
Um CSV arquivo é um arquivo de texto simples que armazena dados em formato tabular. Na maioria dos casos, os arquivos CSV usam vírgulas (,) como delimitador, daí o nome CSV (Comma Separated Values). Ele é usado em situações onde a compatibilidade de dados é uma preocupação, pois os CSVs podem ser abertos com qualquer editor de texto, aplicativos de planilha e outras ferramentas especializadas. Na verdade, muitas linguagens de programação oferecem suporte integrado para CSV.
Neste guia, aprenderemos sobre o uso de CSV em um aplicativo Node.js de exemplo.
CSV no Node.js
O Node.js é um ambiente de execução JavaScript de código aberto e multiplataforma. Ele se tornou um dos backends mais populares, alimentando inúmeros serviços web em toda a internet. Até mesmo grandes empresas como Netflix e Uber usam o Node.js para alimentar seus serviços.
O Node.js também possui inúmeros módulos disponíveis para serem implantados para adicionar funcionalidades extras a um projeto. Quando se trata de CSV, existem muitos módulos disponíveis para uso, por exemplo, node-csv, fast-csv, e papaparse etc.
Como o título do guia sugere, nós vamos usar node-csv para ler arquivos CSV usando streams do Node.js. Também demonstraremos como trabalhar com os dados analisados, por exemplo, transferindo os dados para um banco de dados SQLite .
Pré-requisitos
-
Para realizar as etapas demonstradas neste guia, você precisará dos seguintes componentes:
-
Um sistema Linux configurado corretamente. Saiba mais sobre installing and configuring an Ubuntu cloud server on CloudSigma.
-
Acesso a um usuário não-root com privilégio sudo. Confira managing sudo permission with sudoers.
-
Um editor de texto adequado, por exemplo, Brackets, VS Code, Sublime Text, Vim/NeoVim, etc.
-
Outros softwares:
-
Node.js LTS
-
SQLite
-
Step 1 – Installing Necessary Software
Para este guia, criei um servidor leve executando o Ubuntu 22.04 LTS (conectado via SSH):
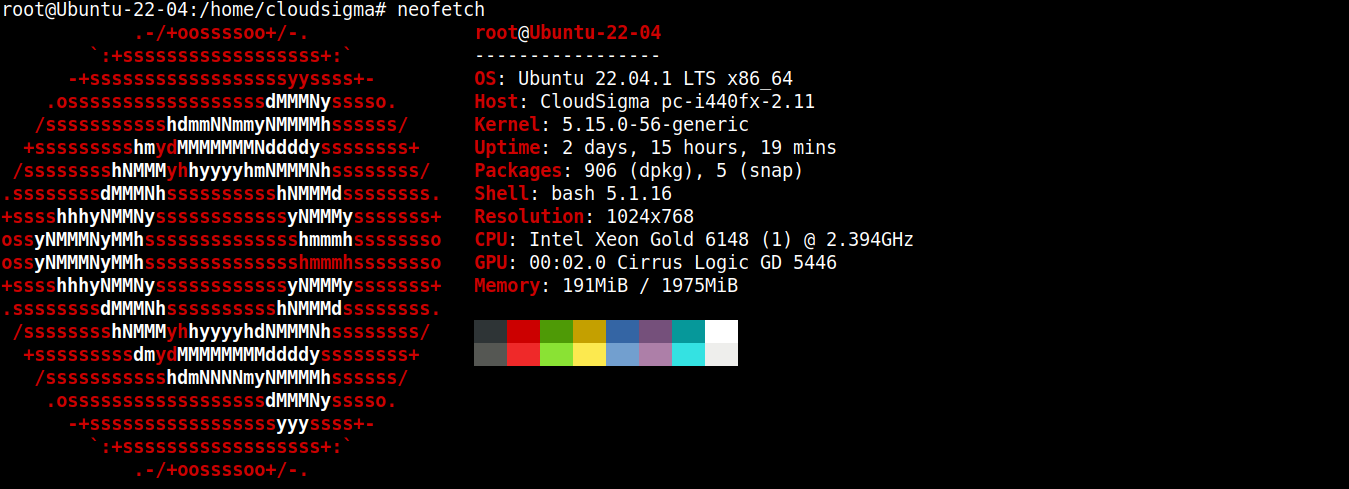
Agora, instalaremos o Node.js e o SQLite nele.
-
Instalando o Node.js LTS
O Node.js está disponível diretamente nos repositórios oficiais de pacotes do Ubuntu. No entanto, não é a versão mais atualizada. É por isso que vamos contar com um repositório de terceiros (Nodesource) para obter os pacotes mais recentes do Node.js.
