

Web scraping, web crawling (web tarama), web harvesting (web hasadı) veya web veri çıkarma, İnternet üzerindeki web sayfalarından veri madenciliği yapma eylemini ifade eden eş anlamlı terimlerdir. Web scraper'lar veya web crawler'lar, web sayfalarını programatik olarak inceleyerek gerekli verileri çıkaran araçlardır. Genellikle büyük metin kümelerinden oluşan bu veriler; analitik amaçlar için, ürünleri anlamak veya belirli bir web sayfası hakkındaki merakı gidermek için kullanılabilir.
Web taramanın nasıl yapıldığını merak ediyorsanız, basit bir veri seti üzerinden web scraping'in temellerini göstereceğiz. Programlama uzmanlığı seviyeniz ne olursa olsun bu öğreticiyi takip edebilmelisiniz. Pratik örnek için kendi CloudSigma blogumuzu kullanacağız. Blog sayfamızdaki öğreticiler hakkında bilgi almaya çalışacağız. Bu öğreticinin sonucunu okuduğunuzda, Python 3 ile yapılmış, blog bölümümüzdeki birkaç sayfayı tarayan ve ardından verileri ekranınızda görüntüleyen çalışan bir web scraper'a sahip olacaksınız.
Bu temel web scraper'ı oluştururken edindiğiniz bilgileri kullanarak bunu genişletebilir ve kendi web scraper'larınızı oluşturabilirsiniz. Bu eğlenceli olmalı, hadi başlayalım!
Önkoşullar
Bu uygulamalı bir öğreticidir, bu nedenle iyi bir şekilde takip edebilmek için Python 3 için yerel bir geliştirme ortamına sahip olmalısınız. İlk olarak, şu konudaki öğreticimize başvurabilirsiniz: Ubuntu üzerinde Python 3 kurma ve yerel bir programlama ortamı oluşturma.
Scrapy
Web scraping iki adımdan oluşur: ilk adım web sayfalarını bulmak ve indirmek, ikinci adım ise bu web sayfalarını taramak ve buralardan bilgi çıkarmaktır.
Birçok programlama dilinde sıfırdan bir web scraper oluşturmak için kullanılabilecek bir dizi yöntem ve kütüphane vardır. Ancak bu durum, gelecekte web scraper'ınız karmaşıklaştığında veya aynı anda farklı ayarlara ve şablonlara sahip birden fazla sayfayı taramanız gerektiğinde sorunlara yol açabilir. Kazıdığınız verileri CSV, XML veya JSON gibi farklı formatlar arasında nasıl dönüştüreceğinizi bulmak oldukça zor bir görev olabilir.
Bazıları sıfırdan kendi web scraper'larını oluşturma zorluğunu sevse de, tekerleği yeniden icat etmemek ve bunun yerine tüm bu sorunları çözen mevcut bir kütüphanenin üzerine inşa etmek daha iyidir. Bu öğreticide web scraper'ı uygulamak için Scrapy adlı Python kütüphanesini, Python 3 ile birlikte kullanacağız. Scrapy, açık kaynaklı bir araçtır ve en popüler ve güçlü Python web scraping kütüphanelerinden biridir. Scrapy, tüm scraper'ların sahip olması gereken bazı ortak işlevleri yerine getirmek üzere oluşturulmuştur. Bu sayede bir web crawler uygulamak istediğinizde her seferinde tekerleği yeniden icat etmek zorunda kalmazsınız. Scrapy ile bir scraper oluşturma süreci kolay ve eğlenceli hale gelir.
Scrapy, PyPi (yaygın olarak pip – Python Paket Dizini olarak bilinir) üzerinden edinilebilir. PyPi, çoğu Python paketini barındıran topluluğa ait bir depodur. Yerel geliştirme ortamınıza Python 3'ü kurup yapılandırdığınızda, Python paketlerini yüklemek için kullanabileceğiniz pip de yüklenir.
