

Это руководство поможет вам настроить Kubernetes кластер с нуля с использованием Ansible и Kubeadm и последующим развертыванием контейнеризированного приложения Nginx с его помощью.
Введение
Kubernetes (также известный как k8s или “kube”) — это платформа оркестрации контейнеров с открытым исходным кодом, которая автоматизирует многие ручные процессы, связанные с развертыванием, управлением и масштабированием контейнеризированных приложений. У Kubernetes быстрорастущее сообщество с открытым исходным кодом, активно вносящее вклад в проект. Ознакомьтесь с нашей записью в блоге, которая познакомит вас со всем, что вам нужно знать об основах платформы Kubernetes.
Kubeadm — это инструмент, который настраивает несколько интегрированных элементов, частей и компонентов, таких как API-сервер, Controller Manager и Kube DNS. Он также помогает автоматизировать установку. Однако он не создает пользователей, не занимается установкой зависимостей на уровне операционной системы и их настройкой, а также не может подготавливать вашу инфраструктуру.
Ansible — это инструмент с открытым исходным кодом для подготовки программного обеспечения и развертывания приложений. Saltstack — это программное обеспечение с открытым исходным кодом для автоматизации информационных технологий на основе событий. Это два инструмента, которые делают создание дополнительных кластеров или воссоздание существующих кластеров менее подверженными ошибкам и могут использоваться для этих предварительных задач.
Цели:
Ваш кластер будет включать следующие физические ресурсы:
1. Один управляющий узел (master node):
Управляющий узел — это узел, который контролирует и управляет набором рабочих узлов (средой выполнения рабочих нагрузок) и представляет собой кластер в Kubernetes. Он также хранит план ресурсов узла для определения правильного действия при возникновении события. На нем работает etcd, распределенное хранилище ключей и значений с открытым исходным кодом, используемое для хранения и управления данными кластера между компонентами, которые планируют рабочие нагрузки на рабочие узлы.
Например, планировщик определяет, на каком рабочем узле будет размещен вновь запланированный POD.
2. Два рабочих узла (worker nodes):
Рабочие узлы — это узлы, которые продолжают выполнять назначенную им работу, даже если управляющий узел выходит из строя после завершения планирования. Рабочие узлы — это серверы, на которых будут выполняться ваши рабочие нагрузки (т. е. контейнеризированные приложения и службы). Вы также можете увеличить емкость кластера, добавив рабочие узлы.
После завершения этого руководства у вас будет полностью функциональный кластер, готовый к запуску рабочих нагрузок (т. е. контейнеризированных приложений и служб), при условии, что серверы в кластере имеют достаточные ресурсы процессора и оперативной памяти для работы ваших приложений. После успешной настройки кластера вы сможете запускать практически любое традиционное UNIX-приложение. Его можно контейнеризировать в вашем кластере, включая веб-приложения, базы данных, демоны и инструменты командной строки.
Сам кластер будет потреблять около 300-500 МБ памяти и 10% ресурсов процессора на каждом узле.
Предварительные требования:
- У вас должна быть пара SSH-ключей на вашей локальной машине Linux, и вы должны уметь использовать SSH-ключи. Однако, если вы ранее не использовали SSH-ключи, вы можете обратиться к этому руководству, которое поможет вам настроить SSH-ключи на локальной машине.
- Три сервера под управлением Ubuntu 18.04, каждый из которых имеет не менее 4 ГБ оперативной памяти и 4 виртуальных процессора (vCPU). У вас должна быть возможность подключаться к каждому серверу по SSH от имени пользователя root с помощью вашей пары SSH-ключей. Следуйте этому руководству для установки сервера Ubuntu.
- Установленный Ansible на вашей локальной машине.
- Вы также должны быть знакомы с плейбуками Ansible.
- Вам также потребуется знать, как запускать контейнер из образа Docker. Обратитесь к разделу “Шаг 5 — Работа с образами Docker в Ubuntu” в руководстве Как установить и использовать Docker на Ubuntu 18.04 , если вам нужно освежить знания.
