

Web scraping, web crawling, web harvesting ou extração de dados da web são sinônimos que se referem ao ato de minerar dados de páginas da web em toda a Internet. Web scrapers ou web crawlers são ferramentas que percorrem páginas da web programaticamente extraindo os dados necessários. Esses dados, que geralmente são grandes conjuntos de texto, podem ser usados para fins analíticos, para entender produtos ou para satisfazer a curiosidade de alguém sobre uma determinada página da web.
Se você está se perguntando como pode começar com o web crawling, mostraremos o básico de web scraping por meio de um conjunto de dados simples. Você deve ser capaz de acompanhar o tutorial independentemente do seu nível de experiência em programação. Para o exemplo prático, usaremos o nosso blog da CloudSigma. Tentaremos obter informações sobre os tutoriais em nossa página de blog. Quando você estiver lendo a conclusão deste tutorial, terá um web scraper funcional feito com Python 3 que rastreia várias páginas em nossa seção de blog e, em seguida, exibe os dados em sua tela.
Usando o conhecimento obtido ao criar este web scraper básico, você pode expandi-lo e criar seus próprios web scrapers. Isso deve ser divertido, vamos começar!
Pré-requisitos
Este é um tutorial prático, então você deve ter um ambiente de desenvolvimento local para Python 3 para acompanhar bem. Primeiro, você pode consultar nosso tutorial sobre como instalar o Python 3 e configurar um ambiente de programação local no Ubuntu.
Scrapy
O web scraping envolve duas etapas: a primeira etapa é encontrar e baixar páginas da web, a segunda etapa é rastrear e extrair informações dessas páginas da web.
Existem várias maneiras e bibliotecas que podem ser usadas para construir um web scraper do zero em muitas linguagens de programação. No entanto, isso pode trazer problemas no futuro quando seu web scraper se tornar complexo, ou quando você precisar rastrear várias páginas com diferentes configurações e padrões ao mesmo tempo. Pode ser uma tarefa bastante pesada descobrir como transformar seus dados extraídos entre diferentes formatos, como CSV, XML ou JSON.
Embora alguns possam gostar do desafio de construir seu próprio web scraper do zero, é melhor não reinventar a roda e, em vez disso, construí-lo sobre uma biblioteca existente que lida com todos esses problemas. Nós usaremos o Scrapy, uma biblioteca Python, junto com o Python 3 para implementar o web scraper neste tutorial. O Scrapy é uma ferramenta de código aberto e uma das bibliotecas de web scraping em Python mais populares e poderosas. O Scrapy foi construído para lidar com algumas das funcionalidades comuns que todos os scrapers devem ter. Dessa forma, você não precisa reinventar a roda sempre que quiser implementar um web crawler. Com o Scrapy, o processo de construção de um scraper torna-se fácil e divertido.
O Scrapy está disponível no PyPi, comumente conhecido como pip – o Python Package Index. O PyPi é um repositório de propriedade da comunidade que hospeda a maioria dos pacotes Python. Quando você instala e configura o Python 3 em seu ambiente de desenvolvimento local, ele também instala o pip, que você pode usar para instalar pacotes Python.
Passo 1: Como Construir um Web Scraper Simples
Primeiro, para instalar o Scrapy, execute o seguinte comando:
|
1 |
pip install scrapy |
Opcionalmente, você pode seguir as instruções oficiais de instalação do Scrapy da página de documentação. Se você instalou o Scrapy com sucesso, crie uma pasta para o projeto usando um nome de sua escolha:
|
1 |
mkdir cloudsigma-crawler |
Navegue até a pasta e crie o arquivo principal para o código. Este arquivo conterá todo o código deste tutorial:
|
1 |
touch main.py |
Se desejar, você pode criar o arquivo usando seu editor de texto ou IDE em vez do comando acima.
Em seguida, abra o arquivo e vamos começar criando um scraper básico que usa o Scrapy. Criaremos uma classe Python que estende scrapy.Spider, uma classe spider básica do Scrapy. Esta classe terá dois atributos obrigatórios, conforme definido abaixo:
- name — um nome do tipo string para identificar o spider (você pode inserir um nome de sua escolha).
