

Бизнес предполагает огромные объемы данных, что усложняет задачу их обработки и управления. Традиционно в течение десятилетий в отрасли использовались системы RDBMS, но с появлением Big Data в XXI веке для крупномасштабных неструктурированных и полуструктурированных данных на сцену вышли базы данных NoSQL (Not only SQL).
В этой статье я собираюсь настроить кластер MongoDB.
MongoDB — это бесплатная документоориентированная база данных NoSQL с открытым исходным кодом, которая широко используется благодаря обеспечиваемому ею высокому уровню масштабируемости и гибкости.
Для развертывания MongoDB в рабочей среде рекомендуется использовать наборы реплик (Replica Sets). Наборы реплик — это эквивалент конфигурации Master/Slave в реляционном мире для MongoDB, но, в отличие от нее, они настраиваются очень легко, так как все уже встроено. Подробнее о наборах реплик читайте в определении процесса репликации от TutorialsPoint’s.
Планирование кластера облачных серверов MongoDB
Я собираюсь создать кластер из 3 узлов. Важно предоставить им одинаковые ресурсы, так как любой из них может стать основным (т. е. master) сервером. Эти узлы или машины могут работать под управлением любой операционной системы, но в этом руководстве я буду использовать Ubuntu 18.04 LTS. О том, как подключить и настроить предустановленный образ из библиотеки CloudSigma’s, вы можете узнать в этом руководстве.
Поскольку весь смысл набора реплик (Replica Set) заключается в том, что кластер должен выдерживать выход из строя одного узла, было бы довольно бессмысленно, если бы все ваши серверы находились на одном физическом хосте. К счастью, CloudSigma предлагает функцию под названием группы доступности. Это означает, что вы можете дать системе команду распределить все три ваших сервера по разным группам. Таким образом, они никогда не будут находиться на одном физическом хосте. Дополнительную информацию об этом, а также о других функциях безопасности и обеспечения непрерывности бизнеса можно найти здесь.
Также важно использовать 64-разрядную версию Linux. Причина проста: MongoDB плохо работает на 32-разрядных системах (подробнее об этом здесь).
Установка MongoDB в облаке
Этот раздел довольно прост. Либо используйте один из предварительно настроенных Ubuntu 18.04 образов, либо установите его самостоятельно.
Конфигурация CPU, RAM и диска действительно индивидуальна и зависит от вашей нагрузки. Для небольшой установки должно быть достаточно CPU 4 GHz, RAM 4 GB и диска 10 GB (для системы). При подключении дисков убедитесь, что вы используете VirtIO. Если вы используете IDE, производительность существенно снизится. Кроме того, поскольку вы создаете набор реплик (Replica Set), вам необходимо, чтобы все узлы (и серверы приложений) находились в одной VLAN.
В отличие от многих других облачных провайдеров, здесь нет необходимости настраивать хранилище с использованием RAID10 или аналогичных технологий для повышения производительности. Как отмечают многие наши клиенты, вы получите потрясающую производительность «из коробки», используя как SSD, так и магнитные диски в CloudSigma.
Я все же рекомендую хранить данные MongoDB на отдельном диске. Причина этого проста: в какой-то момент вам может потребоваться провести оптимизацию файловой системы, которую вы бы не хотели применять ко всей файловой системе.
Исходя из этого, проще всего добавить этот диск после настройки серверов. А пока давайте сосредоточимся на установке системы. Если вы устанавливаете систему самостоятельно (а не используете предварительно настроенные системы), я рекомендую нажать F4 в меню загрузки и выбрать ‘Install a minimal virtual machine’.
Я создаю 3 машины, каждая со следующими характеристиками:
- CPU: 4 GHz
- RAM: 4 GB
- SSD: 10 GB (Ubuntu 18.04 LTS), 20 GB (дополнительный диск)
Как указано в разделе SSD, я подключаю диск размером 10 GB с установленной на нем Ubuntu 18.04 LTS.
Кроме того, я подключаю к нему еще один пустой диск размером 20 GB для хранения данных MongoDB. Его размер во многом зависит от ваших потребностей, но для небольшой системы 20GB должно быть достаточно. Однако, поскольку иногда трудно предсказать, какой объем данных вы будете хранить, мы будем использовать LVM. Это позволит вам просто добавить еще один диск позже и расширить том без необходимости начинать все сначала. Кроме того, вы можете использовать один диск и масштабировать его позже с помощьюresize2fs.
