

CloudSigma позволяет клиентам добавлять GPU к своим виртуальным машинам и использовать высокопроизводительные, экономически эффективные вычисления, способные справиться с самыми ресурсоемкими нагрузками. Сердцем предложения GPU от CloudSigma является графический процессор NVIDIA A100 Tensor Core, оптимизированный для HPC, ИИ и аналитики данных. A100 превосходит NVIDIA TESLA V100 и обладает новыми функциями, которые приложения ИИ могут использовать в полной мере. Мы позволяем клиентам легко создавать оптимизированные виртуальные машины с NVIDIA A100 в режиме прямого доступа (passthrough), благодаря чему экземпляры ВМ получают прямой контроль над GPU и их встроенной памятью.
Варианты использования
Рост числа ресурсоемких приложений, работающих в облаке, привел к недавнему взрывному росту облачных вычислений с ускорением на GPU. Эти приложения включают в себя обучение и инференс глубокого обучения ИИ, аналитику данных, научные вычисления, геномику, рендеринг графики и гейминг, и это лишь некоторые из них. От масштабирования обучения ИИ и научных вычислений до горизонтального масштабирования приложений инференса и обеспечения работы разговорного ИИ в реальном времени — GPU обеспечивают необходимую мощность для ускорения многочисленных сложных и непредсказуемых рабочих нагрузок, выполняемых в облаке.
Графический процессор NVIDIA A100 Tensor Core представляет собой гигантский шаг вперед, обеспечивая беспрецедентное ускорение для ИИ, аналитики данных и HPC на любом масштабе. Созданный на базе архитектуры NVIDIA Ampere, A100 обеспечивает до 20X более высокую производительность по сравнению с предыдущим поколением. CloudSigma предоставляет версию с 80GB памяти, обладающую самой быстрой в мире пропускной способностью — более 2 терабайт в секунду (TB/s) — для запуска крупнейших моделей и наборов данных.
Графические процессоры NVIDIA являются одними из ведущих вычислительных движков, обеспечивающих работу ИИ за счет значительного ускорения рабочих нагрузок по обучению и инференсу ИИ. Кроме того, GPU NVIDIA ускоряют многие типы приложений и систем для HPC и аналитики данных, превращая данные в ценные инсайты.
ИИ и HPC
Обучайте сложные модели машинного обучения быстрее и эффективнее с помощью ускорения на GPU. Решайте задачи с интенсивным использованием данных и совершайте прорывы в инновациях на базе ИИ.NVIDIA AI Enterprise — это комплексный облачный пакет программного обеспечения для ИИ и аналитики данных, оптимизированный для того, чтобы любая организация могла использовать ИИ. Он сертифицирован для развертывания в публичном облаке и включает глобальную корпоративную поддержку для успешной реализации проектов в области ИИ. A100 позволяет исследователям быстро получать практические результаты и масштабно внедрять решения в производство.
ОБУЧЕНИЕ ГЛУБОКОГО ОБУЧЕНИЯ
Обучение моделей ИИ требует огромной вычислительной мощности и масштабируемости. Тензорные ядра NVIDIA A100 с поддержкой Tensor Float (TF32) обеспечивают до 20X более высокую производительность по сравнению с NVIDIA Volta без изменения кода, а также дополнительное 2X ускорение благодаря автоматической смешанной точности и FP16.
Такая задача обучения, как BERT, может быть решена в масштабе менее чем за минуту с помощью 2 048 GPU A100, что является мировым рекордом по времени решения.
