
Файл CSV представляет собой простой текстовый файл, который хранит данные в табличном формате. В большинстве случаев в качестве разделителя в файлах CSV используются запятые (,), отсюда и название CSV (Comma Separated Values). Он используется в ситуациях, когда важна совместимость данных, поскольку файлы CSV можно открыть в любом текстовом редакторе, табличном процессоре и других специализированных инструментах. На самом деле многие языки программирования предлагают встроенную поддержку CSV.
В этом руководстве мы узнаем, как использовать CSV в примере приложения Node.js.
CSV в Node.js
Node.js — это кроссплатформенная среда выполнения JavaScript с открытым исходным кодом. Она стала одним из самых популярных бэкендов, обеспечивающих работу многочисленных веб-сервисов по всему интернету. Даже такие крупные компании, как Netflix и Uber, используют Node.js для работы своих сервисов.
Для Node.js также доступно множество модулей, которые можно развернуть для добавления дополнительной функциональности в проект. Когда дело доходит до CSV, существует множество доступных для использования модулей, например, node-csv, fast-csv, и papaparse и т. д.
Как следует из названия руководства, мы собираемся использовать node-csv для чтения файлов CSV с использованием потоков Node.js. Мы также продемонстрируем работу с проанализированными данными, например, перенос данных в базу данных SQLite.
Предварительные требования
-
Для выполнения шагов, описанных в этом руководстве, вам понадобятся следующие компоненты:
-
Правильно настроенная система Linux. Узнайте больше об установке и настройке облачного сервера Ubuntu на CloudSigma.
-
Доступ к пользователю без прав root с привилегиями sudo. Ознакомьтесь с управлением правами sudo с помощью sudoers.
-
Подходящий текстовый редактор, например, Brackets, VS Code, Sublime Text, Vim/NeoVim и т. д.
-
Другое программное обеспечение:
-
Node.js LTS
-
SQLite
-
Шаг 1 – Установка необходимого программного обеспечения
Для этого руководства я создал легковесный сервер под управлением Ubuntu 22.04 LTS (подключение по SSH):
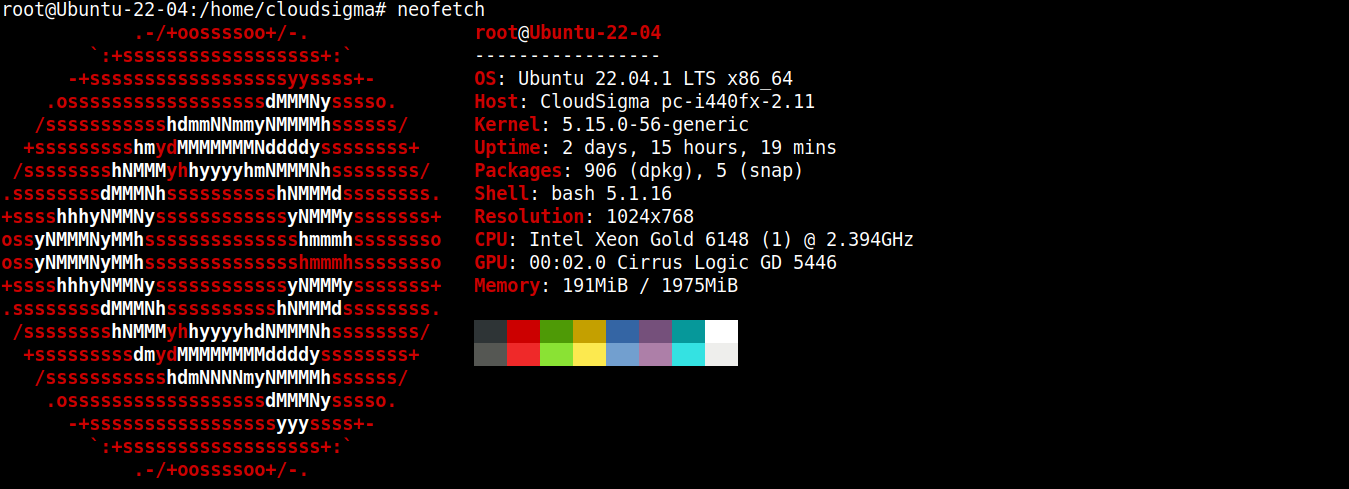
Теперь мы установим на него Node.js и SQLite.
-
Установка Node.js LTS
Node.js доступен напрямую из официальных репозиториев пакетов Ubuntu. Однако это не самая актуальная версия. Вот почему мы будем полагаться на сторонний репозиторий (Nodesource) для получения последних пакетов Node.js.
