

Replicação do MySQL é um recurso interessante que permite aos usuários gerenciar várias cópias de um ou mais bancos de dados MySQL. Os dados são copiados automaticamente de origem para réplica bancos de dados. Pode ser útil em inúmeras situações, como trabalhar com os dados sem comprometer o banco de dados principal, backup de dados ou dimensionamento do acesso ao banco de dados, etc.
Neste guia, vamos repassar as etapas de configuração de uma instância do MySQL em um servidor como banco de dados de origem e, em seguida, a configuração de uma instância do MySQL em outro servidor para funcionar como sua réplica.
Pré-requisitos
Este guia demonstrará um exemplo muito simples de replicação do MySQL. Envolve uma origem e uma réplica de banco de dados. O banco de dados de origem é a cópia primária do banco de dados, enquanto o banco de dados de réplica será a réplica do banco de dados de origem . Para nossa demonstração, dois servidores estão configurados com os seguintes endereços IP:
- Servidor de origem: 31.171.240.179
- Servidor réplica: 31.171.250.139
Cada servidor está configurado com a versão mais recente do Ubuntu 20.04 server configuração. Primeiro, siga as etapas do tutorial que mostram como configurar seu servidor Ubuntu. Observe que o número de bancos de dados réplica pode ser maior. Este guia pressupõe que você já tenha o MySQL instalado e configurado. Precisa de ajuda com a instalação do MySQL? Este guia demonstra detalhadamente as etapas de instalação e uso básico do MySQL.
Resumindo, aqui estão os pacotes que você precisa:
|
1 |
$ sudo apt install mysql-server mysql-client |
Os firewalls em ambos os sistemas devem ser configurados para permitir o tráfego de ambos os sistemas na porta 3306. É a porta padrão para o MySQL. Você pode aprender mais sobre conceitos básicos do UFW com uma demonstração em nossa postagem no blog.
Configuração do Banco de Dados de Origem
-
Ajustando a configuração do MySQL
O MySQL usa o my.cnf como o arquivo de configuração primário. Atualizaremos o my.cnf para designar o servidor como a origem. Primeiro, abra o arquivo de configuração com um editor de texto:
|
1 |
$ sudo nano /etc/mysql/my.cnf |
Em seguida, adicione as seguintes linhas sob a seção mysqld:
|
1 2 3 4 |
bind-address = 31.171.240.179 server-id = 1 log_bin = /var/log/mysql/mysql-bin.log binlog_do_db = newdatabase |
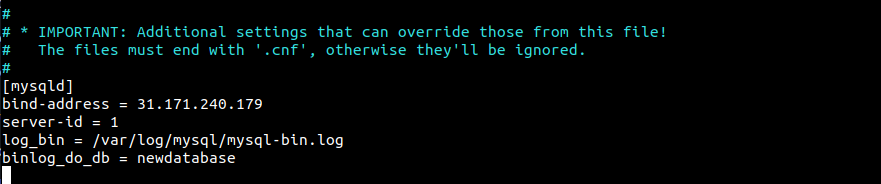
O que significam essas linhas?
bind-address: Esta é a entrada que define a associação entre um serviço e um endereço IP. Por padrão, o valor pode ser127.0.0.1(localhost). O novo valor será o endereço IP do servidor.server-id: Na replicação do MySQL, cada servidor deve ter um ID de servidor exclusivo. Pode ser qualquer número. Para fins de simplicidade, está definido como1.log_bin: Ele armazena os detalhes reais da replicação. O banco de dados réplica copiará tudo o que estiver registrado no log.binlog_do_db: Esta entrada designa o banco de dados que será objeto de replicação no servidor réplica. Pode haver mais de um banco de dados. Aqui, o banco de dados de exemplo énewdatabase.
Depois de fazer as alterações, salve o arquivo de configuração. O MySQL requer reinicialização para carregar as alterações no my.cnf:
|
1 |
$ sudo service mysql restart |
-
Concedendo permissão ao usuário réplica
O próximo passo é criar um usuário réplica e conceder os privilégios apropriados. Isso precisa ser feito a partir do shell do MySQL. Primeiro, inicie o shell do MySQL:
|
1 |
$ sudo mysql -u root -p |
Em seguida, crie um usuário dedicado para o banco de dados réplica. Altere o nome de usuário e a senha adequadamente:
|
1 |
$ CREATE USER 'cloudsigma_s'@'31.171.240.179' IDENTIFIED BY 'password_123'; |
Now, grant the appropriate privileges to the user:
|
1 |
$ GRANT REPLICATION SLAVE ON *.* TO 'cloudsigma_s'@'31.171.240.179'; |
Você pode aprender mais sobre o usuário e permissões do MySQL em nossa postagem no blog. Em seguida, recarregue a tabela de concessões para que as alterações entrem em vigor:
|
1 |
$ FLUSH PRIVILEGES; |

