
Bir CSV dosyası, verileri tablo biçiminde saklayan düz bir metin dosyasıdır. Çoğu durumda, CSV dosyaları sınırlayıcı olarak virgül (,) kullanır, bu nedenle adı CSV (Virgülle Ayrılmış Değerler) olarak geçer. CSV’ler herhangi bir metin düzenleyici, elektronik tablo uygulamaları ve diğer özel araçlarla açılabildiğinden, veri uyumluluğunun önemli olduğu durumlarda kullanılır. Aslında birçok programlama dili CSV için yerleşik destek sunar.
Bu kılavuzda, örnek bir Node.js uygulamasında CSV kullanmayı öğreneceğiz.
Node.js'de CSV
Node.js, açık kaynaklı ve platformlar arası bir JavaScript çalışma ortamıdır. Tüm internet genelinde sayısız web hizmetine güç veren en popüler arka uçlardan biri haline gelmiştir. Netflix ve Uber gibi büyük şirketler bile hizmetlerine güç sağlamak için Node.js kullanmaktadır.
Node.js ayrıca bir projeye ekstra işlevsellik eklemek için dağıtılabilecek çok sayıda modüle sahiptir. CSV söz konusu olduğunda, kullanılabilecek birçok modül mevcuttur, örneğin, node-csv, fast-csv, ve papaparse vb.
Kılavuzun başlığından da anlaşılacağı gibi, node-csv kullanarak Node.js akışları (streams) ile CSV dosyalarını okuyacağız. Ayrıca ayrıştırılan verilerle çalışmayı, örneğin verileri bir SQLite veritabanına aktarmayı göstereceğiz.
Önkoşullar
-
Bu kılavuzda gösterilen adımları gerçekleştirmek için aşağıdaki bileşenlere ihtiyacınız olacak:
-
Düzgün yapılandırılmış bir Linux sistemi. Şunun hakkında daha fazla bilgi edinin: CloudSigma üzerinde bir Ubuntu bulut sunucusu kurma ve yapılandırma.
-
yetkisine sahip root olmayan bir kullanıcıya erişim: sudo yetkisi. Şuna göz atın: sudoers ile sudo iznini yönetme.
-
Uygun bir metin düzenleyici, örneğin, Brackets, VS Code, Sublime Text, Vim/NeoVim, vb.
-
Diğer yazılımlar:
-
Node.js LTS
-
SQLite
-
Adım 1 – Gerekli Yazılımların Kurulması
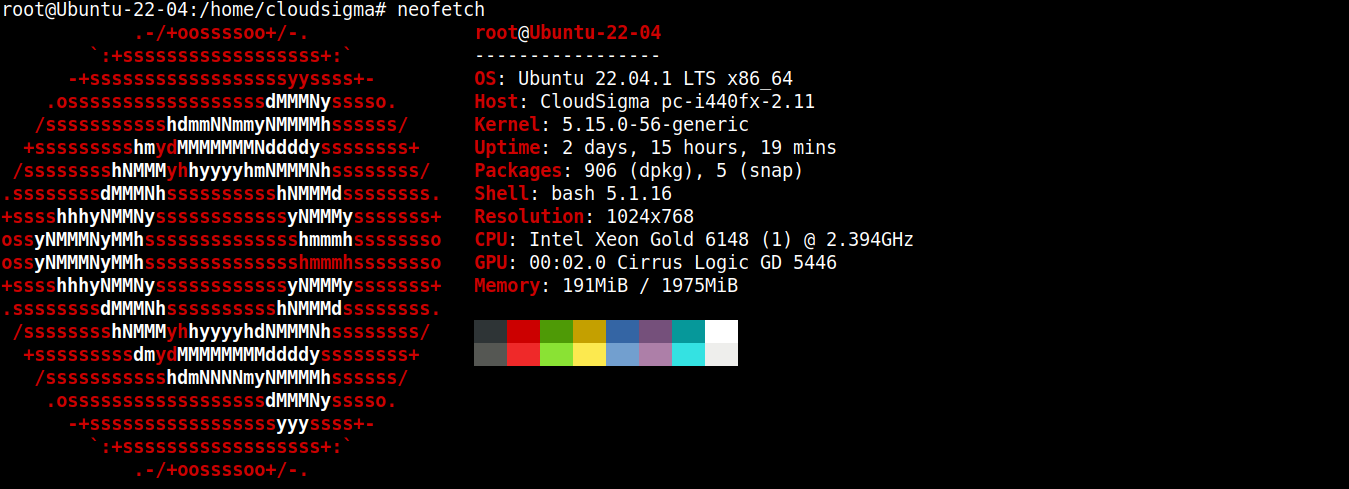
Bu kılavuz için Ubuntu 22.04 LTS çalıştıran hafif bir sunucu oluşturdum (SSH üzerinden bağlı):
Şimdi, üzerine Node.js ve SQLite kuracağız.
-
Node.js LTS Kurulumu
Node.js doğrudan resmi Ubuntu paket depolarından edinilebilir. Ancak güncel sürüm değildir. Bu nedenle, en son Node.js paketlerini almak için üçüncü taraf bir depoya (Nodesource) başvuracağız.
