

The Elastic Stack (anteriormente conhecido como ELK Stack) é uma solução poderosa para registro centralizado. É uma coleção de software de código aberto desenvolvida pela Elastic. Ele permite que os administradores pesquisem, analisem e visualizem logs gerados a partir de qualquer origem em qualquer formato. É uma prática conhecida como registro centralizado. O registro centralizado pode ser muito útil ao tentar identificar problemas com servidores e aplicativos, pois permite pesquisar em todos os logs a partir de um único local. Também pode ajudar a identificar problemas em vários servidores, correlacionando os logs em um momento específico.
In In deste guia, confira como instalar o Elastic Stack no Ubuntu 18.04. Primeiro, siga o nosso tutorial para facilmente instalar o seu servidor Ubuntu na CloudSigma.
O Elastic Stack no Ubuntu
O Elastic Stack consiste nos seguintes componentes:
- Elasticsearch: Um mecanismo de busca RESTful distribuído. Ele armazena todos os dados coletados.
- Logstash: A parte de processamento de dados do Elastic Stack. Ele envia os dados recebidos para o Elasticsearch.
- Kibana: Uma interface web que oferece recursos de pesquisa e visualização de logs.
- Beats: Um transmissor de dados leve e de propósito único. Ele pode enviar dados de inúmeras máquinas para o Logstash ou Elasticsearch.
Você precisará instalar manualmente cada componente da stack.
Pré-requisitos
Antes de prosseguir com a instalação do the Elastic Stack, vários requisitos de sistema devem ser atendidos:
- Requisitos de hardware:
- CPU: 2 CPUs (acessível a partir de um usuário sudo não-root)
- RAM: 4GB
- OpenJDK 11 (a versão mais recente do Java LTS). Para instalar isso, dê uma olhada no nosso tutorial sobre como configurar o Java no Ubuntu 18.04.
- Nginx com as configurações adequadas. Você pode seguir o nosso guia para instalar o Nginx no Ubuntu 18.04 para configurá-lo.
Observe que a quantidade de armazenamento depende do número de logs a serem coletados e armazenados. Além disso, o Elastic Stack também lida com informações valiosas sobre o servidor. Para manter a transmissão de dados segura, recomendamos fortemente a configuração de um certificado TLS/SSL. Siga este tutorial para adquirir um certificado SSL gratuito no seu servidor Nginx.
Além de um servidor criptografado, as seguintes etapas também serão necessárias:
- Um FQDN (fully qualified domain name). Neste guia, será <domain>.
- Ambos os registros DNS dos seguintes domínios direcionam para o servidor.
- Um registro A com <domain> apontando para o IP público do servidor.
- Um registro A com www.<domain> apontando para o IP público do servidor.
Instalando o Elastic Stack
-
Configurando o repositório do Elastic
Os componentes do Elastic Stack não estão disponíveis diretamente no repositório oficial do Ubuntu. Felizmente, o Ubuntu permite que repositórios de 3ª parte instalem pacotes. Para o nosso propósito, adicionaremos o repositório de pacotes do Elastic. O repositório oferece todas as atualizações de pacotes mais recentes de todos os pacotes do Elastic. Todos os pacotes do Elastic são assinados com a chave de assinatura do Elasticsearch para evitar a falsificação de pacotes. Primeiro, adicione a chave ao chaveiro do Ubuntu:
|
1 |
curl -fsSL https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add - |
Em seguida, adicione a lista de fontes do Elastic no diretório “sources.list.d”. É o diretório dedicado que o APT usa para buscar novas fontes:
|
1 |
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list |
Finalmente, atualize o cache do APT:
|
1 |
sudo apt update |
De acordo com a documentação oficial, recomenda-se instalar cada um dos componentes na ordem demonstrada neste guia. Isso garante que os componentes dos quais cada produto depende estejam no lugar certo.
