェースです。Scrapyには、スクレイパーの起動を支援する独自のコマンドラインインターフェースが付属しています。スクレイパーを開始するには、次のコマンドを入力します:
|
1 |
scrapy runspider main.py |
インストールしたScrapyのライブラリバージョンによっては、以下のような出力が表示されるはずです:
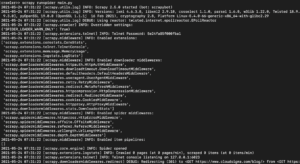
ご覧の通り、出力が非常に長いため、一部のみを抜粋しています。コマンドを実行したときに何が起こったのかは以下の通りです:
- スクレイパーが初期化されました。そのため、URLからのデータの追跡および読み取りに使用するために必要な追加のコンポーネントと拡張機能がロードされました。
- start_urlsリストに指定されたURLを使用して、ページからHTMLを取得しました。これは、ブラウザがウェブページを開くときに行うプロセスと同様です。
- HTMLを取得した後、まだ定義していないparseメソッドに渡されます。現時点では何もしないため、スパイダーは処理を行わずに終了します。次のステップでparseメソッドの動作を定義します。
ステップ 2:ページからデータを抽出する方法
ステップ1では、HTMLページを取得するだけで、その後は何もしない基本的なスクレイパーのみを実装しました。このセクションでは、データを抽出するための手順を説明します。CloudSigmaブログのページからデータを抽出したいのですが、そこでは以下のような点に気づくことができます:
- すべてのページに存在するヘッダー。
- ナビゲーションメニューと検索フィルターボックス。
- グリッド形式のチュートリアルの実際のリスト。
スクレイピングしようとしているHTMLページのソースコードを表示すると、ページの構造を大まかに把握できます。これはスクレイパーを作成するのに役立ちます。ページを右クリックして「ソースコードを表示」を選択するか、Ctrl + Uキーを押すことで、ソースコードを表示できます。以下はソースコードのスニペットです:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
<body> <div id="x-iso-container" class="x-iso-container x-iso-container-posts cols-3"> <article id="post-51691" class="post-51691 post type-post status-publish format-standard has-post-thumbnail hentry category-blog-posts category-tutorials tag-apache tag-certbot tag-cloud-guide tag-cloud-tutorial tag-https tag-lets-encrypt tag-ssl tag-ssl-certification tag-tutorial tag-ubuntu"> <div class="entry-wrap"> <header class="entry-header"> <h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title=""Ubuntu 18.04上のLet’s EncryptによるApacheの保護"へのパーマリンク">Ubuntu 18.04上のLet’s EncryptによるApacheの 保護</a> </h2> </header> <div class="entry-content excerpt"> <p>ウェブサイトとデータのセキュリティは、軽視できないトピックです。財務記録や 顧客の個人情報を含む非常に機密性の高い情報は、常にユーザーのコンピューターと ウェブサイトの間を移動しています。この事実を考慮すると、保護されていない ウェブサイトがビジネスに深刻な損害を与える可能性のある侵害につながる理由は容易に理解できます。そこには … </p> <div><a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="more-link">続きを読む</a></div> </div> </div> ... </article> </div> </body> |
ご覧のとおり、各ブログチュートリアルは<article>というHTMLタグで囲まれています。ページのスクレイピングは2つのステップで行われます。最初のステップは、必要なデータが含まれているページの部分を探して、各ブログチュートリアルを取得することです。次のステップは、HTMLタグで特定された各チュートリアルから必要なデータを抽出することです。
Scrapyは、指定されたセレクターに基づいて取得するデータを特定します。セレクターを使用すると、ページ上の1つ以上の要素を見つけ、その要素内のデータを取得できます。Scrapyは、XPath および CSS セレクターをサポートしています。
先ほど確認したソースから、CSSセレクターの方が簡単そうです。そのため、ページ上のすべてのチュートリアルを見つけるのに役立つこのオプションを採用します。HTMLソースコードから、各チュートリアルはpostというCSSクラス内で指定されています。CSSクラス名は通常、.class_name(ドット クラス名)で識別されます。したがって、CSSセレクターには.postを使用します。スクレイパーのソースコードmain.py内で、responseオブジェクトに.postクラスを渡します。これにより、ファイルは次のようになります。
|
1 2 3 4 5 6 7 8 9 10 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): pass |
このコードスニペットは、指定された start_urls を持つページ上のすべてのチュートリアルを取得し、チュートリアルをループしてデータを抽出します。次のステップでは、このデータを抽出して表示します。もう一度 CloudSigma blog のソースコードを確認すると、各チュートリアルのタイトルが <h2> タグ内にある <a> タグ内に保存されていることがわかります。例えば以下のようになります。
|
1 2 3 4 5 |
<h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Permalink to: "Securing Apache with Let’s Encrypt on Ubuntu 18.04"">Securing Apache with Let’s Encrypt on Ubuntu 18.04</a> </h2> |
ループ処理している各チュートリアルオブジェクトには、子要素を特定して抽出するためのセレクターを渡すことができるCSSメソッドが含まれています。この例では、<a> タグ内に囲まれているタイトルを抽出します。このタグは、.entry-wrap クラス内の .entry-header クラス内の <h2> タグの中にあります。これらのCSSセレクターをオブジェクトメソッドに渡してタイトルを抽出することができます。コードを以下のように修正してください。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), } |
extract_first() の後にある末尾のカンマは、このセクションの下にさらにコードを追加するため、タイプミスではありません。
