

As empresas envolvem muitos dados e isso torna o problema de lidar e gerenciá-los mais difícil. Tradicionalmente, a indústria vem utilizando sistemas RDBMS ao longo das últimas décadas, mas com o advento do Big Data no século XXI, os bancos de dados NoSQL (Not only SQL) entraram em cena para dados não estruturados e semiestruturados em grande escala.
Neste post, vou configurar um cluster MongoDB.
MongoDB é um banco de dados de documentos NoSQL gratuito e de código aberto, amplamente utilizado devido ao alto nível de escalabilidade e flexibilidade que oferece.
Para implantar o MongoDB em produção, é recomendável usar Replica Sets. Os Replica Sets são o equivalente do MongoDB a uma configuração Master/Slave no mundo relacional, mas, em contrapartida, são muito fáceis de configurar, pois tudo já vem integrado. Para saber mais sobre Replica Sets, confira a definição do TutorialsPoint’s sobre o processo de replicação.
Planejando seu Cluster de Servidores Cloud MongoDB
Vou criar um cluster de 3 nós. É importante fornecer a eles recursos iguais porque qualquer um deles pode se tornar o servidor primário (ou seja, master). Esses nós ou máquinas podem rodar em qualquer sistema operacional, mas neste tutorial, vou usar o Ubuntu 18.04 LTS. Para saber como anexar e configurar a imagem pré-instalada da biblioteca da CloudSigma’s, você pode consultar este tutorial.
Como o objetivo principal de um Replica Set é que o cluster sobreviva à queda de um único nó, seria inútil se todos os seus servidores residissem no mesmo host físico. Felizmente, a CloudSigma oferece algo chamado grupos de disponibilidade. O que isso significa é que você pode instruir o sistema a agrupar todos os seus três servidores em grupos diferentes. Ao fazer isso, eles nunca residirão no mesmo host físico. Mais informações sobre isso e outros recursos de segurança e continuidade de negócios podem ser encontradas aqui.
Também é importante usar uma versão de 64 bits do Linux. O motivo é simplesmente que o MongoDB não funciona bem em sistemas de 32 bits (mais sobre isso aqui).
Instalando o MongoDB na Nuvem
Esta seção é bastante simples. Use uma das imagens pré-configuradas do Ubuntu 18.04 ou instale você mesmo.
A configuração de CPU, RAM e disco é realmente individual e depende da sua carga. Para uma instalação pequena, uma CPU de 4 GHz, 4 GB de RAM e 10 GB de disco (para o sistema) devem ser suficientes. Quando você anexar seus discos, certifique-se de que está usando VirtIO. Se você usar IDE, o desempenho será significativamente prejudicado. Além disso, como você está criando um Replica Set, precisa que todos os nós (e servidores de aplicação) estejam na mesma VLAN.
Ao contrário de muitos outros provedores de nuvem, não há necessidade de configurar seu armazenamento com RAID10 ou similar para melhorar o desempenho. Como muitos de nossos clientes relatam, você obterá um desempenho incrível pronto para uso utilizando tanto SSD quanto discos magnéticos na CloudSigma.
Ainda recomendo manter os dados do MongoDB em um disco separado. O motivo para isso é simplesmente que, em algum momento, você pode precisar fazer algumas otimizações no sistema de arquivos que não gostaria de fazer em todo o seu sistema de arquivos.
Com isso em mente, o mais fácil é apenas adicionar esse disco após a configuração dos servidores. Por enquanto, vamos focar apenas na instalação do sistema. Se você estiver instalando por conta própria (em vez de usar os sistemas pré-configurados), recomendo que pressione F4 no menu de boot e selecione ‘Install a minimal virtual machine’.
Estou criando 3 máquinas, cada uma com as seguintes especificações:
- CPU: 4 GHz
- RAM: 4 GB
- SSD: 10 GB (Ubuntu 18.04 LTS), 20 GB (disco extra)
Como listado na parte do SSD, estou anexando um disco de tamanho 10 GB com o Ubuntu 18.04 LTS instalado nele.
Além disso, estou anexando outro disco vazio de tamanho 20 GB junto com ele para armazenar os dados do MongoDB. O tamanho disso depende muito do seu uso, mas para um sistema pequeno, 20 GB provavelmente devem ser suficientes. No entanto, como às vezes é difícil prever quantos dados você armazenará, usaremos LVM. Isso permitirá que você simplesmente adicione outro drive mais tarde e expanda o volume sem ter que recomeçar. Alternativamente, você pode usar um único drive e escalá-lo mais tarde comresize2fs.