Добавьте репозиторий для Node.js LTS:
|
1 |
curl -fsSL https://deb.nodesource.com/setup_lts.x | sudo -E bash - |
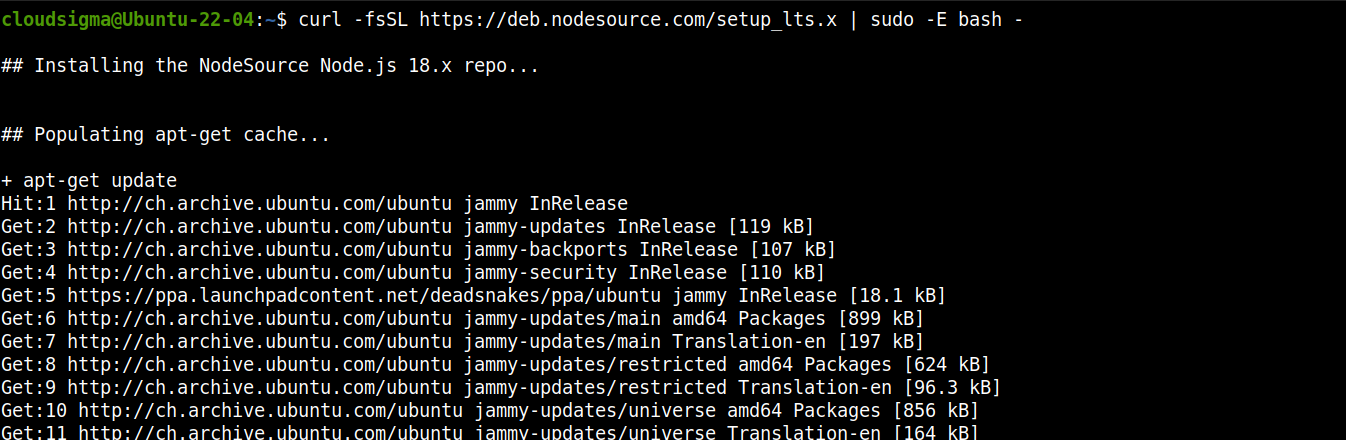
Теперь установите Node.js LTS:
|
1 |
sudo apt install nodejs -y |

-
Установка SQLite
Мы будем устанавливать SQLite напрямую из репозиториев пакетов Ubuntu. Выполните следующие команды:
|
1 |
sudo apt install sqlite3 -y |

Шаг 2 – Настройка каталога проекта
В этом разделе мы подготовим специальный каталог для нашего проекта. В нем будут размещаться все файлы проекта вместе с дополнительными модулями.
Создайте новый каталог:
|
1 |
mkdir -pv csv_practice |
Перейдите в этот каталог:
|
1 |
cd csv_practice/ |
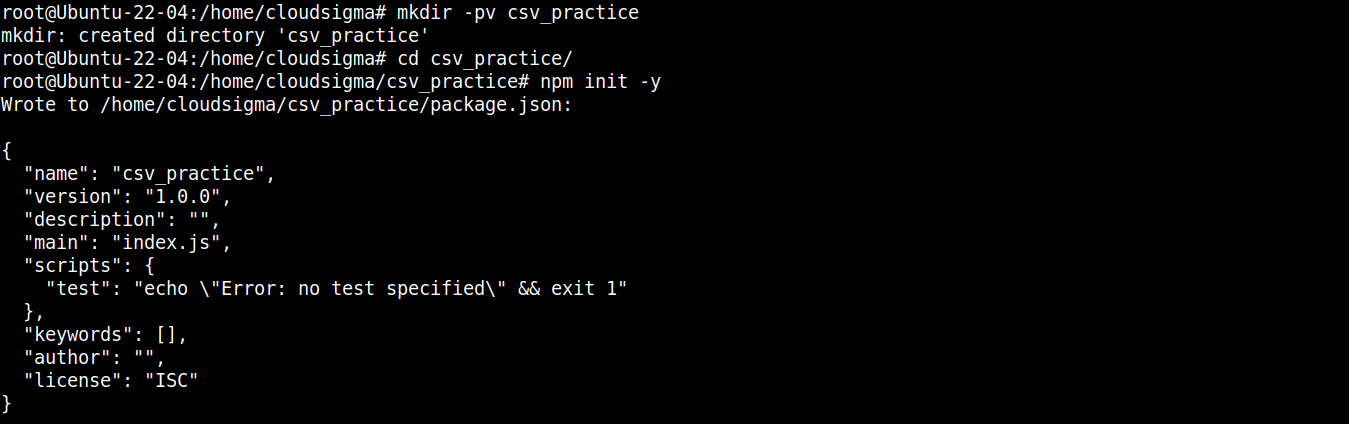
Затем выполните следующую команду, чтобы объявить каталог как npm проект:
|
1 |
npm init -y |
После инициализации папки проекта мы можем приступить к установке необходимых пакетов и модулей. Сначала мы установим node-csv:
|
1 |
npm install csv |

Модуль node-csv на самом деле представляет собой набор из нескольких других модулей: csv-generate, csv-parse (парсинг файлов CSV), csv-stringify (запись данных в CSV) и stream-transform.