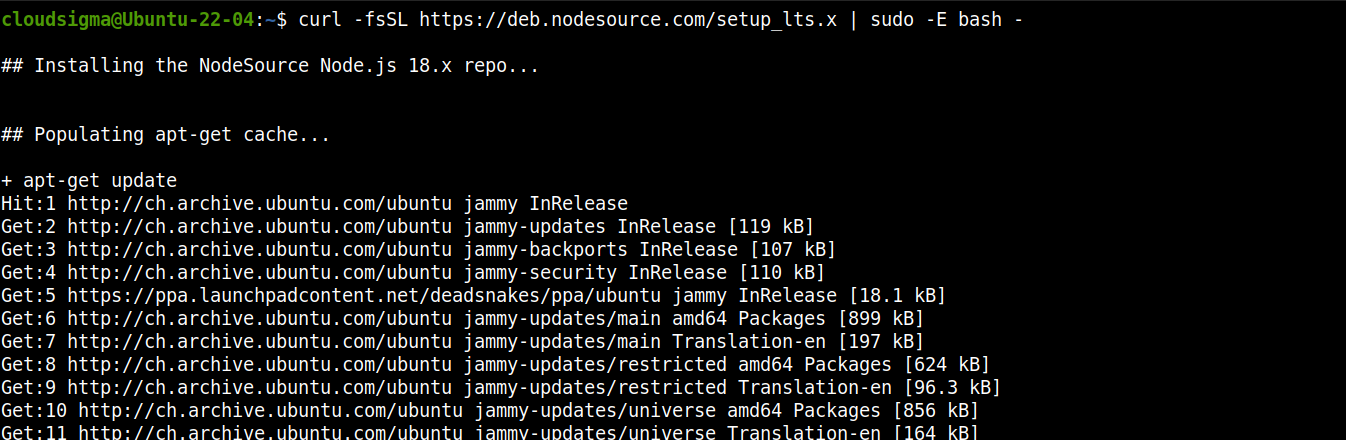
Node.js LTS için depoyu ekleyin:
|
1 |
curl -fsSL https://deb.nodesource.com/setup_lts.x | sudo -E bash - |
Şimdi, Node.js LTS'yi kurun:
|
1 |
sudo apt install nodejs -y |

-
SQLite Kurulumu
SQLite'ı doğrudan Ubuntu paket depolarından kuracağız. Aşağıdaki komutları çalıştırın:
|
1 |
sudo apt install sqlite3 -y |

Adım 2 – Proje Dizini Kurulumu
Bu bölümde projemiz için özel bir dizin hazırlayacağız. Ek modüllerle birlikte tüm proje dosyalarını barındıracaktır.
Yeni bir dizin oluşturun:
|
1 |
mkdir -pv csv_practice |
Dizine gidin:
|
1 |
cd csv_practice/ |
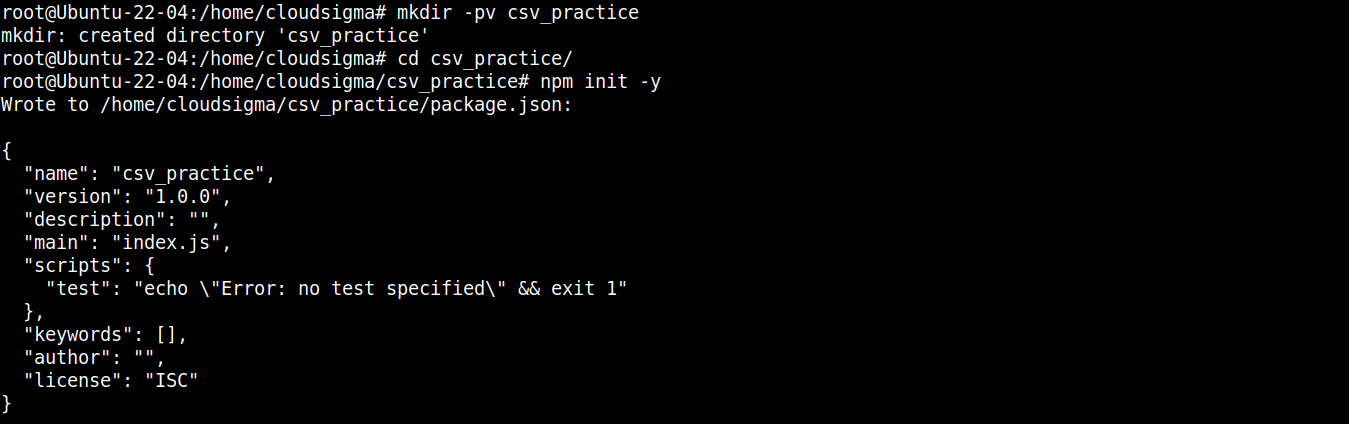
Ardından, dizini bir npm projesi olarak bildirmek için aşağıdaki komutu çalıştırın:
|
1 |
npm init -y |
Proje klasörü başlatıldıktan sonra, gerekli paketleri ve modülleri kurmaya başlayabiliriz. İlk olarak, node-csv:
|
1 |
npm install csv |

node-csv modülü aslında diğer birkaç modülün birleşimidir: csv-generate, csv-parse (CSV dosyalarını ayrıştırma), csv-stringify (CSV'ye veri yazma) ve stream-transform.