上記のソースコードから注意すべきいくつかのポイントは以下の通りです。
- セレクターに追加された ::text – これは、CSS疑似セレクター であり、タグ自体ではなくタグ内のテキストを取得するようにコードに指示します。
- オブジェクト内の extract_first() メソッド呼び出し – セレクターに一致する最初の要素のみを取得するようにコードに指示します。そのため、要素のリストではなく文字列が取得されます。
次に、ファイルを保存し、ターミナルで次のコマンドを入力してコードを実行します。
|
1 |
scrapy runspider main.py |
出力には、チュートリアルのタイトルが表示されるはずです。
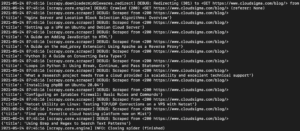
さらにセレクターを追加して、チュートリアルのURL、アイキャッチ画像、キャプションなど、チュートリアルに関する他の詳細情報を取得するように拡張していくことができます。
単一のチュートリアルのHTMLコードをもう一度確認してみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
<body> <div id="x-iso-container" class="x-iso-container x-iso-container-posts cols-3"> <article id="post-51691" class="post-51691 post type-post status-publish format-standard has-post-thumbnail hentry category-blog-posts category-tutorials tag-apache tag-certbot tag-cloud-guide tag-cloud-tutorial tag-https tag-lets-encrypt tag-ssl tag-ssl-certification tag-tutorial tag-ubuntu"> <div class="entry-featured"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="entry-thumb" title=""Ubuntu 18.04でLet’s Encryptを使用してApacheを保護する"へのパーマリンク"> <img width="1000" height="522" src="data:image/svg+xml,%3Csvg%20xmlns='http://www.w3.org/2000/svg'%20viewBox='0%200%201000%20522'%3E%3C/svg%3E" class="attachment-entry-fullwidth size-entry-fullwidth wp-post-image" alt="Let’s Encrypt" loading="lazy" data-lazy-srcset="/media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04.jpg 1000w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-300x157.jpg 300w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-768x401.jpg 768w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-610x318.jpg 610w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-100x52.jpg 100w" data-lazy-sizes="(max-width: 1000px) 100vw, 1000px" data-lazy-src="/media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04.jpg"/> </a> </div> <div class="entry-wrap"> <header class="entry-header"> <h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title=""Ubuntu 18.04でLet’s Encryptを使用してApacheを保護する" へのパーマリンク">保護する Ubuntu 18.04でのLet's EncryptによるApache</a> </h2> </header> <div class="entry-content excerpt"> <p>ウェブサイトとデータのセキュリティは、軽視できないトピックです。以下を含む非常に機密性の高い情報は、 財務記録や顧客の個人情報を含み、常にユーザーのコンピュータと ウェブサイトの間を行き来しています。この事実を考慮すると、保護されていない ウェブサイトが、ビジネスに深刻な損害を与える可能性のある侵害につながる理由は容易に理解できます。そこにはいくつかの … </p> <div><a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="more-link">続きを読む</a></div> </div> </div> </article> </div> </body> |
ハイライトされた部分、つまりチュートリアルのURL、アイキャッチ画像、およびキャプションを抽出してみましょう。
- 上記のコードスニペットから、ブログの画像は、ブログチュートリアルの開始部分にあるdivタグ内の<a>タグ内のimgタグのdata-lazy-src属性に保存されています。チュートリアルのタイトルで行ったように、CSSセレクターを使用して値を取得できます。
- <div>要素の中に<a>タグがあるため、チュートリアルのURLの取得は簡単です。
- キャプションは、<div>タグ内にある<p>タグの中に囲まれています。
必要な情報を取得するためにCSSクラスを使用します。コードを以下のように修正しましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), 'caption': tutorial.css(CAPTION_SELECTOR).extract_first(), } |
変更を保存し、次のコマンドでコードを実行します。
|
1 |
scrapy runspider main.py |
出力には、追加したURL、画像、キャプションなど、より多くのデータが表示されます。

単一ページのクロールは以上です。次に、リンクをたどるスクレイパーを作成する方法を見てみましょう。
ステップ 3: 複数のページをクロールする方法
ここまでは、単一のページからデータを取得できるスクレイパーを作成しました。しかし、それだけでは不十分です。プログラムによってリンクをたどり、ウェブサイトの複数ページからデータを抽出できるスパイダーが必要です。