Далее нам понадобится модуль для взаимодействия с SQLite. Следующая команда установит модуль node-sqlite3:
|
1 |
npm install sqlite3 |

Компонент, который нам нужен для нашего проекта, — это файл CSV. В демонстрационных целях мы будем использовать CSV-файл миграции Новой Зеландии:
|
1 |
wget https://www.stats.govt.nz/assets/Uploads/International-migration/International-migration-September-2021-Infoshare-tables/Download-data/international-migration-September-2021-estimated-migration-by-age-and-sex-csv.csv -O migration_data.csv |
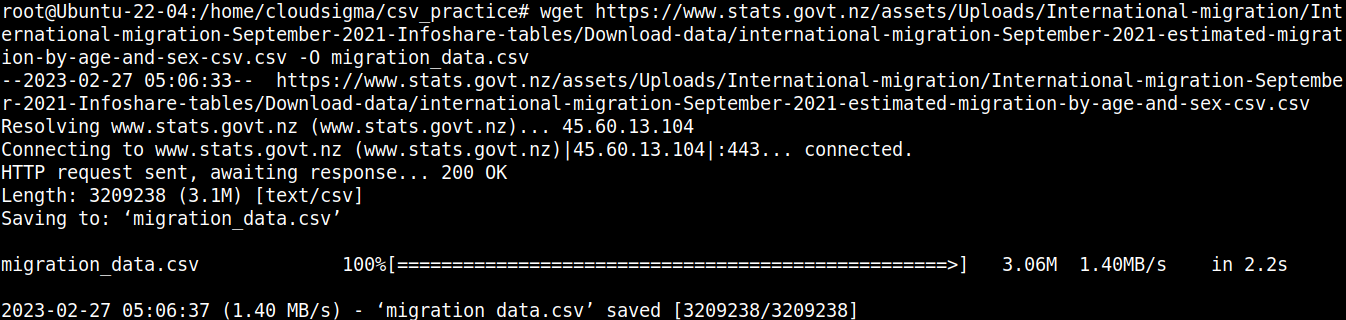
Давайте быстро взглянем на содержимое файла:
|
1 |
cat migration_data.csv | less |
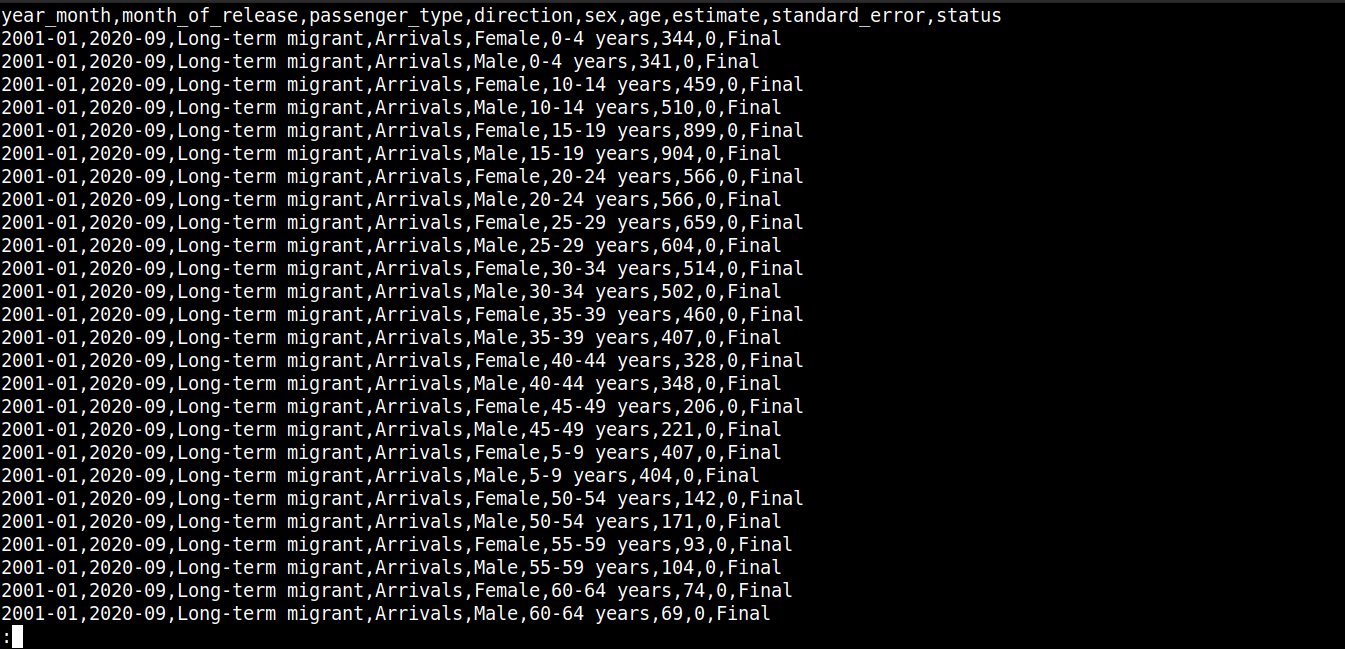
Здесь,
-
Первая строка описывает имена столбцов.
-
Последующие строки содержат значения для этих полей.
-
Каждая строка разделена новой строкой (\n).
-
Каждая точка данных разделена запятой (,).
Однако CSV не ограничивается использованием запятых в качестве разделителя. Другие распространенные разделители включают двоеточия (:), точки с запятой (;) и табуляцию (\td).
Шаг 3 – Чтение CSV
В этом разделе мы продемонстрируем реализацию примера программы, которая считывает и анализирует данные из CSV-файла.
Создайте новый JavaScript файл:
|
1 |
touch read_csv.js |
Откройте файл в вашем любимом текстовом редакторе:
|
1 |
nano read_csv.js |
Сначала мы импортируем модули fs и csv-parse:
|
1 2 |
const fs = require("fs"); const { parse } = require("csv-parse"); |
Здесь,
-
Во-первых, переменной fs присваивается объект fs, который возвращает метод Node.js require() при импорте модуля.
-
Затем метод parse извлекается из объекта, возвращаемого методом require(), в переменную parse с использованием синтаксиса деструктуризации.
Далее мы добавим код для чтения CSV-файла:
|
1 2 3 4 5 |
fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) |
Здесь,
-
Мы вызываем createReadStream() из модуля fs и передаем CSV-файл, который хотим прочитать, в качестве аргумента. Затем он создает поток для чтения, разбивая большой файл на более мелкие части.
-
После создания потока метод pipe() перенаправляет части данных потока в другой поток. Этот новый поток создается при вызове метода parse() из csv-модуля.
-
The csv- модуль развертывает поток преобразования чтения/записи, который принимает фрагмент данных и преобразует его в другую форму.
-
Метод parse() принимает объекты со свойствами. Объект далее обрабатывает проанализированные данные. Здесь объект принимает следующие свойства:
-
delimiter: Символ-разделитель для разделения значений. В случае нашего целевого CSV это запятая (,).