Чтобы добавить диск, просто перейдите в раздел ‘Drives’, нажмите на иконку ‘Create a new drive’ вверху, задайте новому диску имя и размер 20 ГБ. Как только он будет сохранен, перейдите к конкретной машине, к которой вы хотите его подключить, и в разделе дисков в свойствах этой машины нажмите ‘Attach a drive’ и выберите диск.
Теперь, когда у вас есть три машины, вы можете перейти к монтированию дополнительного диска, добавленного для хранения данных MongoDB, на каждую машину. Я рекомендую добавить этот диск как раздел. Использование разделов позволяет операционной системе управлять информацией в каждой области отдельно. Чтобы добавить диск в качестве раздела, я сначала проверю все диски, подключенные к нашей машине. Для этого я выполню следующую команду:
|
1 |
fdisk -l |
При выполнении этой команды я получаю вывод с указанием дисков и устройств на моей машине.
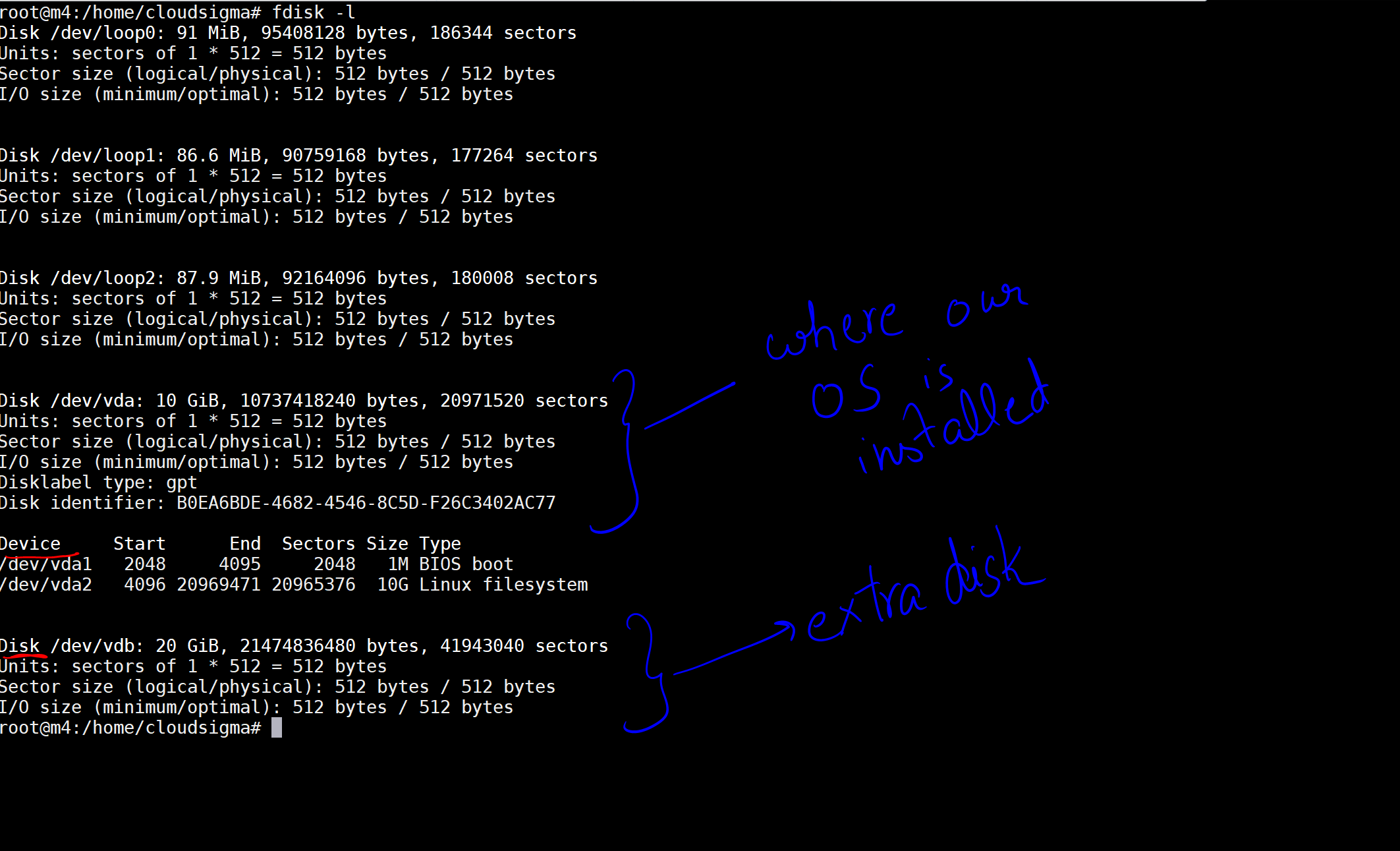
На изображении я отметил диск размером 10 ГБ как диск, на котором установлена наша ОС. Также имеется еще один диск размером 20 ГБ, который теперь подключен. Путь к диску: /dev/vdb. Вы можете создать раздел на этом диске с помощью следующих команд:
|
1 |
sudo fdisk /dev/vdb |
Это откроет утилиту fdisk — утилиту командной строки, предоставляющую функции разбиения диска на разделы, в которой вы можете создавать разделы на нашем диске. Появится запрос “Command (m for help):”, где вам нужно ввести n, чтобы создать новый раздел, а затем просто продолжайте нажимать Enter для принятия значений по умолчанию. И после того, как раздел будет создан, введите w, чтобы записать изменения. Это будет выглядеть следующим образом:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
Команда (m для справки): <strong>n</strong> Раздел тип p основной (0 основной, 0 расширенный, 4 свободно) e расширенный (контейнер для логических разделов) Выберите (по умолчанию p): Используется по умолчанию ответ p. Раздел номер (1-4, по умолчанию 1): Первый сектор (2048-41943039, по умолчанию 2048): Последний сектор, +секторы или +размер{K,M,G,T,P} (2048-41943039, по умолчанию 41943039): Создан a новый раздел 1 типаtype 'Linux' и размеромsize 20 ГиБ. Команда (m для справки): <strong>w</strong> The Таблица разделов была измененаaltered. Вызов ioctl() для повторного -чтения таблицы разделов. Синхронизация дисков. |