CloudSigmaのブログページの下部に移動すると、ページネーションリンクと、次のページを示す右向きの小さな矢印があることに気づくでしょう。以下はHTMLコードのスニペットです。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<div class="x-pagination"> <ul class="center-list center-text"> <li><span class="pages">45ページ中1ページ</span></li> <li></li> <li><span class="current">1</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/2/" class="single_page" title="2">2</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="single_page" title="3">3</a></li> <li><span class="expand">...</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/45/" class="last" title="最後のページ">45</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/2/" class="prev-next hidden-phone">→</a></li> </ul> </div> |
このスニペットは、.x-pagination CSSクラスを持つ<div>タグの下にある、<li>タグ内のいくつかのページナビゲーションリンクを示しています。私たちが注目するのは、次のページを指すリンクです。これは、<ul>タグ内の最後の<li>の<a>タグにあります。
上のスニペットに見られるように、次のページを指すリンクは<a>タグ内に.prev-nextクラスを持っています。しかし、次のページに移動すると、前後のページへのリンクもこのCSSクラスを持っていることに気づくでしょう。ページ2のこのスニペットを考えてみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<div class="x-pagination"> <ul class="center-list center-text"> <li><span class="pages">45ページ中2ページ</span></li> <li><a href="https://blog.cloudsigma.com/blog/" class="prev-next hidden-phone">←</a></li> <li><a href="https://blog.cloudsigma.com/blog/" class="single_page" title="1">1</a></li> <li><span class="current">2</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="single_page" title="3">3</a></li> <li><span class="expand">...</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/45/" class="last" title="最後のページ">45</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="prev-next hidden-phone">→</a></li> </ul> </div> |
Scrapyの extract_first() メソッドを使用すると、最初のページでは機能します。次のページに到達すると、上記のコードスニペットで最初のページを指している .prev-next クラスを持つ最初のリンクが選択されます。これによりループが発生します。そのため、Scrapyの extract() メソッドを使用します。このメソッドは、ユースケースに一致するすべての要素を抽出し、配列に格納します。この配列から、次のページを指す実際のリンクを含む最後の要素を選択できます。コードを以下のように修正してください:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), } NEXT_PAGE_SELECTOR = '.x-pagination > ul.center-list > li > a.prev-next::attr("href")' next_page = response.css(NEXT_PAGE_SELECTOR).extract() if next_page: yield scrapy.Request( response.urljoin(next_page[-1]), callback=self.parse ) |
next_pageの選択に関するコードを見ていきましょう。
まず、次へおよび前へのページリンクのセレクターを定義します。次に、extract()メソッドを使用してURLを抽出し、配列に格納します。next_page変数は、以下のように2つの要素を持つ配列になります。
|
1 |
next_page = [prev_page_url, next_page_url] |
次のページに移動するため、配列の最後の要素を取得します。next_page[-1]は配列の最後の要素を取得します。
ifブロックは、next_page変数に値があるかどうかを確認し、値がある場合はscrapy.Request()メソッドを呼び出します。このコードでは、提供されたURLのページをクロールし、それをparse()メソッドに渡してデータを抽出するために解析し、次のページでも同じプロセスを繰り返すようにこのメソッドに指示しています。このプロセスは、次のページへのリンクが見つからなくなるまで、あるいはブロックが失敗して停止するまで繰り返されます。
コードを保存して実行します。スクレイピングするページがさらに見つかるにつれて、反復処理がページをループし続けることがわかります。これが、Webサイト上のリンクをたどるスクレイパーの定義方法です。この例は非常にシンプルです。ページに移動し、次のページへのリンクを見つけ、そのプロセスを繰り返すだけです。他のユースケースでは、外部ソースなどを指すタグやリンクをたどりたい場合もあるでしょう。以下は、Python 3の基本的なWebスクレイパーの完成したソースコードです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), 'caption': tutorial.css(CAPTION_SELECTOR).extract_first(), } NEXT_PAGE_SELECTOR = '.x-pagination > ul.center-list > li > a.prev-next::attr("href")' next_page = response.css(NEXT_PAGE_SELECTOR).extract() if next_page: yield scrapy.Request( response.urljoin(next_page[-1]), callback=self.parse ) |
結論
このチュートリアルでは、CloudSigmaブログのディレクトリをクロールし、ブログのチュートリアルに関するいくつかの情報をわずか約27行のコードで表示できる、基本的なウェブスクレイパーを構築しました。
もちろん、これが可能なのは、Scrapy Pythonライブラリの上に構築したためです。これは、より多くのタグやウェブサイトの検索結果などを追跡する、より複雑なスクレイパーを構築するのに役立つ基礎にすぎません。詳細については、Scrapyの公式ドキュメントを参照して、Scrapyの操作に関する詳細情報を確認してください。
ハッピーコンピューティング!
コメント
コメントはまだありません。最初のコメントを投稿しましょう。