Adicione o repositório para o Node.js LTS:
|
1 |
curl -fsSL https://deb.nodesource.com/setup_lts.x | sudo -E bash - |
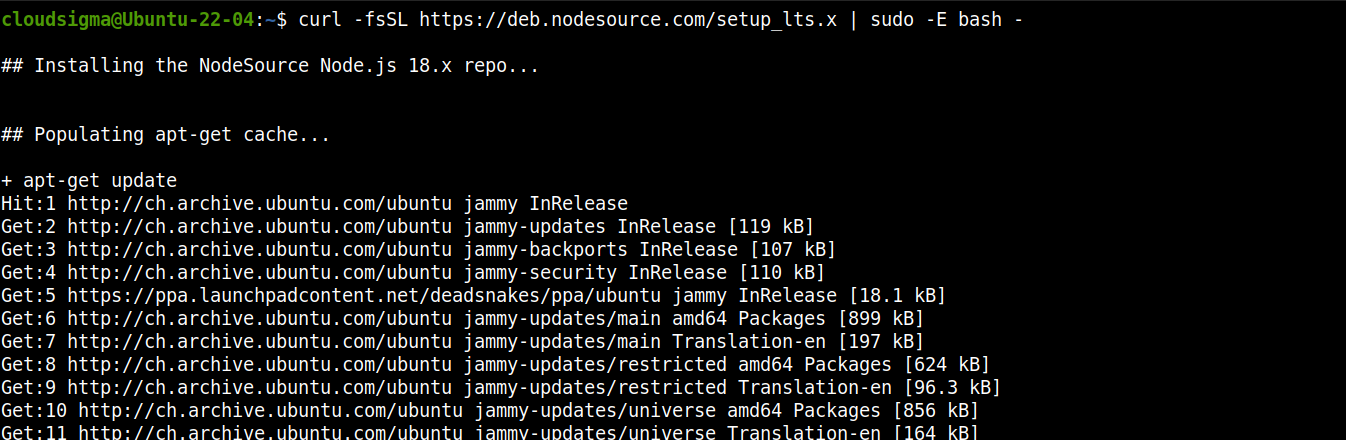
Agora, instale o Node.js LTS:
|
1 |
sudo apt install nodejs -y |

-
Instalar o SQLite
Instalaremos o SQLite diretamente dos repositórios de pacotes do Ubuntu. Execute os seguintes comandos:
|
1 |
sudo apt install sqlite3 -y |

Step 2 – Project Directory Setup
Nesta seção, prepararemos um diretório dedicado para o nosso projeto. Ele hospedará todos os arquivos do projeto junto com módulos adicionais.
Crie um novo diretório:
|
1 |
mkdir -pv csv_practice |
Navegue para dentro do diretório:
|
1 |
cd csv_practice/ |
Em seguida, execute o seguinte comando para declarar o diretório como um projeto npm :
|
1 |
npm init -y |
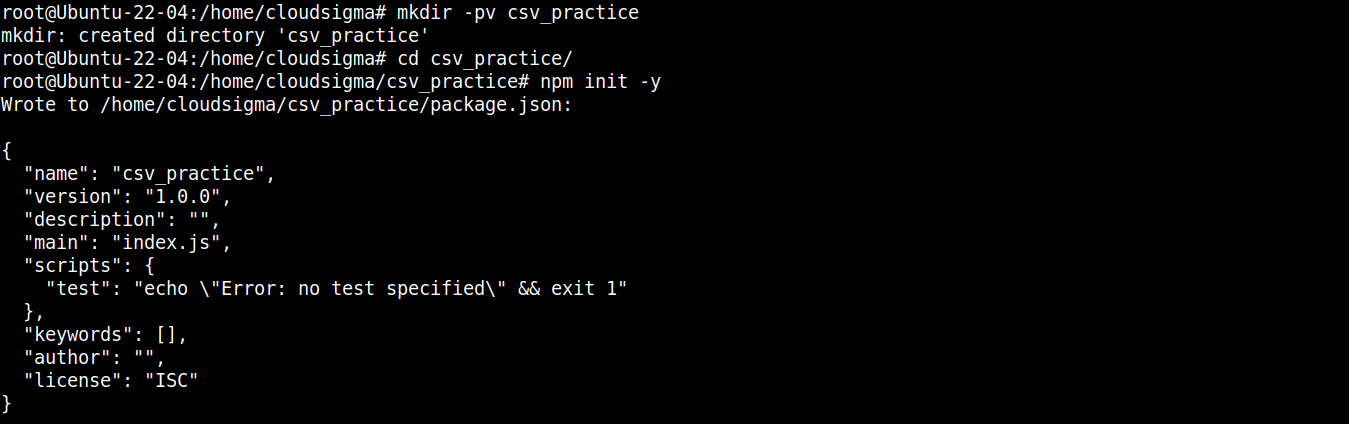
Assim que a pasta do projeto for inicializada, podemos começar a instalar os pacotes e módulos necessários. Primeiro, vamos instalar o node-csv:
|
1 |
npm install csv |

O módulo node-csv é na verdade uma coleção de vários outros módulos: csv-generate, csv-parse (análise de arquivos CSV), csv-stringify (gravação de dados em CSV) e stream-transform.