Adım 1: Basit Bir Web Scraper Nasıl Oluşturulur
İlk olarak, Scrapy'yi kurmak için aşağıdaki komutu çalıştırın:
|
1 |
pip install scrapy |
İsteğe bağlı olarak, resmi Scrapy kurulum talimatlarını dokümantasyon sayfasından takip edebilirsiniz. Scrapy'yi başarıyla kurduysanız, projeniz için seçtiğiniz bir adı kullanarak bir klasör oluşturun:
|
1 |
mkdir cloudsigma-crawler |
Klasörün içine gidin ve kod için ana dosyayı oluşturun. Bu dosya, bu öğreticideki tüm kodları barındıracaktır:
|
1 |
touch main.py |
Dilerseniz yukarıdaki komut yerine metin düzenleyicinizi veya IDE'nizi kullanarak da dosyayı oluşturabilirsiniz.
Ardından, dosyayı açın ve Scrapy kullanan temel bir scraper oluşturarak başlayalım. Scrapy'den temel bir spider sınıfı olan scrapy.Spider'ı genişleten bir Python sınıfı oluşturacağız. Bu sınıf, aşağıda tanımlandığı gibi iki zorunlu niteliğe sahip olacaktır:
- name — spider'ı tanımlamak için bir dize adı (istediğiniz bir adı girebilirsiniz).
- start_urls — taranacak URL'lerin listesini içeren bir dizi. Bir URL ile başlayacağız.
Temel örümceği oluşturmak için açılan dosyaya aşağıdaki kod parçacığını ekleyin:
|
1 2 3 4 5 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] |
Aşağıda her bir kod satırının açıklaması yer almaktadır:
İlk satır Scrapy'yi içe aktararak paketin sunduğu çeşitli sınıfları kullanmamıza olanak tanır.
Bir sonraki satırda, Scrapy tarafından sağlanan Spider sınıfını genişletiyor ve CloudSigmaCrawler adında bir alt sınıf oluşturuyoruz. Bir Sınıfı (Spider) genişleterek, artık kodumuzda kullanabileceğimiz Sınıf özelliklerine erişim elde ederiz. Bu durumda, Spider sınıfı, URL'lerin nasıl takip edileceğini ve web sayfalarından verilerin nasıl çıkarılacağını tanımlayan yöntemlere ve davranışlara sahiptir. Ancak hangi URL'leri takip edeceğini veya hangi verileri çıkaracağını bilmez. Onu genişleterek, yöntemlere gerekli bilgileri sağlayabiliriz. Alt sınıflara ayırma ve genişletme hakkında daha fazla bilgi edinmek için okumaya devam edin Nesne Yönelimli programlama ilkeleri.
CloudSigmaCrawler'ımızda gerekli nitelikleri tanımlıyoruz. İlk olarak, örümceğimize cloudsigma_crawler adını veriyoruz. Ardından, başlamak için tek bir URL sağlıyoruz: https://blog.cloudsigma.com/blog/. Bu URL'yi açmak sizi birçok eğitimden bazılarını içeren CloudSigma blog sayfası 1'e götürecektir.
Kazıyıcıyı test etme zamanı. Birkaç seçeneğiniz var. Örneğin, bir IDE kullanıyorsanız, PyCharm community edition - JetBrains, muhtemelen betiği çalıştırmak için tıklayabileceğiniz bir düğmeyle birlikte gelir. Diğer bir seçenek ise Python dosyalarını komut satırından çalıştırmanın tipik yolunu izlemektir: python yol/dosya_adi.py veya py yol/dosya_adi.py. Başka bir seçenek ise Scrapy'nin komut satırı arayüzüdür. Scrapy, bir kazıyıcıyı başlatmaya yardımcı olmak için kendi komut satırı arayüzüyle birlikte gelir. Kazıyıcıyı başlatmak için aşağıdaki komutu girin:
|
1 |
scrapy runspider main.py |
Yüklediğiniz Scrapy kütüphane sürümüne bağlı olarak, aşağıdakine benzer bir çıktı görmelisiniz:
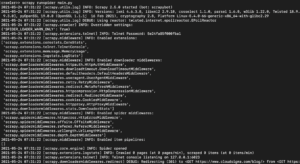
Gördüğünüz gibi çıktı oldukça uzun, bu yüzden sadece bazı kısımları seçtik. Komutu çalıştırdığınızda olanlar şunlardır:
- Kazıcı başlatıldı. Bu nedenle, URL'lerden gelen verileri takip etmek ve okumak için kullanması gereken ek bileşenleri ve uzantıları yükledi.
- start_urls listesinde sağlanan URL'yi kullanarak sayfadaki HTML'yi aldı. Bu, tarayıcının web sayfalarını açarken izlediği sürece benzer bir işlemdir.
