

The grep komutu, metin içindeki kalıpları aramak için güçlü bir yardımcı programdır. Herhangi bir Linux dağıtımında önceden yüklü olarak gelir. İşte LAMP Yığınını - Linux, Apache, MySQL ve PHP - kurmayı ele alan kılavuzumuz.
grep adı, global regular expression print (küresel düzenli ifade yazdırma) anlamına gelir. Araç, girdide belirtilen kalıbı arar. Prensipte bu önemsiz gibi görünür. Ancak asıl gücü, kalıbı nasıl tanımladığınızda yatar. Bu kılavuz, karmaşık aramalar gerçekleştirmek için grep'in düzenli ifadelerle nasıl kullanılacağını ayrıntılı olarak açıklamaktadır. Hadi başlayalım!
Grep Nasıl Kullanılır
grep komutu tek başına karmaşık değildir. Tek gerektirdiği, aramanın yapılacağı kalıp ve içeriktir. grep komutunun temel yapısı şu şekildedir:
|
1 |
grep <regex> <file> |
Metin arama
İlk olarak, işlemi gerçekleştirmek için örnek bir dosya alın. GNU General Public License v3.0 (metin biçiminde) indirin. Çok sayıda kelime ve kelime öbeği içeren oldukça büyük bir metin dosyasıdır. Eğer Ubuntu kullanıyorsanız, bunu aşağıdaki dosyada bulabilirsiniz. Hızlı ve kolay bir Ubuntu kurulumu için kılavuzumuzu takip edin.
|
1 |
curl -o gpl.txt https://www.gnu.org/licenses/gpl-3.0.txt |

Ardından, grep kullanarak temel bir metin araması gerçekleştirebilirsiniz:
|
1 |
grep <pattern> <text_file> |
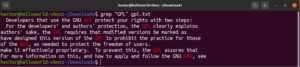
Bir komutun çıktısını grep'e yönlendirmek (pipe) mümkündür:
|
1 |
cat gpl.txt | grep <pattern> |
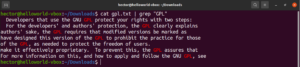
Büyük/küçük harf duyarlılığı
Varsayılan olarak grep, büyük/küçük harfe duyarlı davranır. Birçok durumda, büyük/küçük harf duyarlılığını göz ardı etmek en iyisi olabilir. Büyük/küçük harfe duyarlı aramayı devre dışı bırakmak için “-i” veya “–ignore-case” bayrağını kullanın:
|
1 2 3 |
$ grep -i <pattern> <file> $ grep --ignore-case <pattern> <flag> |
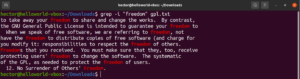
Tersine eşleştirme
Varsayılan olarak grep davranışı, kalıbın bulunduğu satırları yazdırmaktır. Tersine eşleştirme (invert match), kalıpla eşleşen satırları görmek istemediğiniz durumları ifade eder. Tersine eşleştirme yapmak için “-v” veya “–invert-match” bayrağını kullanmanız gerekir:
|
1 2 3 |
$ grep -v <pattern> <file> $ grep --invert-match <pattern> <file> |
Satır numarası
Çok büyük bir dosyada grep çalıştırırken, arama sonucunun konumunu takip etmek zordur. İşleri kolaylaştırmak için grep, satır numarasını gösterme özelliğine sahiptir. Satır numaralandırmayı etkinleştirmek için “-n” veya “–line-number” bayrağını kullanın:
|
1 2 3 |
grep -n <pattern> <file> grep --line-number <pattern> <file> |
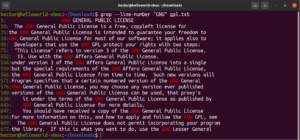
Birden fazla grep bağımsız değişkenini birleştirmek mümkündür. Aşağıdaki grep komutu, satır numaralarını yazdırırken tersine eşleştirme gerçekleştirecektir:
|
1 |
grep -nv <pattern> <file> |
Düzenli ifade
Bu kılavuzun başında, grep'in global regular expression print anlamına geldiğinden bahsetmiştik. “düzenli ifade” terimi, arama kalıbını tanımlayan özel bir dize olarak tanımlanır. Düzenli ifadenin kendine özgü bir yapısı ve kuralları vardır.
Arama ve değiştirme işlemlerini gerçekleştirmek için düzenli ifadeleri (kısaca regex) kullanan çok sayıda dize arama algoritması ve aracı vardır. Popüler olmasına rağmen, farklı uygulamalar ve programlama dilleri regex'i biraz farklı şekilde uygular. Bu bölümde, grep kullanan birkaç regex yöntemini göstereceğiz.
Birebir eşleşme
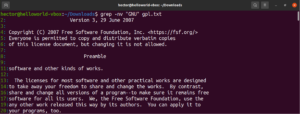
Önceki grep örneklerinde grep, verilen metin dosyasında belirli bir dizeyi aramıştı. Grep aslında en temel düzenli ifadeyi kullanarak arama yapıyordu. Belirli bir dizenin tam eşleşmesini aramayı tanımlayan regex kalıplarına “literaller” denir. Bu isim, kalıpla karakter karakter, birebir eşleşmelerinden gelir.
Birebir eşleşme, alfabetik ve sayısal karakterlerin (ve bazı özel karakterlerin) yanı sıra çalışır. Ancak, diğer ifade mekanizmalarına bağlı olarak bu davranış değişebilir:
|
1 |
grep "<string>" <file> |
Çapa eşleşmesi
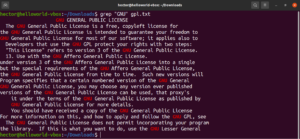
Çapalar, geçerli bir eşleşme elde etmek için eşleşmenin satırdaki konumunun nerede olması gerektiğini tanımlayan özel karakterlerdir. Bunu basitleştirmek için hızlı bir örnek verelim. Yalnızca “GNU” dizesiyle başlayan satırları bulmak istiyorsak, düzenli ifade (regex) içeren grep şu şekilde görünecektir. Burada “^” karakteri, yalnızca satırın başındaki eşleşmelerin geçerli olduğunu tanımlayan çapadır:
|
1 |
grep -n "^GNU" <file> |