Em seguida, precisamos do módulo para comunicação com o SQLite. O seguinte comando instalará o módulo node-sqlite3 :
|
1 |
npm install sqlite3 |

O componente que precisamos para o nosso projeto é um arquivo CSV. Para fins de demonstração, usaremos o arquivo CSV de migração da Nova Zelândia:
|
1 |
wget https://www.stats.govt.nz/assets/Uploads/International-migration/International-migration-September-2021-Infoshare-tables/Download-data/international-migration-September-2021-estimated-migration-by-age-and-sex-csv.csv -O migration_data.csv |
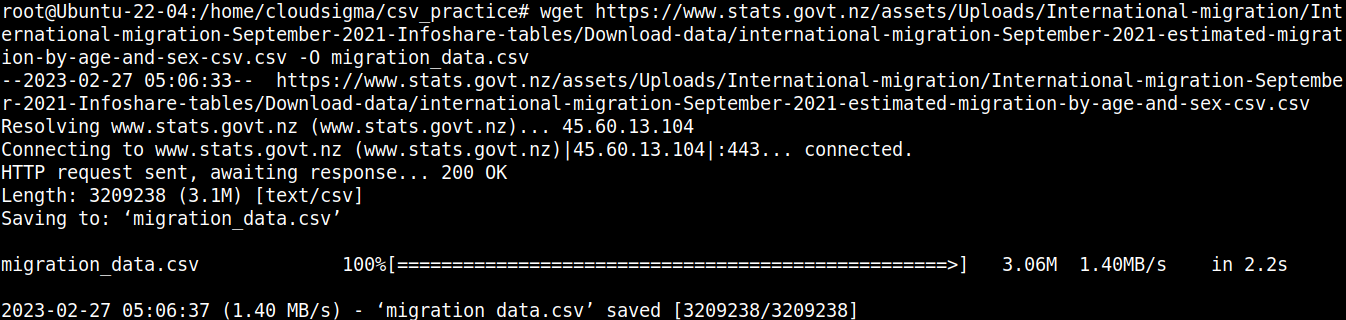
Vamos dar uma olhada rápida no conteúdo do arquivo:
|
1 |
cat migration_data.csv | less |
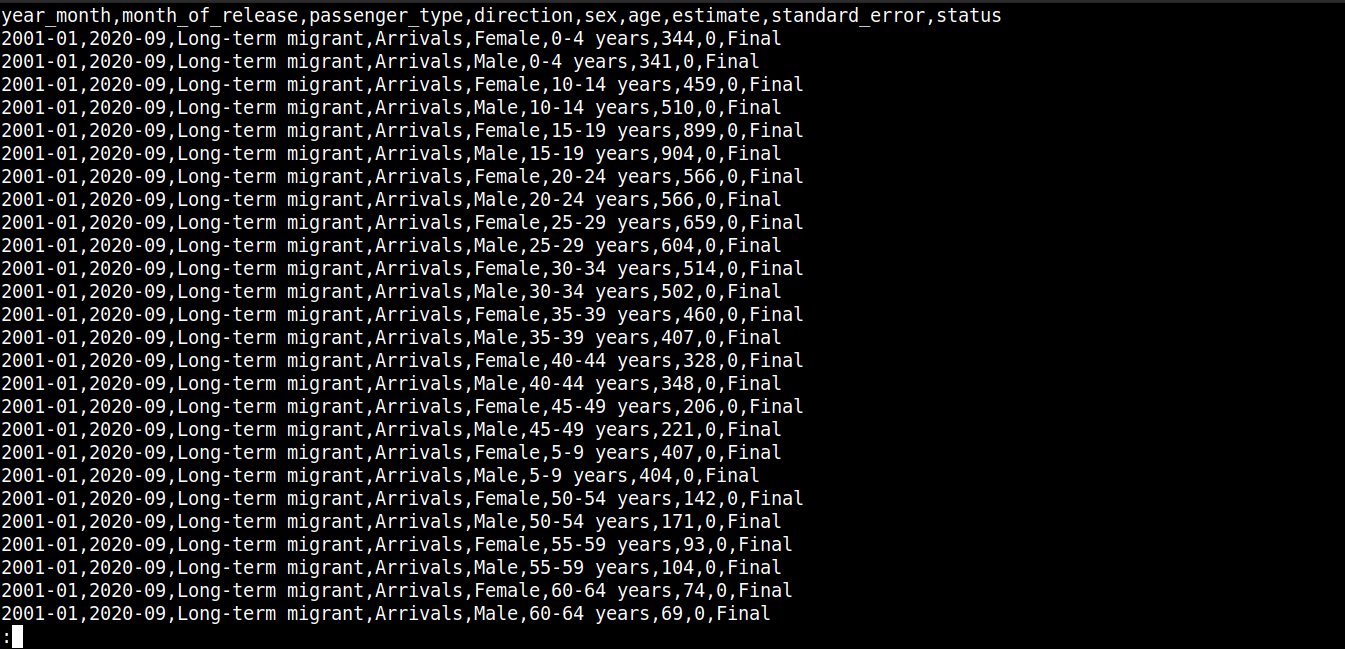
Aqui,
-
A primeira linha descreve os nomes das colunas.
-
As linhas subsequentes contêm os valores para esses campos.
-
Cada linha é separada por uma nova linha (\n).
-
Cada ponto de dados é separado por uma vírgula (,).
No entanto, o CSV não está limitado ao uso de vírgulas como delimitador. Outros delimitadores comuns incluem dois-pontos (:), pontos e vírgulas (;) e tabulações (\td).
Passo 3 – Lendo CSV
Nesta seção, demonstraremos a implementação de um programa de exemplo que lê e analisa dados do arquivo CSV.
Crie um novo arquivo JavaScript:
|
1 |
touch read_csv.js |
Abra o arquivo em seu editor de texto favorito:
|
1 |
nano read_csv.js |
Primeiro, vamos importar os módulos fs e csv-parse:
|
1 2 |
const fs = require("fs"); const { parse } = require("csv-parse"); |
Aqui,
-
Primeiro, a variável fs recebe o objeto fs que retorna o método require() do Node.js ao importar o módulo.
-
Em seguida, o método parse é extraído do objeto retornado pelo método require() para a variável parse usando a sintaxe de desestruturação.
A seguir, vamos adicionar o código para ler o arquivo CSV:
|
1 2 3 4 5 |
fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) |
Aqui,
-
Estamos invocando o createReadStream() do módulo fs e passando o arquivo CSV que queremos ler como argumento. Ele então cria um fluxo de leitura (readable stream) dividindo o arquivo maior em pedaços menores.
-
Após criar o fluxo, o método pipe() encaminha pedaços dos dados do fluxo para outro fluxo. Este novo fluxo é criado ao invocar o método parse() do módulo csv-module.
-
O módulo csv-module implanta um fluxo de transformação de leitura/escrita (readable/writable transform stream) que recebe um pedaço de dados e o transforma em outra forma.