-
Instalando e configurando o Elasticsearch
Assim que o repositório do Elastic estiver configurado, o APT estará pronto para baixar e instalar todos os pacotes do Elastic. Execute o seguinte comando para instalar o Elasticsearch:
|
1 |
sudo apt install elasticsearch |
Agora você pode configurar o Elasticsearch. O arquivo “elasticsearch.yml” fornece opções de configuração sobre clusters, nós, caminhos, redes, memória, gateway e outros. A maioria deles vem pré-configurada no arquivo. Em seguida, abra o arquivo de configuração do Elasticsearch com um editor de texto de sua escolha:
|
1 |
sudo vim /etc/elasticsearch/elasticsearch.yml |
O Elasticsearch escuta na porta 9200 de qualquer lugar. Recomendamos restringir o acesso externo ao Elasticsearch para evitar que pessoas de fora leiam os dados ou desliguem os clusters do Elasticsearch usando sua API REST. Para restringir o acesso ao Elasticsearch e reforçar sua segurança, descomente a seguinte linha e substitua seu valor:
|
1 |
network.host: localhost |
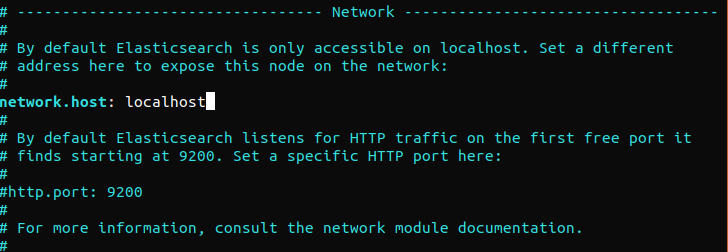
Se o Elasticsearch deve escutar em um endereço IP específico, substitua “localhost” pelo endereço IP de destino. Este é o requisito mínimo de configuração antes de executar o Elasticsearch. Salve e feche o arquivo de configuração. Em seguida, inicie o serviço Elasticsearch. Pode levar alguns instantes para iniciar o Elasticsearch:
|
1 |
sudo systemctl start elasticsearch |
Depois disso, você precisa garantir que o Elasticsearch seja iniciado sempre que o servidor for inicializado:
|
1 |
sudo systemctl enable elasticsearch |
O comando a seguir verificará se o serviço Elasticsearch está em execução. Tudo o que ele requer é o envio de uma requisição HTTP:
|
1 |
curl -X GET "localhost:9200" |
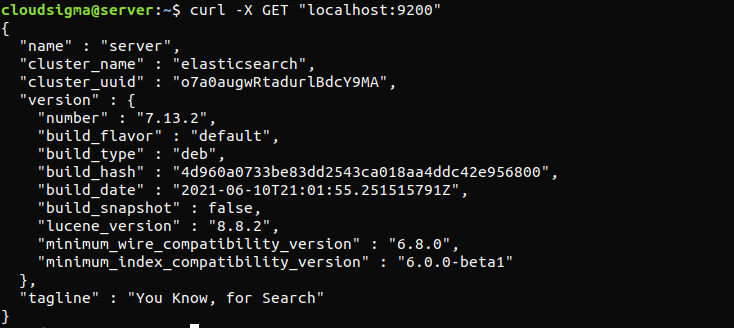
A resposta será parecida com esta. Será uma resposta mostrando algumas informações básicas sobre o nó local.
