

Веб-скрейпинг, веб-краулинг, веб-харвестинг или извлечение веб-данных — это синонимы, обозначающие процесс сбора данных с веб-страниц в Интернете. Веб-скрейперы или веб-краулеры — это инструменты, которые программно обходят веб-страницы, извлекая необходимые данные. Эти данные, обычно представляющие собой большие массивы текста, могут использоваться в аналитических целях, для понимания продуктов или для удовлетворения любопытства относительно определенной веб-страницы.
Если вам интересно, как устроен веб-краулинг, мы покажем вам основы веб-скрейпинга на примере простого набора данных. Вы сможете следовать этому руководству независимо от вашего уровня подготовки в программировании. В качестве практического примера мы будем использовать наш блог CloudSigma. Мы попытаемся получить информацию о руководствах на странице нашего блога. К тому времени, как вы дочитаете это руководство до конца, у вас будет работающий веб-скрейпер, созданный с помощью Python 3, который обходит несколько страниц в разделе нашего блога, а затем выводит данные на экран.
Используя знания, полученные при создании этого базового веб-скрейпера, вы сможете расширить его возможности и создавать собственные веб-скрейперы. Это должно быть весело, давайте начнем!
Предварительные требования
Это практическое руководство, поэтому для успешного прохождения вам понадобится локальная среда разработки для Python 3. Сначала вы можете обратиться к нашему руководству о том, как установить Python 3 и настроить локальную среду программирования на Ubuntu.
Scrapy
Веб-скрейпинг включает в себя два этапа: первый этап — это поиск и загрузка веб-страниц, второй этап — обход этих веб-страниц и извлечение из них информации.
Существует множество способов и библиотек, которые можно использовать для создания веб-скрейпера с нуля на многих языках программирования. Однако это может вызвать проблемы в будущем, когда ваш веб-скрейпер усложнится или когда вам понадобится обходить несколько страниц с разными настройками и шаблонами одновременно. Преобразование собранных данных в различные форматы, такие как CSV, XML или JSON, может оказаться довольно сложной задачей.
Хотя некоторые могут оценить сложность создания собственного веб-скрейпера с нуля, лучше не изобретать велосипед, а построить его на основе существующей библиотеки, которая решает все эти проблемы. Мы будем использовать Scrapy, библиотеку Python, совместно с Python 3 для реализации веб-скрейпера в этом руководстве. Scrapy — это инструмент с открытым исходным кодом и одна из самых популярных и мощных библиотек для веб-скрейпинга на Python. Scrapy был создан для реализации некоторых общих функций, которыми должны обладать все скрейперы. Таким образом, вам не придется изобретать велосипед каждый раз, когда вы захотите реализовать веб-краулер. Со Scrapy процесс создания скрейпера становится простым и увлекательным.
Scrapy доступен в PyPi, широко известном как pip — каталог пакетов Python (Python Package Index). PyPi — это репозиторий, принадлежащий сообществу, в котором размещено большинство пакетов Python. Когда вы устанавливаете и настраиваете Python 3 в своей локальной среде разработки, вместе с ним устанавливается и pip, который вы можете использовать для установки пакетов Python.
Шаг 1: Как создать простой веб-скрейпер
Во-первых, чтобы установить Scrapy, выполните следующую команду:
|
1 |
pip install scrapy |
При желании вы можете следовать официальным инструкциям по установке Scrapy на странице документации. Если вы успешно установили Scrapy, создайте папку для проекта с любым именем по вашему выбору:
|
1 |
mkdir cloudsigma-crawler |
Перейдите в эту папку и создайте основной файл для кода. В этом файле будет содержаться весь код для данного руководства:
|
1 |
touch main.py |
При желании вы можете создать файл с помощью текстового редактора или IDE вместо вышеуказанной команды.
Затем откройте файл, и давайте начнем с создания базового скрейпера, использующего Scrapy. Мы создадим класс Python, который расширяет scrapy.Spider, базовый класс паука из Scrapy. Этот класс будет иметь два обязательных атрибута, определенных ниже:
- name — строковое имя для идентификации паука (вы можете ввести любое имя по своему выбору).