- HTML alındıktan sonra, henüz tanımlamadığımız parse yöntemine aktarılır. Şimdilik hiçbir şey yapmaz, bu nedenle örümcek herhangi bir işlem yapmadan çıkış yapar. Bir sonraki adımda parse yönteminin davranışını tanımlayacağız.
Adım 2: Bir Sayfadan Veri Nasıl Çıkarılır
1. adımda, yalnızca bir HTML sayfasını alan ancak sonrasında hiçbir şey yapmayan temel bir kazıyıcı uyguladık. Bu bölümde, veri çıkarma talimatlarını sağlayacağız. CloudSigma Blog sayfasında, veri çıkarmak istediğimiz bazı şeyler olduğunu fark edebilirsiniz, örneğin:
- Tüm sayfalarda bulunan üst bilgi.
- Gezinme menüsü ve arama filtresi kutusu.
- Eğitimlerin ızgara biçimindeki asıl listesi.
Kazımak istediğiniz HTML sayfasının kaynak kodunu görüntülemek, size sayfanın yapısı hakkında genel bir fikir verir. Bu, bir kazıyıcı yazmanıza yardımcı olur. Sayfaya sağ tıklayıp Kaynak Kodunu Görüntüle seçeneğini seçerek veya Ctrl + U tuşlarına basarak kaynak kodunu görüntüleyebilirsiniz. İşte kaynak kodundan bir kesit:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
<body> <div id="x-iso-container" class="x-iso-container x-iso-container-posts cols-3"> <article id="post-51691" class="post-51691 post type-post status-publish format-standard has-post-thumbnail hentry category-blog-posts category-tutorials tag-apache tag-certbot tag-cloud-guide tag-cloud-tutorial tag-https tag-lets-encrypt tag-ssl tag-ssl-certification tag-tutorial tag-ubuntu"> <div class="entry-wrap"> <header class="entry-header"> <h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Şuna kalıcı bağlantı: "Ubuntu 18.04 üzerinde Let’s Encrypt ile Apache Güvenliğini Sağlama"">Güvenliğini Sağlama: Ubuntu 18.04 üzerinde Let’s Encrypt ile Apache</a> </h2> </header> <div class="entry-content excerpt"> <p>Web sitesi ve veri güvenliği, hafife alınamayacak konulardır. Şunları içeren son derece hassas bilgiler: finansal kayıtlar ve müşterilerin özel bilgileri, her zaman şu ikisi arasında iletim halindedir: kullanıcının bilgisayarı ve web siteniz. Bu gerçeği göz önünde bulundurduğunuzda, güvenli olmayan web sitelerinin neden işletmenize ciddi şekilde zarar verebilecek bir ihlalle sonuçlanabileceğini görmek zor değildir. Birçok … </p> <div><a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="more-link">Devamını Oku</a></div> </div> </div> ... </article> </div> </body> |
Görebileceğiniz gibi, her blog kılavuzu <article> adlı bir HTML etiketi içine alınmıştır. Sayfayı kazımak iki adımdan oluşacaktır. İlk adım, istediğimiz verileri içeren sayfa bölümlerine bakarak her bir blog kılavuzunu yakalamak olacaktır. Bir sonraki adım ise HTML etiketi ile tanımlanan her bir kılavuzdan istediğimiz verileri çekmektir.
Scrapy, yakalanacak verileri sağladığınız seçicilere göre belirler. Bir sayfadaki bir veya daha fazla öğeyi bulmak ve bu öğelerin içindeki verileri almak için seçicileri kullanabiliriz. Scrapy şunları destekler: XPath ve CSS seçicileri.