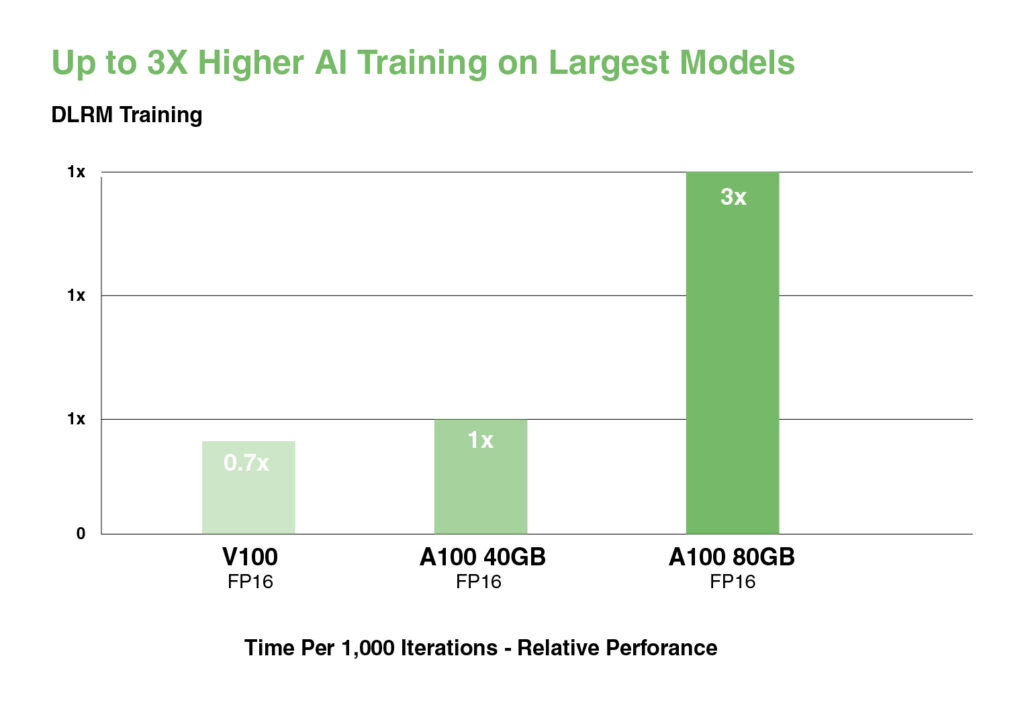
Для крупнейших моделей с массивными таблицами данных, таких как рекомендательные модели глубокого обучения (DLRM), A100 80GB достигает объема до 1.3 TB унифицированной памяти на узел и обеспечивает увеличение пропускной способности до 3X по сравнению с A100 40GB.
Лидерство NVIDIA в MLPerf, установившее множество рекордов производительности в общеотраслевом бенчмарке для обучения ИИ.
ИНФЕРЕНС ГЛУБОКОГО ОБУЧЕНИЯ
A100 представляет революционные функции для оптимизации рабочих нагрузок инференса. Он ускоряет вычисления во всем диапазоне точности от FP32 до INT4. Технология Multi-Instance GPU (MIG) позволяет нескольким сетям работать одновременно на одном A100 для оптимального использования вычислительных ресурсов. А поддержка структурной разреженности обеспечивает до 2X большую производительность в дополнение к другим преимуществам производительности инференса A100.
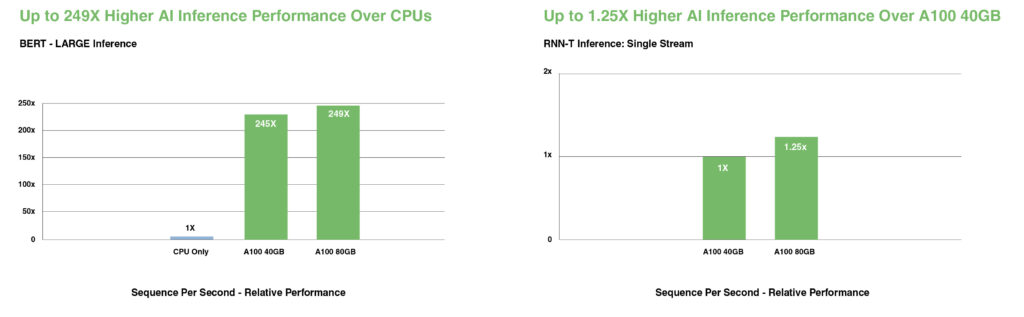
На современных моделях разговорного ИИ, таких как BERT, A100 ускоряет пропускную способность инференса до 249X по сравнению с CPU.
На наиболее сложных моделях с ограничениями по размеру пакета, таких как RNN-T для автоматического распознавания речи, увеличенный объем памяти A100 80GB удваивает размер каждого MIG и обеспечивает до 1.25X более высокую пропускную способность по сравнению с A100 40GB.
Лидирующая на рынке производительность NVIDIA была продемонстрирована в MLPerf Inference. A100 обеспечивает в 20X больше производительности, чтобы еще больше укрепить это лидерство.
ВЫСОКОПРОИЗВОДИТЕЛЬНЫЕ ВЫЧИСЛЕНИЯ
Чтобы совершать открытия нового поколения, ученые обращаются к компьютерному моделированию, позволяющему лучше понять окружающий мир.