Instalando e Configurando o Painel do Kibana
O Kibana está disponível diretamente no repositório da Elastic. Observe que você só deve instalar o Kibana depois de já ter instalado o Elasticsearch. Assumindo que o repositório já está disponível, o APT pode obter e instalar diretamente o Kibana:
|
1 |
sudo apt install kibana |
Depois de instalado, habilite e inicie o serviço Kibana:
|
1 2 |
sudo systemctl enable kibana sudo systemctl start kibana |
Por padrão, o Kibana está configurado para escutar apenas em “localhost”. Para acesso externo, ele requer a configuração de um proxy reverso. Aqui, o Nginx será o proxy reverso. Use o comando openssl para criar um usuário administrador do Kibana. Essa será a conta de usuário para acessar a interface web do Kibana. Aqui, o nome de usuário de exemplo será “kibana_admin”. Para garantir uma melhor segurança, recomendamos o uso de um nome de usuário não padrão. O comando a seguir criará um usuário administrador para o Kibana. O nome de usuário e a senha serão gerados e armazenados no arquivo “htpasswd.users”. O Nginx terá que ser configurado para usar o nome de usuário e a senha:
|
1 |
echo "kibana_admin:`openssl passwd -apr1`" | sudo tee -a /etc/nginx/htpasswd.users |
Insira e confirme uma senha no prompt. Essa senha será importante para acessar a interface do Kibana. Depois disso, você precisa criar um arquivo de bloco de servidor do Nginx. Para demonstração, será exemplo.com. Também pode ser qualquer outro nome descritivo. Se houver registros FQDN e DNS configurados para o servidor, o nome do arquivo também pode ser baseado no FQDN:
|
1 |
sudo vim /etc/nginx/sites-available/example.com |
Se houver algum conteúdo pré-existente, remova-o e substitua-o pelas seguintes linhas de código:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
server { listen 80; server_name example.com; auth_basic "Acesso Restrito"; auth_basic_user_file /etc/nginx/htpasswd.users; location / { proxy_pass http://localhost:5601; proxy_http_version 1.1; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection 'upgrade'; proxy_set_header Host $host; proxy_cache_bypass $http_upgrade; } } |
Salve e feche o arquivo. Crie um link simbólico da nova configuração no diretório “sites-enabled”. Se já existir algum link com o mesmo nome de arquivo, esta etapa pode não ser necessária:
|
1 |
sudo ln -s /etc/nginx/sites-available/example.com /etc/nginx/sites-enabled/example.com |
O seguinte comando solicitará que o Nginx verifique se há algum erro de sintaxe:
|
1 |
sudo nginx -t |
Se houver algum problema de sintaxe, certifique-se de que o conteúdo do arquivo foi colocado corretamente. Em seguida, reinicie o serviço Nginx:
|
1 |
sudo systemctl restart nginx |
Diga ao UFW para permitir a conexão ao Nginx:
|
1 |
sudo ufw allow 'Nginx Full' |
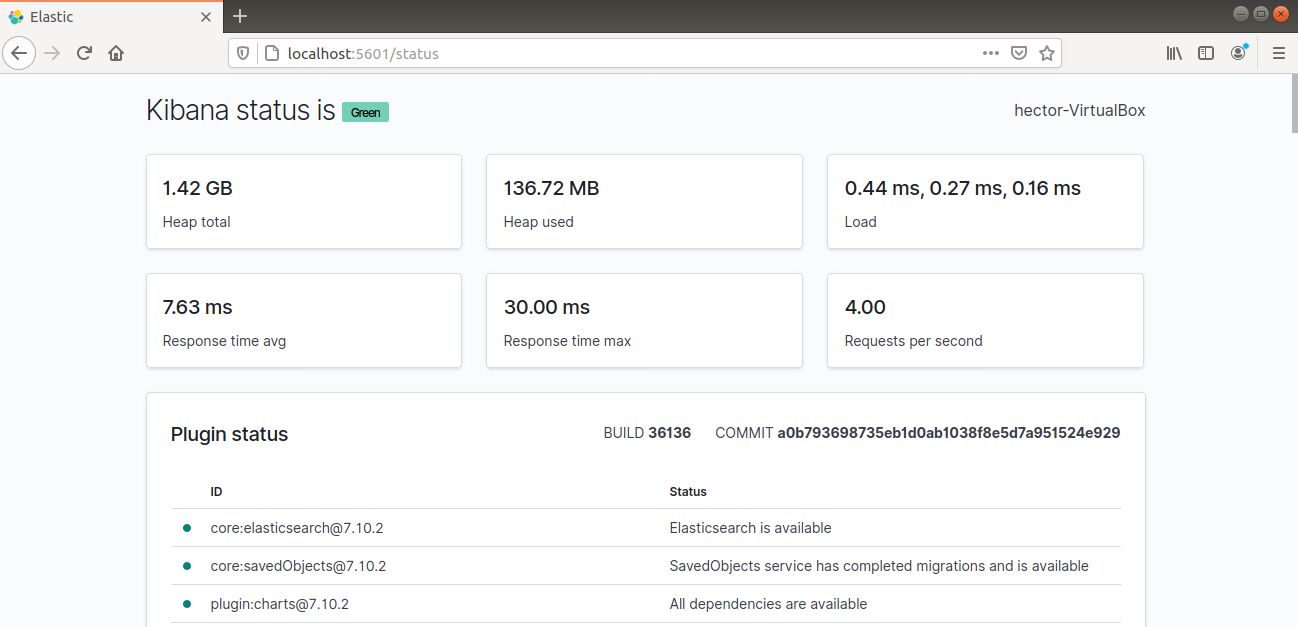
O Kibana agora deve estar acessível através do FQDN ou do endereço IP público do servidor Elastic Stack. Verifique a página de status do servidor Kibana:
|
1 |
http://<server_ip>:5601/status |
Instalando e configurando o Logstash
Embora o Beats possa enviar dados diretamente para o banco de dados do Elasticsearch’s, é recomendável usar o Logstash para processar os dados. O Logstash pode coletar os dados e convertê-los em um formato comum antes de exportá-los para outro banco de dados. Execute o seguinte comando APT para instalar o Logstash:
|
1 |
sudo apt install logstash |