-
O método parse() aceita objetos com propriedades. O objeto processa adicionalmente os dados analisados. Aqui, o objeto está recebendo as seguintes propriedades:
-
delimiter: O caractere delimitador para separar os valores. No caso do nosso CSV de destino, é a vírgula (,).
-
from_line: O número de linhas a partir de onde o analisador começará a analisar. Com o valor fornecido de 2, o analisador ignorará a linha 1 e começará na linha 2. Com essa disposição, evitamos que os nomes das colunas sejam integrados aos dados analisados.
-
A seguir, vamos anexar um evento de fluxo usando o método on() do Node.js:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) .on("end", function () { console.log("finished"); }) .on("error", function (error) { console.log(error.message); }); |
Aqui,
-
Ao emitir um determinado evento, um evento de fluxo permite que um método consuma um pedaço de dados.
-
Quando os dados analisados pelo método parse() estão prontos para serem consumidos, ele aciona o evento data.
-
Para acessar os dados, estamos passando uma função de retorno (callback) para o método on() que recebe um parâmetro row.
-
O parâmetro row é um pedaço de dados na forma de um array (resultado da análise).
-
Finalmente, os dados são registrados no console usando console.log().
Para finalizar o programa, vamos adicionar eventos de fluxo adicionais para tratar erros e exibir uma mensagem de sucesso quando todos os dados do arquivo CSV forem consumidos. Atualize o código da seguinte forma:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) .on("end", function () { console.log("finished"); }) .on("error", function (error) { console.log(error.message); }); |
Aqui,
-
O evento end é emitido quando todos os dados no arquivo CSV são consumidos. Isso resulta na chamada do console.log() método que imprime uma mensagem de sucesso.
-
O evento error é emitido ao encontrar um erro ao analisar os dados do CSV. Isso resulta na chamada do console.log() método que imprime uma mensagem de erro.
O código final deve ficar assim:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
const fs = require("fs"); const { parse } = require("csv-parse"); fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) .on("end", function () { console.log("finished"); }) .on("error", function (error) { console.log(error.message); }); |
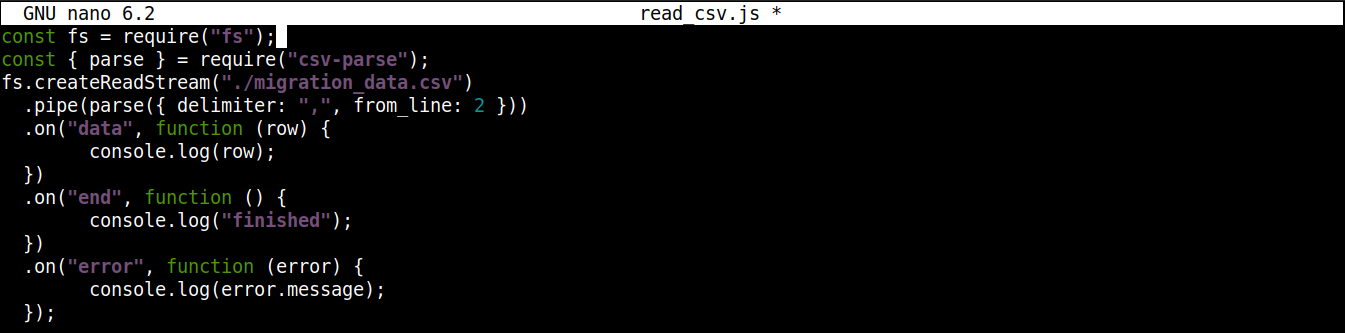
Salve o arquivo e feche o editor. Agora estamos prontos para executar o programa. Execute-o usando o Node.js:
|
1 |
node read_csv.js |
A saída deve ser algo parecido com isto:

Observe que os dados são consumidos, transformados e impressos no console. Como é um processo contínuo, parecerá que os dados estão sendo baixados em vez de imprimir a saída de uma só vez.
Passo 4 – Transferindo Dados CSV para um Banco de Dados
Até agora, aprendemos como analisar um arquivo CSV usando o node-csv. Esta seção demonstrará a transferência dos dados analisados para um banco de dados (SQLite).
Crie um novo arquivo JavaScript para interagir com o banco de dados:
|
1 |
touch csv-to-sqlite3.js |
Agora, abra o arquivo em um editor de texto:
|
1 |
nano csv-to-sqlite3.js |
![]()
Começaremos nosso programa com os seguintes códigos:
|
1 2 3 |
const fs = require("fs"); const sqlite3 = require("sqlite3").verbose(); const filepath = "./population.db"; |

Aqui,
-
Na primeira linha, estamos importando o módulo fs.
-
Na terceira linha, a variável filepath contém o caminho do banco de dados SQLite.
-
Neste ponto, o banco de dados ainda não existe. No entanto, ele será necessário ao trabalhar com o node-sqlite3.
