

Команда grep — это мощная утилита для поиска шаблонов в тексте. Она предустановлена в любом дистрибутиве Linux . Вот наше руководство по настройке LAMP-стека — Linux, Apache, MySQL и PHP.
Название grep расшифровывается как global regular expression print (печать глобального регулярного выражения). Инструмент ищет указанный шаблон во входных данных. В принципе, это звучит тривиально. Однако его истинная сила заключается в том, как вы определяете шаблон. Это руководство подробно описывает, как использовать grep с регулярными выражениями для выполнения сложных поисков. Давайте начнем!
Как использовать Grep
Сама по себе команда grep не является сложной. Все, что ей требуется, — это шаблон и содержимое, в котором нужно выполнить поиск. Вот как выглядит базовая структура команды grep:
|
1 |
grep <regex> <file> |
Поиск текста
Сначала возьмите пример файла для выполнения действия. Скачайте GNU General Public License v3.0 (в текстовом формате). Это довольно большой текстовый файл со множеством слов и фраз. Если вы используете Ubuntu вы можете найти его в файле ниже. Следуйте нашему руководству по быстрой и простой установке Ubuntu.
|
1 |
curl -o gpl.txt https://www.gnu.org/licenses/gpl-3.0.txt |

Затем вы можете выполнить базовый поиск текста с помощью grep:
|
1 |
grep <pattern> <text_file> |
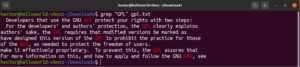
Можно передать вывод команды в grep через конвейер (pipe):
|
1 |
cat gpl.txt | grep <pattern> |
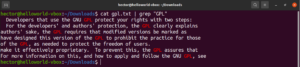
Чувствительность к регистру
По умолчанию grep чувствителен к регистру. Во многих ситуациях игнорирование регистра может быть оптимальным. Чтобы отключить чувствительность к регистру, используйте флаг «-i» или «–ignore-case»:
|
1 2 3 |
$ grep -i <pattern> <file> $ grep --ignore-case <pattern> <flag> |
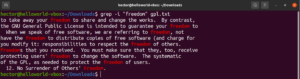
Инвертирование поиска
По умолчанию поведение grep заключается в выводе строк, в которых был найден шаблон. Инвертированное соответствие относится к явлению, когда вы не хотите видеть строки, соответствующие шаблону. Чтобы инвертировать соответствие, вам нужно использовать флаг «-v» или «–invert-match»:
|
1 2 3 |
$ grep -v <pattern> <file> $ grep --invert-match <pattern> <file> |
Номер строки
При запуске grep для очень большого файла трудно отследить местоположение результата поиска. Чтобы упростить задачу, в grep есть функция отображения номера строки. Чтобы включить нумерацию строк, используйте флаг «-n» или «–line-number»:
|
1 2 3 |
grep -n <pattern> <file> grep --line-number <pattern> <file> |
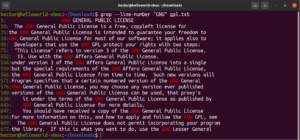
Можно комбинировать несколько аргументов grep. Следующая команда grep выполнит инвертированный поиск с выводом номеров строк:
|
1 |
grep -nv <pattern> <file> |
Регулярное выражение
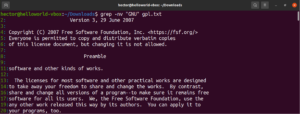
В начале этого руководства мы упомянули, что grep расшифровывается как global regular expression print. Термин “regular expression” определяется как специальная строка, описывающая шаблон поиска. Регулярное выражение имеет свою структуру и правила.
Существует множество алгоритмов и инструментов поиска строк, которые используют регулярные выражения (сокращенно regex) для выполнения поиска и замены. Несмотря на их популярность, различные приложения и языки программирования реализуют регулярные выражения немного по-разному. В этом разделе мы покажем несколько методов работы с регулярными выражениями с использованием grep.
Литеральное соответствие
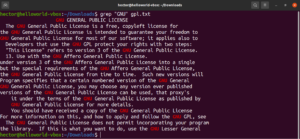
В предыдущих примерах grep выполнял поиск конкретной строки в заданном текстовом файле. На самом деле grep выполнял поиск с использованием самого базового регулярного выражения. Шаблоны регулярных выражений, определяющие поиск точного соответствия заданной строки, называются «литералами». Название происходит от того факта, что они соответствуют шаблону буквально, символ за символом.
Буквальное совпадение работает с буквенными и числовыми символами (а также с некоторыми специальными символами). Однако, в зависимости от других механизмов выражений, это поведение может измениться:
|
1 |
grep "<string>" <file> |
Соответствие якорям
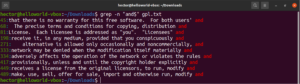
Якоря — это специальные символы, которые определяют, в каком месте строки должно находиться совпадение, чтобы оно считалось допустимым. Вот простой пример для наглядности. Если мы хотим найти только те строки, которые начинаются со строки «GNU», то команда grep с регулярным выражением будет выглядеть следующим образом. Здесь символ «^» является якорем, определяющим, что совпадения в начале строки являются единственно допустимыми:
|
1 |
grep -n "^GNU" <file> |