Шаг 1 — Настройка каталога рабочей области и файла инвентаря Ansible
Сначала вам нужно настроить Ansible на вашей локальной машине. Это поможет вам выполнять команды на удаленном сервере. Это также упрощает ручное развертывание за счет его автоматизации. Для этого вам потребуется создать каталог на вашей локальной машине, который будет служить вашей временной областью цифрового хранения (рабочей областью).
После создания каталога вы создадите hosts — файл для хранения всей информации об IP-адресах и группах каждого сервера. Он поможет вам хранить инвентарную информацию внутри. Как было сказано ранее, серверов будет три: один главный (master) и два рабочих (worker). Главный сервер будет мастером с IP-адресом, отображаемым как master_ip. Другие два сервера будут рабочими и будут иметь IP-адреса worker_1_ip и worker_2_ip.
Вам нужно создать директорию с именем ~/kube-cluster в домашней директории вашей локальной машины и перейти в нее с помощью команды cd:
|
1 2 |
mkdir ~/kube-cluster cd ~/kube-cluster |
Директория ~/kube-cluster теперь будет служить временным цифровым хранилищем (рабочей областью), внутри которого вы будете запускать все локальные команды для создания кластера Kubernetes с помощью kubeadm. Эта директория будет содержать все ваши плейбуки Ansible и будет использоваться в оставшейся части руководства.
Создание файла hosts
Создайте файл с именем ~/kube-cluster/hosts с помощью nano или вашего любимого текстового редактора:
|
1 |
nano ~/kube-cluster/hosts |
Теперь вам нужно будет добавить следующий текст, который определит информацию о логической структуре вашего кластера:
|
1 2 3 4 5 6 7 8 9 |
[masters] master ansible_host=master_ip ansible_user=root [workers] worker1 ansible_host=worker_1_ip ansible_user=root worker2 ansible_host=worker_2_ip ansible_user=root [all:vars] ansible_python_interpreter=/usr/bin/python3 |
Как уже упоминалось, этот инвентарный файл поможет вам хранить всю информацию об IP-адресах ваших серверов и группах, к которым принадлежит каждый сервер. ~/kube-cluster/hosts будет вашим инвентарным файлом, а (masters и workers) будут двумя группами Ansible, которые вы в него добавили, определяющими логическую структуру вашего кластера.
Группа Master указывает, что Ansible должен выполнять удаленные команды от имени пользователя root. В ней также указан IP-адрес главного узла (master_ip) , который может быть указан в записи сервера с именем “master”. Аналогично, группа Workers содержит две записи для рабочих серверов (worker_1_ip и worker_2_ip) , которые также определяют ansible_user как root.
Последняя строка файла указывает Ansible использовать интерпретаторы Python 3 удаленных серверов для операций управления. Наконец, вам нужно сохранить и закрыть файл после добавления текста. После настройки рабочей директории и инвентарного файла Ansible перейдем к следующему шагу — установке зависимостей на уровне операционной системы и созданию настроек конфигурации.
Шаг 2 — Создание пользователя без прав root на всех удаленных серверах
На этом шаге вы узнаете, как создать пользователя без прав root с привилегиями sudo на всех серверах, чтобы вы могли подключаться к ним по SSH вручную как непривилегированный пользователь.
Это может быть полезно для часто выполняемых операций по поддержанию кластера. Более того, этот шаг поможет вам выполнить задачу более точно и с меньшим количеством ошибок, снижая вероятность непреднамеренного изменения или удаления важных файлов. Если вы хотите изменить настройки файлов, принадлежащих root, или просмотреть системную информацию с помощью таких команд, как top/htop и просмотреть список запущенных контейнеров, следующий шаг поможет вам выполнить все эти задачи.
Создание плейбука
Создайте файл с именем ~/kube-cluster/initial.yml в рабочей области:
|
1 |
nano ~/kube-cluster/initial.yml |
Далее вам нужно добавить следующий сценарий (play). Сценарий в Ansible — это набор шагов, которые должны быть выполнены на определенных серверах и группах. В плейбуке может быть один или несколько сценариев.