- start_urls — uma matriz contendo uma lista de URLs para rastrear. Começaremos com uma URL.
Adicione o seguinte snippet de código no arquivo aberto para criar o spider básico:
|
1 2 3 4 5 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] |
Abaixo está uma explicação de cada linha de código:
A primeira linha importa o Scrapy, permitindo-nos usar as várias classes que o pacote fornece.
Na próxima linha, estendemos a classe Spider fornecida pelo Scrapy e criamos uma subclasse chamada CloudSigmaCrawler. Ao estender uma Classe(Spider), obtemos acesso às propriedades da Classe que agora podemos usar em nosso código. Neste caso, a classe Spider possui métodos e comportamentos que definem como seguir URLs e extrair dados de páginas web. No entanto, ela não sabe quais URLs seguir ou quais dados extrair. Ao estendê-la, podemos fornecer as informações necessárias aos métodos. Para entender mais sobre criação de subclasses e extensão, continue lendo Princípios de programação orientada a objetos.
Em nosso CloudSigmaCrawler, definimos os atributos necessários. Primeiro, nomeamos nosso spider como cloudsigma_crawler. Em seguida, fornecemos uma única URL para começar: https://blog.cloudsigma.com/blog/. Abrir esta URL levará você à página 1 do blog da CloudSigma, que contém alguns dos muitos tutoriais.
Hora de testar o scraper. Você tem algumas opções. Se estiver usando uma IDE, por exemplo, a PyCharm community edition da JetBrains, ela provavelmente vem com um botão no qual você pode apenas clicar para executar o script. Outra opção é seguir a maneira típica de executar arquivos Python a partir da linha de comando: python caminho/para/arquivo.py, ou py caminho/para/arquivo.py. Outra opção é a interface de linha de comando do Scrapy. O Scrapy vem com sua própria interface de linha de comando para ajudar a iniciar um scraper. Insira o seguinte comando para iniciar o scraper:
|
1 |
scrapy runspider main.py |
Dependendo da versão da biblioteca do Scrapy que você instalou, você deverá ver uma saída parecida com a seguinte:
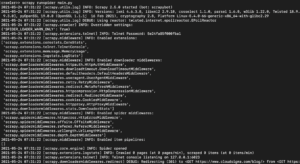
Como você pode ver, a saída é bastante longa, então apenas escolhemos algumas partes. Aqui está o que aconteceu quando você executou o comando:
- O scraper foi inicializado. Portanto, ele carregou componentes e extensões adicionais que precisa usar para seguir e ler dados de URLs.
- Ao usar a URL fornecida na lista start_urls, ele capturou o HTML da página. Este é um processo semelhante ao que o navegador segue ao abrir páginas web.
- Depois de capturar o HTML, ele é passado para o método parse, que ainda não definimos. Por enquanto ele não faz nada, portanto o spider apenas sai sem fazer nenhum processamento. Definiremos o comportamento do método parse na próxima etapa.
Etapa 2: Como extrair dados de uma página
Na etapa 1, implementamos apenas um scraper básico que captura uma página HTML, mas não faz nada depois. Nesta seção, forneceremos instruções para extrair dados. Na página do CloudSigma Blog da qual queremos extrair dados, há algumas coisas que você pode notar, tais como:
- O cabeçalho, presente em todas as páginas.
- O menu de navegação e a caixa de filtro de pesquisa.
- A lista real dos tutoriais em formato de grade.