Assim que a instalação for concluída, é hora de configurar o Logstash. Os arquivos de configuração do Logstash estão no formato JSON. Você pode encontrar todos eles no diretório “/etc/logstash/conf.d”. É útil pensar no Logstash como um pipeline, recebendo dados em uma extremidade, processando-os e enviando-os para o destino. Um pipeline do Logstash requer dois elementos obrigatórios – input e output com um elemento opcional – filter. O plugin input recebe os dados, o filter plugin processa os dados, e o output plugin grava os dados no destino. O seguinte comando criará um arquivo de configuração que configurará o Logstash para o input do Filebeat:
|
1 |
sudo vim /etc/logstash/conf.d/02-beats-input.conf |
Insira a seguinte configuração de input. Ela descreve um beats input que escutará na porta 5044 via TCP:
|
1 2 3 4 5 |
input { beats { port => 5044 } } |
O próximo passo é criar um arquivo de configuração chamado “10-syslog-filter.conf”. Nós o usaremos para definir um filtro para syslogs (logs do sistema):
|
1 |
sudo vim /etc/logstash/conf.d/10-syslog-filter.conf |
Insira o seguinte código de configuração do syslog. Este código está disponível diretamente no Elastic guide. Este código explica a configuração de input para o Logstash:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
input{ beats{ port => 5044 host => "0.0.0.0" } } filter { if [fileset][module] == "system" { if [fileset][name] == "auth" { grok { match => { "message" => ["%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: %{DATA:[system][auth][ssh][event]} %{DATA:[system][auth][ssh][method]} for (invalid user )?%{DATA:[system][auth][user]} from %{IPORHOST:[system][auth][ssh][ip]} port %{NUMBER:[system][auth][ssh][port]} ssh2(: %{GREEDYDATA:[system][auth][ssh][signature]})?", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: %{DATA:[system][auth][ssh][event]} user %{DATA:[system][auth][user]} from %{IPORHOST:[system][auth][ssh][ip]}", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: Did not receive identification string from %{IPORHOST:[system][auth][ssh][dropped_ip]}", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sudo(?:\[%{POSINT:[system][auth][pid]}\])?: \s*%{DATA:[system][auth][user]} :( %{DATA:[system][auth][sudo][error]} ;)? TTY=%{DATA:[system][auth][sudo][tty]} ; PWD=%{DATA:[system][auth][sudo][pwd]} ; USER=%{DATA:[system][auth][sudo][user]} ; COMMAND=%{GREEDYDATA:[system][auth][sudo][command]}", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} groupadd(?:\[%{POSINT:[system][auth][pid]}\])?: new group: name=%{DATA:system.auth.groupadd.name}, GID=%{NUMBER:system.auth.groupadd.gid}", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} useradd(?:\[%{POSINT:[system][auth][pid]}\])?: new user: name=%{DATA:[system][auth][user][add][name]}, UID=%{NUMBER:[system][auth][user][add][uid]}, GID=%{NUMBER:[system][auth][user][add][gid]}, home=%{DATA:[system][auth][user][add][home]}, shell=%{DATA:[system][auth][user][add][shell]}$", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} %{DATA:[system][auth][program]}(?:\[%{POSINT:[system][auth][pid]}\])?: %{GREEDYMULTILINE:[system][auth][message]}"] } pattern_definitions => { "GREEDYMULTILINE"=> "(.|\n)*" } remove_field => "message" } date { match => [ "[system][auth][timestamp]", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ] } geoip { source => "[system][auth][ssh][ip]" target => "[system][auth][ssh][geoip]" } } else if [fileset][name] == "syslog" { grok { match => { "message" => ["%{SYSLOGTIMESTAMP:[system][syslog][timestamp]} %{SYSLOGHOST:[system][syslog][hostname]} %{DATA:[system][syslog][program]}(?:\[%{POSINT:[system][syslog][pid]}\])?: %{GREEDYMULTILINE:[system][syslog][message]}"] } pattern_definitions => { "GREEDYMULTILINE" => "(.|\n)*" } remove_field => "message" } date { match => [ "[system][syslog][timestamp]", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ] } } } } |
