

The grep コマンドは、テキスト内のパターンを検索するための強力なユーティリティです。これは、任意の Linux ディストリビューションにプリインストールされています。以下は、LAMP Stack(Linux、Apache、MySQL、PHP)のセットアップについて説明したチュートリアル.
です。grepという名前は、global regular expression print(グローバル正規表現印刷)の略です。このツールは、入力内の指定されたパターンを検索します。原理的には単純に聞こえます。しかし、その真の力はパターンの定義方法にあります。このガイドでは、複雑な検索を実行するために、正規表現でgrepを使用する方法について詳しく説明します。 それでは始めましょう!
Grepの使い方
grepコマンド自体は複雑ではありません。必要なのは、検索を実行するパターンとコンテンツだけです。grepコマンドの基本構造は次のようになります。
|
1 |
grep <regex> <file> |
テキストの検索
まず、アクションを実行するためのサンプルファイルを取得します。 GNU General Public License v3.0 (テキスト形式)をダウンロードしてください。これは、多くの単語やフレーズが含まれている非常に大きなテキストファイルです。 Ubuntu を使用している場合は、以下のファイルで見つけることができます。迅速かつ簡単なUbuntuのインストールについては、Ubuntuのインストールに関するクイック&イージーチュートリアル.
|
1 |
curl -o gpl.txt https://www.gnu.org/licenses/gpl-3.0.txt |

次に、grepを使用して基本的なテキスト検索を実行できます。
|
1 |
grep <pattern> <text_file> |
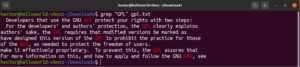
コマンドの出力をgrepにパイプすることも可能です。
|
1 |
cat gpl.txt | grep <pattern> |
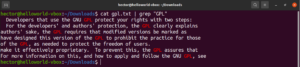
大文字と小文字の区別
デフォルトでは、grepは大文字と小文字を区別して動作します。多くの場合、大文字と小文字の区別を無視するのが最適です。大文字と小文字を区別しない検索を有効にするには、「-i」または「–ignore-case」フラグを使用します。
|
1 2 3 |
$ grep -i <pattern> <file> $ grep --ignore-case <pattern> <flag> |
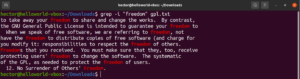
検索結果の反転
デフォルトでは、grepの動作はパターンが見つかった行を出力することです。一致の反転とは、パターンに一致する行を表示したくない現象を指します。一致を反転するには、「-v」または「–invert-match」フラグを使用する必要があります。
|
1 2 3 |
$ grep -v <pattern> <file> $ grep --invert-match <pattern> <file> |
行番号
非常に大きなファイルに対してgrepを実行する場合、検索結果の場所を追跡するのは困難です。作業を容易にするために、grepには行番号を表示する機能があります。行番号表示を有効にするには、「-n」または「–line-number」フラグを使用します。
|
1 2 3 |
grep -n <pattern> <file> grep --line-number <pattern> <file> |
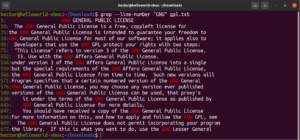
複数のgrep引数を組み合わせることも可能です。次のgrepコマンドは、行番号を出力しながら一致を反転します。
|
1 |
grep -nv <pattern> <file> |
正規表現
このガイドの冒頭で、grepはglobal regular expression printの略であると言及しました。 「正規表現」 という用語は、検索パターンを記述する特別な文字列として定義されます。正規表現には独自の構造とルールがあります。
検索や置換のアクションを実行するために正規表現(略してregex)を使用する文字列検索アルゴリズムやツールは数多く存在します。人気はありますが、アプリケーションやプログラミング言語によって正規表現の実装はわずかに異なります。このセクションでは、grepを使用したいくつかの正規表現メソッドを紹介します。
リテラル一致
これまでのgrepの例では、grepは指定されたテキストファイル内の特定の文字列の検索を実行しました。実際には、grepは非常に基本的な正規表現を使用して検索していました。指定された文字列の完全一致の検索を定義する正規表現パターンは「リテラル」と呼ばれます。この名前は、文字ごとにパターンと文字通りに一致することに由来しています。
リテラル一致は、アルファベット文字と数字(およびいくつかの特殊文字)で機能します。ただし、他の表現メカニズムによっては、この動作が変更される場合があります。
|
1 |
grep "<string>" <file> |
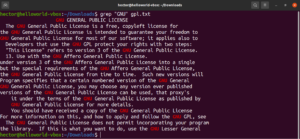
アンカー一致
アンカーは、有効な一致とするために、行内のどの位置に一致させるかを定義する特殊文字です。分かりやすくするために簡単な例を挙げます。「GNU」という文字列で始まる行のみを検索したい場合、正規表現を使用したgrepは次のようになります。ここで、「^」文字はアンカーであり、行の先頭での一致のみが有効であることを定義しています。
|
1 |
grep -n "^GNU" <file> |