Аналогично, если мы хотим найти только те строки, которые заканчиваются строкой «works», то команда grep с регулярным выражением будет выглядеть так. Здесь символ «$» является якорем, определяющим, что допустимыми являются только совпадения в конце строки:
|
1 |
grep -n "and$" <file> |
Совпадение с любым символом
При выполнении текстового поиска вам может потребоваться указать, что в определенном месте может находиться любой символ. В регулярных выражениях это обозначается символом точки (.).
Посмотрите на этот пример. В текстовом файле GNU GPL 3 слова «accept» и «except» имеют общую часть «cept». Более того, оба слова содержат два символа перед частью «cept». Следующая команда grep найдет любое слово, содержащее два символа перед частью «cept»:
|
1 |
grep -n "..cept" <file> |
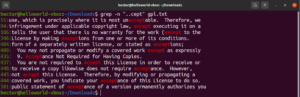
Согласно этому регулярному выражению, другие слова, такие как suscept, unaccept, unexpected и т. д., также будут являться совпадениями.
Квадратные скобки
В регулярных выражениях выражения в квадратных скобках определяют, что в указанном месте может находиться любой символ, объявленный внутри скобок. Посмотрите на следующую строку регулярного выражения:
|
1 |
t[wo]o |
При применении этого выражения на практике подходящими совпадениями будут слова too и two:
|
1 |
grep -n "t[wo]o" <file> |
Выражения в квадратных скобках открывают интересные возможности. Их можно использовать для указания того, что в определенном месте может находиться любой символ, кроме объявленных внутри скобок. Посмотрите на следующую строку регулярного выражения. Совпадение будет найдено только в том случае, если перед «ode» стоит любой символ, кроме «c»:
|
1 |
"[^c]ode" |
Запустите его для текстового файла лицензии GPL-3:
|
1 |
grep -n "[^c]ode" <file> |

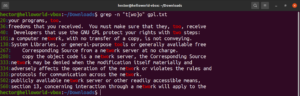
Помимо результатов из файла, другими подходящими результатами будут node, abode, anode и т. д. Выражения в квадратных скобках также могут описывать диапазон символов. Следующее регулярное выражение указывает, что совпадение является допустимым, если строка начинается с заглавной буквы:
|
1 |
"^[A-Z]" |
Запустите его для текстового файла лицензии GPL-3. Будут выведены все строки текстового файла:
|
1 |
grep -n "^[A-Z]" <file> |
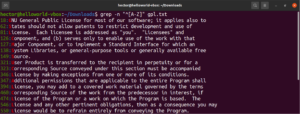
Для удобства использования существуют определенные классы символов со специальными обозначениями. В предыдущем примере мы использовали диапазон «A-Z» для определения заглавных букв. Вместо этого мы также можем использовать «[:upper:]». Результат будет тем же:
|
1 |
grep -n "^[[:upper:]]" <file> |
Повторение шаблона
В определенных ситуациях вам может потребоваться найти совпадение с определенным шаблоном или регулярным выражением ноль или более раз. Для этого используется метасимвол «звездочка» (*). Следующее регулярное выражение найдет все круглые скобки, содержащие только буквы и одиночные пробелы между ними. Обратите внимание, что объявление наборов строчных и прописных букв, а также пробелов идет вместе, без каких-либо знаков препинания:
|
1 |
"([a-zA-Z ]*)" |
Примените регулярное выражение на практике с помощью grep:
|
1 |
grep -n "([A-Za-z ]*)" <file> |

