

Команда sed — это сокращение от stream editor (потоковый редактор). Это очень популярный инструмент в системах Linux/UNIX. Sed сам по себе не является текстовым редактором. Однако он может выполнять различные модификации для управления заданным текстом. Входной текст передается в виде потока. Sed затем выполняет предписанные действия над потоком. Это руководство содержит обзор команды sed и того, как с ней работать для успешного манипулирования текстом в Linux.
Sed в Linux
Входной поток sed может поступать либо из текстового файла, либо из STDIN (стандартного ввода). Мы можем работать с выводом другой команды или напрямую с текстовым файлом. Инструмент sed предустановлен во всех дистрибутивах Linux.
Обзор использования Sed
Команда sed имеет следующую структуру:
|
1 |
$ sed <опции> <команды> <файл> |
Для демонстрации мы взяли текстовую версию лицензии GPL версии 3:
|
1 |
$ wget https://www.gnu.org/licenses/gpl-3.0.txt |

Следующая команда sed выведет содержимое текстового файла:
|
1 |
$ sed '' gpl-3.0.txt |
Здесь sed выполняет операции, описанные в одинарных кавычках, и выводит результат. Поскольку опции не определены, sed просто выполнит пустую операцию и выведет все содержимое файла.
Sed также принимает вывод другой команды в качестве входного потока. В следующем примере передайте содержимое текстового файла GPL v3 по конвейеру в sed для выполнения пустой операции:
|
1 |
$ cat gpl-3.0.txt | sed '' |
Как выводить строки
Без указания каких-либо опций sed выведет все содержимое файла напрямую. Вместо этого мы можем явно отправить команду печати для вывода результатов непосредственно в стандартный вывод (STDOUT).
Для вывода используйте символ p:
|
1 |
$ sed 'p' gpl-3.0.txt |
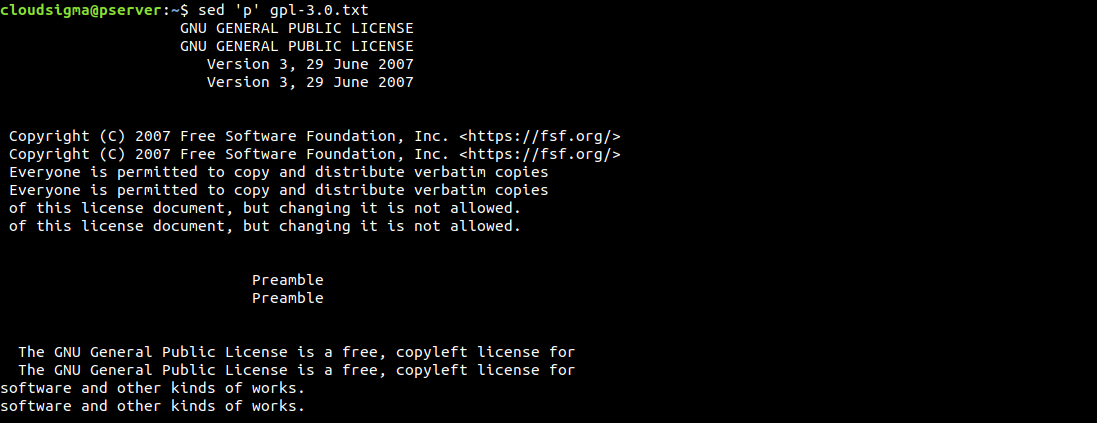
По умолчанию sed выводит результат на экран. Поскольку мы специально использовали команду печати, sed выведет каждую строку дважды. Sed работает построчно. Он считывает одну строку, выполняет определенные операции, выводит ее и переходит к следующей строке.