Следующий сценарий создаст пользователя без прав root с привилегиями sudo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
- hosts: all become: yes tasks: - name: создать пользователя 'ubuntu' user user: name=ubuntu append=yes state=present createhome=yes shell=/bin/bash - name: разрешить 'ubuntu' использовать have без пароля sudo lineinfile: dest: /etc/sudoers line: 'ubuntu ALL=(ALL) NOPASSWD: ALL' validate: 'visudo -cf %s' - name: настроить up авторизованные ключи для пользователя ubuntu user authorized_key: user=ubuntu key="{{item}}" with_file: - ~/.ssh/id_rsa.pub |
Ниже приведено описание того, что делает наш плейбук:
- Этот плейбук создаст пользователя без прав root
ubuntu. - Поскольку вам необходимо запускать команды
sudoбез запроса пароля, этот сценарий настроит файлsudoers, чтобы разрешить пользователюubuntuделать это. - Основная цель описанной выше задачи — позволить вам подключаться к каждому серверу по SSH от имени пользователя
ubuntu. Этот плейбук добавляет публичный ключ вашей локальной машины (обычно~/.ssh/id_rsa.pub) для удаленного пользователяubuntuв список авторизованных ключей.
Теперь, после добавления текста, вам нужно сохранить и закрыть файл.
Запуск плейбука
После этого нам нужно запустить наш плейбук, который создаст пользователя ubuntu без прав root, просто выполнив на локальной машине:
|
1 |
ansible-playbook -i hosts ~/kube-cluster/initial.yml |
Выполнение этой команды займет некоторое время, после чего вы увидите следующий вывод:
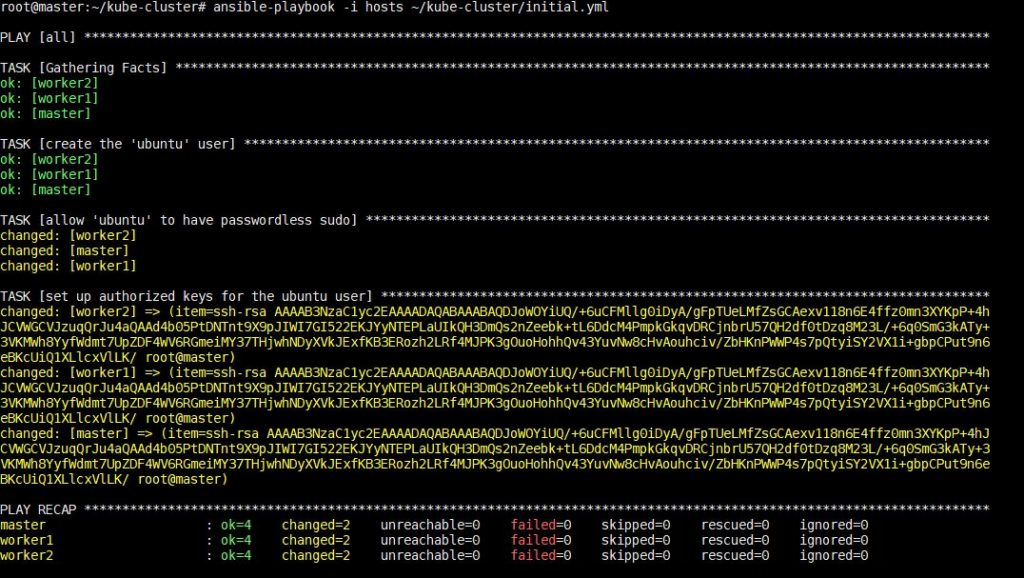
После завершения этого шага вы можете перейти к установке зависимостей Kubernetes на следующем шаге.
Шаг 3 — Установка зависимостей Kubernetes
На этом шаге вы узнаете, как установить пакеты уровня операционной системы, необходимые для Kubernetes, с помощью пакетного менеджера Ubuntu.
Эти пакеты:
- Docker: Docker — это платформа и инструмент для сборки, распространения и запуска контейнеров Docker. Вы можете легко настроить Docker, следуя нашему руководству по установке & работе с Docker на Ubuntu в публичном облаке. Однако поддержка других сред выполнения, таких как rkt, находится в стадии активной разработки в Kubernetes.