-
from_line: Номер строки, с которой парсер начнет синтаксический анализ. При заданном значении 2 парсер пропустит строку 1 и начнет со строки 2. Таким образом, мы избегаем интеграции имен столбцов в проанализированные данные.
-
Далее мы собираемся прикрепить потоковое событие с помощью метода on() из Node.js:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) .on("end", function () { console.log("finished"); }) .on("error", function (error) { console.log(error.message); }); |
Здесь,
-
При возникновении определенного события потоковое событие позволяет методу потреблять фрагмент данных.
-
Когда данные, проанализированные методом parse(), готовы к потреблению, это вызывает событие data.
-
Для доступа к данным мы передаем функцию обратного вызова методу on(), который принимает параметр row.
-
Параметр row представляет собой фрагмент данных в виде массива (результат синтаксического анализа).
-
Наконец, данные выводятся в консоль с помощью console.log().
Чтобы завершить программу, мы добавим дополнительные потоковые события для обработки ошибок и вывода сообщения об успешном завершении, когда все данные в CSV-файле будут обработаны. Обновите код следующим образом:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) .on("end", function () { console.log("finished"); }) .on("error", function (error) { console.log(error.message); }); |
Здесь,
-
Событие end генерируется, когда все данные из CSV-файла будут обработаны. Это приводит к вызову console.log() метода, который выводит сообщение об успешном завершении.
-
Событие error генерируется при возникновении ошибки во время парсинга данных CSV. Это приводит к вызову console.log() метода, который выводит сообщение об ошибке.
Итоговый код должен выглядеть следующим образом:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
const fs = require("fs"); const { parse } = require("csv-parse"); fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) .on("end", function () { console.log("finished"); }) .on("error", function (error) { console.log(error.message); }); |
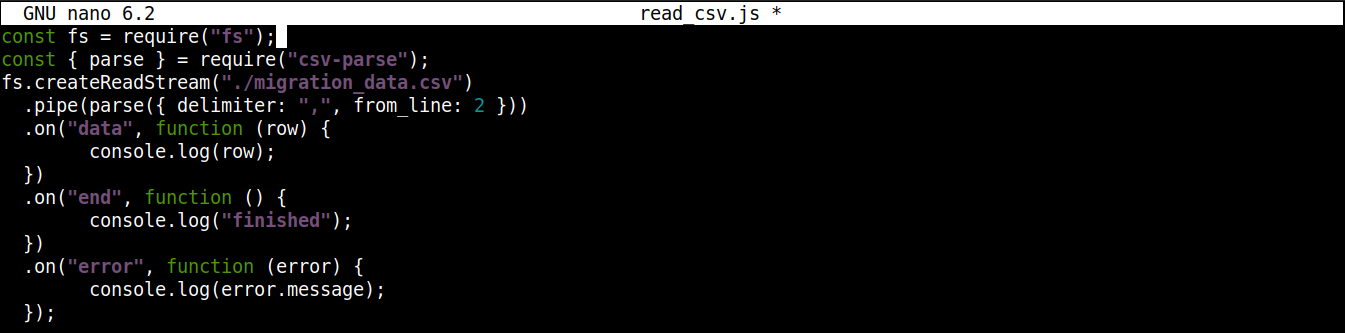
Сохраните файл и закройте редактор. Теперь мы готовы запустить программу. Запустите её с помощью Node.js:
|
1 |
node read_csv.js |
Вывод должен выглядеть примерно так:

Обратите внимание, что данные считываются, преобразуются и выводятся в консоль. Поскольку это непрерывный процесс, это будет выглядеть так, будто данные загружаются, а не выводятся все сразу.
Шаг 4 – Перенос данных CSV в базу данных
Итак, мы узнали, как парсить CSV-файл с помощью node-csv. В этом разделе будет показан перенос спарсенных данных в базу данных (SQLite).
Создайте новый файл JavaScript для взаимодействия с базой данных:
|
1 |
touch csv-to-sqlite3.js |
Теперь откройте файл в текстовом редакторе:
|
1 |
nano csv-to-sqlite3.js |
![]()
Мы начнем нашу программу со следующего кода:
|
1 2 3 |
const fs = require("fs"); const sqlite3 = require("sqlite3").verbose(); const filepath = "./population.db"; |

Здесь,
-
В первой строке мы импортируем fs модуль.
-
В третьей строке переменная filepath содержит путь к базе данных SQLite.
-
На данный момент базы данных еще не существует. Однако она понадобится при работе с node-sqlite3.