-
Ajustando o banco de dados
Precisamos de uma cópia do banco de dados de origem na réplica. É possível construir a estrutura manualmente. No entanto, na maioria dos casos, isso é bastante inconveniente. É por isso que exportar o banco de dados diretamente é a solução ideal. Neste exemplo, o banco de dados de origem é newdatabase. Altere o banco de dados atual:
|
1 |
$ USE newdatabase; |
O seguinte comando irá bloquear o banco de dados, impedindo novas alterações:
|
1 |
$ FLUSH TABLES WITH READ LOCK; |
Em seguida, verifique o status do banco de dados:
|
1 |
$ SHOW MASTER STATUS; |
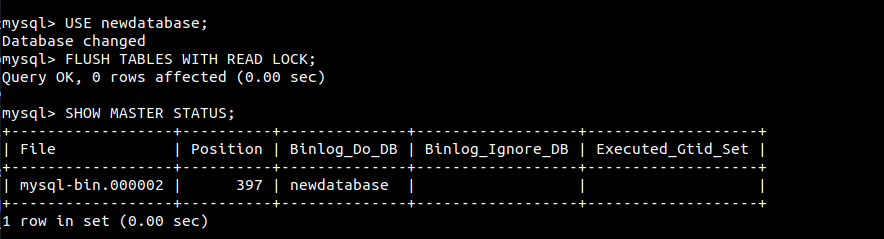
A partir desta posição, o banco de dados réplica começará a replicar a partir da origem. Esses números serão úteis mais tarde, portanto, guarde um registro deles. Se qualquer alteração for feita na mesma janela, o MySQL desbloqueará automaticamente o banco de dados. Portanto, recomenda-se realizar as seguintes etapas em outra aba ou janela do terminal. O banco de dados ainda está bloqueado. Exporte-o para um arquivo SQL portátil:
|
1 |
$ mysqldump -u root -p --opt newdatabase > newdatabase.sql |
A tarefa está concluída. Em seguida, desbloqueie o banco de dados:
|
1 |
$ UNLOCK TABLES; |
Finalmente, saia do shell:
|
1 |
$ QUIT; |
Configuração da Réplica
Agora é hora de configurar o banco de dados réplica.
-
Importando o banco de dados de origem
Precisamos de uma cópia do banco de dados de origem no servidor réplica. Usaremos o arquivo SQL que exportamos anteriormente para fazer isso. Inicie o shell do MySQL:
|
1 |
$ sudo mysql -u root -p |
Depois disso, crie um banco de dados vazio usando o mesmo nome de banco de dados:
|
1 |
$ CREATE DATABASE newdatabase; |
Em seguida, saia do shell:
|
1 |
$ EXIT; |
Agora, importe o arquivo SQL para o banco de dados:
|
1 |
$ sudo mysql -u root -p newdatabase < newdatabase.sql |
![]()
-
Ajustando a configuração do MySQL
Há algumas coisas que precisam ser declaradas no arquivo de configuração do MySQL. Abra o arquivo de configuração em um editor de texto:
|
1 |
$ sudo nano /etc/mysql/my.cnf |
As seguintes entradas ficarão sob a seção mysqld. Caso contrário, não funcionará. A primeira é o ID do servidor. Como mencionado anteriormente, ele deve ser exclusivo para todos os servidores na configuração de replicação origem-réplica. Para demonstração, ele está definido como 2:
|
1 |
$ server-id = 2 |
Em seguida, adicione as seguintes linhas:
|
1 2 3 |
$ relay-log = /var/log/mysql/mysql-relay-bin.log $ log_bin = /var/log/mysql/mysql-bin.log $ binlog_do_db = newdatabase |