O próximo arquivo de configuração lidará com a saída. Abra um novo arquivo chamado “30-elasticsearch-output.conf”:
|
1 |
sudo vim /etc/logstash/conf.d/30-elasticsearch-output.conf |
Insira o seguinte código. Este código explica a configuração de saída para o Logstash:
|
1 2 3 4 5 6 7 |
output { elasticsearch { hosts => ["localhost:9200"] manage_template => false index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}" } } |
Teste a configuração do Logstash. Em seguida, execute o seguinte comando:
|
1 |
sudo -u logstash /usr/share/logstash/bin/logstash --path.settings /etc/logstash -t |
Se não houver erros, o Logstash exibirá a seguinte mensagem de sucesso. Se não for bem-sucedido, certifique-se de que todos os arquivos de configuração tenham os códigos corretos. Por fim, inicie e ative o serviço do Logstash:
|
1 2 |
sudo systemctl start logstash sudo systemctl enable logstash |
Agora que o Logstash está sendo executado com sucesso e totalmente configurado, vamos instalar o Filebeat.
Instalando e configurando o Filebeat
O Elastic Stack usa coletores de dados, conhecidos como “Beats”, para coletar dados de várias fontes e transportá-los para o Logstash/Elasticsearch. Aqui está uma pequena lista dos Beats disponíveis da Elastic:
- Filebeat: Coleta/envio de arquivos de log.
- Metricbeat: Coleta/envio de métricas de sistemas e serviços.
- Packetbeat: Coleta/análise de dados de rede.
- Winlogbeat: Coleta de logs de eventos do Windows.
- Auditbeat: Coleta de dados do framework de auditoria do Linux e monitoramento de integridade de arquivos.
- Heartbeat: Monitoramento de serviços quanto à sua disponibilidade.
Para fins deste tutorial, precisaremos do Filebeat para enviar logs locais para o Elastic Stack. Primeiro, instale o Filebeat:
|
1 |
sudo apt install filebeat |
Agora você pode configurar o Filebeat. Primeiro, ele precisa se conectar ao Logstash. Usaremos a configuração de exemplo que vem com o Filebeat. Abra o arquivo de configuração em um editor de texto. Observe que, como o arquivo está no formato YAML, a indentação correta é importante:
|
1 |
sudo vim /etc/filebeat/filebeat.yml |
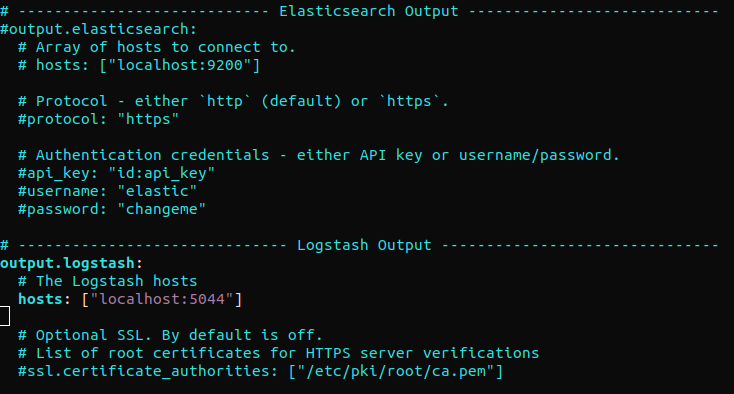
Encontre a seção “output.elasticsearch” e comente as seguintes linhas. Isso configurará o Filebeat para enviar eventos diretamente para o Elasticsearch/Logstash para processamento adicional. Em seguida, pule para a seção “output.logstash.” Depois, descomente as linhas:
|
1 2 3 4 5 6 7 |
#output.elasticsearch: # Array de hosts para se conectar. # hosts: ["localhost:9200"] output.logstash: # Os hosts do Logstash hosts: ["localhost:5044"] |
O Filebeat suporta módulos que podem estender sua funcionalidade. Neste tutorial, usaremos o módulo system que coleta e analisa logs gerados pelo serviço de log do sistema de distribuições Linux comuns. Ative o módulo system do Filebeat:
|
1 |
sudo filebeat modules enable system |
O seguinte comando do Filebeat listará todos os módulos ativados e desativados:
|
1 |
sudo filebeat modules list |
Por padrão, o Filebeat está configurado para seguir os caminhos padrão para logs de syslog e autorização. Os parâmetros dos módulos estão disponíveis no arquivo de configuração “/etc/filebeat/modules.d/system.yml”.