Затем добавьте следующие строки, чтобы установить соединение с базой данных SQLite:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
function connectToDatabase() { if (fs.existsSync(filepath)) { return new sqlite3.Database(filepath); } else { const db = new sqlite3.Database(filepath, (error) => { if (error) { return console.error(error.message); } console.log("Успешное подключение к базе данных"); }); return db; } } |
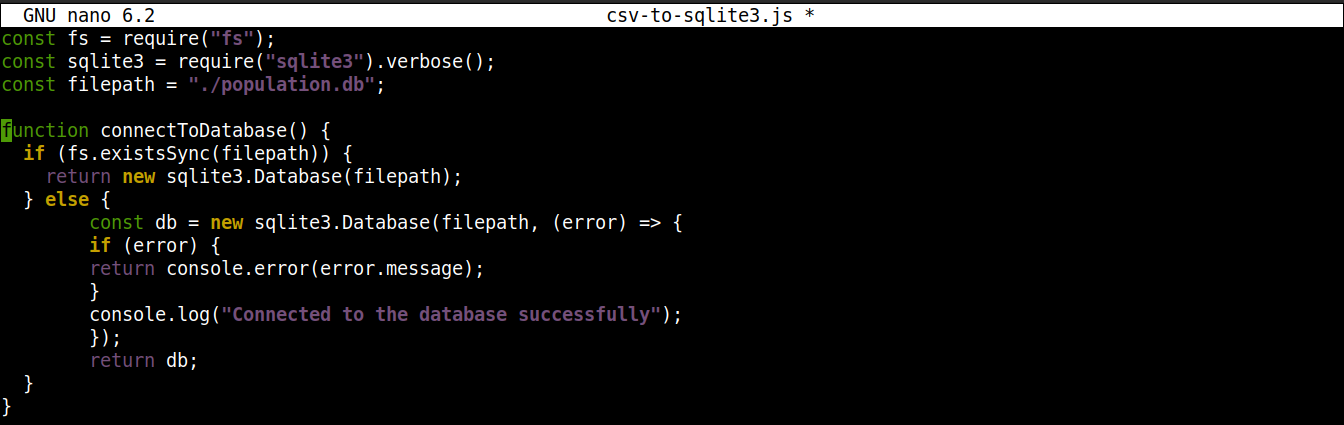
Здесь,
-
Метод connectoToDatabase() устанавливает соединение с базой данных.
-
Внутри connectToDatabase(), мы вызываем метод existsSync() из модуля fs внутри оператора if. Оператор if проверяет существование базы данных в указанном месте.
-
Если результат вычисления условия равен true, то класс Database() модуля node-sqlite3 инициализируется. Как только соединение установлено, функция возвращает объект и завершает работу.
-
Если результат вычисления условия равен false (база данных не существует), то выполнение перейдет к блоку else. Там класс Database() будет инициализирован с двумя аргументами: путем к файлу базы данных и функцией обратного вызова.
-
По сути, база данных будет создана, если она не существует. Однако, если в процессе создания возникнет какая-либо ошибка, это приведет к установке объекта error и выводу сообщения об ошибке.
Далее мы представим код для создания таблицы, если база данных не существует:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
const fs = require("fs"); const sqlite3 = require("sqlite3").verbose(); const filepath = "./population.db"; function connectToDatabase() { if (fs.existsSync(filepath)) { return new sqlite3.Database(filepath); } else { const db = new sqlite3.Database(filepath, (error) => { if (error) { return console.error(error.message); } createTable(db); console.log("Успешное подключение к базе данных"); }); return db; } } function createTable(db) { db.exec(` CREATE TABLE migration ( year_month VARCHAR(10), month_of_release VARCHAR(10), passenger_type VARCHAR(50), direction VARCHAR(20), sex VARCHAR(10), age VARCHAR(50), estimate INT ) `); } module.exports = connectToDatabase(); |
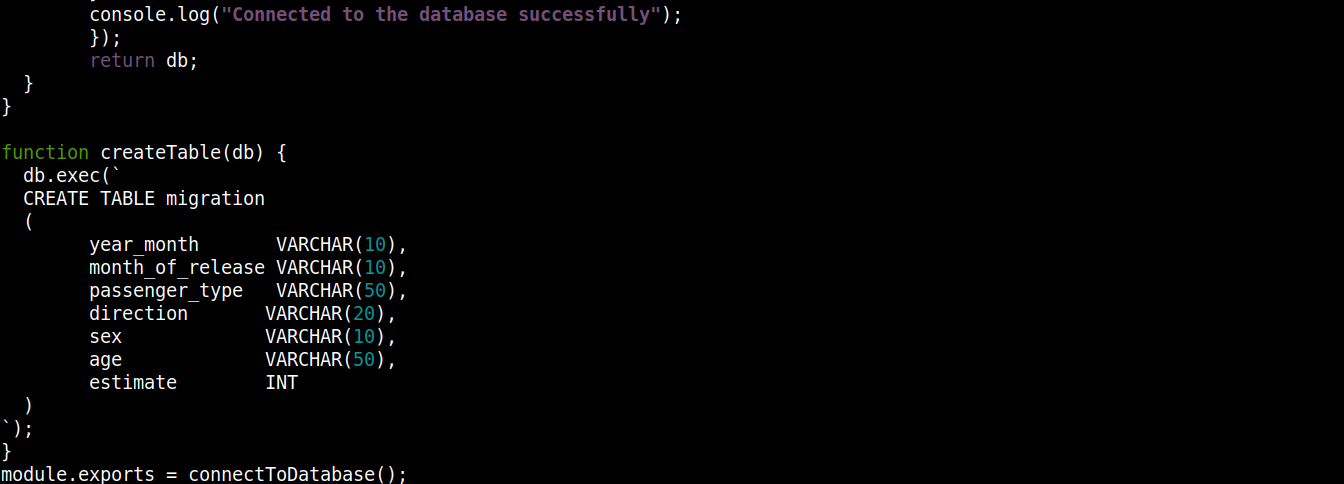
Здесь,
-
Функция connectToDatabase() вызывает функцию createTable(), которая принимает объект, хранящийся в db, в качестве аргумента.
-
Вне connectToDatabase(), мы определили метод createTable(), который принимает объект подключения db в качестве параметра.
-
Метод exec() объекта db принимает SQL-инструкцию в качестве аргумента. Внутри этой SQL-инструкции мы определили создание таблицы migration с 7 столбцами, каждый из которых соответствует заголовкам столбцов в файле migration_data.csv .