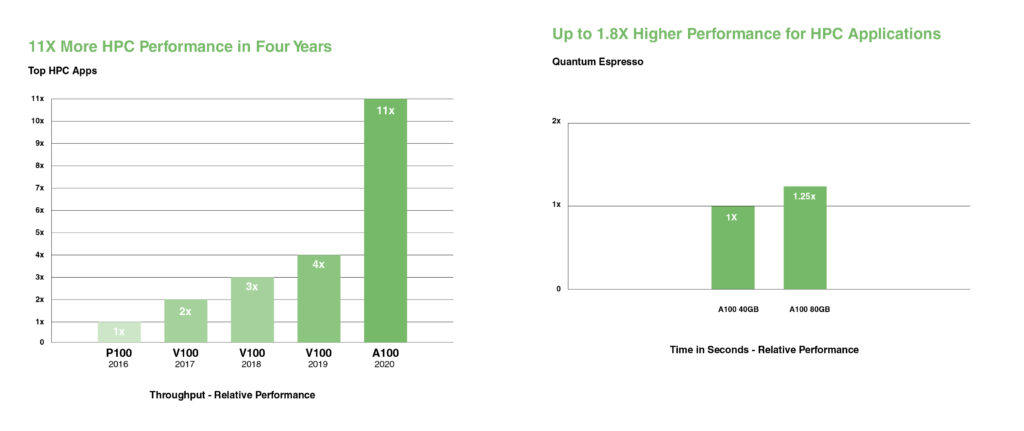
NVIDIA A100 представляет Tensor Cores двойной точности, обеспечивая самый большой скачок в производительности HPC с момента появления GPU. Благодаря 80GB самой быстрой памяти GPU исследователи могут сократить 10-часовое моделирование двойной точности на A100 менее чем до четырех часов. Приложения HPC могут использовать TF32 для достижения увеличения пропускной способности до 11X для операций умножения плотных матриц одинарной точности.
Для приложений HPC с крупнейшими наборами данных дополнительная память A100 80GB обеспечивает увеличение пропускной способности до 2X в Quantum Espresso, решении для моделирования материалов. Этот огромный объем памяти и беспрецедентная пропускная способность памяти делают A100 80GB идеальной платформой для рабочих нагрузок нового поколения.
ВЫСОКОПРОИЗВОДИТЕЛЬНАЯ АНАЛИТИКА ДАННЫХ
Специалистам по анализу данных необходимо иметь возможность анализировать, визуализировать и превращать огромные наборы данных в ценные сведения. Однако горизонтально масштабируемые решения часто буксуют из-за того, что наборы данных распределены по нескольким серверам.
Ускоренные серверы с A100 обеспечивают необходимую вычислительную мощность — огромный объем памяти, пропускную способность памяти более 2 TB/sec и масштабируемость с помощью NVIDIA® NVLink® и NVSwitch™ — для решения этих задач. В сочетании с InfiniBand, NVIDIA Magnum IO™ и пакетом библиотек с открытым исходным кодом RAPIDS™, включая RAPIDS Accelerator для Apache Spark для ускоренной на GPU аналитики данных, платформа NVIDIA для центров обработки данных ускоряет эти огромные рабочие нагрузки на беспрецедентном уровне производительности и эффективности.
В тесте производительности аналитики больших данных A100 80GB обеспечил получение ценных сведений с 2X увеличением скорости по сравнению с A100 40GB, что делает его идеально подходящим для новых рабочих нагрузок с лавинообразно растущими объемами данных.
НАУЧНОЕ МОДЕЛИРОВАНИЕ: Ускоряйте научные исследования и моделирование, обеспечивая более быстрое получение результатов и открытий в области физики, химии и наук об окружающей среде.
МЕДИА И РАЗВЛЕЧЕНИЯ: Выполняйте рендеринг графики высокого разрешения, видео и анимации с молниеносной скоростью. Обеспечьте своей аудитории исключительное качество визуального восприятия без компромиссов.
ФИНАНСОВОЕ МОДЕЛИРОВАНИЕ: Анализируйте огромные наборы данных и выполняйте сложное финансовое моделирование с непревзойденной скоростью, получая важнейшие сведения для принятия обоснованных решений.
Комментарии
Комментариев пока нет. Будьте первым.