Ardından, SQLite ile iletişim kurmak için gereken modüle ihtiyacımız var. Aşağıdaki komut şu modülü kuracaktır: node-sqlite3 modülü:
|
1 |
npm install sqlite3 |

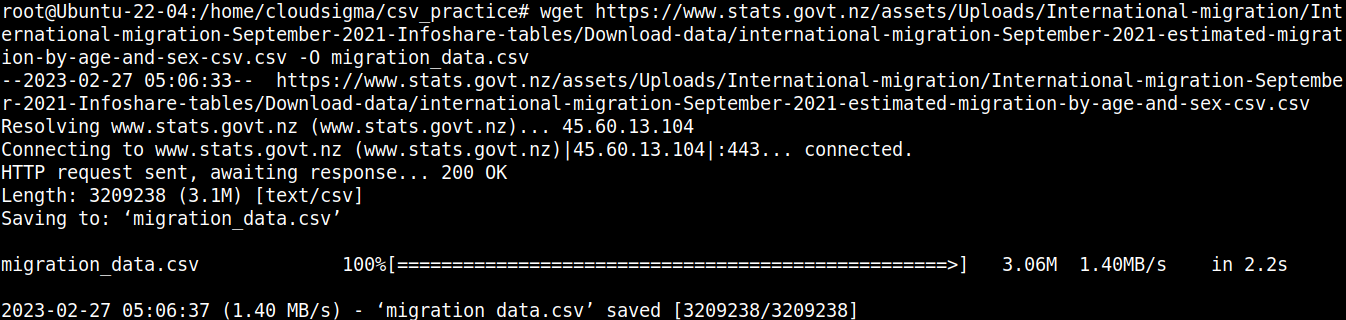
Projemiz için ihtiyacımız olan bileşen bir CSV dosyasıdır. Gösterim amacıyla, Yeni Zelanda göç CSV dosyasını kullanacağız:
|
1 |
wget https://www.stats.govt.nz/assets/Uploads/International-migration/International-migration-September-2021-Infoshare-tables/Download-data/international-migration-September-2021-estimated-migration-by-age-and-sex-csv.csv -O migration_data.csv |
Dosyanın içeriğine hızlıca bir göz atalım:
|
1 |
cat migration_data.csv | less |
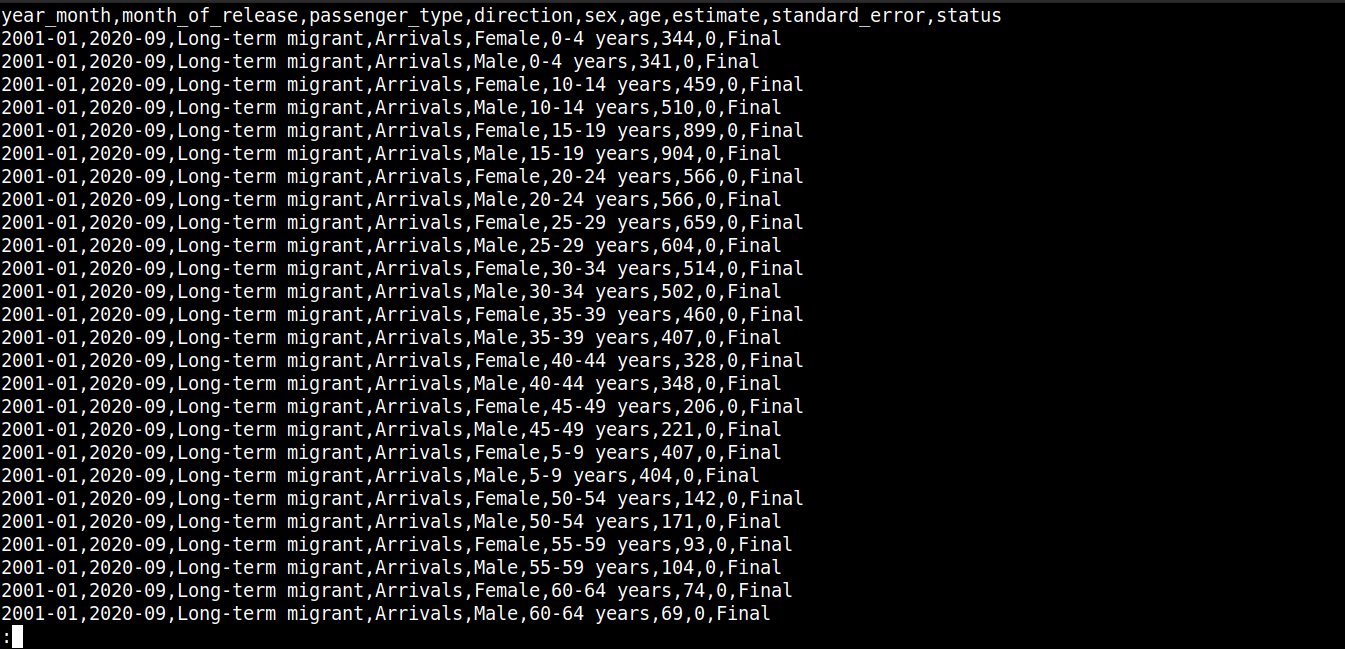
Burada,
-
İlk satır sütun adlarını tanımlar.
-
Sonraki satırlar bu alanların değerlerini içerir.
-
Her satır yeni bir satırla (\n) ayrılır.
-
Her veri noktası bir virgülle (,) ayrılır.
Ancak CSV, sınırlayıcı olarak yalnızca virgül kullanmakla sınırlı değildir. Diğer yaygın sınırlayıcılar arasında iki nokta üst üste (:), noktalı virgül (;) ve sekmeler (\td) bulunur.
Adım 3 – CSV Okuma
Bu bölümde, CSV dosyasındaki verileri okuyan ve ayrıştıran örnek bir programın uygulanmasını göstereceğiz.
Yeni bir JavaScript dosyası oluşturun:
|
1 |
touch read_csv.js |
Dosyayı favori metin düzenleyicinizde açın:
|
1 |
nano read_csv.js |
İlk olarak, fs ve csv-parse modüllerini içe aktaracağız:
|
1 2 |
const fs = require("fs"); const { parse } = require("csv-parse"); |
Burada,
-
İlk olarak, fs değişkenine, modül içe aktarıldığında Node.js fs nesnesini döndüren require() yöntemi atanır.
-
Ardından, parse yöntemi, require() yöntemi tarafından döndürülen nesneden, destructuring sözdizimi kullanılarak parse değişkenine çıkarılır.
Ardından, CSV dosyasını okumak için kodlar ekleyeceğiz:
|
1 2 3 4 5 |
fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) |
Burada,
-
fs modülünden createReadStream() yöntemini çağırıyoruz ve okumak istediğimiz CSV dosyasını argüman olarak iletiyoruz. Bu yöntem, büyük dosyayı daha küçük parçalara bölerek okunabilir bir akış oluşturur.
-
Akışı oluşturduktan sonra, pipe() yöntemi, akış verilerinin parçalarını başka bir akışa iletir. Bu yeni akış, parse() yönteminin csv-modülünden çağrılmasıyla oluşturulur.
-
The csv-modülü, bir veri parçasını alan ve onu başka bir forma dönüştüren okunabilir/yazılabilir bir dönüştürme (transform) akışı dağıtır.
-
The parse() yöntemi, özelliklere sahip nesneleri kabul eder. Nesne, ayrıştırılan verileri daha fazla işler. Burada nesne aşağıdaki özellikleri almaktadır:
-
delimiter: Değerleri ayırmak için kullanılacak sınırlayıcı karakter. Hedef CSV'miz durumunda bu virgüldür (,).