Daha önce incelediğimiz kaynaktan, CSS seçicileri daha kolay görünmektedir. Bu nedenle, sayfadaki tüm kılavuzları bulmamıza yardımcı olacağı için tercih edeceğimiz seçenek bu olacaktır. HTML kaynak kodundan, her kılavuz post adlı CSS sınıfı içinde belirtilmiştir. CSS sınıf adları genellikle .sınıf_adı (nokta sınıf_adı) ile tanımlanır. Bu nedenle, CSS seçicimiz için .post kullanacağız. main.py kazıyıcı kaynak kodumuzun içinde, .post sınıfını response nesnesine aktaracağız, böylece dosyanız artık şu şekilde görünecektir:
|
1 2 3 4 5 6 7 8 9 10 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): pass |
Bu kod parçacığı, belirtilen start_urls adresine sahip sayfadaki tüm eğitimleri alacak ve verileri çıkarmak için eğitimler arasında döngü oluşturacaktır. Bir sonraki adımda bu verileri çıkarmak ve görüntülemek isteyeceksiniz. Eğer CloudSigma blog kaynak kodunu tekrar incelerseniz, her bir eğitimin başlığının bir <h2> etiketi içindeki bir <a> etiketi içinde saklandığını göreceksiniz, örneğin:
|
1 2 3 4 5 |
<h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Permalink to: "Securing Apache with Let’s Encrypt on Ubuntu 18.04"">Securing Apache with Let’s Encrypt on Ubuntu 18.04</a> </h2> |
Üzerinde döngü oluşturduğumuz her bir eğitim nesnesi, alt öğeleri bulmak ve çıkarmak için bir seçici iletebileceğimiz bir CSS yöntemi içerir. Bu örnek için, <a> etiketinin içinde yer alan başlığı çıkarmak istiyoruz. Bu etiket, .entry-wrap sınıfının içindeki .entry-header sınıfının içindeki <h2> etiketinin içindedir. Başlığı çıkarmak için bu CSS seçicilerini nesne yöntemine iletebiliriz, kodu şu şekilde görünecek şekilde değiştirin:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), } |
extract_first() yönteminden sonraki sondaki virgül bir yazım hatası değildir, çünkü bölümün altına daha fazla kod ekleyeceğiz.
Yukarıdaki kaynak koddan dikkat edilmesi gereken bazı noktalar şunlardır:
- seçiciye eklenen ::text – bu, CSS sözde seçicisidir ve koda etiketin kendisini değil, etiketin içindeki metni getirmesini söyler.
- nesne içindeki extract_first() yöntem çağrısı – koda yalnızca seçiciyle eşleşen ilk öğeyi seçmesini söyler. Bu nedenle, bir öğe listesi yerine bir dize elde ederiz.
Ardından, dosyayı kaydedin ve terminalinize aşağıdaki komutu girerek kodu çalıştırın:
|
1 |
scrapy runspider main.py |
Çıktıda, eğitimlerin başlıklarını görmelisiniz:
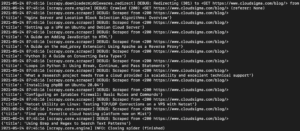
Bir eğitimin URL'si, öne çıkan görseli ve açıklaması gibi diğer ayrıntılarını almak için daha fazla seçici ekleyerek bunu genişletmeye devam edebiliriz.
Tek bir eğitimin HTML kodunu tekrar inceleyelim:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
<body> <div id="x-iso-container" class="x-iso-container x-iso-container-posts cols-3"> <article id="post-51691" class="post-51691 post type-post status-publish format-standard has-post-thumbnail hentry category-blog-posts category-tutorials tag-apache tag-certbot tag-cloud-guide tag-cloud-tutorial tag-https tag-lets-encrypt tag-ssl tag-ssl-certification tag-tutorial tag-ubuntu"> <div class="entry-featured"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="entry-thumb" title="Kalıcı bağlantı: "Securing Apache with Let’s Encrypt on Ubuntu 18.04""> <img width="1000" height="522" src="data:image/svg+xml,%3Csvg%20xmlns='http://www.w3.org/2000/svg'%20viewBox='0%200%201000%20522'%3E%3C/svg%3E" class="attachment-entry-fullwidth size-entry-fullwidth wp-post-image" alt="Let’s Encrypt" loading="lazy" data-lazy-srcset="/media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04.jpg 1000w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-300x157.jpg 300w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-768x401.jpg 768w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-610x318.jpg 610w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-100x52.jpg 100w" data-lazy-sizes="(max-width: 1000px) 100vw, 1000px" data-lazy-src="/media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04.jpg"/> </a> </div> <div class="entry-wrap"> <header class="entry-header"> <h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Kayıcı bağlantı: "Ubuntu 18.04 üzerinde Let’s Encrypt ile Apache'yi Güvenli Hale Getirme"">Güvenli Hale Getirme: Ubuntu 18.04 üzerinde Let’s Encrypt ile Apache</a> </h2> </header> <div class="entry-content excerpt"> <p>Web sitesi ve veri güvenliği hafife alınamayacak konulardır. Finansal kayıtları ve müşterilerin özel bilgilerini içeren son derece hassas bilgiler, kullanıcının bilgisayarı ile web siteniz arasında her zaman iletim halindedir. Bu gerçeği göz önünde bulundurduğunuzda, güvenli olmayan web sitelerinin, işletmenize ciddi şekilde zarar verebilecek bir veri ihlaline neden olabileceğini görmek zor değildir. Bu konuda çeşitli … </p> <div><a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="more-link">Devamını Oku</a></div> </div> </div> </article> </div> </body> |
Vurgulanan kısımları, yani eğitimin URL'sini, öne çıkan görselini ve açıklamasını çıkarmayı denemek istiyoruz.