Kubeadm: kubeadm — это инструмент командной строки (CLI), который выполняет действия, необходимые для запуска минимально жизнеспособного кластера. Это поможет вам установить и собрать различные компоненты кластера стандартным способом.kubelet: kubelet — это основной “агент узла” (node agent), который работает на каждом узле и обрабатывает операции на уровне узла.kubectl: kubectl — это также инструмент командной строки (CLI), который взаимодействует с вашим кластером и отправляет команды через его API-сервер.
Создание плейбука
Создайте файл с именем ~/kube-cluster/kube-dependencies.yml в рабочей области:
|
1 |
nano ~/kube-cluster/kube-dependencies.yml |
Теперь вам нужно добавить в файл следующие сценарии для установки этих пакетов на ваши серверы:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
- hosts: all become: yes tasks: - name: установить Docker apt: name: docker.io state: present update_cache: true - name: установить APT Transport HTTPS apt: name: apt-transport-https state: present - name: добавить Kubernetes apt-key apt_key: url: https://packages.cloud.google.com/apt/doc/apt-key.gpg validate_certs: false state: present - name: добавить Kubernetes' APT-репозиторий apt_repository: repo: deb http://apt.kubernetes.io/ kubernetes-xenial main state: present filename: 'kubernetes' - name: установить kubelet apt: name: kubelet=1.16.0-00 state: present update_cache: true - name: установить kubeadm apt: name: kubeadm=1.16.0-00 state: present - hosts: master become: yes tasks: - name: установить kubectl apt: name: kubectl=1.16.0-00 state: present force: yes |
Первый сценарий в playbook делает следующее:
- Этот сценарий поможет вам установить пакеты уровня операционной системы, Docker – среду выполнения контейнеров.
- Он устанавливает
apt-transport-https, что позволяет добавлять внешние источники HTTPS в список источников APT. - Добавляет apt-key APT-репозитория Kubernetes для проверки ключей.
- Добавляет APT-репозиторий Kubernetes в список источников APT ваших удаленных серверов.
- Устанавливает
kubeletиkubeadm.
Второй сценарий выполняет важную и единственную задачу, которая включает в себя установку kubectl на вашем master-узле. Теперь после добавления текста вам нужно сохранить и закрыть файл.
Запуск playbook
После этого нам нужно запустить наш playbook, просто выполнив на локальных машинах:
|
1 |
ansible-playbook -i hosts ~/kube-cluster/kube-dependencies.yml |
Выполнение этой команды займет некоторое время, после чего вы увидите следующий вывод:
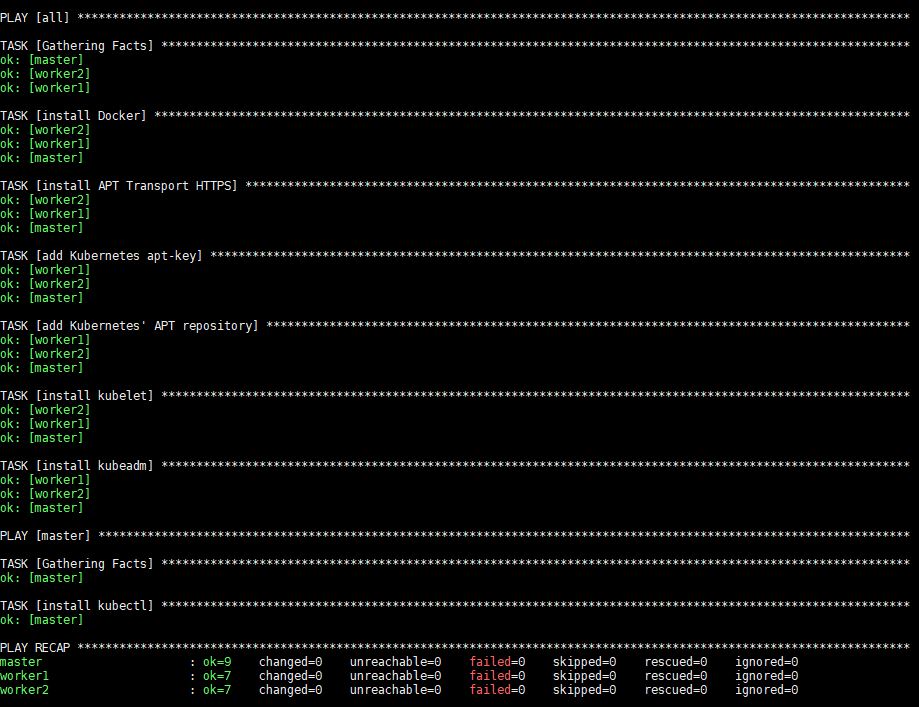
После выполнения Docker, kubeadm и kubelet будут установлены на всех удаленных серверах. Kubectl не является обязательным компонентом и нужен только для выполнения команд кластера. Установка его только на master-узле имеет смысл в данном контексте, так как вы будете запускать команды kubectl только с master-узла. Обратите внимание, однако, что kubectl команды можно запускать с любого из рабочих узлов или с любой машины, где их можно установить и настроить для подключения к кластеру.