Em seguida, adicione as seguintes linhas para estabelecer uma conexão com o banco de dados SQLite:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
function connectToDatabase() { if (fs.existsSync(filepath)) { return new sqlite3.Database(filepath); } else { const db = new sqlite3.Database(filepath, (error) => { if (error) { return console.error(error.message); } console.log("Conectado ao banco de dados com sucesso"); }); return db; } } |
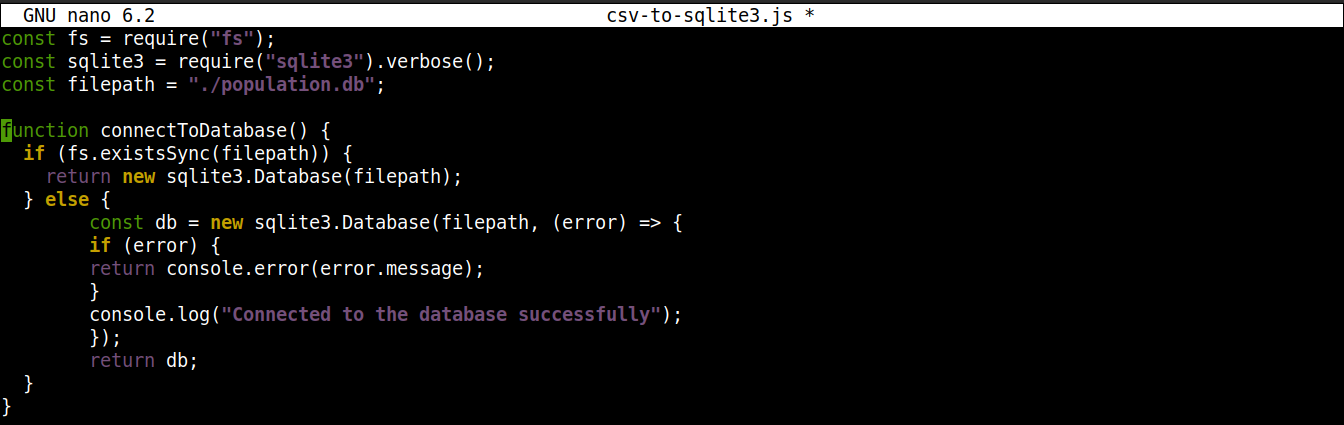
Aqui,
-
O método connectoToDatabase() estabelece uma conexão com o banco de dados.
-
Dentro de connectToDatabase(), estamos invocando o método existsSync() do módulo fs dentro de uma instrução if. A instrução if verifica a existência do banco de dados no local especificado.
-
Se a avaliação da condição for true, então a classe Database() do módulo node-sqlite3 é instanciada. Uma vez estabelecida a conexão, a função retorna um objeto e sai.
-
Se a avaliação da condição for false (o banco de dados não existe), então a execução saltará para o bloco else. Lá, a classe Database() será iniciada com dois argumentos: um caminho para o arquivo do banco de dados e um callback.
-
Basicamente, o banco de dados será criado se não existir. No entanto, se ocorrer algum erro durante o processo de criação, ele definirá o objeto error e imprimirá a mensagem de erro.
A seguir, vamos introduzir códigos para criar uma tabela se o banco de dados não existir:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
const fs = require("fs"); const sqlite3 = require("sqlite3").verbose(); const filepath = "./population.db"; function connectToDatabase() { if (fs.existsSync(filepath)) { return new sqlite3.Database(filepath); } else { const db = new sqlite3.Database(filepath, (error) => { if (error) { return console.error(error.message); } createTable(db); console.log("Conectado ao banco de dados com sucesso"); }); return db; } } function createTable(db) { db.exec(` CREATE TABLE migration ( year_month VARCHAR(10), month_of_release VARCHAR(10), passenger_type VARCHAR(50), direction VARCHAR(20), sex VARCHAR(10), age VARCHAR(50), estimate INT ) `); } module.exports = connectToDatabase(); |
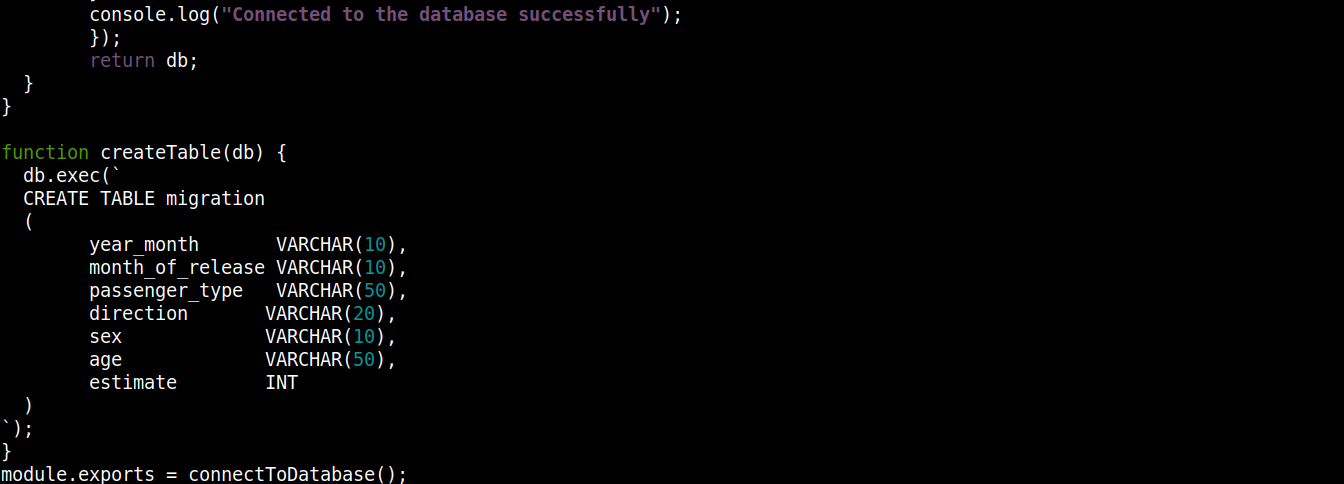
Aqui,
-
O método connectToDatabase() invoca a função createTable() que aceita os objetos armazenados em db como argumento.
-
Fora de connectToDatabase(), definimos o método createTable() que aceita o objeto de conexão db como parâmetro.
-
O método exec() em db recebe uma instrução SQL como argumento. Dentro desta instrução SQL, definimos a criação de uma tabela migration com 7 colunas, cada coluna correspondendo aos cabeçalhos das colunas no arquivo migration_data.csv .