Был создан новый раздел 1 типа ‘Linux’ и размером 20 ГиБ. Теперь, когда раздел создан, давайте создадим пул LVM:
|
1 2 3 |
sudo pvcreate /dev/vdb1 sudo vgcreate mongodb /dev/vdb1 sudo lvcreate -n db -L 19.5g mongodb |
Я ввел ‘19.5g’, так как размер моего раздела составляет 20g. Далее выполните следующую команду, чтобы узнать имя диска:
|
1 |
fdisk -l | grep mongo | awk '{print $2'} |
После этого отформатируйте диск в файловую систему ext4 с помощью следующей команды:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
sudo mkfs.ext4 /dev/mapper/mongodb-db Вывод: root@m4:/home/cloudsigma# sudo mkfs.ext4 /dev/mapper/mongodb-db mke2fs 1.44.1 (24-Мар-2018) Создание файловой системы с 5217280 4k блоками и 1305600 inodes Файловая система UUID: 695a62e6-021d-4fc0-945c-cc51a92d86da Суперблок резервные копии сохранены в блоках: 32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208, 4096000 Выделение групп таблиц: готово Запись inodes таблиц: готово Создание журнала (32768 блоков): готово Запись суперблоков и файловой системы учетной информации: готово |
Далее давайте создадим точку монтирования для диска и папку для хранения данных MongoDB.
|
1 |
sudo mkdir -p /mongodb/data |
Чтобы добавить запись о монтировании нового диска в fstab, вы можете напрямую использовать команду ниже:
|
1 |
echo -e "` blkid | grep mongodb | awk {'print $2'}`\t/mongodb\text4 auto,noexec,rw,sync,nouser\t0\t0" >> /etc/fstab |
В этой команде blkid возвращает UUID – универсальный уникальный идентификатор каждого диска. Здесь я извлекаю UUID для диска MongoDB с помощью grep и объединяю этот UUID с путем к папке монтирования, типом файловой системы и другими параметрами диска соответственно. Я добавляю эту строку в /etc/fstab. Если вы этого не сделаете, при монтировании диска возникнет ошибка. Запись выглядит следующим образом:
UUID=”695a62e6-021d-4fc0-945c-cc51a92d86da” /mongodb ext4 auto,noexec,rw,sync,nouser 0 0
Теперь вы можете смонтировать диск в директорию /mongodb:
|
1 |
sudo mount /mongodb |
Установка MongoDB
После подготовки системы перейдем к установке MongoDB. Хотя Ubuntu предлагает версию MongoDB в собственном репозитории, я рекомендую использовать официальную версию MongoDB. Причина в том, что репозиторий Ubuntu сильно отстает по версиям, поэтому, если вы хотите получить максимум от MongoDB, вам придется обратиться к официальным релизам.