Все системные зависимости установлены. Давайте настроим главный узел и инициализируем кластер.
Шаг 4 — Настройка главного узла
На этом шаге вы познакомитесь с несколькими концепциями, такими как Поды и сетевые плагины подов, так как ваш кластер будет включать и то, и другое после настройки главного узла.
Поды — это самые маленькие, базовые развертываемые объекты в Kubernetes. Поды содержат один или несколько контейнеров, таких как контейнеры Docker. Когда в поде запущено несколько контейнеров, они управляются как единое целое и совместно используют ресурсы Pod’а.
Каждый под имеет свой собственный IP-адрес, и под на одном узле должен иметь возможность доступа к поду на другом узле, используя IP-адрес Pod’а. Однако взаимодействие между подами устроено сложнее. Для этого требуется отдельный компонент, который может прозрачно маршрутизировать трафик от пода на одном узле к поду на другом. Для этой цели используются сетевые плагины подов. Доступно множество сетевых плагинов для подов, но мы будем использовать Flannel, так как это стабильный и эффективный вариант.
Создание плейбука
Создайте плейбук Ansible с именем master.yml на локальном компьютере:
|
1 |
nano ~/kube-cluster/master.yml |
Далее вам нужно добавить в файл следующий сценарий для инициализации кластера и установки Flannel:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
- hosts: master become: yes tasks: - name: initialize the cluster shell: kubeadm init --pod-network-cidr=10.244.0.0/16 >> cluster_initialized.txt args: chdir: $HOME creates: cluster_initialized.txt become: yes become_user: root - name: create .kube directory become: yes become_user: ubuntu file: path: $HOME/.kube state: directory mode: 0755 - name: copy admin.conf to user's kube config copy: src: /etc/kubernetes/admin.conf dest: /home/ubuntu/.kube/config remote_src: yes owner: ubuntu - name: install Pod network become: yes become_user: ubuntu shell: kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/2140ac876ef134e0ed5af15c65e414cf26827915/Documentation/kube-flannel.yml >> pod_network_setup.txt args: chdir: $HOME creates: pod_network_setup.txt |
Вот подробный разбор этого сценария (play):
- Первая задача в этом сценарии настроит кластер, запустив
kubeadm init. Для указания частной подсети, которая будет назначена IP-адресам подов, мы передаем аргумент--pod-network-cidr=10.244.0.0/16. Flannel использует указанную выше подсеть по умолчанию. Мы используем это, чтобы указатьkubeadmиспользовать ту же подсеть. - Вторая задача используется для создания каталога
.kubeв/home/ubuntu. В этом каталоге будет храниться конфигурационная информация, такая как файлы ключей администратора, необходимые для подключения к кластеру, и API-адрес кластера. - Третья задача используется для копирования файла
/etc/kubernetes/admin.conf, который был создан в результате выполненияkubeadm initв домашний каталог вашего пользователя без прав root. Это позволит вам использоватьkubectlдля доступа к только что созданному кластеру. - Последняя задача запускает
kubectl applyдля установкиFlannel.kubectl apply -f descriptor.[yml|json]— это синтаксис, указывающийkubectlсоздать объекты, описанные в файлеdescriptor.[yml|json]. Файлkube-flannel.ymlсодержит описания объектов, необходимых для настройкиFlannelв кластере.
Теперь, после добавления текста, вам нужно сохранить и закрыть файл.