Visualizar o código-fonte da página HTML que você pretende raspar dá uma ideia geral da estrutura da página. Isso ajuda você a escrever um scraper. Você pode ver o código-fonte clicando com o botão direito na página e selecionando Exibir código-fonte, ou pressionando Ctrl + U. Aqui está um snippet do código-fonte:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
<body> <div id="x-iso-container" class="x-iso-container x-iso-container-posts cols-3"> <article id="post-51691" class="post-51691 post type-post status-publish format-standard has-post-thumbnail hentry category-blog-posts category-tutorials tag-apache tag-certbot tag-cloud-guide tag-cloud-tutorial tag-https tag-lets-encrypt tag-ssl tag-ssl-certification tag-tutorial tag-ubuntu"> <div class="entry-wrap"> <header class="entry-header"> <h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Link permanente para: "Protegendo o Apache com Let’s Encrypt no Ubuntu 18.04"">Protegendo o Apache com Let’s Encrypt no Ubuntu 18.04</a> </h2> </header> <div class="entry-content excerpt"> <p>A segurança do site e dos dados são tópicos que não podem ser tratados de forma leviana. Informações altamente confidenciais, que incluem registros financeiros e informações privadas dos clientes, estão sempre em trânsito entre o computador do usuário e o seu site. Quando você considera esse fato, não é difícil ver por que sites não seguros poderiam resultar em uma violação que poderia prejudicar seriamente o seu negócio. Existem … </p> <div><a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="more-link">Leia Mais</a></div> </div> </div> ... </article> </div> </body> |
Como você pode ver, cada tutorial do blog está contido dentro de uma tag HTML chamada <article>. A raspagem da página envolverá duas etapas. A primeira etapa será capturar cada tutorial do blog procurando as partes da página que contêm os dados que queremos. A próxima etapa é extrair os dados que queremos de cada tutorial identificado pela tag HTML.
O Scrapy identifica os dados a serem capturados com base nos seletores que você fornece. Podemos usar seletores para encontrar um ou mais elementos em uma página e obter os dados dentro dos elementos. O Scrapy tem suporte para XPath e CSS seletores.
A partir do código-fonte que visualizamos anteriormente, os seletores CSS parecem ser mais fáceis. Portanto, esta será a opção que escolheremos, pois nos ajudará a encontrar todos os tutoriais na página. A partir do código-fonte HTML, cada tutorial é especificado dentro da classe CSS chamada post. Os nomes das classes CSS são geralmente identificados com .nome_da_classe (ponto nome_da_classe). Assim, usaremos .post para o nosso seletor CSS. Dentro do código-fonte do nosso scraper main.py, passaremos a classe .post para o objeto de resposta, de modo que seu arquivo agora ficará assim:
|
1 2 3 4 5 6 7 8 9 10 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): pass |
Este trecho de código irá capturar todos os tutoriais na página com as start_urls especificadas e percorrer os tutoriais para extrair dados. Na próxima etapa, você desejará extrair e exibir esses dados. Se você examinar o código-fonte do blog da CloudSigma novamente, você verá que o título de cada tutorial está armazenado dentro de uma tag <a> que está dentro de uma tag <h2>, por exemplo:
|
1 2 3 4 5 |
<h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Permalink to: "Securing Apache with Let’s Encrypt on Ubuntu 18.04"">Securing Apache with Let’s Encrypt on Ubuntu 18.04</a> </h2> |
Cada objeto de tutorial sobre o qual estamos iterando contém um método CSS ao qual podemos passar um seletor para localizar e extrair elementos filhos. Para este exemplo, queremos extrair o título que está contido dentro da tag <a>. Esta tag está dentro da tag <h2> dentro da classe .entry-header dentro da classe .entry-wrap. Podemos passar esses seletores CSS para o método do objeto para extrair o título, modifique o código para que fique assim:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), } |
A vírgula final após extract_first() não é um erro de digitação, pois adicionaremos mais código abaixo da seção.
Alguns pontos a serem observados no código-fonte acima incluem:
- ::text anexado ao seletor – este é um pseudo-seletor CSS que instrui o código a buscar o texto dentro da tag e não a tag em si.
- chamada do método extract_first() dentro do objeto – instrui o código a escolher apenas o primeiro elemento que corresponde ao seletor. Portanto, obtemos uma string em vez de uma lista de elementos.
Em seguida, salve o arquivo e execute o código digitando o seguinte comando no seu terminal:
|
1 |
scrapy runspider main.py |
Na saída, você deverá ver os títulos dos tutoriais:
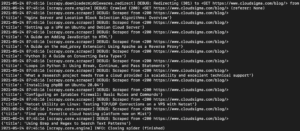
Podemos continuar expandindo isso adicionando mais seletores para obter outros detalhes sobre um tutorial, como a URL do tutorial, a imagem de destaque e a legenda.
