

O grep comando é um utilitário poderoso para pesquisar padrões em texto. Ele vem pré-instalado em qualquer Linux distro. Aqui está o nosso tutorial que aborda a configuração da LAMP Stack - Linux, Apache, MySQL e PHP.
O nome grep significa global regular expression print. A ferramenta busca pelo padrão especificado na entrada. Em princípio, parece trivial. No entanto, seu verdadeiro poder está em como você define o padrão. Este guia explica detalhadamente como usar o grep com expressões regulares para realizar buscas complexas. Vamos começar!
Como usar o Grep
O comando grep, por si só, não é complicado. Tudo o que ele exige é o padrão e o conteúdo no qual realizar a busca. É assim que se parece a estrutura básica do comando grep:
|
1 |
grep <regex> <file> |
Pesquisando texto
Primeiro, obtenha um arquivo de exemplo para realizar a ação. Baixe o GNU General Public License v3.0 (em formato de texto). É um arquivo de texto bastante grande, com muitas palavras e frases. Se você estiver usando o Ubuntu você pode encontrá-lo no arquivo abaixo. Siga o nosso tutorial para uma instalação rápida e fácil do Ubuntu.
|
1 |
curl -o gpl.txt https://www.gnu.org/licenses/gpl-3.0.txt |

A seguir, você pode realizar uma busca de texto básica usando o grep:
|
1 |
grep <pattern> <text_file> |
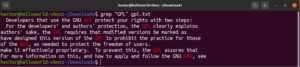
É possível direcionar (pipe) a saída de um comando para o grep:
|
1 |
cat gpl.txt | grep <pattern> |
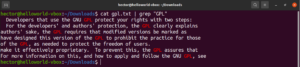
Diferenciação de maiúsculas e minúsculas
Por padrão, o grep se comporta como sensível a maiúsculas e minúsculas. Em muitas situações, ignorar a diferenciação de maiúsculas e minúsculas pode ser o ideal. Para desativar a busca sensível a maiúsculas e minúsculas, use a flag “-i” ou “–ignore-case”:
|
1 2 3 |
$ grep -i <pattern> <file> $ grep --ignore-case <pattern> <flag> |
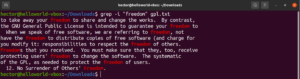
Inverter a busca
Por padrão, o comportamento do grep é imprimir as linhas onde o padrão foi encontrado. A inversão de correspondência (invert match) refere-se ao fenômeno de quando você não quer ver as linhas que correspondem ao padrão. Para inverter a correspondência, você precisa usar a flag “-v” ou “–invert-match”:
|
1 2 3 |
$ grep -v <pattern> <file> $ grep --invert-match <pattern> <file> |
Número da linha
Ao executar o grep em um arquivo muito grande, é difícil acompanhar a localização do resultado da busca. Para facilitar as coisas, o grep possui o recurso de mostrar o número da linha. Para ativar a numeração de linhas, use a flag “-n” ou “–line-number”:
|
1 2 3 |
grep -n <pattern> <file> grep --line-number <pattern> <file> |
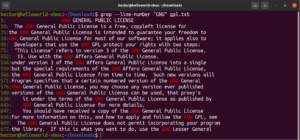
É possível combinar vários argumentos do grep. O seguinte comando grep realizará uma correspondência invertida enquanto imprime os números das linhas:
|
1 |
grep -nv <pattern> <file> |
Expressão regular
No início deste guia, mencionamos que grep significa global regular expression print. O termo “expressão regular” é definido como uma string especial que descreve o padrão de busca. A expressão regular tem sua própria estrutura e regras.
Existem inúmeros algoritmos e ferramentas de busca de strings que usam expressões regulares (regex, para abreviar) para realizar buscas e ações de substituição. Embora seja popular, diferentes aplicativos e linguagens de programação implementam regex de maneira ligeiramente diferente. Nesta seção, mostraremos alguns métodos de regex usando o grep.
Correspondência literal
Nos exemplos anteriores do grep, o grep realizou a busca de uma string específica no arquivo de texto fornecido. O grep estava, na verdade, buscando usando a expressão regular mais básica. Os padrões de regex que definem a busca pela correspondência exata de uma determinada string são chamados de “literais”. O nome vem do fato de que eles correspondem ao padrão literalmente, caractere por caractere.
A correspondência literal funciona com caracteres alfabéticos e numéricos (bem como alguns caracteres especiais). No entanto, dependendo de outros mecanismos de expressão, este comportamento pode mudar:
|
1 |
grep "<string>" <file> |
Correspondência de âncora
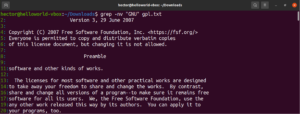
As âncoras são caracteres especiais que definem onde deve ser a posição da correspondência na linha para que haja uma correspondência válida. Aqui está um exemplo rápido para simplificar. Se quisermos encontrar apenas as linhas que começam com a string “GNU”, o grep com regex será assim. Aqui, o caractere “^” é a âncora, definindo que as correspondências no início da linha são as únicas válidas:
|
1 |
grep -n "^GNU" <file> |