Запуск плейбука
После этого вам нужно запустить наш плейбук, просто выполнив на локальных машинах:
|
1 |
ansible-playbook -i hosts ~/kube-cluster/master.yml |
Выполнение этой команды займет некоторое время, после чего вы увидите следующий вывод:
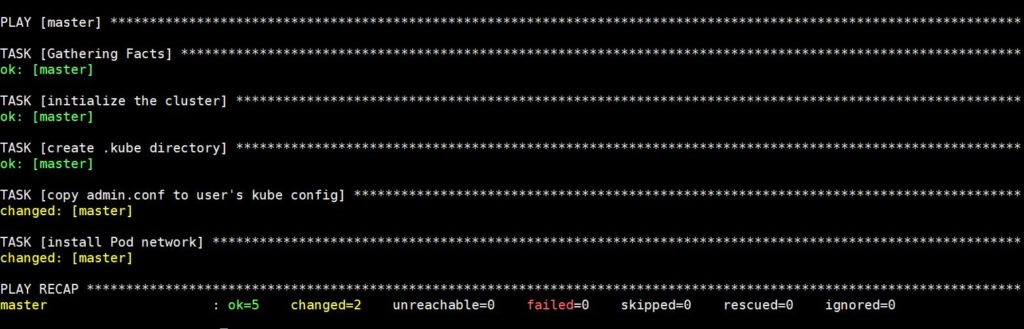
Теперь подключитесь к нему по SSH с помощью следующей команды, чтобы проверить статус мастер-ноды:
|
1 |
ssh ubuntu@master_ip |
Оказавшись внутри мастер-ноды, выполните:
|
1 |
kubectl get nodes |
Теперь вы увидите следующий вывод:

Получив этот вывод, вы можете констатировать, что все задачи по настройке мастер-ноды выполнены, и она может начать принимать рабочие ноды (worker nodes) и выполнять задачи, перейдя в состояние Ready. Теперь вы можете добавить рабочие ноды со своей локальной машины.
Шаг 5 — Настройка рабочих нод
После настройки мастер-ноды мы можем перейти к следующему шагу — настройке рабочих нод. Добавление рабочих нод в кластер можно выполнить простым запуском одной команды на каждом рабочем сервере. Эта команда содержит важную информацию, такую как IP-адрес, порт API-сервера мастера и защищенный токен. Однако стоит отметить, что не все ноды смогут присоединиться к кластеру, а только те, которые передадут правильный защищенный токен.
Создание плейбука
Эта команда поможет вам вернуться в рабочую область и создать плейбук с именем workers.yml:
|
1 |
nano ~/kube-cluster/workers.yml |
Добавьте следующий текст в файл, чтобы добавить рабочие ноды в кластер:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
- hosts: master become: yes gather_facts: false tasks: - name: получить команду присоединения shell: kubeadm token create --print-join-command register: join_command_raw - name: задать команду присоединения set_fact: join_command: "{{ join_command_raw.stdout_lines[0] }}" - hosts: workers become: yes tasks: - name: присоединиться к кластеру shell: "{{ hostvars['master'].join_command }} >> node_joined.txt" args: chdir: $HOME creates: node_joined.txt |
Вот что делает плейбук. В приведенном выше коде есть два сценария:
- Первый сценарий используется для получения команды присоединения, которую необходимо запустить на рабочих узлах. Формат команды будет следующим:
kubeadm join --token sha256:<hash><token><master-ip>:<master-port> --discovery-token-ca-cert-hash sha256:<hash>;. Задача должна получить правильные значения токена и хэша. Как только она получает правильные входные данные, задача устанавливает их в качестве факта, чтобы второй сценарий мог получить доступ к этой информации. - Второй сценарий написан только для выполнения одной задачи – сделать два рабочих узла частью кластера, просто запустив команду присоединения на всех рабочих узлах.
После добавления текста вам нужно сохранить и закрыть файл.