Para adicionar o disco, basta ir à seção ‘Drives’, clicar no ícone ‘Create a new drive’ no topo, dar um nome ao novo disco e definir seu tamanho para 20 GB. Assim que estiver salvo, vá para a máquina individual à qual deseja anexá-lo e, na seção de drives dos detalhes dessa máquina, você pode clicar em ‘Attach a drive’ e selecionar o disco.
Agora que você tem três máquinas, pode prosseguir com a montagem do disco extra que adicionou para o armazenamento de dados do MongoDB em cada máquina. Recomendo adicionar este disco como uma partição. O uso de particionamento permite que o sistema operacional gerencie as informações em cada região separadamente. Para adicionar o disco como uma partição, primeiro vou verificar todos os discos conectados à nossa máquina. Para isso, executarei o seguinte comando:
|
1 |
fdisk -l |
Quando executo o comando, obtenho a saída indicando os discos e os dispositivos na minha máquina.
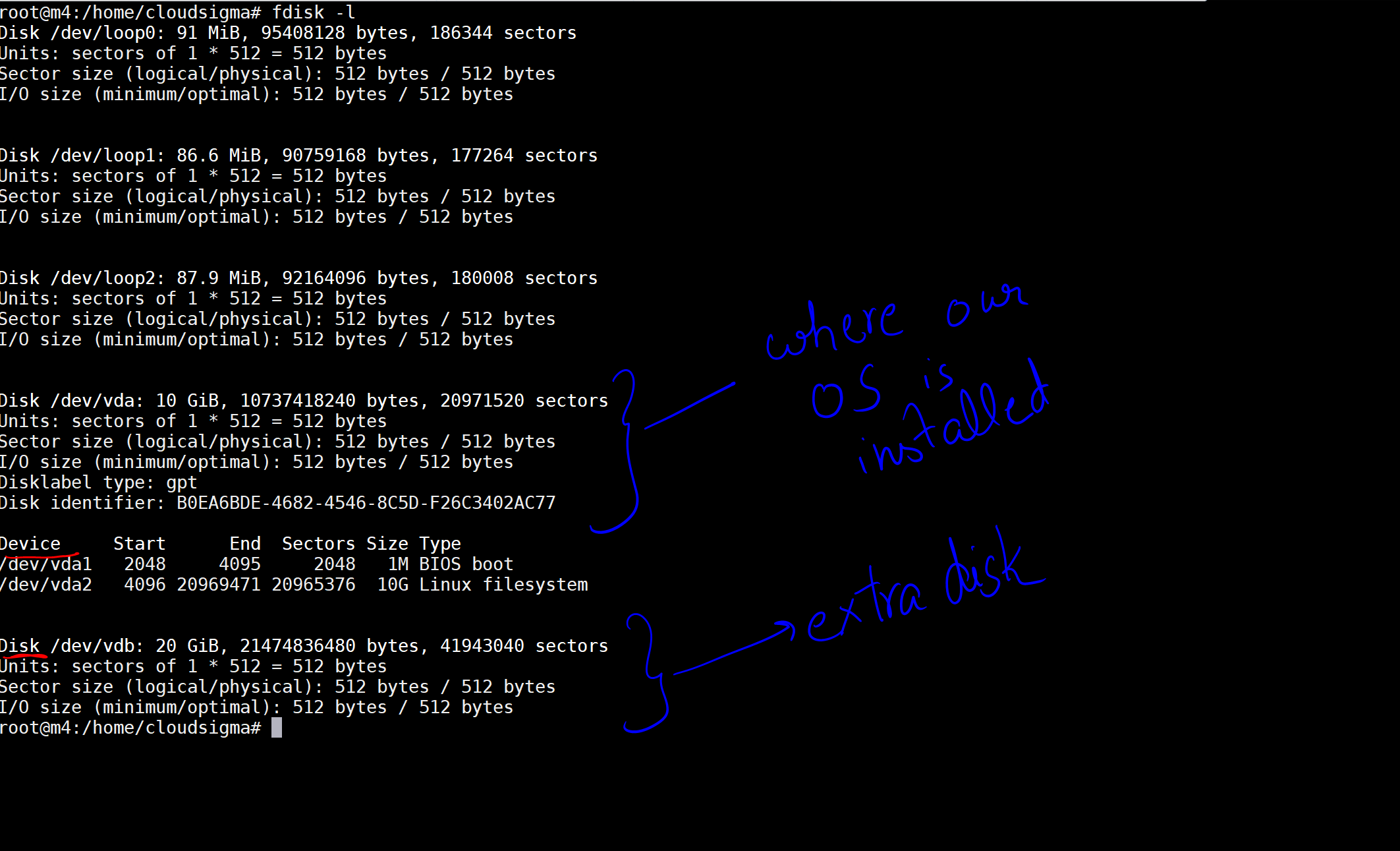
Na imagem, marquei um disco de 10 GB como aquele onde nosso SO está instalado. Depois, há outro disco de 20 GB que agora foi conectado. A localização do disco é /dev/vdb. Você pode criar uma partição neste disco usando os seguintes comandos:
|
1 |
sudo fdisk /dev/vdb |
Isso abrirá o utilitário fdisk, um utilitário de linha de comando que fornece funções de particionamento de disco, no qual você pode criar partições no nosso disco. Ele exibirá um prompt “Command (m for help):” onde você precisa digitar n para criar uma nova partição e, em seguida, continue pressionando enter para aceitar os valores padrão. E depois de criar a partição, digite w para gravar as alterações. Ficará assim:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
Comando (m para ajuda): <strong>n</strong> Partição tipo p primária (0 primária, 0 estendida, 4 livre) e estendida (container para lógica partições) Selecionar (padrão p): Usando padrão resposta p. Partição número (1-4, padrão 1): Primeiro setor (2048-41943039, padrão 2048): Último setor, +setores ou +tamanho{K,M,G,T,P} (2048-41943039, padrão 41943039): Criada uma nova partição 1 do tipo 'Linux' e de tamanho 20 GiB. Comando (m para ajuda): <strong>w</strong> A tabela de partição foi totalmente alterada. Chamando ioctl() para re-ler a tabela de partição. Sincronizando discos. |
Uma nova partição 1 do tipo ‘Linux’ e de tamanho 20 GiB foi criada. Agora que a partição foi criada, vamos criar um pool LVM:
|
1 2 3 |
sudo pvcreate /dev/vdb1 sudo vgcreate mongodb /dev/vdb1 sudo lvcreate -n db -L 19.5g mongodb |
Eu inseri ‘19.5g’ já que o tamanho da minha partição é 20g. Em seguida, execute o seguinte comando para descobrir o nome do disco:
|
1 |
fdisk -l | grep mongo | awk '{print $2'} |
Depois disso, formate o disco usando o método ext4 com o seguinte comando:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
sudo mkfs.ext4 /dev/mapper/mongodb-db Saída: root@m4:/home/cloudsigma# sudo mkfs.ext4 /dev/mapper/mongodb-db mke2fs 1.44.1 (24-Mar-2018) Criando sistema de arquivos com 5217280 4k blocos e 1305600 inodes Sistema de arquivos UUID: 695a62e6-021d-4fc0-945c-cc51a92d86da Superbloco backups armazenados em blocos: 32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208, 4096000 Alocando grupo tabelas: concluído Gravando inode tabelas: concluído Criando journal (32768 blocos): concluído Gravando superblocos e sistema de arquivos contabilidade informações: concluído |
A seguir, vamos criar um local para montar o disco e uma pasta para manter os seus dados do MongoDB.
|
1 |
sudo mkdir -p /mongodb/data |
Para adicionar uma entrada no fstab sobre o seu novo disco a ser montado, você pode usar diretamente o comando abaixo:
|
1 |
echo -e "` blkid | grep mongodb | awk {'print $2'}`\t/mongodb\text4 auto,noexec,rw,sync,nouser\t0\t0" >> /etc/fstab |
No comando, blkid fornece um UUID – Identificador Único Universal de cada disco. Aqui eu extraio com o grep o do disco do MongoDB e combino este UUID com o local da pasta de montagem, tipo de sistema de arquivos e outras opções para o disco, respectivamente. Estou adicionando esta linha ao /etc/fstab. Se você não fizer isso, receberá um erro ao montar o disco. A entrada se parece com isso:
UUID=”695a62e6-021d-4fc0-945c-cc51a92d86da” /mongodb ext4 auto,noexec,rw,sync,nouser 0 0
Agora, você pode montar o disco no local /mongodb:
|
1 |
sudo mount /mongodb |
Instalando o MongoDB
Com o sistema preparado, vamos passar para a instalação do MongoDB. Embora o Ubuntu ofereça uma versão do MongoDB em seu próprio repositório, recomendo que você use a versão oficial do MongoDB. O motivo é que o repositório do Ubuntu está bastante desatualizado em relação aos lançamentos, portanto, se você quiser aproveitar ao máximo o MongoDB, terá que recorrer aos lançamentos oficiais.