O próximo passo é carregar o modelo de índice no Elasticsearch. Um índice do Elasticsearch denota uma coleção de documentos que compartilham características semelhantes. Cada índice vem com um nome. O nome é necessário ao realizar várias operações dentro dele. O modelo de índice é aplicado automaticamente toda vez que um novo índice é gerado. Em seguida, carregue o modelo:
|
1 |
sudo filebeat setup --template -E output.logstash.enabled=false -E 'output.elasticsearch.hosts=["localhost:9200"]' |
O Filebeat contém um painel de exemplo para o Kibana por padrão. Ele ajuda a visualizar os dados do Filebeat no Kibana. No entanto, antes de usar o painel, é necessário criar o padrão de índice e carregar os painéis no Kibana. Enquanto os painéis são carregados, o Filebeat entra em contato com o Elasticsearch para obter informações sobre a versão. Para carregar os painéis, enquanto o Logstash está ativado, é necessário ter a saída do Logstash desativada e a saída do Elasticsearch ativada. O seguinte comando fará o trabalho:
|
1 |
sudo filebeat setup -e -E output.logstash.enabled=false -E output.elasticsearch.hosts=['localhost:9200'] -E setup.kibana.host=localhost:5601 |
Finalmente, você pode iniciar o Filebeat:
|
1 2 |
sudo systemctl start filebeat sudo systemctl enable filebeat |
Agora, é hora de testar a configuração do Elastic Stack. Se tiver sido configurado corretamente, a saída será parecida com isto:
|
1 |
curl -XGET 'http://localhost:9200/filebeat-*/_search?pretty' |
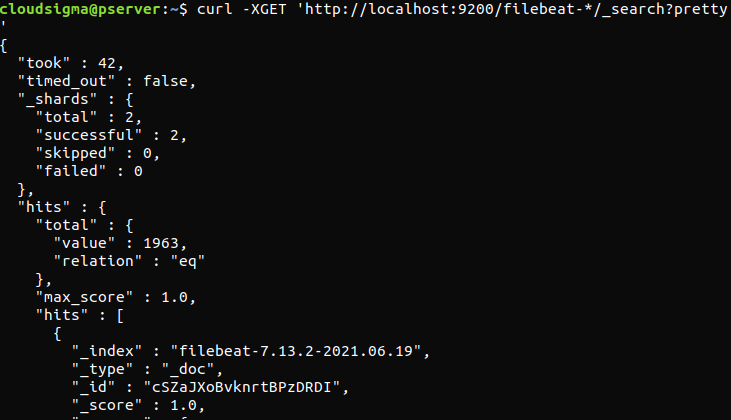
Se a saída reportar 0 total hits, o Elasticsearch não está carregando nenhum log sob o índice que pesquisamos. Isso indica que houve um erro na configuração. Se a saída for a esperada, então o Elastic Stack foi configurado com sucesso.