同様に、「works」という文字列で終わる行のみを検索したい場合、正規表現を使用したgrepは次のようになります。ここで、「$」文字はアンカーであり、行の末尾での一致のみが有効であることを定義しています。
|
1 |
grep -n "and$" <file> |
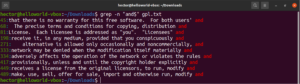
任意の文字の一致
テキスト検索を実行するとき、特定の場所に任意の文字を配置できるように定義したい場合があります。正規表現では、これはピリオド文字(.)で表されます。
この例を見てみましょう。GNU GPL 3のテキストファイルでは、「accept」と「except」という単語はどちらも「cept」という部分が共通しています。さらに、どちらの単語も「cept」部分の前に2つの文字があります。次のgrepコマンドは、「cept」部分の前に2つの文字がある任意の単語に一致します。
|
1 |
grep -n "..cept" <file> |
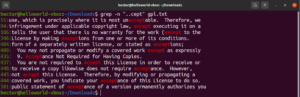
この正規表現によると、suscept、unaccept、unexpectedなどの他の単語も有効な一致となります。
ブラケット
正規表現において、ブラケット(角括弧)表現は、指定された位置にブラケット内で宣言された任意の文字を配置できることを定義します。次の正規表現文字列を見てみましょう。
|
1 |
t[wo]o |
実際に実行すると、tooとtwoという単語が有効な一致となります。
|
1 |
grep -n "t[wo]o" <file> |
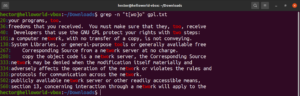
ブラケット表現は、いくつかの興味深い可能性を広げます。ブラケット表現を使用して、指定された位置に、ブラケット内で宣言された文字以外の任意の文字を配置できることを指定できます。次の正規表現文字列を見てみましょう。「ode」の前に「c」以外の任意の文字がある場合にのみ、一致が有効になります。
|
1 |
"[^c]ode" |
GPL-3ライセンステキストファイルで実行します。
|
1 |
grep -n "[^c]ode" <file> |

ファイルからの結果に加えて、他の有効な結果としてはnode、abode、anodeなどがあります。ブラケット表現は、文字の範囲を表すこともできます。次の正規表現は、行の先頭が大文字である場合に一致が有効であることを示しています。
|
1 |
"^[A-Z]" |
GPL-3ライセンステキストファイルで実行します。テキストファイル内のすべての行が対象になります。
|
1 |
grep -n "^[A-Z]" <file> |
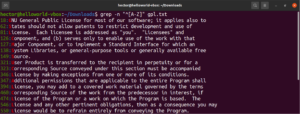
使いやすくするために、特定のラベルが指定された文字クラスがあります。前の例では、大文字を定義するために「A-Z」の範囲を使用しました。代わりに「[:upper:]」を使用することもできます。結果は同じになります。
|
1 |
grep -n "^[[:upper:]]" <file> |
パターンの繰り返し
特定の状況では、特定のパターンまたは正規表現に0回以上一致させたい場合があります。これを行うためのメタ文字はアスタリスク(*)です。次の正規表現は、アルファベットと単一のスペースのみが挟まれたすべての括弧に一致します。小文字、大文字の文字セット、およびスペースの宣言は、句読点なしで一緒に記述されていることに注意してください。
|
1 |
"([a-zA-Z ]*)" |
grepで正規表現を実行します。
|
1 |
grep -n "([A-Za-z ]*)" <file> |