Aqui, apenas relay-log é uma nova entrada. É o log que o servidor réplica cria durante a replicação. O formato do log é o mesmo do log binário. Salve o arquivo de configuração e reinicie o MySQL:
|
1 |
$ sudo service mysql restart |
-
Ativando a replicação
Finalmente, estamos prontos para ativar a replicação de dentro do MySQL. Inicie o shell do MySQL:
|
1 |
$ sudo mysql -u root -p |
Execute o seguinte comando. Primeiro, altere o endereço IP, o nome de usuário e as senhas de acordo:
|
1 |
$ CHANGE MASTER TO MASTER_HOST='31.171.240.179',MASTER_USER='cloudsigma_master', MASTER_PASSWORD='password_123', MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS= 107; |

O comando realiza o seguinte:
- O servidor atual é marcado como a réplica do servidor de origem.
- O servidor réplica possui as credenciais de login adequadas.
- O servidor réplica sabe de onde começar a replicar. Lembra-se do status do banco de dados que verificamos no servidor de origem? O arquivo de log de origem e a posição do log vêm de lá.
Finalmente, ative o servidor réplica:
|
1 |
$ START REPLICA; |

-
Diversos
Precisa verificar os detalhes do estado atual da réplica? Execute o seguinte comando no shell do MySQL. O \G no final serve para reorganizar os textos para torná-los mais legíveis:
|
1 |
$ SHOW REPLICA STATUS\G |
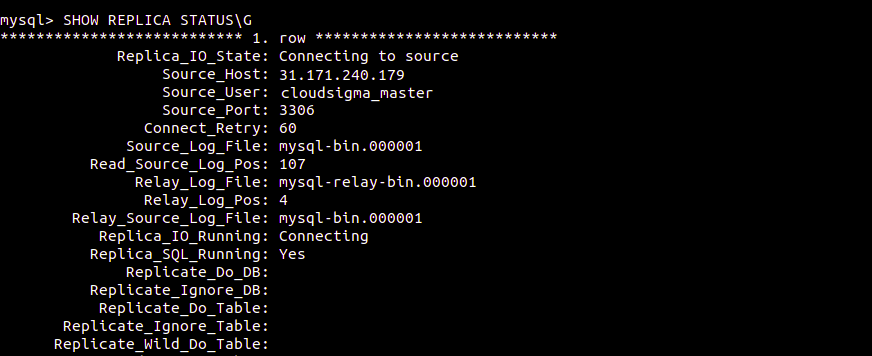
Se houver um problema de conexão, tente iniciar o servidor réplica para ignorá-lo:
|
1 |
$ SET GLOBAL SQL_REPLICA_SKIP_COUNTER = 1; REPLICA START; |
Conclusão
A replicação do MySQL tem muitas implicações. É apenas uma breve demonstração de sua forma básica. No entanto, ela pode ser facilmente estendida para múltiplas configurações de origem-réplica. Os mesmos passos também se aplicarão a quaisquer configurações complexas de nível superior. É sempre uma boa ideia testar qualquer configuração depois. Tente realizar alguns insert, delete ou update comandos no banco de dados de origem. Se a configuração estiver funcionando, o banco de dados réplica deverá capturar tudo corretamente.
Além disso, você pode dar uma olhada em mais recursos do nosso blog cobrindo o que você pode fazer com o MySQL:
- SQLite vs MySQL vs. PostgreSQL: Comparativo de Sistemas de Gerenciamento de Banco de Dados Relacionais
- Como redefinir a senha root do MariaDB ou MySQL
- Como instalar a pilha LEMP (Linux, Nginx, MySQL PHP) no Ubuntu 20.04
Feliz computação!
Comentários
Nenhum comentário ainda. Seja o primeiro.