-
Наконец, мы вызываем connectToDatabase() метод и экспортируем возвращаемый им объект подключения, чтобы мы могли использовать его в других файлах.
Сохраните файл и закройте редактор.
Далее мы создадим еще одну программу для вставки проанализированных данных в базу данных:
|
1 |
nano insert_data.js |
Введите следующий код в insert_data.js:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
const fs = require("fs"); const { parse } = require("csv-parse"); const db = require("./csv-to-sqlite3"); fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { db.serialize(function () { db.run( `INSERT INTO migration VALUES (?, ?, ? , ?, ?, ?, ?)`, [row[0], row[1], row[2], row[3], row[4], row[5], row[6]], function (error) { if (error) { return console.log(error.message); } console.log(`Row inserted, ID: ${this.lastID}`); } ); }); }); |
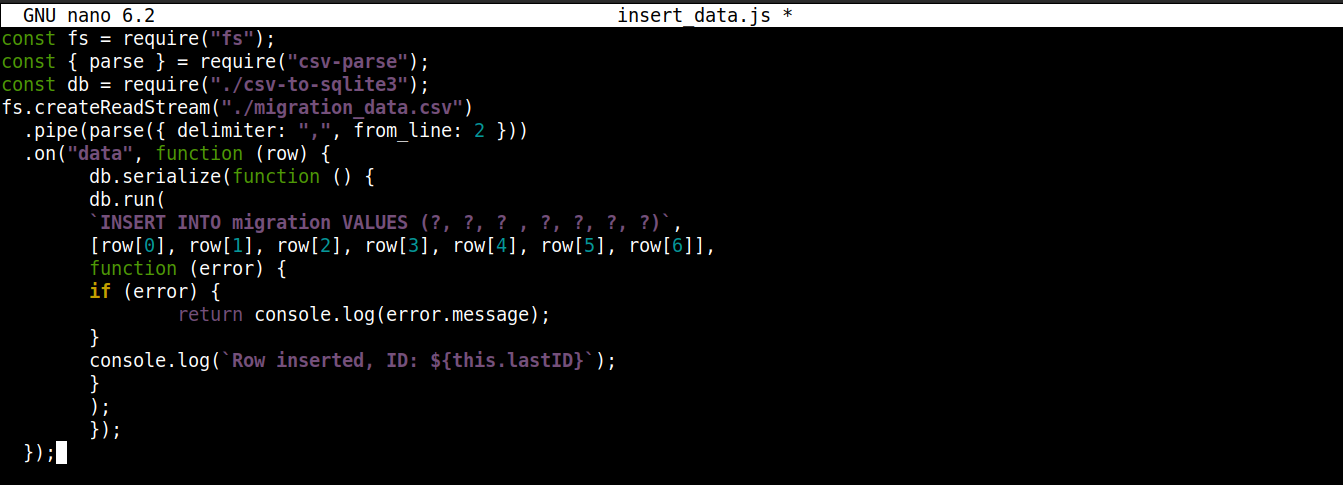
Здесь,
-
Мы сохраняем объект подключения, полученный из csv-to-sqlite3.js в переменной db.
-
Внутри обратного вызова события data (прикрепленного к потоку модуля fs) мы вызываем метод serialize() объекта подключения. Он гарантирует, что выполнение одной инструкции SQL завершится до начала следующей, предотвращая состояние гонки в базе данных (когда система выполняет конкурирующие операции одновременно).
-
Метод serialize() принимает три аргумента:
-
Первый аргумент — это SQL-инструкция.
-
Второй аргумент — это массив.
-
Третий аргумент — это обратный вызов, который выполняется при успешной или неуспешной вставке данных в базу данных.
-
Мы готовы запустить программу. Выполните insert_data.js с помощью Node.js:
|
1 |
node insert_data.js |
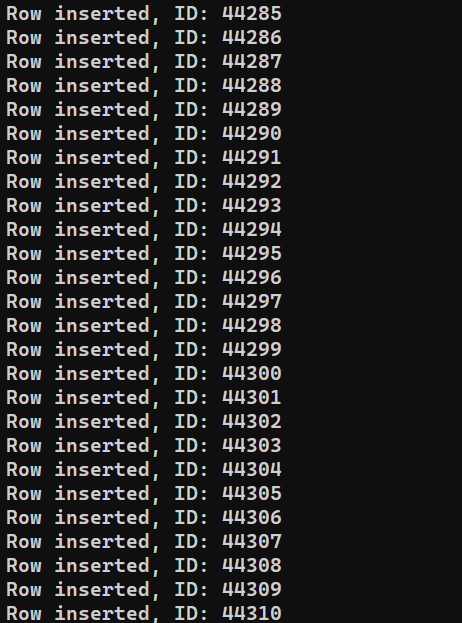
В зависимости от производительности системы процесс может занять некоторое время. Однако после его завершения вывод должен выглядеть примерно так:
Шаг 5 – Запись данных в CSV
После предыдущего раздела у нас есть база данных, содержащая все записи, которые мы извлекли из migration_data.csv. В этом разделе мы собираемся прочитать данные из базы данных и записать их в отдельный CSV-файл.