Da mesma forma, se quisermos encontrar apenas as linhas que terminam com a string “works”, o grep com regex será assim. Aqui, o caractere “$” é a âncora, definindo que apenas as correspondências no final da linha são válidas:
|
1 |
grep -n "and$" <file> |
Correspondência de qualquer caractere
Ao realizar uma pesquisa de texto, você pode querer definir que, em um local específico, pode haver qualquer caractere. Em regex, isso é expresso pelo caractere de ponto (.).
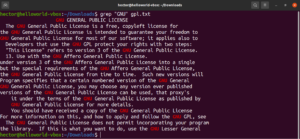
Dê uma olhada neste exemplo. No arquivo de texto da GNU GPL 3, as palavras “accept” e “except” têm a parte “cept” em comum. Além disso, ambas as palavras têm dois caracteres antes da parte “cept”. O seguinte comando grep corresponderá a qualquer palavra que tenha dois caracteres antes da parte “cept”:
|
1 |
grep -n "..cept" <file> |
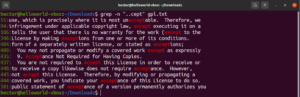
De acordo com esta regex, outras palavras como suscept, unaccept, unexpected, etc. também são correspondências válidas.
Colchetes
Em regex, as expressões entre colchetes definem que, no local especificado, pode haver qualquer caractere declarado dentro dos colchetes. Dê uma olhada na seguinte string de expressão regular:
|
1 |
t[wo]o |
Ao colocá-la em ação, as palavras too e two serão as correspondências válidas:
|
1 |
grep -n "t[wo]o" <file> |
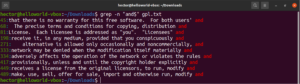
A expressão entre colchetes abre a possibilidade para algumas coisas interessantes. É possível usar expressões entre colchetes para dizer que, no local especificado, pode haver qualquer caractere diferente dos declarados dentro dos colchetes. Dê uma olhada na seguinte string regex. A correspondência só será válida se houver qualquer caractere diferente de “c” antes de “ode”:
|
1 |
"[^c]ode" |
Execute-o no arquivo de texto da licença GPL-3:
|
1 |
grep -n "[^c]ode" <file> |

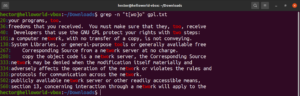
Além do resultado do arquivo, outros resultados válidos seriam node, abode, anode, etc. As expressões entre colchetes também podem descrever um intervalo de caracteres. A seguinte regex indica que a correspondência é válida se o início da linha for um caractere maiúsculo:
|
1 |
"^[A-Z]" |
Execute-o no arquivo de texto da licença GPL-3. Serão todas as linhas do arquivo de texto:
|
1 |
grep -n "^[A-Z]" <file> |
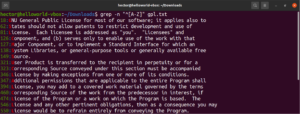
Para facilitar o uso, existem certas classes de caracteres que possuem rótulos específicos. No exemplo anterior, usamos o intervalo “A-Z” para definir os caracteres maiúsculos. Em vez disso, também podemos usar “[:upper:]”. O resultado será o mesmo:
|
1 |
grep -n "^[[:upper:]]" <file> |
Repetindo um padrão
Em certas situações, você pode querer corresponder a um padrão específico ou regex zero ou mais vezes. Para fazer isso, o metacaractere é o asterisco (*). A seguinte expressão regular corresponderá a todos os parênteses apenas com letras e espaços simples entre eles. Observe que a declaração dos conjuntos de caracteres minúsculos, maiúsculos e espaços estão juntas, sem qualquer pontuação:
|
1 |
"([a-zA-Z ]*)" |
Coloque a regex em ação com o grep:
|
1 |
grep -n "([A-Za-z ]*)" <file> |