-
from_line: Ayrıştırıcının ayrıştırmaya başlayacağı satır sayısı. Verilen 2 değeriyle, ayrıştırıcı 1. satırı atlayacak ve 2. satırdan başlayacaktır. Bu düzenlemeyle, sütun adlarının ayrıştırılmış verilere dahil edilmesini önlemiş oluyoruz.
-
Ardından, Node.js'deki on() yöntemini kullanarak bir akış olayı ekleyeceğiz:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) .on("end", function () { console.log("finished"); }) .on("error", function (error) { console.log(error.message); }); |
Burada,
-
Belirli bir olay yayınlandığında, bir akış olayı bir yöntemin bir veri parçasını tüketmesine olanak tanır.
-
When data parsed by parse() yöntemi tarafından ayrıştırılan veriler tüketilmeye hazır olduğunda, data olayını tetikler.
-
Verilere erişmek için, on() yöntemine bir row parametresi alan geri arama (callback) işlevi iletiyoruz.
-
row parametresi, bir dizi biçimindeki bir veri parçasıdır (ayrıştırma sonucu).
-
Son olarak, veriler console.log kullanılarak konsola kaydedilir.().
Programı tamamlamak için, hataları işlemek ve CSV dosyasındaki tüm veriler tüketildiğinde bir başarı mesajı yazdırmak üzere ek akış olayları ekleyeceğiz. Kodu aşağıdaki gibi güncelleyin:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) .on("end", function () { console.log("tamamlandı"); }) .on("error", function (error) { console.log(error.message); }); |
Burada,
-
end olayı, CSV dosyasındaki tüm veriler tüketildiğinde tetiklenir. Bu, console.log() yönteminin çağrılmasıyla sonuçlanır ve bir başarı mesajı yazdırır.
-
error olayı, CSV verileri ayrıştırılırken bir hatayla karşılaşıldığında tetiklenir. Bu, console.log() yönteminin çağrılmasıyla sonuçlanır ve bir hata mesajı yazdırır.
Nihai kod şu şekilde görünmelidir:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
const fs = require("fs"); const { parse } = require("csv-parse"); fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) .on("end", function () { console.log("tamamlandı"); }) .on("error", function (error) { console.log(error.message); }); |
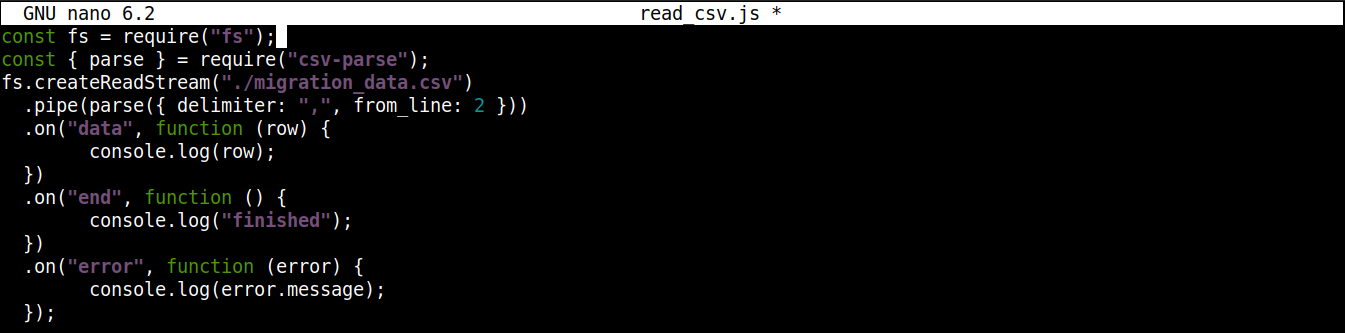
Dosyayı kaydedin ve düzenleyiciyi kapatın. Artık programı yürütmeye hazırız. Node.js kullanarak çalıştırın:
|
1 |
node read_csv.js |
Çıktı şuna benzer görünmelidir:

Verilerin tüketildiğini, dönüştürüldüğünü ve konsola yazdırıldığını unutmayın. Bu sürekli bir işlem olduğundan, çıktının tamamını tek seferde yazdırmak yerine veriler indiriliyormuş gibi görünecektir.
Adım 4 – CSV Verilerini Bir Veritabanına Aktarma
Şimdiye kadar, node-csv kullanarak bir CSV dosyasını nasıl ayrıştıracağımızı öğrendik. Bu bölüm, ayrıştırılan verilerin bir veritabanına (SQLite) aktarılmasını gösterecektir.
Veritabanıyla etkileşim kurmak için yeni bir JavaScript dosyası oluşturun:
|
1 |
touch csv-to-sqlite3.js |
Şimdi, dosyayı bir metin düzenleyicide açın:
|
1 |
nano csv-to-sqlite3.js |
![]()
Programımıza aşağıdaki kodlarla başlayacağız:
|
1 2 3 |
const fs = require("fs"); const sqlite3 = require("sqlite3").verbose(); const filepath = "./population.db"; |

Burada,
-
İlk satırda, fs modülünü içe aktarıyoruz.
-
Üçüncü satırda, filepath değişkeni SQLite veritabanının yolunu içerir.
-
Bu noktada veritabanı henüz mevcut değildir. Ancak, node-sqlite3.