Создайте новый файл JavaScript для хранения программы:
|
1 |
nano write_csv.js |
Сначала добавьте следующие строки для импорта fs и csv-stringify вместе с объектом подключения к базе данных из csv-to-sqlite3.js:
|
1 2 3 |
const fs = require("fs"); const { stringify } = require("csv-stringify"); const db = require("./csv-to-sqlite3"); |
Затем мы добавим переменную, которая содержит имя CSV-файла для записи, а также записываемый поток:
|
1 2 3 4 5 6 7 8 9 10 11 |
const filename = "saved_from_db.csv"; const writableStream = fs.createWriteStream(filename); const columns = [ "year_month", "month_of_release", "passenger_type", "direction", "sex", "age", "estimate", ]; |
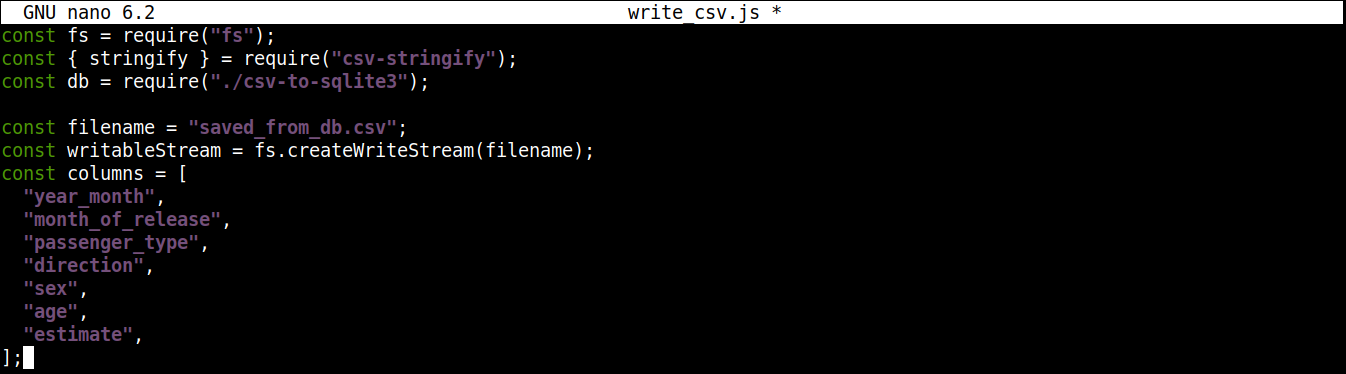
Здесь,
-
Метод createWriteStream() принимает имя файла для записи в качестве аргумента. Мы назовем файл saved_from_db.csv.
-
Переменная column хранит массив, содержащий все имена заголовков для данных CSV.
Затем добавьте следующие строки кода, чтобы прочитать данные из базы данных и записать их в saved_from_db.csv:
|
1 2 3 4 5 6 7 8 9 10 11 |
const stringifier = stringify({ header: true, columns: columns }); db.each(`select * from migration`, (error, row) => { if (error) { return console.log(error.message); } stringifier.write(row); }); stringifier.pipe(writableStream); console.log("запись в CSV завершена"); |
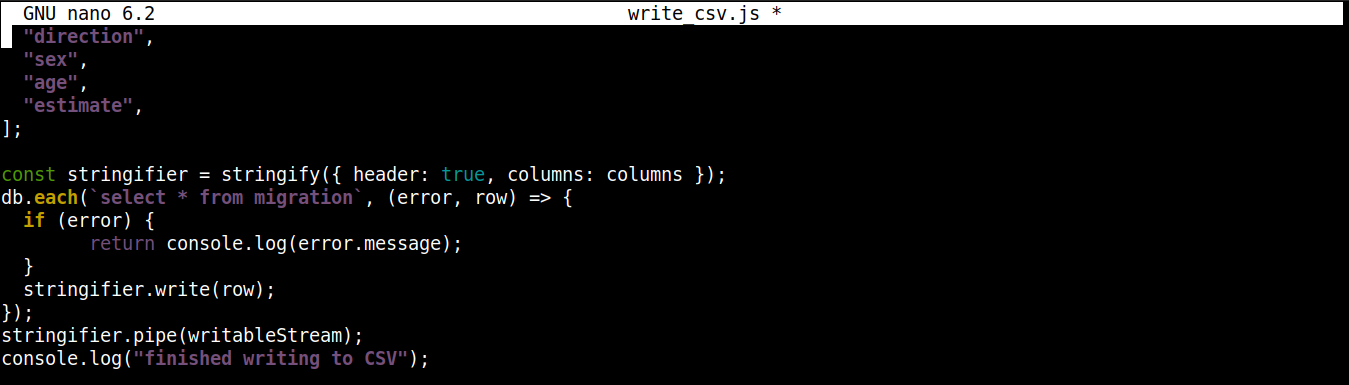
Здесь,
-
Мы вызываем метод stringify() с объектом в качестве аргумента. В результате создается поток преобразования (transform stream), который преобразует данные из объекта в формат CSV. Объект, переданный в stringify(), имеет два свойства:
-
header: принимает логическое значение. Если значение равно true, то генерируется заголовок.
-
columns: принимает массив, содержащий имена столбцов, которые будут записаны в первой строке CSV-файла, если header имеет значение true.
-
-
Метод each() из объекта соединения csv-to-sqlite3 вызывается с двумя аргументами: SQL-инструкцией (чтение данных из базы данных) и колбэком (обработка успешного выполнения/ошибки).
-
При каждой итерации each(), pipe() (из потока stringifier ) начинает отправлять данные частями в записываемый поток writableStream. Затем каждая часть данных записывается в saved_from_db.csv.
-
Когда все данные будут записаны в CSV-файл, на экран консоли будет выведено сообщение об успешном завершении.