Использование метасимволов как обычных символов
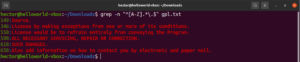
До сих пор мы познакомились с различными метасимволами, такими как звездочка (*), точка (.), якоря (^ и $) и т. д. Каждый из них выполняет уникальную функцию в контексте регулярных выражений. Проблема возникает, когда их нужно использовать как литералы, а не как метасимволы. В таких ситуациях обратная косая черта (\) перед метасимволом будет указывать на то, что он должен использоваться в буквальном смысле, а не как метасимвол. Посмотрите на этот пример регулярного выражения. Оно будет соответствовать всем строкам, которые начинаются с заглавной буквы и заканчиваются точкой:
|
1 |
grep -n "^[A-Z].*\.$" <file> |
Альтернатива
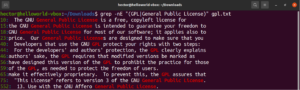
Используя выражения в квадратных скобках, мы можем указать различные возможные варианты для совпадения одного символа. В регулярных выражениях есть функция делать то же самое со словами и фразами. Для обозначения альтернативы используется символ вертикальной черты (|). Варианты остаются внутри круглых скобок, а символ вертикальной черты отделяет их друг от друга. Для того чтобы совпадение было действительным, может быть два или более возможных вариантов. Посмотрите на следующий пример регулярного выражения. Оно будет соответствовать как «GPL», так и «General Public License»:
|
1 |
grep -nE "(GPL|General Public License)" <file> |
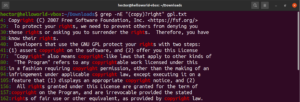
Квантификаторы
Используя метасимвол «звездочка» (*), мы могли определять шаблон, повторяющийся ноль или более раз. Однако есть и другие возможности. Проще всего объяснить квантификаторы на примере. Следующее регулярное выражение описывает, что и «copyright», и «right» являются допустимыми совпадениями. Вопросительный знак (?) указывает на то, что часть «copy» является необязательной для совпадения:
|
1 |
grep -nE "(copy)?right" <file> |
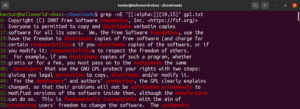
Следующий квантификатор — это символ сложения (+). Он ведет себя аналогично звездочке. Однако определяемый шаблон должен совпасть как минимум один раз. В следующем примере регулярное выражение будет соответствовать слову «soft» с одним или несколькими непробельными символами:
|
1 |
grep -nE "soft[^[:space:]]+" <file> |
Указание количества повторений
Можно указать количество повторений совпадения. Для этого используйте фигурные скобки ({}). Следующее регулярное выражение будет соответствовать любому слову, содержащему как минимум три гласные буквы:
|
1 |
grep -nE "[aeiouAEIOU]{3}" <file> |

Эта функция также позволяет определить нижний и верхний пределы длины совпадения. В следующем примере регулярное выражение будет соответствовать любому слову длиной от 10 до 15 символов:
|
1 |
grep -nE "[[:alpha:]]{10,15}" <file> |
Заключение
Поиск в текстовых файлах с помощью grep очень удобен. Регулярные выражения делают поиск с помощью grep более интересным и полезным. Они также позволяют настроить шаблон поиска по вашему желанию.
Хотя мы продемонстрировали некоторые из распространенных регулярных выражений, это только начало. Существуют более сложные регулярные выражения, которые предлагают тончайший контроль над поведением поиска. Помимо grep, регулярные выражения также широко используются другими инструментами и языками программирования.
Приятной работы!
Комментарии
Комментариев пока нет. Будьте первым.