メタ文字をリテラル文字として使用する
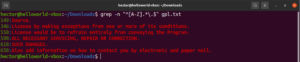
これまで、アスタリスク(*)、ピリオド(.)、アンカー(^ および $)など、さまざまなメタ文字を紹介してきました。これらはそれぞれ、正規表現のコンテキストにおいて独自の機能を表します。問題は、これらをメタ文字としてではなく、リテラル(文字通り)として使用する必要がある場合に発生します。このような状況では、メタ文字の前にバックスラッシュ(\\)を置くことで、メタ文字としてではなくリテラルとして使用することを表します。次の正規表現の例を見てみましょう。これは、大文字で始まり、ピリオドで終わるすべての行に一致します。
|
1 |
grep -n "^[A-Z].*\.$" <file> |
選択
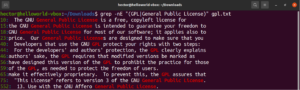
ブラケット表現(文字クラス)を使用すると、単一文字の一致に対して異なる候補を指定できます。正規表現には、単語やフレーズに対しても同様のことを行う機能があります。選択を示すには、パイプ文字(|)を使用します。オプションは括弧内に記述し、パイプ文字で互いを区切ります。一致が有効となる候補は2つ以上指定できます。次の正規表現の例を見てみましょう。これは「GPL」と「General Public License」の両方に一致します。
|
1 |
grep -nE "(GPL|General Public License)" <file> |
量指定子
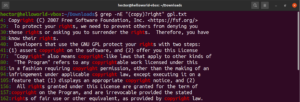
アスタリスク(*)メタ文字を使用することで、パターンが0回以上繰り返されることを定義できました。しかし、それだけではありません。量指定子については、例を用いて説明する方が簡単です。次の正規表現は、「copyright」と「right」の両方が有効な一致であることを示しています。疑問符(?)は、「copy」の部分が一致するかどうかがオプション(任意)であることを意味します。
|
1 |
grep -nE "(copy)?right" <file> |
次の量指定子はプラス記号(+)です。これはアスタリスクと同様に動作します。ただし、定義されたパターンは少なくとも1回は一致する必要があります。次の例では、正規表現は「soft」に続く1文字以上の非空白文字に一致します。
|
1 |
grep -nE "soft[^[:space:]]+" <file> |
一致の繰り返し回数の指定
一致が繰り返される回数を指定することができます。そのためには、波括弧({})を使用します。次の正規表現は、母音が最低3つ含まれる任意の単語に一致します。
|
1 |
grep -nE "[aeiouAEIOU]{3}" <file> |

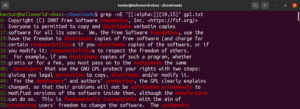
この機能では、一致する長さの下限と上限を定義することもできます。次の例では、正規表現は長さが10〜15文字の任意の単語に一致します。
|
1 |
grep -nE "[[:alpha:]]{10,15}" <file> |
まとめ
grepを使用したテキストファイルの検索は非常に便利です。正規表現を使用すると、grepでの検索がより面白く、便利になります。また、検索パターンを思い通りに微調整することもできます。
ここでは一般的な正規表現のいくつかを紹介しましたが、これはほんの始まりにすぎません。検索動作を細かく制御できる、より高度な正規表現が存在します。grep以外にも、正規表現は他のツールやプログラミング言語でも広く使用されています。
快適なコンピューティングを!
コメント
コメントはまだありません。最初のコメントを投稿しましょう。