-
Finalmente, estamos invocando o connectToDatabase() método e exportando o objeto de conexão que ele retorna para que possamos usá-lo em outros arquivos.
Save the file and close the editor.
A seguir, vamos criar outro programa para inserir os dados analisados no banco de dados:
|
1 |
nano insert_data.js |
Insira o seguinte código em insert_data.js:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
const fs = require("fs"); const { parse } = require("csv-parse"); const db = require("./csv-to-sqlite3"); fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { db.serialize(function () { db.run( `INSERT INTO migration VALUES (?, ?, ? , ?, ?, ?, ?)`, [row[0], row[1], row[2], row[3], row[4], row[5], row[6]], function (error) { if (error) { return console.log(error.message); } console.log(`Linha inserida, ID: ${this.lastID}`); } ); }); }); |
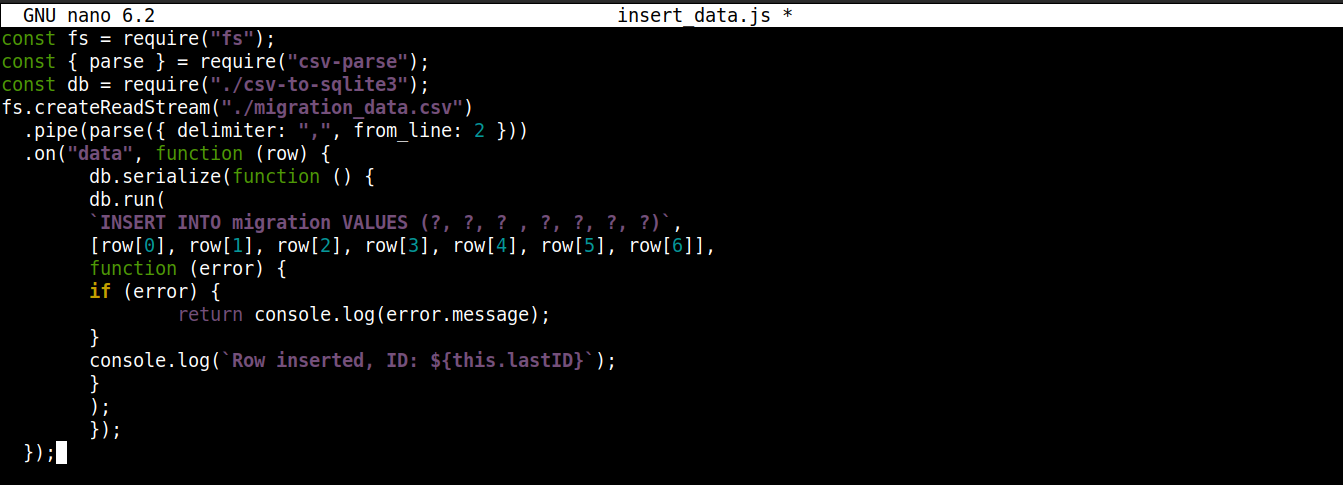
Aqui,
-
Estamos armazenando o objeto de conexão obtido de csv-to-sqlite3.js na variável db.
-
Dentro do callback do evento data (anexado ao stream do módulo fs), estamos invocando o serialize() método no objeto de conexão. Ele garante que uma instrução SQL termine de ser executada antes que a próxima comece, evitando condições de corrida no banco de dados (sistema executando operações concorrentes simultaneamente).
-
O serialize() aceita três argumentos:
-
O primeiro argumento é a instrução SQL.
-
O segundo argumento é um array.
-
O terceiro argumento é um callback que é executado quando os dados são inseridos com sucesso ou sem sucesso no banco de dados.
-
Estamos prontos para executar o programa. Execute insert_data.js usando o Node.js:
|
1 |
node insert_data.js |
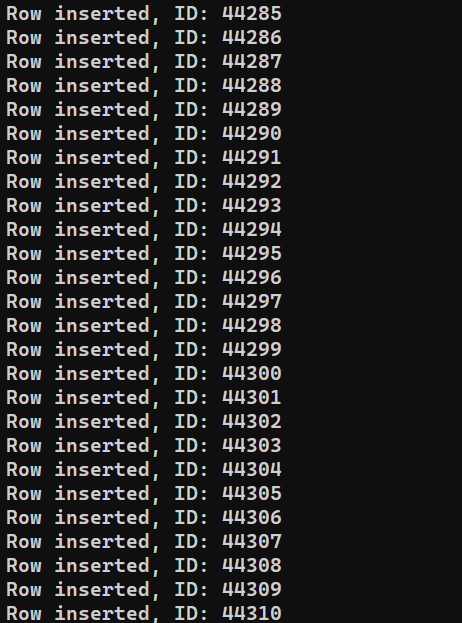
Dependendo do desempenho do sistema, o processo pode levar algum tempo para terminar. No entanto, após a conclusão, a saída deve ser parecida com esta:
Passo 5 – Gravando Dados em CSV
Após a última seção, temos um banco de dados contendo todos os registros que analisamos de migration_data.csv. Nesta seção, vamos ler os dados do banco de dados e gravá-los em um arquivo CSV separado.