- start_urls — массив, содержащий список URL-адресов для обхода. Мы начнем с одного URL-адреса.
Добавьте следующий фрагмент кода в открытый файл, чтобы создать базового паука:
|
1 2 3 4 5 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] |
Ниже приведено объяснение каждой строки кода:
Первая строка импортирует Scrapy, позволяя нам использовать различные классы, предоставляемые этим пакетом.
В следующей строке мы наследуем класс Spider, предоставляемый Scrapy, и создаем подкласс с именем CloudSigmaCrawler. Наследуя класс (Spider), мы получаем доступ к свойствам класса, которые теперь можем использовать в нашем коде. В данном случае класс Spider содержит методы и поведение, определяющие, как переходить по URL-адресам и извлекать данные с веб-страниц. Однако он не знает, по каким URL-адресам переходить и какие данные извлекать. Наследуя его, мы можем передать необходимую информацию в эти методы. Чтобы узнать больше о создании подклассов и наследовании, читайте далее принципы объектно-ориентированного программирования.
В нашем CloudSigmaCrawler мы определяем необходимые атрибуты. Сначала мы даем нашему пауку имя cloudsigma_crawler. Затем мы указываем один URL-адрес для начала работы: https://blog.cloudsigma.com/blog/. Открытие этого URL-адреса приведет вас на первую страницу блога CloudSigma, которая содержит некоторые из многочисленных руководств.
Время протестировать парсер. У вас есть несколько вариантов. Если вы используете IDE, например, PyCharm community edition от JetBrains, в ней, скорее всего, есть кнопка, на которую можно просто нажать для запуска скрипта. Другой вариант — использовать стандартный способ запуска файлов Python из командной строки: python path/to/file.py или py path/to/file.py. Еще один вариант — интерфейс командной строки Scrapy. Scrapy поставляется с собственным интерфейсом командной строки, который помогает запустить парсер. Введите следующую команду, чтобы запустить парсер:
|
1 |
scrapy runspider main.py |
В зависимости от установленной версии библиотеки Scrapy, вы должны увидеть вывод, похожий на следующий:
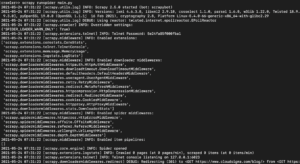
Как видите, вывод довольно длинный, поэтому мы выбрали только некоторые части. Вот что произошло при выполнении команды:
- Парсер был инициализирован. Таким образом, он загрузил дополнительные компоненты и расширения, необходимые для перехода по URL-адресам и чтения данных.
- Используя URL-адрес, указанный в списке start_urls, он получил HTML-код страницы. Этот процесс аналогичен тому, который выполняет браузер при открытии веб-страниц.
- После получения HTML-кода он передается методу parse, который мы еще не определили. Пока он ничего не делает, поэтому паук просто завершает работу без какой-либо обработки. Мы определим поведение метода parse на следующем шаге.
Шаг 2: Как извлечь данные со страницы
На шаге 1 мы реализовали только базовый парсер, который получает HTML-страницу, но ничего не делает после этого. В этом разделе мы приведем инструкции по извлечению данных. На странице блога CloudSigma, с которой мы хотим извлечь данные, вы можете заметить некоторые элементы, такие как:
- Заголовок (header), присутствующий на всех страницах.
- Навигационное меню и поле фильтра поиска.
- Непосредственно список руководств в виде сетки.