Ardından, SQLite veritabanına bir bağlantı kurmak için aşağıdaki satırları ekleyin:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
function connectToDatabase() { if (fs.existsSync(filepath)) { return new sqlite3.Database(filepath); } else { const db = new sqlite3.Database(filepath, (error) => { if (error) { return console.error(error.message); } console.log("Veritabanına başarıyla bağlandı"); }); return db; } } |
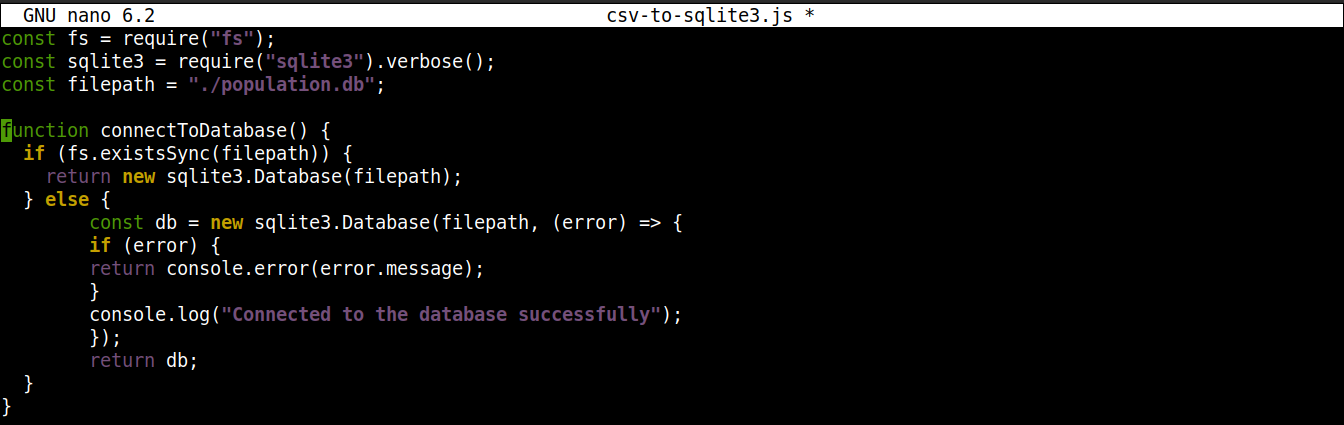
Burada,
-
The method connectoToDatabase() metodu, veritabanına bir bağlantı kurar.
-
Within connectToDatabase() içinde, bir if ifadesi içinde fs modülünden existsSync() metodunu çağırıyoruz. If ifadesi, veritabanının belirtilen konumda var olup olmadığını kontrol eder.
-
Koşul değerlendirmesi true ise, o zaman Database() sınıfı, node-sqlite3 modülü üzerinden başlatılır. Bağlantı kurulduktan sonra, fonksiyon bir nesne döndürür ve sonlanır.
-
Koşul değerlendirmesi false (veritabanı mevcut değilse) ise, yürütme else bloğuna atlayacaktır. Orada, Database() sınıfı iki argümanla başlatılacaktır: veritabanı dosyasının yolu ve bir geri çağırma (callback) fonksiyonu.
-
Temel olarak, veritabanı mevcut değilse oluşturulacaktır. Ancak, oluşturma işlemi sırasında herhangi bir hata oluşursa, error nesnesini ayarlayacak ve hata mesajını yazdıracaktır.
Sırada, eğer bir veritabanı mevcut değilse tablo oluşturmak için kodları ekleyeceğiz:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
const fs = require("fs"); const sqlite3 = require("sqlite3").verbose(); const filepath = "./population.db"; function connectToDatabase() { if (fs.existsSync(filepath)) { return new sqlite3.Database(filepath); } else { const db = new sqlite3.Database(filepath, (error) => { if (error) { return console.error(error.message); } createTable(db); console.log("Connected to the database successfully"); }); return db; } } function createTable(db) { db.exec(` CREATE TABLE migration ( year_month VARCHAR(10), month_of_release VARCHAR(10), passenger_type VARCHAR(50), direction VARCHAR(20), sex VARCHAR(10), age VARCHAR(50), estimate INT ) `); } module.exports = connectToDatabase(); |
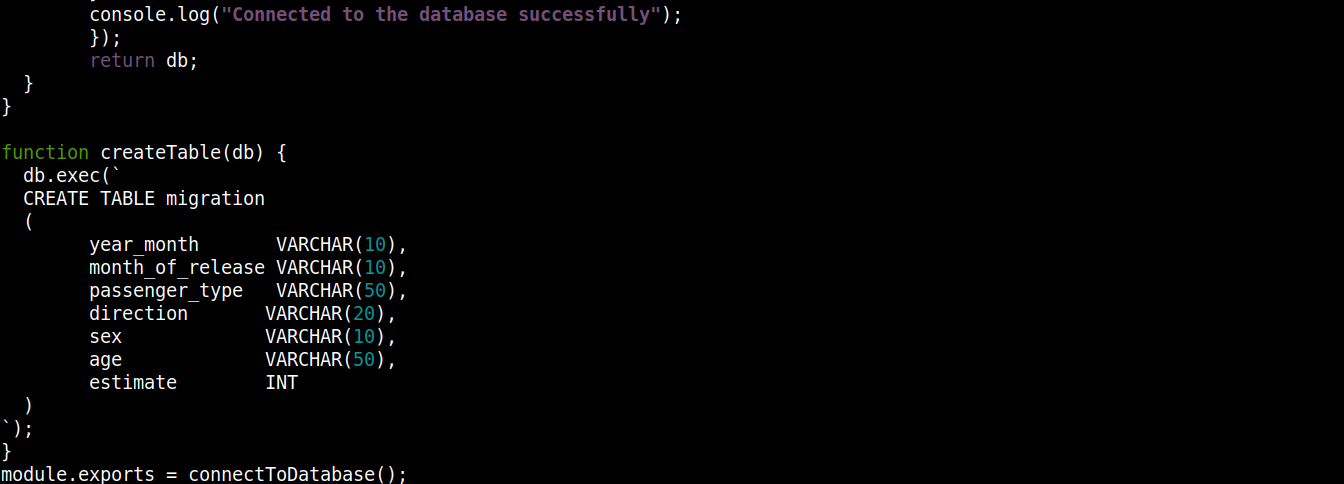
Burada,
-
The connectToDatabase() fonksiyonu, createTable() fonksiyonunu çağırır; bu fonksiyon db içinde saklanan nesneleri bir argüman olarak kabul eder.
-
Outside connectToDatabase() dışında, createTable() metodunu, bağlantı nesnesi olan db nesnesini parametre olarak kabul edecek şekilde tanımladık.
-
The exec() metodu, db üzerinde bir SQL ifadesini argüman olarak alır. Bu SQL ifadesi içinde, migration tablosunun 7 sütunla oluşturulmasını tanımladık; buradaki her bir sütun migration_data.csv dosyasındaki sütun başlıklarına karşılık gelir.