Como o MongoDB oferece seu próprio repositório, você pode simplesmente adicioná-lo ao seu sistema e instalar o MongoDB normalmente. Aqui estão as etapas a seguir:
Primeiro, importe a chave pública usada pelo sistema de gerenciamento de pacotes:
|
1 |
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 9DA31620334BD75D9DCB49F368818C72E52529D4 |
Depois, eu crio um arquivo de lista. Ele conterá o repositório onde o MongoDB está, para que seu sistema possa baixá-lo de lá:
|
1 |
echo "deb [ arch=amd64 ] https://repo.mongodb.org/apt/ubuntu bionic/mongodb-org/4.0 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-4.0.list |
Agora, estou atualizando meu banco de dados de pacotes local para que eu possa considerar as alterações.
|
1 |
sudo apt-get update |
Agora, posso apenas instalar o pacote usando o seguinte comando:
|
1 |
sudo apt-get install -y mongodb-org |
Instalei o MongoDB em cada uma das máquinas.
|
1 |
sudo service mongod start |
Agora o MongoDB está ativo e em execução, com os dados na unidade criada. Se for esperada uma carga pesada e/ou muitas conexões, você pode precisar aumentar os valores de ulimit.
Se você quiser obter mais informações sobre seus dados, também pode se inscrever no MMS, que é um serviço gratuito de monitoramento baseado em nuvem para o MongoDB.
Criando o Replica Set para a sua Nuvem MongoDB
Agora, vamos criar um replica set. Antes disso, você precisa garantir que cada uma das máquinas possa se comunicar entre si. Para este propósito, adicione estas entradas em /etc/hosts
|
1 2 3 |
IP-1 m1.mongo.cluster m1 IP-2 m2.mongo.cluster m2 IP-3 m3.mongo.cluster m3 |
Para verificação, você pode tentar pingar as máquinas usando o hostname. Então, se o IP da minha máquina 1’s é IP-1, digamos, 213.189.123.12, em vez de escrever
|
1 |
ping 123.189.123.12 |
eu escreverei,
|
1 2 3 |
ping m1.mongo.cluster ou ping m1. |
Se você ativou o firewall (o que realmente deveria fazer), certifique-se de que os nós possam enviar e receber tráfego TCP nas portas 28017 e 27017 na interface interna.
Agora, em cada uma das máquinas, prossiga e inicie o serviço mongod usando os seguintes comandos.
Na máquina m1,
|
1 |
mongod --dbpath /mongodb/data --replSet rs0 --bind_ip localhost,m1.mongo.cluster |
Em seguida, na máquina m2,
|
1 |
mongod --dbpath /mongodb/data --replSet rs0 --bind_ip localhost,m2.mongo.cluster |
Na máquina m3,
|
1 |
mongod --dbpath /mongodb/data --replSet rs0 --bind_ip localhost,m3.mongo.cluster |
Aqui,
mongod é o nome do serviço
dbpath é o local do diretório do nosso banco de dados
replSet é o nome do nosso conjunto de réplicas. Deve ser o mesmo para cada uma das máquinas no mesmo conjunto de réplicas
bind_ip é o hostname da máquina onde você o está executando.
Depois de iniciar o serviço mongod, vá para o servidor primário (no meu caso, escolhi o m1) e execute o mongo.
|
1 |
mongo |
Isso iniciará o terminal do MongoDB. No terminal, inicie o replicaSet usando o comando abaixo. Ele criará o replicaSet com as configurações padrão:
|
1 |
rs.initiate() |
Agora, vamos apenas adicionar as outras duas máquinas como réplicas usando os seguintes comandos:
|
1 2 |
rs.add("m2.mongo.cluster") rs.add("m3.mongo.cluster") |
Você pode monitorar o status usando o comando:
|
1 |
rs.status() |
Isso é realmente tudo. Agora você deve estar com seu cluster MongoDB ativo e funcionando na nuvem ultrarrápida da CloudSigma’s.
Comentários
Nenhum comentário ainda. Seja o primeiro.