Просмотр исходного кода HTML-страницы, которую вы собираетесь парсить, дает общее представление о структуре страницы. Это помогает при написании парсера. Вы можете просмотреть исходный код, щелкнув правой кнопкой мыши на странице и выбрав «Просмотр кода страницы» или нажав Ctrl + U. Вот фрагмент исходного кода:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
<body> <div id="x-iso-container" class="x-iso-container x-iso-container-posts cols-3"> <article id="post-51691" class="post-51691 post type-post status-publish format-standard has-post-thumbnail hentry category-blog-posts category-tutorials tag-apache tag-certbot tag-cloud-guide tag-cloud-tutorial tag-https tag-lets-encrypt tag-ssl tag-ssl-certification tag-tutorial tag-ubuntu"> <div class="entry-wrap"> <header class="entry-header"> <h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Постоянная ссылка на: "Защита Apache с помощью Let’s Encrypt на Ubuntu 18.04"">Защита Apache с помощью Let’s Encrypt на Ubuntu 18.04</a> </h2> </header> <div class="entry-content excerpt"> <p>Безопасность веб-сайтов и данных — это темы, к которым нельзя относиться легкомысленно. Высокочувствительная информация, которая включает в себя финансовые отчеты и личную информацию клиентов, всегда находится в процессе передачи между компьютером пользователя и вашим веб-сайтом. Если учесть этот факт, нетрудно понять, почему незащищенные веб-сайты могут привести к утечке данных, которая может серьезно навредить вашему бизнесу. Существует … </p> <div><a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="more-link">Читать далее</a></div> </div> </div> ... </article> </div> </body> |
Как видите, каждое руководство в блоге заключено в HTML-тег <article>. Сбор данных со страницы будет состоять из двух шагов. Первым шагом будет извлечение каждого руководства блога путем поиска частей страницы, содержащих нужные нам данные. Следующим шагом будет извлечение нужных данных из каждого руководства, определенного HTML-тегом.
Scrapy определяет данные для извлечения на основе предоставленных вами селекторов. Мы можем использовать селекторы для поиска одного или нескольких элементов на странице и получения данных внутри этих элементов. Scrapy поддерживает XPath и CSS селекторы.
Судя по исходному коду, который мы просматривали ранее, CSS-селекторы кажутся проще. Поэтому мы выберем этот вариант, так как он поможет нам найти все руководства на странице. В исходном коде HTML каждое руководство указано внутри CSS-класса post. Имена CSS-классов обычно обозначаются как .имя_класса (точка имя_класса). Таким образом, мы будем использовать .post в качестве нашего CSS-селектора. Внутри исходного кода нашего скрейпера main.py мы передадим класс .post объекту response, так что теперь ваш файл будет выглядеть следующим образом:
|
1 2 3 4 5 6 7 8 9 10 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): pass |
Этот фрагмент кода соберет все руководства на странице с указанными start_urls и переберет их в цикле для извлечения данных. На следующем шаге вам нужно будет извлечь и отобразить эти данные. Если вы снова изучите исходный код блога CloudSigma, то увидите, что заголовок каждого руководства хранится внутри тега <a>, который находится внутри тега <h2>, например:
|
1 2 3 4 5 |
<h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Permalink to: "Securing Apache with Let’s Encrypt on Ubuntu 18.04"">Securing Apache with Let’s Encrypt on Ubuntu 18.04</a> </h2> |
Каждый объект руководства, который мы перебираем в цикле, содержит метод CSS, в который мы можем передать селектор для поиска и извлечения дочерних элементов. В этом примере мы хотим извлечь заголовок, который заключен внутри тега <a>. Этот тег находится внутри тега <h2> внутри класса .entry-header внутри класса .entry-wrap. Мы можем передать эти CSS-селекторы методу объекта для извлечения заголовка, изменив код следующим образом:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), } |
Запятая после extract_first() не является опечаткой, так как ниже мы добавим еще код.
Вот несколько важных моментов, на которые стоит обратить внимание в приведенном выше исходном коде:
- ::text, добавленный к селектору — это псевдоселектор CSS, который указывает коду извлекать текст внутри тега, а не сам тег.
- вызов метода extract_first() внутри объекта — указывает коду выбирать только первый элемент, соответствующий селектору. Таким образом, мы получаем строку, а не список элементов.
Затем сохраните файл и запустите код, введя в терминале следующую команду:
|
1 |
scrapy runspider main.py |
В выводе вы должны увидеть названия руководств:
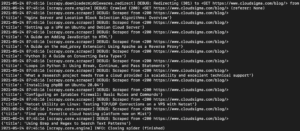
Мы можем продолжить расширять это, добавляя больше селекторов для получения других сведений о руководстве, таких как URL-адрес руководства, рекомендуемое изображение и подпись.