-
Son olarak, şu fonksiyonu çağırıyoruz: connectToDatabase() yöntemi ve döndürdüğü bağlantı nesnesini diğer dosyalarda kullanabilmemiz için dışa aktarma.
Dosyayı kaydedin ve düzenleyiciyi kapatın.
Ardından, ayrıştırılan verileri veritabanına eklemek için başka bir program oluşturacağız:
|
1 |
nano insert_data.js |
Aşağıdaki kodu insert_data.js dosyasına girin::
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
const fs = require("fs"); const { parse } = require("csv-parse"); const db = require("./csv-to-sqlite3"); fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { db.serialize(function () { db.run( `INSERT INTO migration VALUES (?, ?, ? , ?, ?, ?, ?)`, [row[0], row[1], row[2], row[3], row[4], row[5], row[6]], function (error) { if (error) { return console.log(error.message); } console.log(`Row inserted, ID: ${this.lastID}`); } ); }); }); |
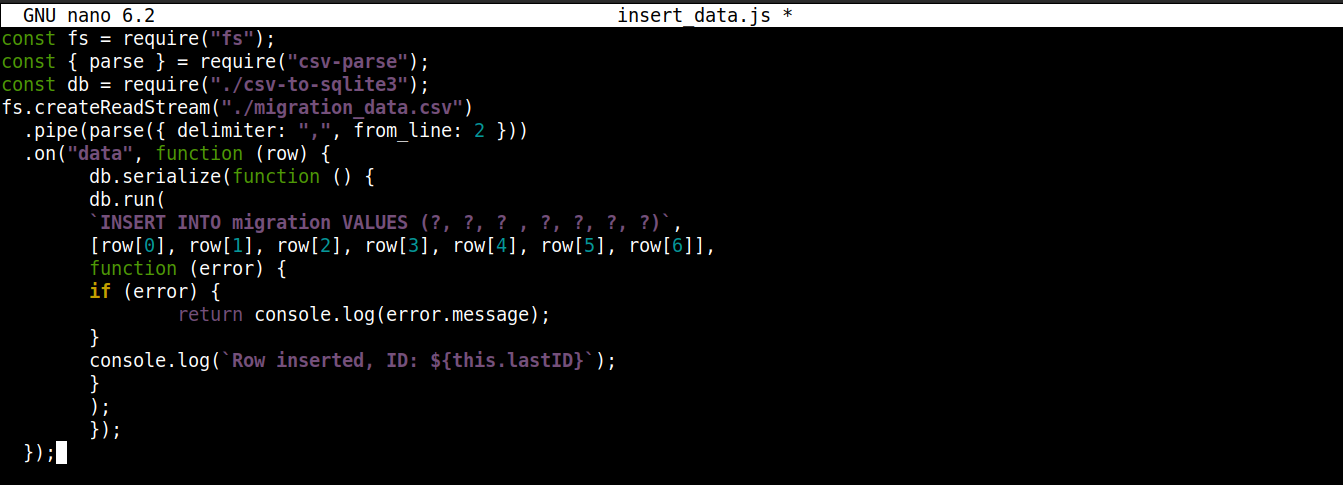
Burada,
-
We are storing the connection object obtained from csv-to-sqlite3.js dosyasından elde edilen bağlantı nesnesini in the variable db değişkeninde saklıyoruz..
-
Veri olayı geri çağrısı içinde (fs modülü akışına bağlı), bağlantı nesnesi üzerinde serialize() yöntemini çağırıyoruz. Bu yöntem, bir SQL ifadesinin yürütülmesinin bir sonrakinin başlamasından önce tamamlanmasını sağlayarak veritabanı yarış durumlarını (sistemin eşzamanlı olarak rakip işlemleri çalıştırması) önler.
-
The serialize() yöntemi üç bağımsız değişken kabul eder:
-
İlk bağımsız değişken SQL ifadesidir.
-
İkinci bağımsız değişken bir dizidir.
-
Üçüncü bağımsız değişken, veriler veritabanına başarıyla eklendiğinde veya eklenemediğinde çalışan bir geri çağrıdır.
-
Programı yürütmeye hazırız. insert_data.js dosyasını Node.js kullanarak çalıştırın:
|
1 |
node insert_data.js |
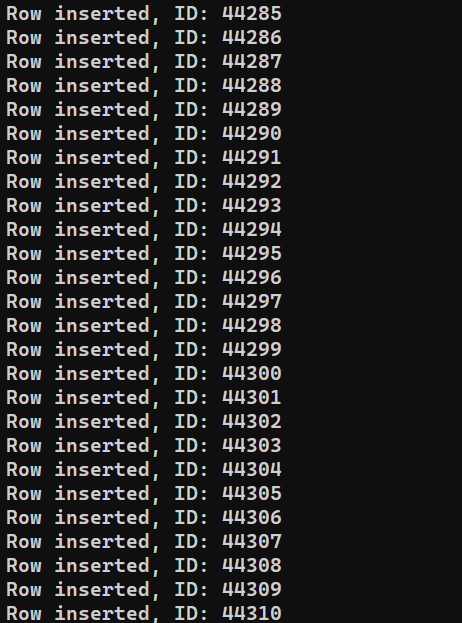
Sistemin performansına bağlı olarak işlemin tamamlanması biraz zaman alabilir. Ancak tamamlandığında çıktı şuna benzer görünmelidir:
Adım 5 – Verileri CSV'ye Yazma
Son bölümden sonra, migration_data.csv dosyasından ayrıştırdığımız tüm kayıtları içeren bir veritabanımız var. Bu bölümde, verileri veritabanından okuyacağız ve ayrı bir CSV dosyasına yazacağız.