Поскольку MongoDB предоставляет собственный репозиторий, вы можете просто добавить его в свою систему, а затем установить MongoDB как обычно. Вот шаги, которые необходимо выполнить:
Сначала импортируйте публичный ключ, используемый системой управления пакетами:
|
1 |
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 9DA31620334BD75D9DCB49F368818C72E52529D4 |
Затем я создаю файл списка. Он будет содержать репозиторий, в котором находится MongoDB, чтобы ваша система могла загрузить ее оттуда:
|
1 |
echo "deb [ arch=amd64 ] https://repo.mongodb.org/apt/ubuntu bionic/mongodb-org/4.0 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-4.0.list |
Теперь я обновляю локальную базу данных пакетов, чтобы учесть изменения.
|
1 |
sudo apt-get update |
Теперь я могу просто установить пакет с помощью следующей команды:
|
1 |
sudo apt-get install -y mongodb-org |
Я установил MongoDB на каждую из машин.
|
1 |
sudo service mongod start |
Теперь MongoDB запущена и работает, а данные на созданном диске сохранены. Если ожидается высокая нагрузка и/или большое количество подключений, вам может потребоваться увеличить ulimit значения.
Если вы хотите получить больше информации о своих данных, вы также можете зарегистрироваться в MMS от MongoDB — бесплатной облачной службе мониторинга.
Создание набора реплик (Replica Set) для вашего облака MongoDB
Теперь давайте создадим набор реплик. Перед этим вам необходимо убедиться, что все машины могут взаимодействовать друг с другом. Для этого добавьте следующие записи в /etc/hosts
|
1 2 3 |
IP-1 m1.mongo.cluster m1 IP-2 m2.mongo.cluster m2 IP-3 m3.mongo.cluster m3 |
Для проверки вы можете попробовать выполнить команду ping для машин, используя имя хоста. Так, если IP-адрес моей машины 1 — это IP-1, скажем, 213.189.123.12, то вместо того, чтобы писать
|
1 |
ping 123.189.123.12 |
я напишу,
|
1 2 3 |
ping m1.mongo.cluster или ping m1. |
Если вы активировали брандмауэр (что действительно стоит сделать), убедитесь, что узлы могут отправлять и получать TCP-трафик через порты 28017 и 27017 на внутреннем интерфейсе.
Теперь на каждой машине запустите службу mongod с помощью следующих команд.
На машине m1,
|
1 |
mongod --dbpath /mongodb/data --replSet rs0 --bind_ip localhost,m1.mongo.cluster |
Затем на машине m2,
|
1 |
mongod --dbpath /mongodb/data --replSet rs0 --bind_ip localhost,m2.mongo.cluster |
На машине m3,
|
1 |
mongod --dbpath /mongodb/data --replSet rs0 --bind_ip localhost,m3.mongo.cluster |
Здесь,
mongod — это имя службы
dbpath — это расположение каталога нашей базы данных
replSet — это имя нашего набора реплик. Оно должно быть одинаковым для каждой из машин в одном наборе реплик
bind_ip — это имя хоста той машины, на которой вы его запускаете.
После запуска службы mongod перейдите на первичный сервер (в моем случае я выбрал m1) и запустите mongo.
|
1 |
mongo |
Это запустит терминал MongoDB. В терминале инициализируйте replicaSet с помощью команды ниже. Она создаст replicaSet с конфигурациями по умолчанию:
|
1 |
rs.initiate() |
Теперь давайте просто добавим две другие машины в качестве реплик, используя следующие команды:
|
1 2 |
rs.add("m2.mongo.cluster") rs.add("m3.mongo.cluster") |
Вы можете следить за состоянием с помощью команды:
|
1 |
rs.status() |
Вот и всё. Теперь ваш кластер MongoDB должен быть запущен и работать в невероятно быстром облаке CloudSigma’s.
Комментарии
Комментариев пока нет. Будьте первым.