Запуск плейбука
После этого нам нужно запустить наш плейбук, выполнив следующую команду на рабочих машинах:
|
1 |
ansible-playbook -i hosts ~/kube-cluster/workers.yml |
Выполнение этой команды займет некоторое время, после чего вы увидите следующий вывод:
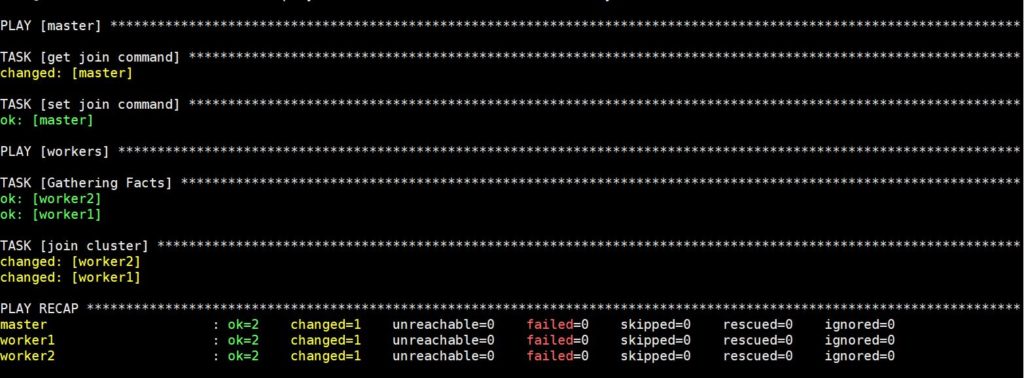
Теперь ваш кластер Kubernetes полностью настроен и функционирует, а рабочие узлы готовы к выполнению нагрузок. Прежде чем перейти к следующему шагу, давайте проверим, что кластер работает так, как планировалось.
Шаг 6 — Проверка кластера
Могут возникнуть ситуации, когда настройка кластера завершается неудачей. Это может произойти из-за сетевой ошибки между главным и рабочим узлами или из-за проблемы с узлом. Поэтому нам необходимо проверить кластер перед планированием приложений и убедиться в отсутствии сбоев. Для этого вам нужно будет проверить текущее состояние кластера с главного узла, чтобы убедиться, что узлы готовы. Вы можете восстановить соединение с помощью следующей команды, если узлы не готовы или вы отключились:
|
1 |
ssh ubuntu@master_ip |
Используйте следующие команды для получения статуса кластера:
|
1 |
kubectl get nodes |
Выполнение этой команды займет некоторое время, после чего вы увидите следующий вывод:

Вам необходимо проверить, находятся ли все узлы, входящие в состав кластера, в состоянии готовности. Если у нескольких узлов указано Not Ready в качестве STATUS, это показывает, что рабочие узлы еще не завершили свою настройку. Тем не менее, перед повторным запуском kubectl get nodes и проверкой обновленного вывода вам следует подождать еще от пяти до десяти минут. Если некоторые узлы все еще показывают Not Ready в качестве своего статуса, вам следует вернуться, проверить предыдущие шаги и запустить команды заново. Только если узлы имеют значение Ready для STATUS, они являются частью кластера и готовы к запуску рабочих нагрузок. После успешного выполнения 6-го шага ваш кластер проверен. Теперь давайте запланируем запуск примера приложения Nginx в кластере.
Шаг 7 — Запуск приложения в кластере
Создание развертывания
После успешного создания кластера вы можете развернуть в нем любое контейнеризированное приложение. Вы можете использовать приведенные ниже команды для других контейнеризированных приложений, если находитесь на главном узле. Далее выполните следующую команду, чтобы создать развертывание с именем nginx :
|
1 |
kubectl create deployment nginx --image=nginx |
Вам необходимо изменить имя Docker-образа и любые соответствующие флаги (такие как порты и тома). Чтобы все было привычно, вы можете развернуть Nginx с помощью развертываний и служб, чтобы увидеть, как приложения могут быть развернуты в кластере.
A развертывание Kubernetes — это объект ресурса в Kubernetes, который обеспечивает декларативные обновления приложений. Развертывание (deployment) позволяет описать жизненный цикл приложения, например образ контейнера, реплики и стратегию обновления. Развертывание гарантирует, что желаемое количество подов запущено и доступно в любое время. Если под аварийно завершает работу в течение жизненного цикла кластера, оно запускает его снова. Процесс обновления также полностью записывается и версионируется с возможностью приостановки, продолжения и отката к предыдущим версиям. Приведенная выше команда для создания развертывания с именем Nginx поможет вам развернуть под с одним контейнером из Docker-образа Nginx в реестре Docker.