Programı depolamak için yeni bir JavaScript dosyası oluşturun:
|
1 |
nano write_csv.js |
İlk olarak, fs ve csv-stringify modüllerini, csv-to-sqlite3.js dosyasındaki veritabanı bağlantı nesnesiyle birlikte içe aktarmak için aşağıdaki satırları ekleyin::
|
1 2 3 |
const fs = require("fs"); const { stringify } = require("csv-stringify"); const db = require("./csv-to-sqlite3"); |
Ardından, yazılacak CSV dosyasının adını ve bir yazılabilir akışı (writable stream) içeren bir değişken ekleyeceğiz:
|
1 2 3 4 5 6 7 8 9 10 11 |
const filename = "saved_from_db.csv"; const writableStream = fs.createWriteStream(filename); const columns = [ "year_month", "month_of_release", "passenger_type", "direction", "sex", "age", "estimate", ]; |
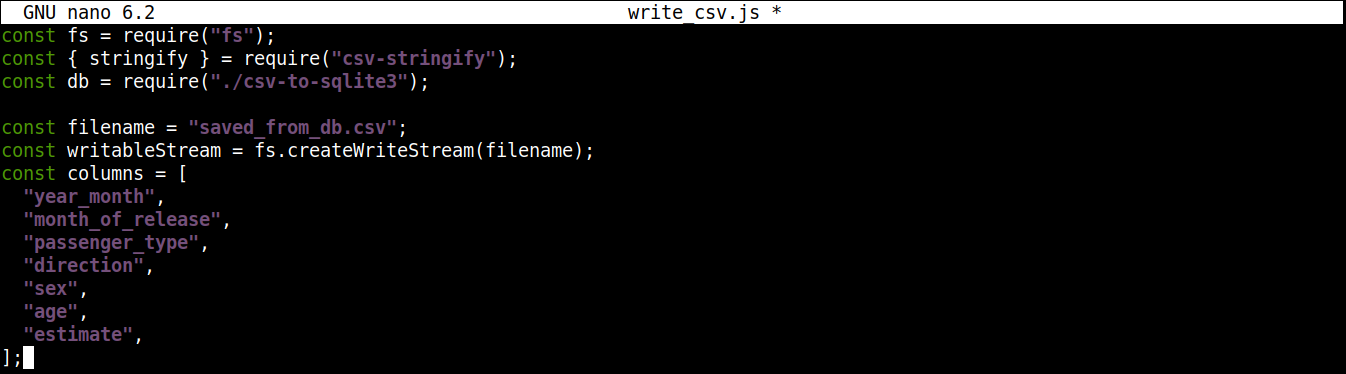
Burada,
-
The createWriteStream() yöntemi, yazılacak dosya adını bir argüman olarak alır. Dosyayı saved_from_db.csv olarak adlandıracağız..
-
The column değişkeni, CSV verileri için tüm başlık adlarını içeren bir diziyi depolar.
Ardından, veritabanından verileri okumak ve saved_from_db.csv dosyasına yazmak için aşağıdaki kod satırlarını ekleyin::
|
1 2 3 4 5 6 7 8 9 10 11 |
const stringifier = stringify({ header: true, columns: columns }); db.each(`select * from migration`, (error, row) => { if (error) { return console.log(error.message); } stringifier.write(row); }); stringifier.pipe(writableStream); console.log("finished writing to CSV"); |
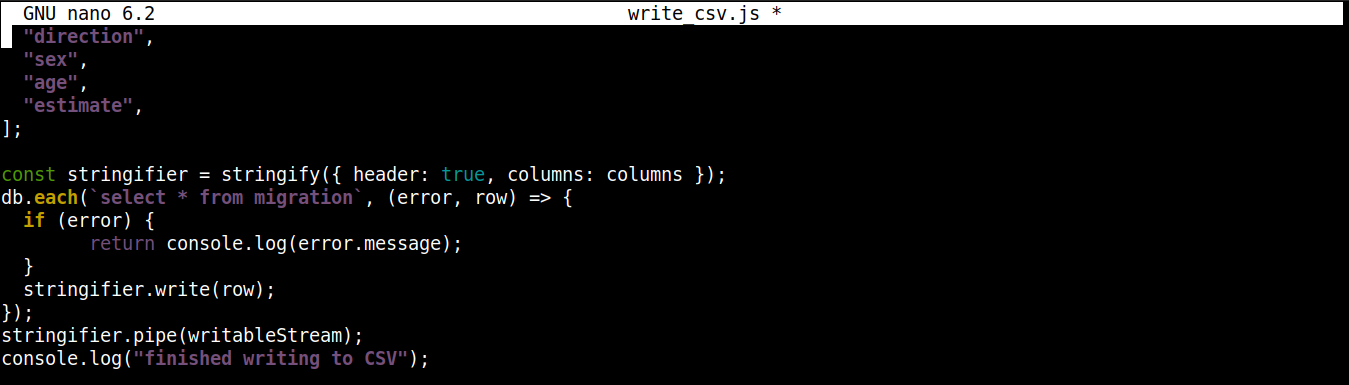
Burada,
-
We are invoking the stringify() yöntemini bir nesne argümanıyla çağırıyoruz. Bu, verileri bir nesneden CSV formatına dönüştüren bir dönüştürme akışı (transform stream) ile sonuçlanır. stringify() yöntemine iletilen nesnenin iki özelliği vardır:
-
header: Bir Boolean değeri kabul eder. Eğer değer true ise bir başlık oluşturulur.
-
columns: Eğer header değeri true ise, CSV dosyasının ilk satırına yazılacak sütun adlarını içeren bir diziyi kabul eder..
-
-
The each() yöntemi, csv-to-sqlite3 bağlantı nesnesinden iki argümanla çağrılır: SQL ifadesi (veritabanından veri okuma) ve bir geri çağırma (başarı/hata yönetimi).
-
Upon each iteration of each(), pipe() ( stringifier akışından gelen), verileri yığınlar halinde writableStream yazılabilir akışına göndermeye başlar. Her veri yığını daha sonra saved_from_db.csv dosyasına yazılır..
-
Tüm veriler CSV dosyasına yazıldığında, konsol ekranında bir başarı mesajı yazdırılır.