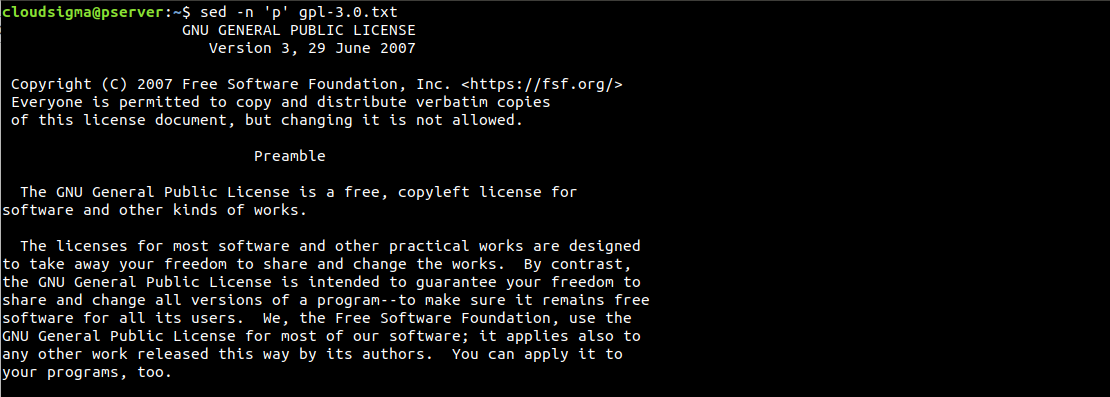
Как мы видим, каждая строка печатается дважды. Если такой результат сбивает с толку, мы можем исправить это с помощью опции -n. Она подавляет функцию автоматического вывода. Поскольку мы отправляем команду печати, нам не нужно, чтобы функция вывода по умолчанию была включена:
|
1 |
$ sed -n 'p' gpl-3.0.txt |
Классы символов в регулярных выражениях
В регулярных выражениях существуют различные классы символов. Каждый из этих классов имеет диапазон. Многие классы также имеют несколько выражений. Большинство классов представляют собой диапазоны символов:
-
- [a-z]: Символ в нижнем регистре
-
- [A-Z]: Символ в верхнем регистре
-
- [0-9]: Цифры
-
- [a-zA-z]: Буквы
-
- [a-zA-z0-9]: Любой буквенно-цифровой символ
Эти классы символов также имеют различные обозначения:
-
- [:lower:]: Символ в нижнем регистре
-
- [:upper:]: Символ в верхнем регистре
-
- [:digit:]: Цифры
-
- [:alpha:]: Буквы
-
- [:alphanum:]: Буквенно-цифровой символ
Например, следующая команда выведет все строки, содержащие хотя бы одну цифру:
|
1 |
$ sed -n 's/[[:digit:]]/&/p' gpl-3.0.txt |
Диапазоны адресов
Мы можем указать конкретную часть текстового потока для работы. Это может быть статический адрес строки или диапазон строк. В первом примере мы выведем строку 5 из текстового файла GPL v3:
|
1 |
$ sed -n '5p' gpl-3.0.txt |

Вместо одной строки мы также можем указать диапазон строк для работы. Здесь мы указали диапазон адресов от строки 5 до строки 9 (всего 5 строк), с которыми sed будет работать:
|
1 |
$ sed -n '5,9p' gpl-3.0.txt |

Существуют также различные способы указания адреса строки. Вместо того чтобы определять номера строк самостоятельно, мы можем перестроить предыдущий пример так, чтобы sed начинал со строки 5 и обрабатывал следующие 5 строк:
|
1 |
$ sed -n '5,+5p' gpl-3.0.txt |

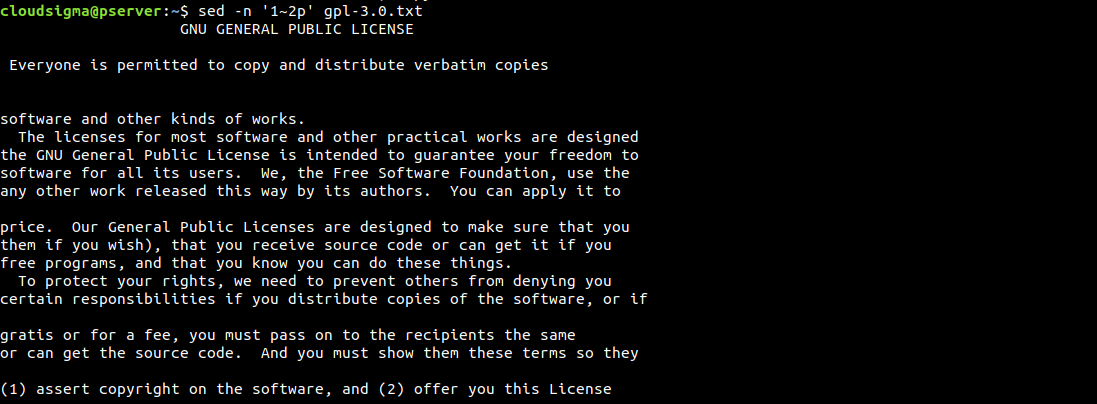
Еще один способ указания строк — использование интервалов. В следующем примере sed начнет со строки 1 и будет обрабатывать каждую вторую строку:
|
1 |
$ sed -n '1~2p' gpl-3.0.txt |
Удаление текста
До сих пор мы работали над выводом целевых строк текста. Вместо вывода мы можем удалить эти строки из вывода. В следующем примере мы удалим несколько строк с начала. Здесь нам не нужно использовать опцию -n, потому что мы хотим, чтобы sed выводил всё остальное, что не удалено. Для удаления строк мы будем использовать опцию d:
|
1 |
$ sed '1~2d' gpl-3.0.txt |
Обратите внимание, что исходный файл остался нетронутым. Sed просто выполняет удаление строк во время вывода. При желании вы можете сохранить вывод sed в файл. Вы можете перезаписать исходный файл или сохранить его под другим именем:
|
1 |
$ sed '1~2d' gpl-3.0.txt > gpl-3.0.modified.txt |
Вместо того чтобы вручную записывать вывод в файл, sed может выполнять редактирование исходного файла на месте. Короче говоря, sed отредактирует исходный файл и запишет все внесенные изменения. Этот метод перезапишет исходный файл, поэтому его следует использовать с осторожностью:
|
1 |
$ sed -i '1~2d' gpl-3.0.txt |
Поскольку редактирование на месте опасно, sed поставляется с функцией резервного копирования. При редактировании на месте используйте -i.bak вместо -i, чтобы сделать резервную копию перед редактированием. Sed создаст файл резервной копии с расширением .bak:
|
1 |
$ sed -i.bak '1~2d' gpl-3.0.txt |
Замена текста
На сегодняшний день это одно из самых распространенных применений sed. Он ищет текстовый шаблон и заменяет его на заданный текст. Здесь текстовый шаблон описывается регулярными выражениями (сокращенно regex). Чтобы узнать больше об использовании регулярных выражений, обратитесь к этому руководству, в котором описывается, как использовать Grep с регулярными выражениями для поиска текстовых шаблонов в файлах.
Вот пример самой базовой замены текста с использованием регулярных выражений:
|
1 |
$ 's/<search_pattern>/<replacement>' |
Здесь s — это команда замены. Косые черты являются разделителями для шаблона и замены. Давайте применим это на практике:
|
1 |
$ echo "hello world" | sed 's/hello/HELLO/' |
![]()
В следующем примере будет продемонстрировано использование символа подчеркивания (_). Здесь символы подчеркивания будут выступать в качестве разделителей:
|
1 |
$ echo http://example.com/index.html | sed 's_com/index_net/home_' |
Здесь мы ищем com/index, чтобы заменить на net/home. Обратите внимание на расположение символов подчеркивания, так как они очень важны. Например, если вы пропустите последнее подчеркивание, sed выдаст ошибку:
|
1 |
$ echo "http://www.example.com/index.html" | sed 's_com/index_net/home' |
![]()
Нам нужен тестовый файл для практики замены. Здесь у меня есть обрезанная версия текстового файла GPL v3:
|
1 |
$ cat gpl-3.0.cropped.txt |
Давайте выполним несколько базовых замен текста:
|
1 |
$ cat gpl-3.0.cropped.txt | sed 's/GNU/GNU is Not Unix/' |
Посмотрите на следующий пример. Мы хотим заменить все вхождения the на THE :
|
1 |
$ echo "the the quick brown fox jumps over the lazy dog" | sed 's/the/THE/' |
![]()