Давайте еще раз изучим HTML-код для одного руководства:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
<body> <div id="x-iso-container" class="x-iso-container x-iso-container-posts cols-3"> <article id="post-51691" class="post-51691 post type-post status-publish format-standard has-post-thumbnail hentry category-blog-posts category-tutorials tag-apache tag-certbot tag-cloud-guide tag-cloud-tutorial tag-https tag-lets-encrypt tag-ssl tag-ssl-certification tag-tutorial tag-ubuntu"> <div class="entry-featured"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="entry-thumb" title="Постоянная ссылка на: "Securing Apache with Let’s Encrypt on Ubuntu 18.04""> <img width="1000" height="522" src="data:image/svg+xml,%3Csvg%20xmlns='http://www.w3.org/2000/svg'%20viewBox='0%200%201000%20522'%3E%3C/svg%3E" class="attachment-entry-fullwidth size-entry-fullwidth wp-post-image" alt="Let’s Encrypt" loading="lazy" data-lazy-srcset="/media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04.jpg 1000w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-300x157.jpg 300w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-768x401.jpg 768w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-610x318.jpg 610w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-100x52.jpg 100w" data-lazy-sizes="(max-width: 1000px) 100vw, 1000px" data-lazy-src="/media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04.jpg"/> </a> </div> <div class="entry-wrap"> <header class="entry-header"> <h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Permalink to: "Securing Apache with Let’s Encrypt on Ubuntu 18.04"">Защита Apache с помощью Let’s Encrypt на Ubuntu 18.04</a> </h2> </header> <div class="entry-content excerpt"> <p>Безопасность веб-сайтов и данных — это темы, к которым нельзя относиться легкомысленно. Высокочувствительная информация, которая включает финансовые отчеты и личную информацию клиентов, всегда находится в процессе передачи между компьютером пользователя и вашим веб-сайтом. Если учесть этот факт, нетрудно понять, почему незащищенные веб-сайты могут привести к утечке данных, которая может серьезно навредить вашему бизнесу. Существует … </p> <div><a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="more-link">Читать далее</a></div> </div> </div> </article> </div> </body> |
Мы хотим попытаться извлечь выделенные фрагменты, то есть URL-адрес руководства, рекомендуемое изображение и подпись.
- Из приведенного выше фрагмента кода видно, что изображение для блога хранится внутри атрибута data-lazy-src тега img внутри тега <a> внутри тега div в начале руководства по блогу. Мы можем использовать CSS-селектор, чтобы получить это значение, как мы делали это с заголовками руководств.
- Получить URL-адрес руководства несложно, так как у нас есть тег <a> внутри элемента <div>.
- Подпись заключена внутри тега <p>, который находится внутри тега <div>.
Мы будем использовать CSS-классы, чтобы получить то, что нам нужно. Давайте изменим код, чтобы он выглядел следующим образом:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), 'caption': tutorial.css(CAPTION_SELECTOR).extract_first(), } |
Сохраните изменения и запустите код с помощью следующей команды:
|
1 |
scrapy runspider main.py |
В выводе вы увидите больше данных, таких как URL, изображение и подпись, которые мы добавили:

На этом всё с парсингом одной страницы. Далее давайте посмотрим, как создать парсер, который переходит по ссылкам.
Шаг 3: Как парсить несколько страниц
К этому моменту мы создали парсер, который может получать данные с одной страницы. Однако нам нужно больше. Вам нужен паук, который может переходить по ссылкам и программно извлекать данные с нескольких страниц веб-сайта.
Если вы перейдете в самый низ страницы блога CloudSigma, вы заметите ссылки пагинации и маленькую стрелку, указывающую вправо, которая обозначает следующую страницу. Вот фрагмент HTML-кода:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<div class="x-pagination"> <ul class="center-list center-text"> <li><span class="pages">Страница 1 из 45</span></li> <li></li> <li><span class="current">1</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/2/" class="single_page" title="2">2</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="single_page" title="3">3</a></li> <li><span class="expand">...</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/45/" class="last" title="Last Page">45</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/2/" class="prev-next hidden-phone">→</a></li> </ul> </div> |
Фрагмент кода показывает несколько ссылок навигации по страницам внутри тегов <li>, под тегом <div> с CSS-классом .x-pagination. Наше внимание сосредоточено на ссылке, указывающей на следующую страницу. Она находится в теге <a> последнего <li> в теге <ul>.