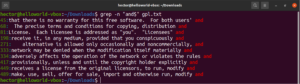
Benzer şekilde, yalnızca “works” dizesiyle biten satırları bulmak istiyorsak, regex içeren grep şu şekilde görünecektir. Burada “$” karakteri, yalnızca satırın sonundaki eşleşmelerin geçerli olduğunu tanımlayan çapadır:
|
1 |
grep -n "and$" <file> |
Herhangi bir karakter eşleşmesi
Bir metin araması yaparken, belirli bir yerde herhangi bir karakterin bulunabileceğini tanımlamak isteyebilirsiniz. Regex'te bu, nokta karakteri (.) ile ifade edilir.
Bu örneğe bir göz atın. GNU GPL 3 metin dosyasında, “accept” ve “except” kelimelerinin her ikisinde de ortak olarak “cept” bölümü bulunur. Dahası, her iki kelimenin de “cept” bölümünden önce iki karakteri vardır. Aşağıdaki grep komutu, “cept” bölümünden önce iki karakteri olan herhangi bir kelimeyle eşleşecektir:
|
1 |
grep -n "..cept" <file> |
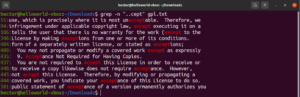
Bu regex'e göre, suscept, unaccept, unexpected vb. diğer kelimeler de geçerli eşleşmelerdir.
Köşeli Parantezler
Regex'te köşeli parantez ifadeleri, belirtilen konumda, parantez içinde bildirilen herhangi bir karakterin bulunabileceğini tanımlar. Aşağıdaki düzenli ifade dizesine bir göz atın:
|
1 |
t[wo]o |
Uygulamaya koyulduğunda, too ve two kelimeleri geçerli eşleşmeler olacaktır:
|
1 |
grep -n "t[wo]o" <file> |
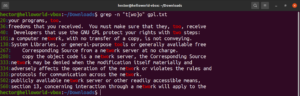
Köşeli parantez ifadesi bazı ilginç olasılıkların önünü açar. Belirtilen konumda, parantez içinde bildirilenler dışındaki herhangi bir karakterin bulunabileceğini belirtmek için köşeli parantez ifadelerini kullanmak mümkündür. Aşağıdaki regex dizesine bir göz atın. Eşleşme, yalnızca “ode” kelimesinden önce “c” dışında herhangi bir karakter varsa geçerli olacaktır:
|
1 |
"[^c]ode" |
Bunu GPL-3 lisans metni dosyasında çalıştırın:
|
1 |
grep -n "[^c]ode" <file> |

Dosyadan elde edilen sonucun yanı sıra, diğer geçerli sonuçlar node, abode, anode vb. olacaktır. Köşeli parantez ifadeleri bir karakter aralığını da tanımlayabilir. Aşağıdaki regex, satırın başlangıcı büyük harf bir karakter ise eşleşmenin geçerli olduğunu belirtir:
|
1 |
"^[A-Z]" |
Bunu GPL-3 lisans metni dosyasında çalıştırın. Metin dosyasındaki tüm satırlar listelenecektir:
|
1 |
grep -n "^[A-Z]" <file> |
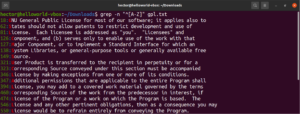
Kullanım kolaylığı için, belirli etiketlere sahip bazı karakter sınıfları vardır. Önceki örnekte, büyük harf karakterleri tanımlamak için “A-Z” aralığını kullanmıştık. Bunun yerine “[:upper:]” ifadesini de kullanabiliriz. Sonuç aynı olacaktır:
|
1 |
grep -n "^[[:upper:]]" <file> |
Bir deseni tekrarlama
Belirli durumlarda, belirli bir deseni veya regex'i sıfır veya daha fazla kez eşleştirmek isteyebilirsiniz. Bunu yapmak için kullanılan meta karakter yıldız işaretidir (*). Aşağıdaki düzenli ifade, aralarında yalnızca harfler ve tek boşluklar bulunan tüm parantezleri eşleştirecektir. Küçük harf, büyük harf karakter kümelerinin ve boşlukların bildiriminin herhangi bir noktalama işareti olmaksızın bir arada olduğuna dikkat edin:
|
1 |
"([a-zA-Z ]*)" |
Regex'i grep ile uygulamaya koyun:
|
1 |
grep -n "([A-Za-z ]*)" <file> |