Son kod şu şekilde görünmelidir:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
const fs = require("fs"); const { stringify } = require("csv-stringify"); const db = require("./csv-to-sqlite3"); const filename = "saved_from_db.csv"; const writableStream = fs.createWriteStream(filename); const columns = [ "year_month", "month_of_release", "passenger_type", "direction", "sex", "age", "estimate", ]; const stringifier = stringify({ header: true, columns: columns }); db.each(`select * from migration`, (error, row) => { if (error) { return console.log(error.message); } stringifier.write(row); }); stringifier.pipe(writableStream); console.log("CSV'ye yazma tamamlandı"); |
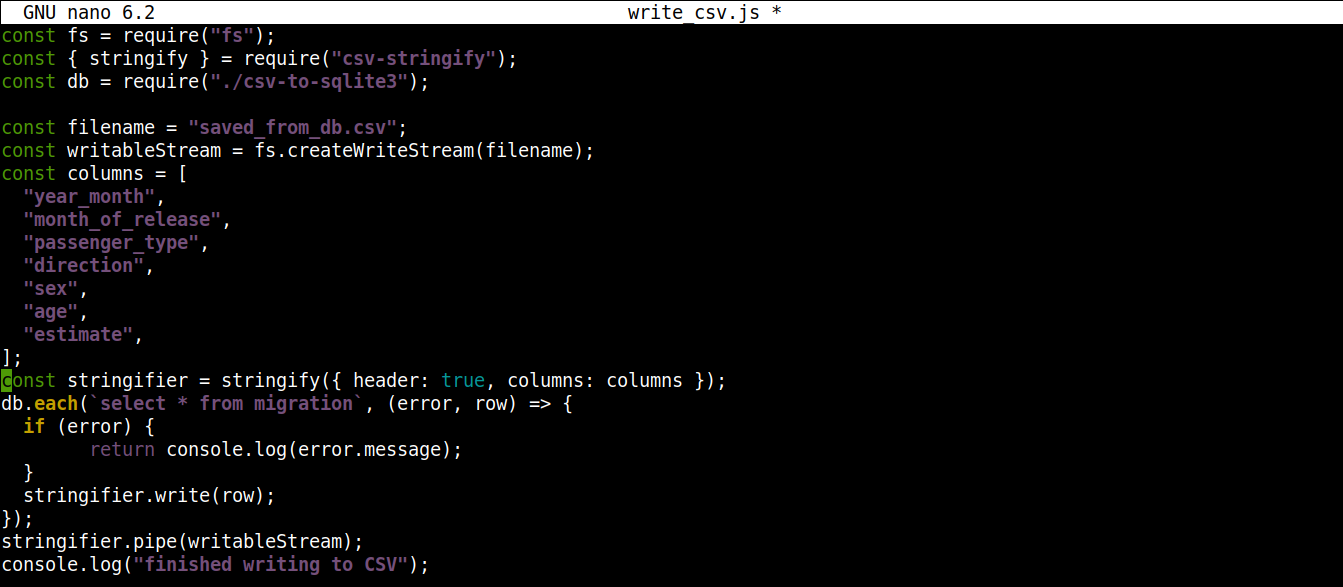
Dosyayı kaydedin ve editörü kapatın. Artık programı Node.js kullanarak çalıştırabiliriz:
|
1 |
node write_csv.js |
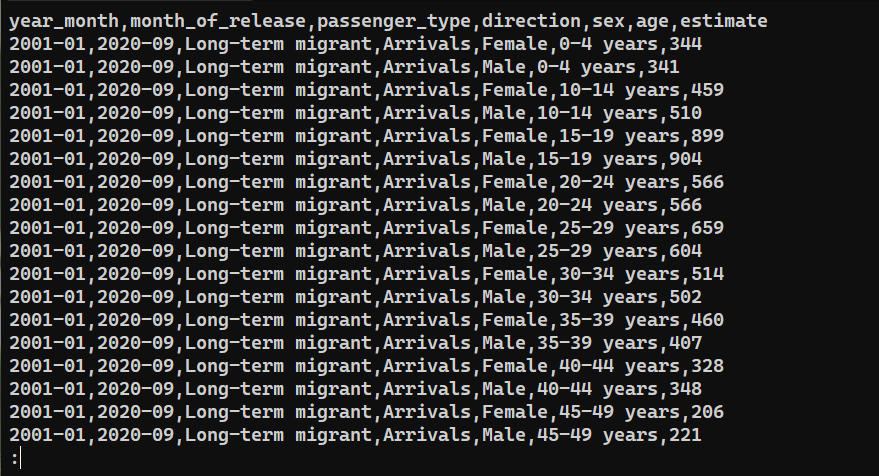
Verilerin başarıyla dışa aktarıldığını doğrulamak için şu dosyanın içeriğini kontrol edin: saved_from_db.csv:
|
1 |
cat saved_from_db.csv | less |
Son Düşünceler
Bu kılavuzda, node-csv ve node-sqlite3 modüllerini kullanarak Node.js'de CSV dosyalarıyla çalışmayı gösterdik. CSV'den verileri ayrıştırmak, verileri bir SQLite veritabanına aktarmak ve verileri yeni bir CSV dosyasına yazmak gibi çeşitli görevleri gerçekleştirmek için birden fazla program oluşturduk.
Bu kılavuz, node-csv modülünün yeteneklerinin yalnızca küçük bir kısmını göstermektedir. Tüm özellikleri hakkında daha fazla bilgiyi şurada bulabilirsiniz: CSV Project. node-sqlite3 hakkında daha fazla bilgi edinmek için GitHub'daki resmi belgelere göz atın. Bahsetmeye değer başka bir modül de event-stream akışlarla çalışmayı kolaylaştırmak içindir.
Node.js projenizi daha da büyütmek mi istiyorsunuz? İşte göz atmanız gereken bazı Node.js eğitimleri:
-
npm ve package.json ile Node.js Modüllerini Kullanma: Bir Eğitim
-
Ubuntu 20.04 üzerinde Docker ile Node.js (Express.js) Uygulaması Nasıl Dağıtılır
Keyifli Kodlamalar!
Yorumlar
Henüz yorum yapılmamış. İlk siz olun.