- Yukarıdaki kod parçacığından anlaşılacağı üzere, blogun görseli, blog eğitiminin başlangıcındaki bir div etiketi içindeki bir <a> etiketi içindeki bir img etiketinin data-lazy-src özniteliğinde saklanır. Eğitim başlıklarında yaptığımız gibi değeri yakalamak için bir CSS seçici kullanabiliriz.
- <div> öğesinin içinde <a> etiketine sahip olduğumuz için eğitimin URL'sini almak oldukça kolaydır.
- Açıklama, <div> etiketinin içindeki <p> etiketinin içinde yer almaktadır.
İstediğimizi elde etmek için CSS sınıflarını kullanacağız. Kodu şu şekilde görünecek şekilde değiştirelim:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), 'caption': tutorial.css(CAPTION_SELECTOR).extract_first(), } |
Değişiklikleri kaydedin ve kodu aşağıdaki komutla çalıştırın:
|
1 |
scrapy runspider main.py |
Çıktıda, eklediğimiz URL, resim ve açıklama gibi daha fazla veri göreceksiniz:

Tek bir sayfayı taramak için bu kadar. Sırada, bağlantıları takip eden bir tarayıcıyı nasıl oluşturabileceğimizi görelim.
Adım 3: Birden Fazla Sayfa Nasıl Taranır
Bu noktaya kadar, tek bir sayfadan veri alabilen bir tarayıcı oluşturduk. Ancak bundan daha fazlasını istiyoruz. Bağlantıları takip edebilen ve bir web sitesinin birden fazla sayfasından programlı olarak veri çıkarabilen bir örümcek istiyorsunuz.
CloudSigma blog sayfasının en altına giderseniz, sayfalama bağlantılarını ve sonraki sayfayı gösteren sağa doğru küçük bir ok göreceksiniz. İşte HTML kod parçası:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<div class="x-pagination"> <ul class="center-list center-text"> <li><span class="pages">Page 1 of 45</span></li> <li></li> <li><span class="current">1</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/2/" class="single_page" title="2">2</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="single_page" title="3">3</a></li> <li><span class="expand">...</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/45/" class="last" title="Last Page">45</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/2/" class="prev-next hidden-phone">→</a></li> </ul> </div> |
Kod parçası, .x-pagination CSS sınıfına sahip <div> etiketinin altındaki <li> etiketleri içinde birkaç sayfa gezinti bağlantısı göstermektedir. Odak noktamız sonraki sayfayı işaret eden bağlantıdır. Bu bağlantı, <ul> etiketindeki son <li> etiketinin <a> etiketinde yer almaktadır.