Заметили что-нибудь? Sed не изменил все вхождения the. На самом деле, изменилось только первое вхождение. Что происходит? Это поведение по умолчанию для опции s. Она находит только первое вхождение в данной строке и переходит к следующей. Чтобы убедиться, что sed проверяет всю строку на наличие искомого шаблона, нам нужно использовать необязательный флаг g. Давайте исправим команду:
|
1 |
$ echo "the the quick brown fox jumps over the lazy dog" | sed 's/the/THE/g' |
Теперь все работает как надо. Еще один интересный способ использования команды — указание количества вхождений для изменения. В предыдущем примере было 3 вхождения the, верно? Как насчет того, чтобы указать изменение только 3-го вхождения? Изменение произойдет в необязательном флаге:
|
1 |
$ echo "the the quick brown fox jumps over the lazy dog" | sed 's/the/THE/3' |
Если вы работаете с большим текстовым файлом, то может быть полезно, если sed выводил только те строки, в которых произошли замены. Чтобы добиться этого, нам нужно добавить еще один дополнительный флаг p:
|
1 |
$ sed -n 's/GNU/GNU is Not Unix/gp' gpl-3.0.txt |

Чувствительность к регистру
По умолчанию все операции sed чувствительны к регистру. Следующая команда продемонстрирует поведение по умолчанию:
|
1 |
$ echo "HELLO WORLD" | sed 's/hello/hElLo/' |
![]()
Из-за несовпадения регистра изменений нет. В такой ситуации мы можем указать sed отключить чувствительность к регистру. Для этого добавьте необязательный флаг i:
|
1 |
$ echo "HELLO WORLD" | sed 's/hello/hElLo/i' |
Как заменять текст и ссылаться на него
Сила sed в основном заключается в возможности использования регулярных выражений. С более продвинутыми и сложными шаблонами регулярных выражений мы можем добиться гораздо большего. Например, мы можем заменить текст от начала файла до определенного места. Посмотрите на следующее выражение:
|
1 |
$ sed 's/^.*GNU/GNU_replaced/' gpl-3.0.txt |
Здесь символ каретки (^) обозначает начало строки. Оператор соответствия любому символу обозначается точкой (.). Звездочка (*) является выражением подстановки, соответствующим тексту от начала строки до GNU.
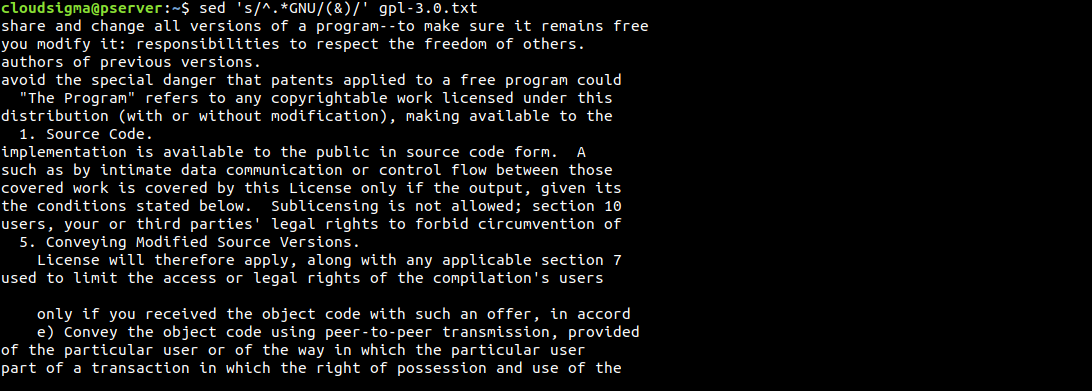
Еще один интересный трюк — использование символа &. Мы можем использовать его, чтобы выделить области, в которых sedнаходит искомый шаблон:
|
1 |
$ sed 's/^.*GNU/(&)/' gpl-3.0.txt |
Заключение
В этом руководстве мы изучили основы команды sed . Мы узнали, как выводить определенные строки, искать текст, удалять и заменять текст, перезаписывать текст и использовать регулярные выражения. Правильно составленная команда sed может кардинально изменить текстовый документ. Теперь вы можете успешно манипулировать текстом в Linux с помощью sed.
Приятной работы!
Комментарии
Комментариев пока нет. Будьте первым.