Vamos examinar o código HTML de um único tutorial novamente:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
<body> <div id="x-iso-container" class="x-iso-container x-iso-container-posts cols-3"> <article id="post-51691" class="post-51691 post type-post status-publish format-standard has-post-thumbnail hentry category-blog-posts category-tutorials tag-apache tag-certbot tag-cloud-guide tag-cloud-tutorial tag-https tag-lets-encrypt tag-ssl tag-ssl-certification tag-tutorial tag-ubuntu"> <div class="entry-featured"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="entry-thumb" title="Link permanente para: "Protegendo o Apache com Let’s Encrypt no Ubuntu 18.04""> <img width="1000" height="522" src="data:image/svg+xml,%3Csvg%20xmlns='http://www.w3.org/2000/svg'%20viewBox='0%200%201000%20522'%3E%3C/svg%3E" class="attachment-entry-fullwidth size-entry-fullwidth wp-post-image" alt="Let’s Encrypt" loading="lazy" data-lazy-srcset="/media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04.jpg 1000w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-300x157.jpg 300w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-768x401.jpg 768w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-610x318.jpg 610w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-100x52.jpg 100w" data-lazy-sizes="(max-width: 1000px) 100vw, 1000px" data-lazy-src="/media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04.jpg"/> </a> </div> <div class="entry-wrap"> <header class="entry-header"> <h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Permalink to: "Securing Apache with Let’s Encrypt on Ubuntu 18.04"">Protegendo Apache com Let’s Encrypt no Ubuntu 18.04</a> </h2> </header> <div class="entry-content excerpt"> <p>A segurança do site e dos dados são tópicos que não podem ser tratados de forma leviana. Informações altamente confidenciais que incluem registros financeiros e informações privadas dos clientes estão sempre em trânsito entre o computador do usuário e o seu site. Ao considerar esse fato, não é difícil ver por que sites não seguros poderiam resultar em uma violação que poderia prejudicar seriamente o seu negócio. Há uma … </p> <div><a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="more-link">Leia Mais</a></div> </div> </div> </article> </div> </body> |
Queremos tentar extrair as partes destacadas, ou seja, a URL do tutorial, a imagem em destaque e a legenda.
- A partir do trecho de código acima, a imagem do blog é armazenada dentro do atributo data-lazy-src de uma tag img dentro de uma tag <a> dentro de uma tag div no início do tutorial do blog. Podemos usar um seletor CSS para capturar o valor como fizemos com os títulos dos tutoriais.
- Obter a URL do tutorial é simples, pois temos a tag <a> dentro do elemento <div>.
- A legenda está contida dentro da tag <p> que está dentro da tag <div>.
Usaremos as classes CSS para obter o que queremos. Vamos modificar o código para que fique assim:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), 'caption': tutorial.css(CAPTION_SELECTOR).extract_first(), } |
Salve as alterações e execute o código com o seguinte comando:
|
1 |
scrapy runspider main.py |
Você verá mais dados na saída, como a URL, imagem e legenda que adicionamos:

Isso é tudo para rastrear uma única página. A seguir, vamos ver como podemos criar um scraper que segue links.
Passo 3: Como Rastrear Múltiplas Páginas
Até este ponto, criamos um scraper que consegue obter dados de uma única página. No entanto, queremos mais do que isso. Você quer um spider que possa seguir links e extrair dados de múltiplas páginas de um site de forma programática.
Se você for até o final da página do blog da CloudSigma, notará os links de paginação e uma pequena seta apontando para a direita indicando a próxima página. Aqui está o trecho de código HTML:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<div class="x-pagination"> <ul class="center-list center-text"> <li><span class="pages">Página 1 de 45</span></li> <li></li> <li><span class="current">1</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/2/" class="single_page" title="2">2</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="single_page" title="3">3</a></li> <li><span class="expand">...</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/45/" class="last" title="Última Página">45</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/2/" class="prev-next hidden-phone">→</a></li> </ul> </div> |
O trecho mostra vários links de navegação de página dentro de tags <li>, sob a tag <div> com a classe CSS .x-pagination. Nosso foco está no link que aponta para a próxima página. Ele está na tag <a> do último <li> na tag <ul>.