Crie um novo arquivo JavaScript para armazenar o programa:
|
1 |
nano write_csv.js |
Primeiro, adicione as seguintes linhas para importar fs e csv-stringify junto com o objeto de conexão do banco de dados de csv-to-sqlite3.js:
|
1 2 3 |
const fs = require("fs"); const { stringify } = require("csv-stringify"); const db = require("./csv-to-sqlite3"); |
Em seguida, vamos adicionar uma variável que contém o nome do arquivo CSV no qual gravar, junto com um fluxo de gravação (writable stream):
|
1 2 3 4 5 6 7 8 9 10 11 |
const filename = "saved_from_db.csv"; const writableStream = fs.createWriteStream(filename); const columns = [ "year_month", "month_of_release", "passenger_type", "direction", "sex", "age", "estimate", ]; |
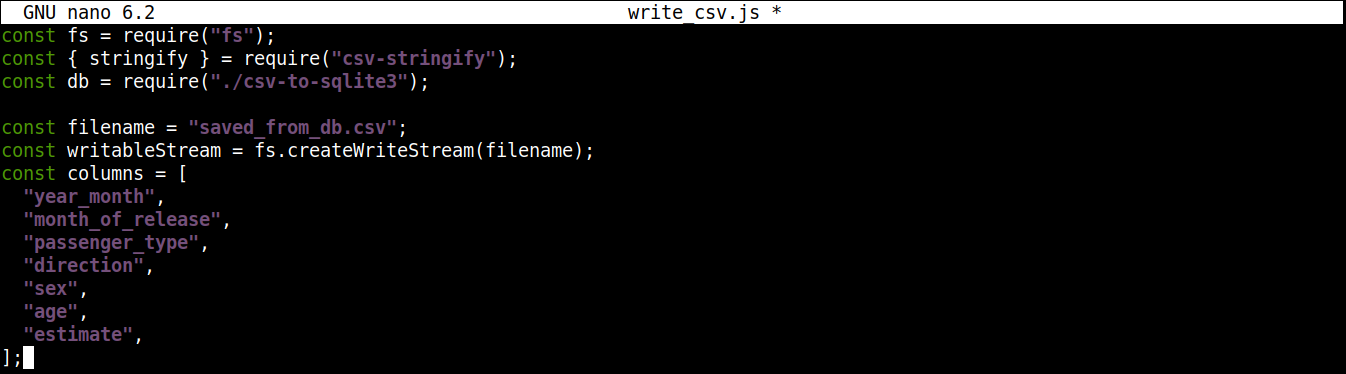
Aqui,
-
O createWriteStream() aceita o nome do arquivo para gravação como um argumento. Vamos nomear o arquivo saved_from_db.csv.
-
A column armazena um array que contém todos os nomes do cabeçalho para os dados do CSV.
Em seguida, adicione as seguintes linhas de código para ler os dados do banco de dados e gravá-los em saved_from_db.csv:
|
1 2 3 4 5 6 7 8 9 10 11 |
const stringifier = stringify({ header: true, columns: columns }); db.each(`select * from migration`, (error, row) => { if (error) { return console.log(error.message); } stringifier.write(row); }); stringifier.pipe(writableStream); console.log("gravação no CSV concluída"); |
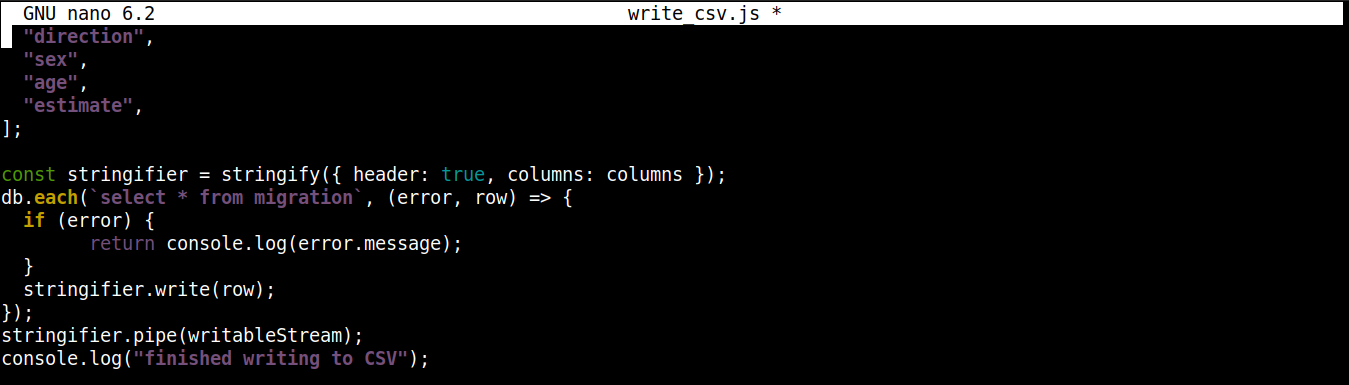
Aqui,
-
Estamos invocando o método stringify() com um objeto como argumento. Isso resulta em um fluxo de transformação (transform stream) que converte os dados de um objeto para o formato CSV. O objeto passado para stringify() possui duas propriedades:
-
header: Aceita um valor booleano. Se o valor for true, então um cabeçalho é gerado.
-
columns: Aceita um array que contém os nomes das colunas a serem gravados na primeira linha do arquivo CSV se header for true.
-
-
O método each() do objeto de conexão csv-to-sqlite3 é invocado com dois argumentos: a instrução SQL (lendo dados do banco de dados) e um callback (tratando sucesso/erro).
-
A cada iteração de each(), pipe() (do fluxo stringifier) começa a enviar dados em partes para o fluxo de gravação writableStream. Cada parte de dados é então gravada em saved_from_db.csv.
-
Quando todos os dados forem gravados no arquivo CSV, uma mensagem de sucesso será exibida na tela do console.