Usando metacaracteres como caracteres literais
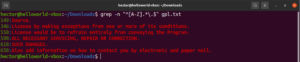
Até agora, fomos apresentados a vários metacaracteres como o asterisco (*), o ponto (.), âncoras (^ e $), etc. Cada um deles denota uma função única no contexto de regex. O problema surge quando eles precisam ser usados como literais, não como metacaracteres. Nessas situações, a barra invertida (\) na frente do metacaractere indicará que ele deve ser usado no sentido literal, não como um metacaractere. Dê uma olhada neste exemplo de regex. Ele corresponderá a todas as linhas que começam com um caractere maiúsculo e terminam com um ponto:
|
1 |
grep -n "^[A-Z].*\.$" <file> |
Alternância
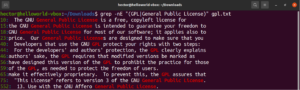
Usando expressões entre colchetes, podemos especificar diferentes escolhas possíveis para a correspondência de um único caractere. O Regex tem o recurso de fazer o mesmo com palavras e frases. Para indicar uma alternância, o caractere de barra vertical (|) é usado. As opções permanecem entre parênteses enquanto o caractere de barra vertical as separa umas das outras. Pode haver duas ou mais opções possíveis para que a correspondência seja válida. Dê uma olhada no seguinte exemplo de regex. Ele corresponderá tanto a “GPL” quanto a “General Public License”:
|
1 |
grep -nE "(GPL|General Public License)" <file> |
Quantificadores
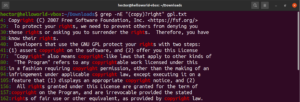
Usando o metacaractere asterisco (*), fomos capazes de definir um padrão repetidamente zero ou mais vezes. No entanto, há mais com o que trabalhar. É mais fácil explicar os quantificadores com um exemplo. A seguinte expressão regular descreve que tanto “copyright” quanto “right” são correspondências válidas. O ponto de interrogação (?) torna a parte “copy” opcional para correspondência:
|
1 |
grep -nE "(copy)?right" <file> |
O próximo quantificador é o símbolo de adição (+). Ele se comporta de maneira semelhante ao asterisco. No entanto, o padrão definido deve corresponder pelo menos uma vez. No exemplo a seguir, a expressão regular corresponderá a “soft” com um ou mais caracteres que não sejam de espaço em branco:
|
1 |
grep -nE "soft[^[:space:]]+" <file> |
Especificar repetição de correspondência
É possível especificar o número de vezes que uma correspondência é repetida. Para fazer isso, use as chaves ({}). A seguinte expressão regular corresponderá a qualquer palavra que contenha no mínimo três vogais:
|
1 |
grep -nE "[aeiouAEIOU]{3}" <file> |

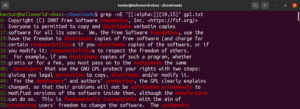
Este recurso também permite definir o limite inferior e o limite superior do comprimento da correspondência. No exemplo a seguir, a regex corresponderá a qualquer palavra que tenha de 10 a 15 caracteres de comprimento:
|
1 |
grep -nE "[[:alpha:]]{10,15}" <file> |
Conclusão
Pesquisar arquivos de texto com o grep é bastante prático. As expressões regulares tornam a pesquisa com o grep mais interessante e útil. Elas também ajustam o padrão de pesquisa de acordo com o seu desejo.
Embora tenhamos demonstrado algumas das expressões regulares comuns, isso é apenas o começo. Existem expressões regulares mais avançadas que oferecem o controle mais refinado sobre o comportamento da pesquisa. Além do grep, as expressões regulares também são amplamente utilizadas por outras ferramentas e linguagens de programação.
Boa computação!
Comentários
Nenhum comentário ainda. Seja o primeiro.