Итоговый код должен выглядеть следующим образом:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
const fs = require("fs"); const { stringify } = require("csv-stringify"); const db = require("./csv-to-sqlite3"); const filename = "saved_from_db.csv"; const writableStream = fs.createWriteStream(filename); const columns = [ "year_month", "month_of_release", "passenger_type", "direction", "sex", "age", "estimate", ]; const stringifier = stringify({ header: true, columns: columns }); db.each(`select * from migration`, (error, row) => { if (error) { return console.log(error.message); } stringifier.write(row); }); stringifier.pipe(writableStream); console.log("finished writing to CSV"); |
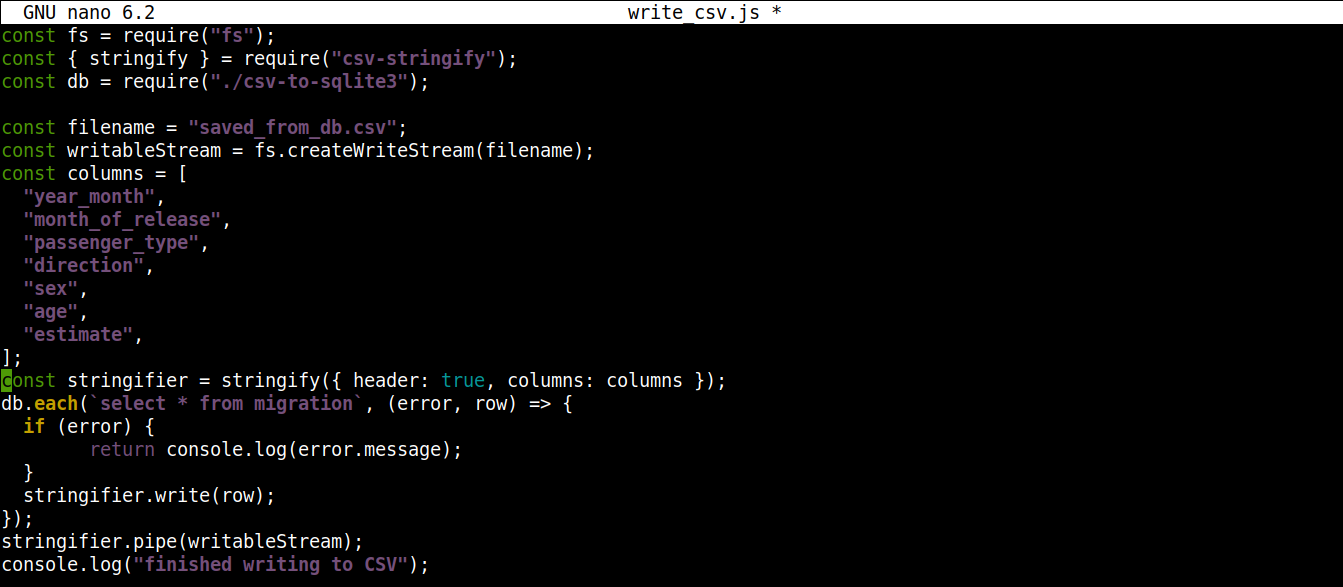
Сохраните файл и закройте редактор. Теперь мы можем запустить программу с помощью Node.js:
|
1 |
node write_csv.js |
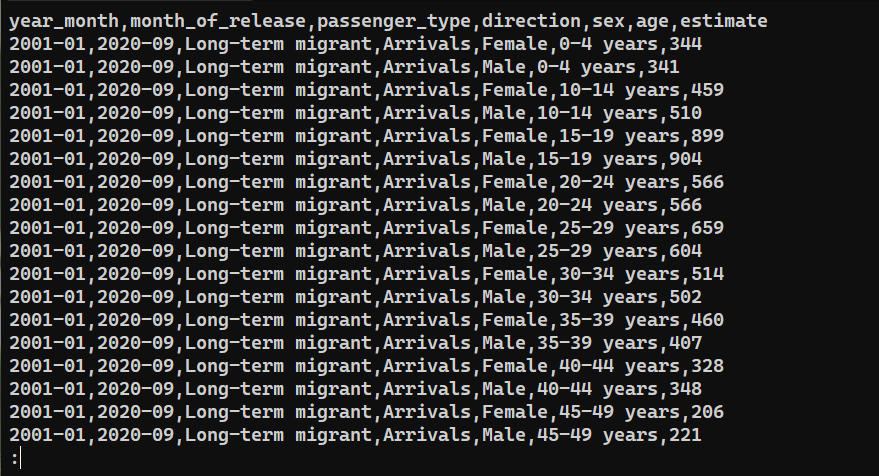
Чтобы убедиться, что данные были успешно экспортированы, проверьте содержимое saved_from_db.csv:
|
1 |
cat saved_from_db.csv | less |
Заключение
В этом руководстве мы продемонстрировали работу с файлами CSV в Node.js с использованием модулей node-csv и node-sqlite3. Мы создали несколько программ для решения различных задач, например, парсинга данных из CSV, вставки данных в базу данных SQLite и записи данных в новый файл CSV.
Это руководство демонстрирует лишь малую часть возможностей node-csv модуля. Узнайте больше обо всех его возможностях на CSV Project. Чтобы узнать больше о node-sqlite3, ознакомьтесь с официальной документацией на GitHub. Еще один модуль, который стоит упомянуть, — это event-stream для упрощения работы с потоками.
Хотите развивать свой проект на Node.js дальше? Вот несколько руководств по Node.js, с которыми вам стоит ознакомиться:
-
Использование модулей Node.js с npm и package.json: руководство
-
Как развернуть приложение Node.js (Express.js) с помощью Docker на Ubuntu 20.04
Приятной работы!
Комментарии
Комментариев пока нет. Будьте первым.