O código final deve ficar assim:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
const fs = require("fs"); const { stringify } = require("csv-stringify"); const db = require("./csv-to-sqlite3"); const filename = "saved_from_db.csv"; const writableStream = fs.createWriteStream(filename); const columns = [ "year_month", "month_of_release", "passenger_type", "direction", "sex", "age", "estimate", ]; const stringifier = stringify({ header: true, columns: columns }); db.each(`select * from migration`, (error, row) => { if (error) { return console.log(error.message); } stringifier.write(row); }); stringifier.pipe(writableStream); console.log("gravação no CSV concluída"); |
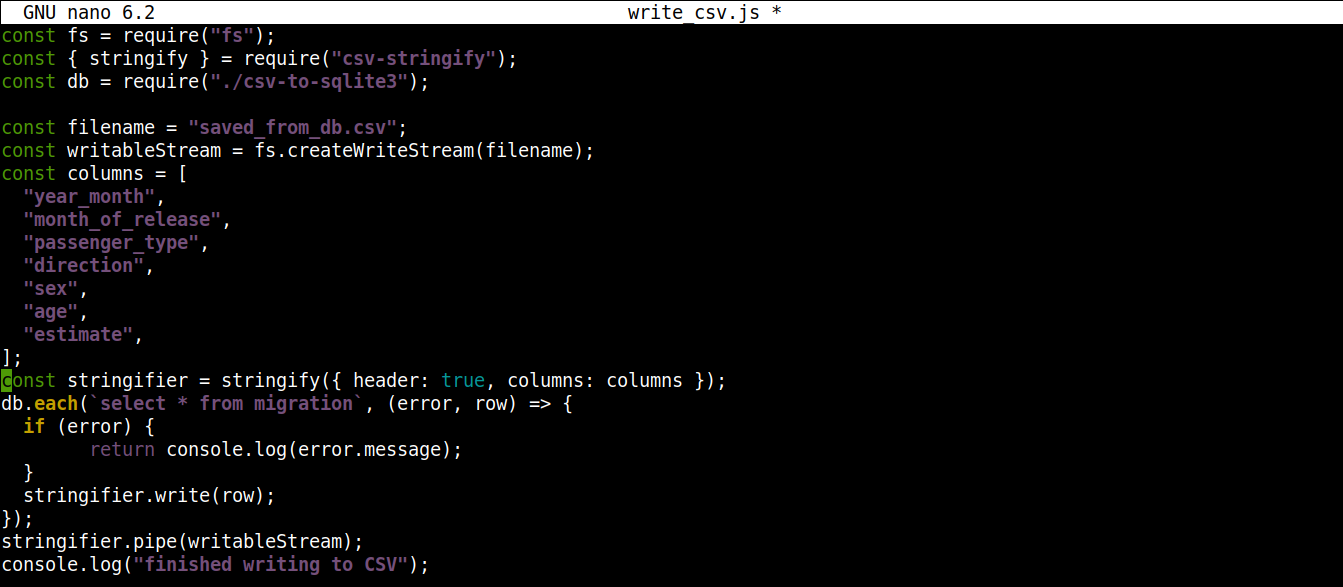
Salve o arquivo e feche o editor. Agora podemos executar o programa usando o Node.js:
|
1 |
node write_csv.js |
Para confirmar se os dados foram exportados com sucesso, verifique o conteúdo de saved_from_db.csv:
|
1 |
cat saved_from_db.csv | less |
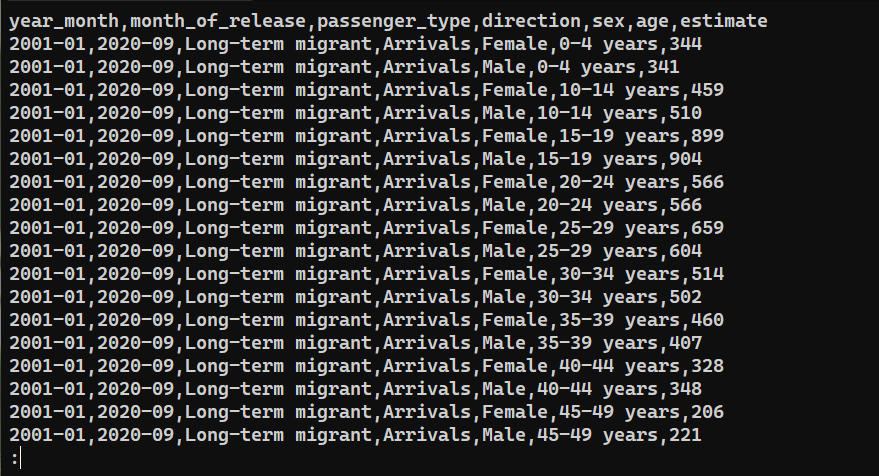
Considerações Finais
Neste guia, demonstramos como trabalhar com arquivos CSV no Node.js usando os módulos node-csv e node-sqlite3. Criamos vários programas para realizar diversas tarefas, por exemplo, analisar dados de um CSV, inserir os dados em um banco de dados SQLite e gravar dados em um novo arquivo CSV.
Este guia demonstra apenas uma pequena parte da capacidade do node-csv módulo. Saiba mais sobre todos os seus recursos em CSV Project. Para saber mais sobre o node-sqlite3, confira a documentação oficial no GitHub. Outro módulo que vale a pena mencionar é o event-stream para simplificar o trabalho com streams.
Interessado em expandir ainda mais seu projeto Node.js? Aqui estão alguns tutoriais de Node.js que você deve conferir:
-
Como implantar um aplicativo Node.js (Express.js) com Docker no Ubuntu 20.04
-
Conectando o PostgreSQL com aplicativos Node.js: Um tutorial
-
Configurando aplicativos Node.js: Como realizar tarefas de produção no Ubuntu 20.04 com Node.js
Boa computação!
Comentários
Nenhum comentário ainda. Seja o primeiro.