Yukarıdaki kod parçasında görüldüğü gibi, sonraki sayfayı işaret eden bağlantı, <a> etiketi içinde .prev-next sınıfına sahiptir. Ancak, sonraki sayfaya geçerseniz, önceki ve sonraki sayfa bağlantılarının da bu CSS sınıfına sahip olduğunu fark edeceksiniz. Sayfa 2 için bu kod parçasını inceleyin:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<div class="x-pagination"> <ul class="center-list center-text"> <li><span class="pages">Sayfa 2 / 45</span></li> <li><a href="https://blog.cloudsigma.com/blog/" class="prev-next hidden-phone">←</a></li> <li><a href="https://blog.cloudsigma.com/blog/" class="single_page" title="1">1</a></li> <li><span class="current">2</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="single_page" title="3">3</a></li> <li><span class="expand">...</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/45/" class="last" title="Son Sayfa">45</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="prev-next hidden-phone">→</a></li> </ul> </div> |
Eğer Scrapy extract_first() metodunu kullanırsak, ilk sayfada çalışacaktır. Sonraki sayfaya ulaştığında, yukarıdaki kod parçacığında ilk sayfayı işaret eden .prev-next sınıfına sahip ilk bağlantıyı seçecektir. Bu bir döngüye neden olacaktır. Bu nedenle, Scrapy extract() metodunu kullanacağız. Bu metot, bir kullanım durumuyla eşleşen tüm öğeleri çıkarır ve bunları bir diziye yerleştirir. Bu diziden, sonraki sayfayı işaret eden gerçek bağlantıyı içerecek olan son öğeyi seçebiliriz. Kodunuzu şu şekilde görünecek şekilde değiştirin:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), } NEXT_PAGE_SELECTOR = '.x-pagination > ul.center-list > li > a.prev-next::attr("href")' next_page = response.css(NEXT_PAGE_SELECTOR).extract() if next_page: yield scrapy.Request( response.urljoin(next_page[-1]), callback=self.parse ) |
next_page seçimi için kodun üzerinden geçelim.
İlk olarak sonraki ve önceki sayfa bağlantıları için bir seçici tanımlıyoruz. Ardından URL'leri çıkarmak ve bunları bir diziye yerleştirmek için extract() metodunu kullanıyoruz. next_page değişkeni şu şekilde iki elemanlı bir dizi olacaktır:
|
1 |
next_page = [prev_page_url, next_page_url] |
Sonraki sayfaya yönlendiğimiz için dizideki son elemanı seçeceğiz. Next_page[-1] dizideki son elemanı seçer.
if bloğu, next_page değişkeninin bir değere sahip olup olmadığını kontrol eder ve ardından scrapy.Request() metodunu çağırır. Kodumuzda, bu metoda sağlanan URL ile sayfayı taramasını ve verileri çıkarmak üzere ayrıştırmamız ve sonraki sayfa için işlemi tekrarlamamız için parse() metoduna geri göndermesini talimat veriyoruz. Bu işlem, sonraki sayfaya giden bir bağlantı bulamayana kadar veya blok başarısız olana kadar tekrarlanır ve ardından durur.
Kodunuzu kaydedin ve çalıştırın. Kazınacak daha fazla sayfa buldukça yinelemenin sayfalar arasında dönmeye devam ettiğini fark edeceksiniz. Bir web sitesindeki bağlantıları takip eden bir kazıyıcıyı bu şekilde tanımlarsınız. Örneğimiz oldukça basittir. Sadece bir sayfaya gidiyor, sonraki sayfanın bağlantısını buluyor ve işlemi tekrarlıyoruz. Diğer kullanım durumlarında, harici kaynakları gösteren etiketleri veya bağlantıları ve daha fazlasını takip etmek isteyebilirsiniz. İşte Python 3 temel web kazıyıcı için tamamlanmış kaynak kodu:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), 'caption': tutorial.css(CAPTION_SELECTOR).extract_first(), } NEXT_PAGE_SELECTOR = '.x-pagination > ul.center-list > li > a.prev-next::attr("href")' next_page = response.css(NEXT_PAGE_SELECTOR).extract() if next_page: yield scrapy.Request( response.urljoin(next_page[-1]), callback=self.parse ) |
Sonuç
Bu eğitimde, CloudSigma blog dizinini tarayabilen ve blog eğitimleri hakkında bazı bilgileri yalnızca yaklaşık 27 satır kodla görüntüleyebilen temel bir web kazıyıcı oluşturduk.
Elbette bu, onu Scrapy Python kütüphanesinin üzerine inşa ettiğimiz için mümkün oldu. Bu, yalnızca daha fazla etiketi, web sitelerinin arama sonuçlarını ve daha fazlasını takip eden daha karmaşık kazıyıcılar oluşturmanıza yardımcı olacak bir temeldir. Scrapy ile çalışma hakkında daha fazla bilgi edinmek için Scrapy'nin resmi belgelerine göz atabilirsiniz.
Keyifli Hesaplamalar!
Yorumlar
Henüz yorum yapılmamış. İlk siz olun.