O link que aponta para a próxima página possui a classe .prev-next dentro da tag <a>, como visto no trecho acima. No entanto, se você for para a próxima página, também notará que os links para a página anterior e seguinte possuem essa classe CSS. Considere este trecho para a Página 2:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<div class="x-pagination"> <ul class="center-list center-text"> <li><span class="pages">Página 2 de 45</span></li> <li><a href="https://blog.cloudsigma.com/blog/" class="prev-next hidden-phone">←</a></li> <li><a href="https://blog.cloudsigma.com/blog/" class="single_page" title="1">1</a></li> <li><span class="current">2</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="single_page" title="3">3</a></li> <li><span class="expand">...</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/45/" class="last" title="Última Página">45</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="prev-next hidden-phone">→</a></li> </ul> </div> |
Se usarmos o método extract_first() do Scrapy, ele funcionará na primeira página. Quando chegar à próxima página, ele escolherá o primeiro link com a classe .prev-next, que no trecho acima, aponta para a primeira página. Isso resultará em um loop. Portanto, usaremos o método extract() do Scrapy. Este método extrai todos os elementos correspondentes a um caso de uso e os coloca em um array. A partir deste array, podemos escolher o último elemento que conterá o link real que aponta para a próxima página. Modifique seu código para que fique assim:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), } NEXT_PAGE_SELECTOR = '.x-pagination > ul.center-list > li > a.prev-next::attr("href")' next_page = response.css(NEXT_PAGE_SELECTOR).extract() if next_page: yield scrapy.Request( response.urljoin(next_page[-1]), callback=self.parse ) |
Vamos analisar o código para a seleção de next_page.
Primeiro definimos um seletor para os links da página seguinte e anterior. Em seguida, usamos o método extract() para extrair as URLs e colocá-las em um array. A variável next_page será um array com dois elementos como:
|
1 |
next_page = [prev_page_url, next_page_url] |
Como estamos navegando para a página seguinte, escolheremos o último elemento do array. Next_page[-1] escolhe o último elemento do array.
O bloco if verifica se a variável next_page tem algum conteúdo e, em seguida, chama o método scrapy.Request(). Em nosso código, instruímos esse método a rastrear a página com a URL fornecida e passá-la de volta para o método parse() para que possamos analisá-la para extrair os dados e repetir o processo para a página seguinte. Esse processo é repetido até que não encontre um link para a página seguinte, ou melhor, se o bloco falhar, ele para.
Salve seu código e execute-o. Você notará que a iteração continua percorrendo as páginas à medida que encontra mais páginas para extrair dados. É assim que você definiria um scraper que segue links em um site. Nosso exemplo é bastante simples. Estamos apenas acessando uma página, encontrando o link para a página seguinte e repetindo o processo. Em outros casos de uso, você pode querer seguir tags ou links que apontam para fontes externas e muito mais. Aqui está o código-fonte completo para o web scraper básico em Python 3:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), 'caption': tutorial.css(CAPTION_SELECTOR).extract_first(), } NEXT_PAGE_SELECTOR = '.x-pagination > ul.center-list > li > a.prev-next::attr("href")' next_page = response.css(NEXT_PAGE_SELECTOR).extract() if next_page: yield scrapy.Request( response.urljoin(next_page[-1]), callback=self.parse ) |
Conclusão
Neste tutorial, construímos um web scraper básico que pode rastrear o diretório do blog da CloudSigma e exibir algumas informações sobre os tutoriais do blog em apenas cerca de 27 linhas de código.
Claro, isso é possível porque o construímos sobre a biblioteca Python Scrapy. Esta é apenas uma base que deve ajudá-lo a construir scrapers mais complexos que seguem mais tags, resultados de pesquisa de sites e muito mais. Você pode conferir as documentações oficiais do Scrapy para mais informações sobre como trabalhar com o Scrapy.
Boa computação!
Comentários
Nenhum comentário ainda. Seja o primeiro.