Visão Geral dos Painéis do Kibana
Agora, é hora de explorar a interface web do Kibana que já instalamos. Primeiro, abra o painel do Kibana. Ele deve estar localizado no FQDN ou no endereço IP público do servidor Elastic Stack:
|
1 |
http://<server_ip>:5601 |
Insira as credenciais de login que geramos anteriormente. Uma vez logado, o painel se parecerá com isto:
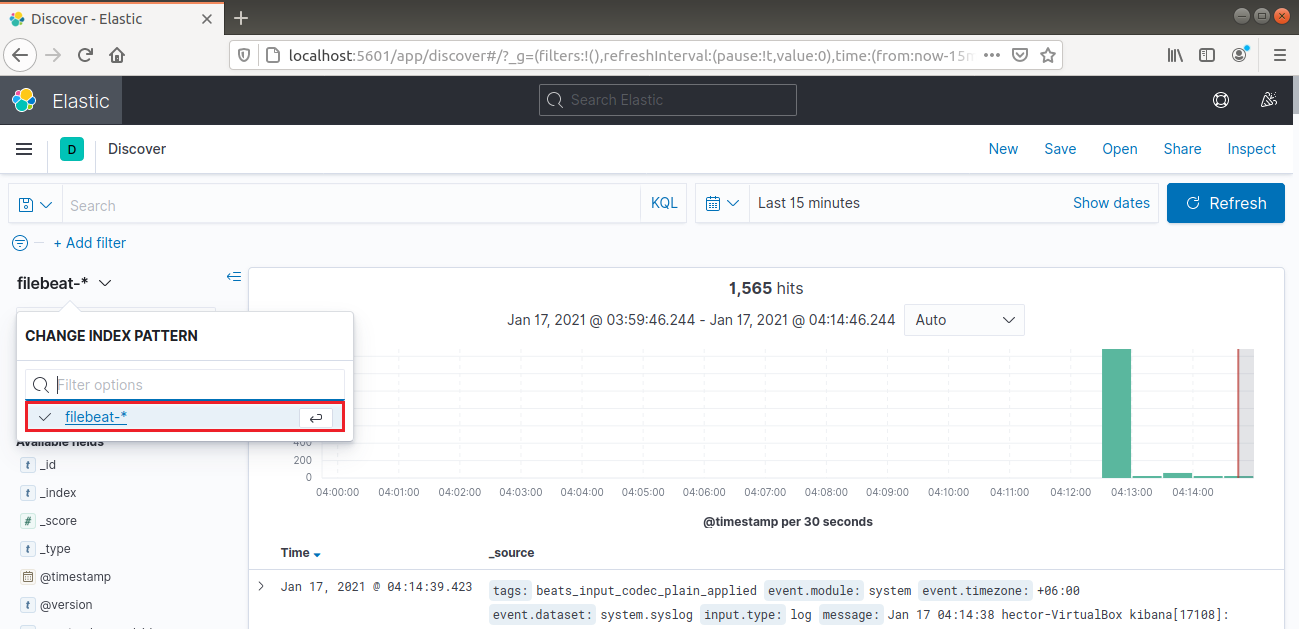
Na barra de navegação esquerda, selecione “Discover”. Em seguida, selecione o padrão “filebeat-*”. Ele mostra todos os logs coletados nos últimos 15 minutos. É possível pesquisar e navegar pelos logs e personalizar o painel:
Na barra de navegação esquerda, vá para Dashboard >> Filebeat System. Aqui, todos os painéis de amostra do módulo de sistema do Filebeat estão disponíveis.