Настройка Node Port
Далее нам нужно создать NodePort. NodePort — это открытый порт на каждом узле вашего кластера. Kubernetes прозрачно перенаправляет входящий трафик с NodePort на вашу службу, даже если ваше приложение запущено на другом узле. Для этого мы можем использовать эту команду, чтобы создать ресурс NodePort с именем Nginx, который сделает приложение общедоступным:
|
1 |
kubectl expose deploy nginx --port 80 --target-port 80 --type NodePort |
Служба (service) — это еще один объект Kubernetes, отвечающий за предоставление интерфейса для этих подов, что обеспечивает сетевой доступ как изнутри кластера, так и между внешними процессами и службой. Ее можно определить как абстракцию поверх пода, которая предоставляет один IP-адрес и DNS-имя, по которым можно получить доступ к подам. С помощью службы очень легко управлять конфигурацией балансировки нагрузки.
Запустите следующую команду:
|
1 |
kubectl get services |
Это выведет текст, похожий на следующий:

После получения вывода Kubernetes автоматически назначит случайный порт, который больше, чем 30000, при этом также убедившись, что назначенный порт еще не занят другой службой. Третья строка приведенного выше вывода поможет вам узнать порт, на котором работает Nginx.
Чтобы убедиться, что все работает, перейдите по адресу http://worker_1_ip:nginx_port или http://worker_2_ip:nginx_port через браузер на вашем локальном компьютере. Вы увидите знакомую приветственную страницу Nginx.
Удаление развертывания
Если вы хотите удалить приложение Nginx, вам сначала нужно удалить службу nginx с мастер-узла:
|
1 |
kubectl delete service nginx |
Чтобы убедиться, что приложение окончательно удалено, вам нужно запустить эту команду:
|
1 |
kubectl get services |
Вы получите следующий вывод:

После этого вам нужно удалить развертывание с помощью следующей команды:
|
1 |
kubectl delete deployment nginx |
Вы можете использовать эту команду, чтобы проверить, удалено ли развертывание окончательно:
|
1 |
kubectl get deployments |
![]()
Заключение:
Это руководство поможет вам правильно настроить кластер на Ubuntu 18.04 с помощью Kubeadm и Ansible. Теперь, когда ваш кластер настроен, вы можете легко начать развертывание собственных приложений и служб.
Вот список ссылок с дополнительными сведениями, которые помогут вам в этом процессе:
- Докеризация приложений – Эта ссылка содержит примеры, которые помогут вам загружать приложения с помощью Docker. Например, докеризация PostgreSQL, службы CouchDB и т. д.
- Обзор подов – По этой ссылке представлены подробные сведения о том, как использовать под, о функционировании подов и о том, как поды связаны с другими объектами Kubernetes. Поды являются важной частью Kubernetes, поэтому понимание их работы поможет вам успешно справиться с задачей.
- Обзор развертываний – Это поможет вам узнать о развертываниях. Развертывание обеспечивает декларативные обновления для подов (Pods) и наборов реплик (ReplicaSets). Вы узнаете, как обновлять, перезапускать и откатывать развертывание.
- Обзор служб - Эта ссылка расскажет вам о службах, которые являются еще одним часто используемым объектом в кластерах Kubernetes. Служба в Kubernetes — это абстракция, которая определяет логический набор подов и политику доступа к ним. Понимание типов служб и доступных для них опций необходимо для запуска приложений как с сохранением состояния (stateful), так и без него (stateless).
Кроме того, обратите внимание на другие наши руководства по Docker и Kubernetes, которые вы можете найти в нашем блоге:
- Знакомство с Kubernetes
- Очистка ресурсов Docker — образы, контейнеры и тома
- Как запустить Docker на CloudSigma (с помощью CloudInit) Обновлено
- Установка и настройка Docker на CentOS 7
- Как установить & использовать Docker на Ubuntu в публичном облаке
Существует также множество других важных концепций, таких как Тома, Ingress, и Секреты которые вы можете использовать при развертывании приложений в продакшене.
Приятной работы!
Комментарии
Комментариев пока нет. Будьте первым.