Ссылка, указывающая на следующую страницу, имеет класс .prev-next внутри тега <a>, как показано во фрагменте выше. Однако, если вы перейдете на следующую страницу, вы также заметите, что ссылки на предыдущую и следующую страницы имеют этот CSS-класс. Рассмотрим этот фрагмент для страницы 2:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<div class="x-pagination"> <ul class="center-list center-text"> <li><span class="pages">Страница 2 из 45</span></li> <li><a href="https://blog.cloudsigma.com/blog/" class="prev-next hidden-phone">←</a></li> <li><a href="https://blog.cloudsigma.com/blog/" class="single_page" title="1">1</a></li> <li><span class="current">2</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="single_page" title="3">3</a></li> <li><span class="expand">...</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/45/" class="last" title="Последняя страница">45</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="prev-next hidden-phone">→</a></li> </ul> </div> |
Если мы используем метод Scrapy extract_first(), он сработает на первой странице. Когда он перейдет на следующую страницу, он выберет первую ссылку с классом .prev-next, которая в приведенном выше фрагменте указывает на первую страницу. Это приведет к зацикливанию. Поэтому мы будем использовать метод Scrapy extract(). Этот метод извлекает все элементы, соответствующие условию, и помещает их в массив. Из этого массива мы можем выбрать последний элемент, который будет содержать фактическую ссылку, указывающую на следующую страницу. Измените свой код следующим образом:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), } NEXT_PAGE_SELECTOR = '.x-pagination > ul.center-list > li > a.prev-next::attr("href")' next_page = response.css(NEXT_PAGE_SELECTOR).extract() if next_page: yield scrapy.Request( response.urljoin(next_page[-1]), callback=self.parse ) |
Давайте разберем код для выбора next_page.
Сначала мы определяем селектор для ссылок на следующую и предыдущую страницы. Затем мы используем метод extract() для извлечения URL-адресов и помещения их в массив. Переменная next_page будет массивом из двух элементов, например:
|
1 |
next_page = [prev_page_url, next_page_url] |
Поскольку мы переходим на следующую страницу, мы выберем последний элемент в массиве. Next_page[-1] выбирает последний элемент в массиве.
Блок if проверяет, содержит ли переменная next_page какое-либо значение, и если да, то вызывает метод scrapy.Request(). В нашем коде мы указываем этому методу обойти страницу по предоставленному URL-адресу и передать ее обратно в метод parse(), чтобы мы могли проанализировать ее для извлечения данных и повторить процесс для следующей страницы. Этот процесс повторяется до тех пор, пока не перестанет находить ссылку на следующую страницу, или, точнее, если блок if не сработает, процесс остановится.
Сохраните код и запустите его. Вы заметите, что итерация продолжается по страницам, так как обнаруживаются новые страницы для парсинга. Именно так определяется веб-парсер, который переходит по ссылкам на сайте. Наш пример довольно прост. Мы просто переходим на страницу, находим ссылку на следующую страницу и повторяем процесс. В других случаях вам может потребоваться переходить по тегам или ссылкам, указывающим на внешние источники, и так далее. Вот готовый исходный код базового веб-парсера на Python 3:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), 'caption': tutorial.css(CAPTION_SELECTOR).extract_first(), } NEXT_PAGE_SELECTOR = '.x-pagination > ul.center-list > li > a.prev-next::attr("href")' next_page = response.css(NEXT_PAGE_SELECTOR).extract() if next_page: yield scrapy.Request( response.urljoin(next_page[-1]), callback=self.parse ) |
Заключение
В этом руководстве мы создали простой веб-парсер, который может обходить каталог блога CloudSigma и отображать некоторую информацию о руководствах в блоге всего примерно в 27 строках кода.
Конечно, это возможно, потому что мы создали его на базе библиотеки Scrapy для Python. Это лишь основа, которая должна помочь вам создавать более сложные парсеры, отслеживающие больше тегов, результаты поиска веб-сайтов и многое другое. Вы можете ознакомиться с официальной документацией Scrapy для получения дополнительной информации о работе со Scrapy.
Приятной работы!
Комментарии
Комментариев пока нет. Будьте первым.