No exemplo a seguir, são detalhadas várias estatísticas com base nas mensagens do syslog:
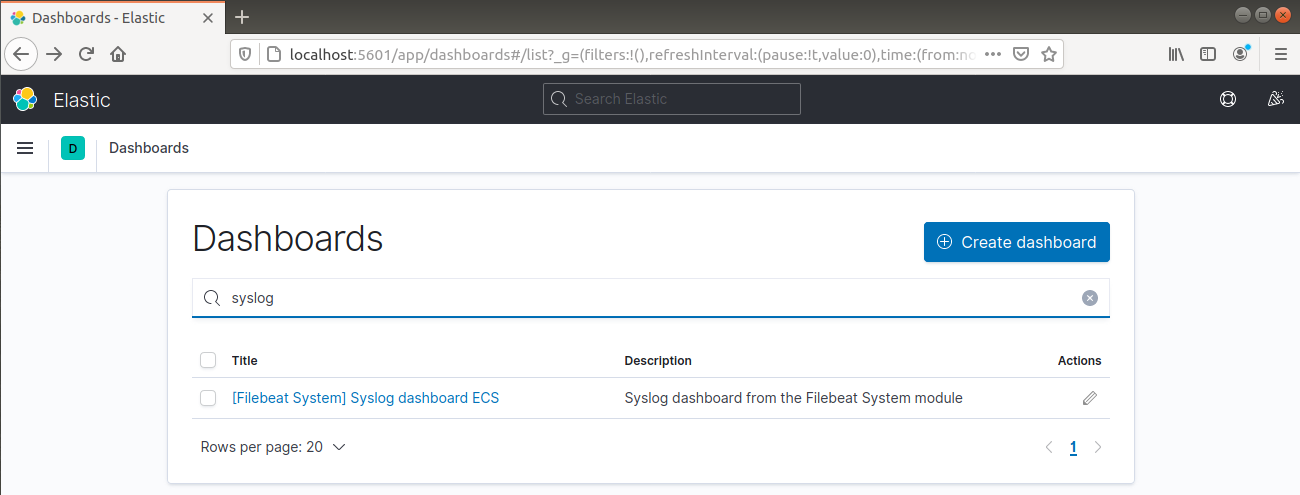
Ele também pode relatar quais usuários executaram comandos com sudo:
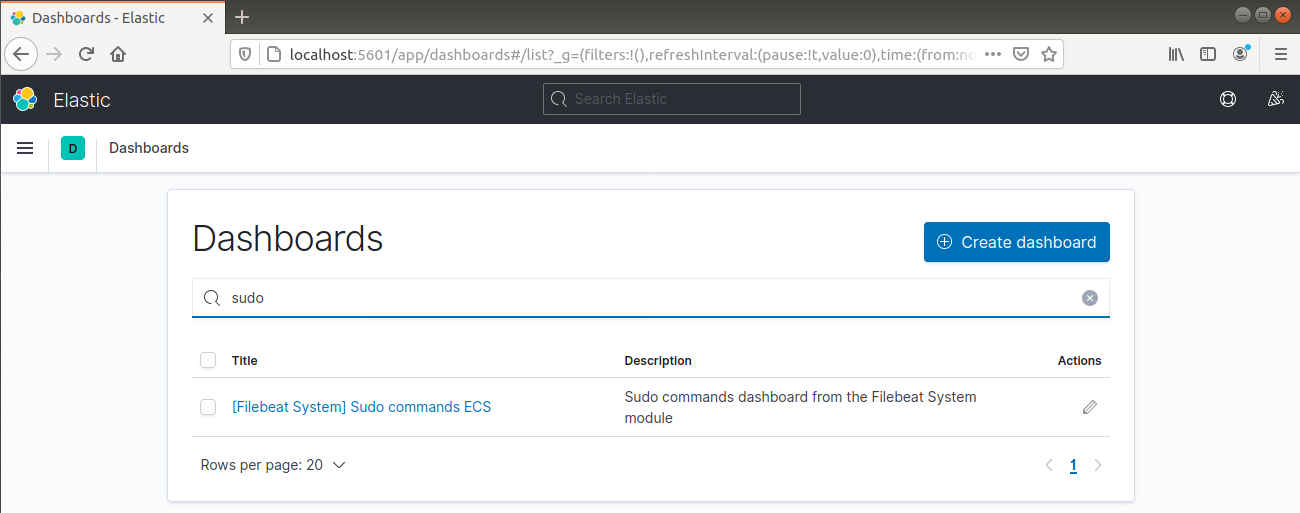
Finalmente, o Kibana oferece a oportunidade de explorar muitas outras funcionalidades, como gráficos e filtragem, então sinta-se à vontade para explorar por conta própria.
Considerações Finais
O Elastic Stack é uma solução poderosa para analisar logs do sistema. Tenha em mente que, embora qualquer log ou dado indexado possa ser enviado para o Logstash usando Beats, ele se torna mais útil quando analisado e estruturado por meio de filtros do Logstash.
Boa computação!
Comentários
Nenhum comentário ainda. Seja o primeiro.