Meta karakterleri düz karakter olarak kullanma
Şimdiye kadar yıldız (*), nokta (.), çıpalar (^ ve $) vb. gibi çeşitli meta karakterlerle tanıştık. Bunların her biri regex bağlamında benzersiz bir işlevi belirtir. Sorun, bunların meta karakter olarak değil, düz metin (literal) olarak kullanılması gerektiğinde ortaya çıkar. Bu gibi durumlarda, meta karakterin önündeki ters eğik çizgi (\), onun meta karakter olarak değil, düz metin anlamında kullanılacağını belirtir. Bu regex örneğine bir göz atın. Büyük harfle başlayan ve nokta ile biten tüm satırları eşleştirecektir:
|
1 |
grep -n "^[A-Z].*\.$" <file> |
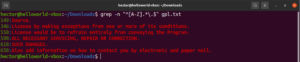
Alternasyon
Köşeli parantez ifadelerini kullanarak, tek bir karakter eşleşmesi için farklı olası seçenekler belirtebiliriz. Regex, aynı şeyi kelimeler ve ifadelerle de yapma özelliğine sahiptir. Bir alternasyonu belirtmek için dikey çizgi karakteri (|) kullanılır. Seçenekler parantez içinde kalırken, dikey çizgi karakteri bunları birbirinden ayırır. Eşleşmenin geçerli olması için iki veya daha fazla olası seçenek olabilir. Aşağıdaki regex örneğine göz atın. Hem “GPL” hem de “General Public License” ifadelerini eşleştirecektir:
|
1 |
grep -nE "(GPL|General Public License)" <file> |
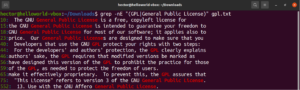
Niceleyiciler
Yıldız (*) meta karakterini kullanarak, bir kalıbı sıfır veya daha fazla kez tekrarlanacak şekilde tanımlayabiliyorduk. Ancak, çalışacak daha çok şey var. Niceleyicileri bir örnekle açıklamak daha kolaydır. Aşağıdaki düzenli ifade, hem “copyright” hem de “right” kelimelerinin geçerli eşleşmeler olduğunu tanımlar. Soru işareti (?), “copy” kısmının eşleşme için isteğe bağlı olduğunu belirtir:
|
1 |
grep -nE "(copy)?right" <file> |
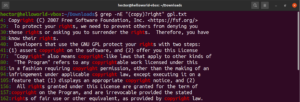
Bir sonraki niceleyici artı sembolüdür (+). Yıldız işaretine benzer şekilde davranır. Ancak, tanımlanan kalıbın en az bir kez eşleşmesi gerekir. Aşağıdaki örnekte, düzenli ifade “soft” kelimesini bir veya daha fazla boşluk dışı karakterle eşleştirecektir:
|
1 |
grep -nE "soft[^[:space:]]+" <file> |
Eşleşme tekrarını belirtme
Bir eşleşmenin kaç kez tekrarlanacağını belirtmek mümkündür. Bunu yapmak için süslü parantezleri ({}) kullanın. Aşağıdaki düzenli ifade, en az üç sesli harf içeren herhangi bir kelimeyi eşleştirecektir:
|
1 |
grep -nE "[aeiouAEIOU]{3}" <file> |

Bu özellik ayrıca eşleşme uzunluğunun alt sınırını ve üst sınırını tanımlamanıza da olanak tanır. Aşağıdaki örnekte, regex 10-15 karakter uzunluğundaki herhangi bir kelimeyle eşleşecektir:
|
1 |
grep -nE "[[:alpha:]]{10,15}" <file> |
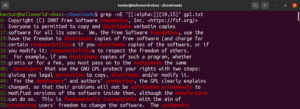
Sonuç
Metin dosyalarını grep ile aramak oldukça kullanışlıdır. Düzenli ifadeler, grep ile aramayı daha ilginç ve yararlı hale getirir. Ayrıca arama kalıbını tam istediğiniz gibi ince ayarlamanıza olanak tanır.
Bazı yaygın düzenli ifadeleri göstermiş olsak da, bu sadece başlangıçtır. Arama davranışı üzerinde en hassas kontrolü sunan daha gelişmiş düzenli ifadeler de mevcuttur. Grep'in yanı sıra, düzenli ifadeler diğer araçlar ve programlama dilleri tarafından da yaygın olarak kullanılmaktadır.
Keyifli kodlamalar!
Yorumlar
Henüz yorum yapılmamış. İlk siz olun.