
A CSV ファイルは、データを表形式で保存するプレーンテキストファイルです。ほとんどの場合、CSVファイルは区切り文字としてカンマ(,)を使用するため、CSV(Comma Separated Values)という名前が付けられています。CSVは、任意のテキストエディタ、スプレッドシートアプリ、その他の専用ツールで開くことができるため、データの互換性が懸念される状況で使用されます。実際、多くのプログラミング言語がCSVの組み込みサポートを提供しています。
このガイドでは、サンプルの Node.js アプリケーションでCSVを使用する方法について学びます。
Node.jsにおけるCSV
Node.jsは、オープンソースでクロスプラットフォームのJavaScriptランタイム環境です。インターネット上の無数のWebサービスを支える、最も人気のあるバックエンドの1つとなっています。NetflixやUberのような大企業でさえ、自社サービスを動かすためにNode.jsを使用しています。
Node.jsには、プロジェクトに機能を追加するためにデプロイできる多数のモジュールも用意されています。CSVに関しては、使用できる多くのモジュールがあります。例えば、node-csv, fast-csv、および papaparse などです。
ガイドのタイトルが示すように、 node-csv を使用して、Node.jsストリームでCSVファイルを読み込みます。また、解析されたデータの操作(例えば、データを SQLite データベースに転送するなど)についても実演します。
前提条件
-
このガイドで説明する手順を実行するには、次のコンポーミントが必要です。
-
適切に設定されたLinuxシステム。詳細については、CloudSigmaでのUbuntuクラウドサーバーのインストールと設定について詳しく学ぶ.
-
Access to a non-root user with sudo 権限を持つ非rootユーザーへのアクセス。詳細については、sudoersによるsudo権限の管理を参照してください.
-
適切なテキストエディタ。例えば、Brackets, VS Code, Sublime Text, Vim/NeoVim など。
-
その他のソフトウェア:
-
Node.js LTS
-
SQLite
-
ステップ 1 – 必要なソフトウェアのインストール
このガイドでは、Ubuntu 22.04 LTSを実行する軽量サーバーを作成しました(SSH経由で接続):
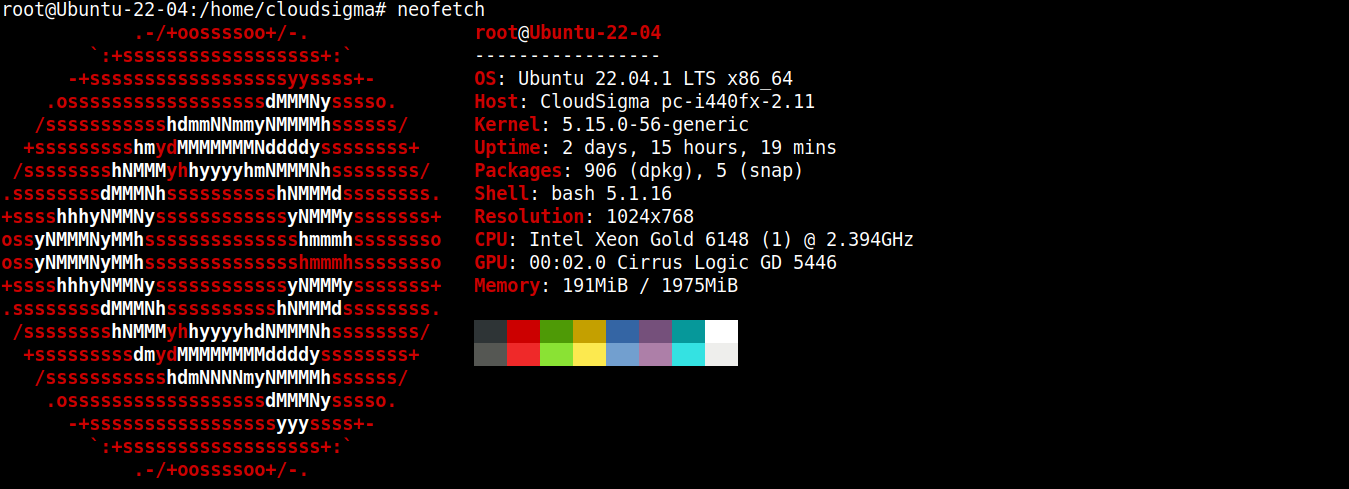
次に、そこにNode.jsとSQLiteをインストールします。
-
Node.js LTSのインストール
Node.jsは公式のUbuntuパッケージリポジトリから直接入手できます。ただし、最新バージョンではありません。そのため、最新のNode.jsパッケージを取得するためにサードパーティのリポジトリ(Nodesource)に依存することになります。
Node.js LTSのリポジトリを追加します:
|
1 |
curl -fsSL https://deb.nodesource.com/setup_lts.x | sudo -E bash - |
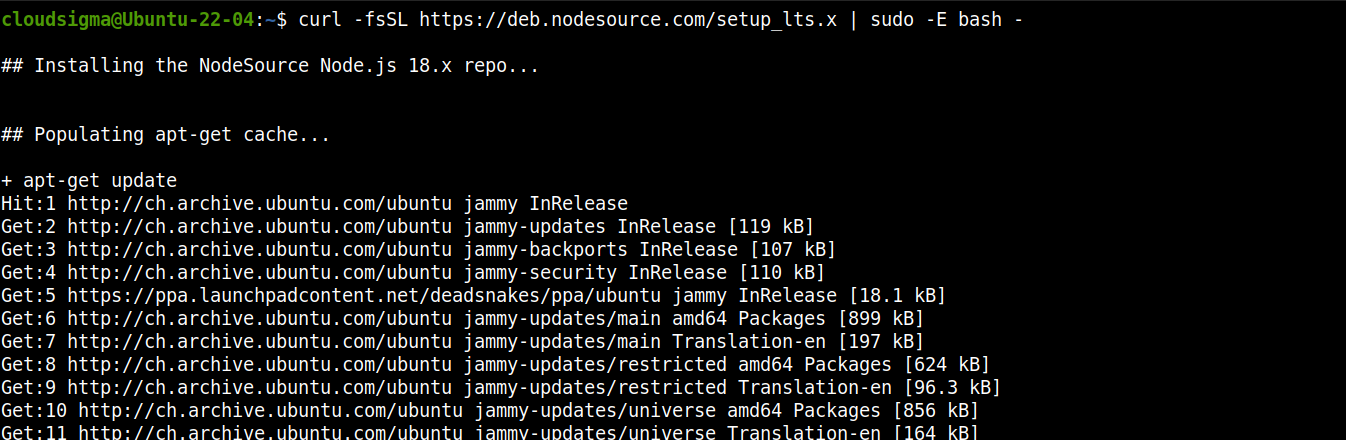
次に、Node.js LTSをインストールします:
|
1 |
sudo apt install nodejs -y |

-
SQLiteのインストール
SQLiteはUbuntuパッケージリポジトリから直接インストールします。次のコマンドを実行します:
|
1 |
sudo apt install sqlite3 -y |

ステップ 2 – プロジェクトディレクトリの設定
このセクションでは、プロジェクト専用のディレクトリを用意します。ここには、追加のモジュールとともにすべてのプロジェクトファイルが保存されます。
新しいディレクトリを作成します:
|
1 |
mkdir -pv csv_practice |
ディレクトリに移動します:
|
1 |
cd csv_practice/ |
次に、以下のコマンドを実行して、ディレクトリを npm プロジェクトとして宣言します:
|
1 |
npm init -y |
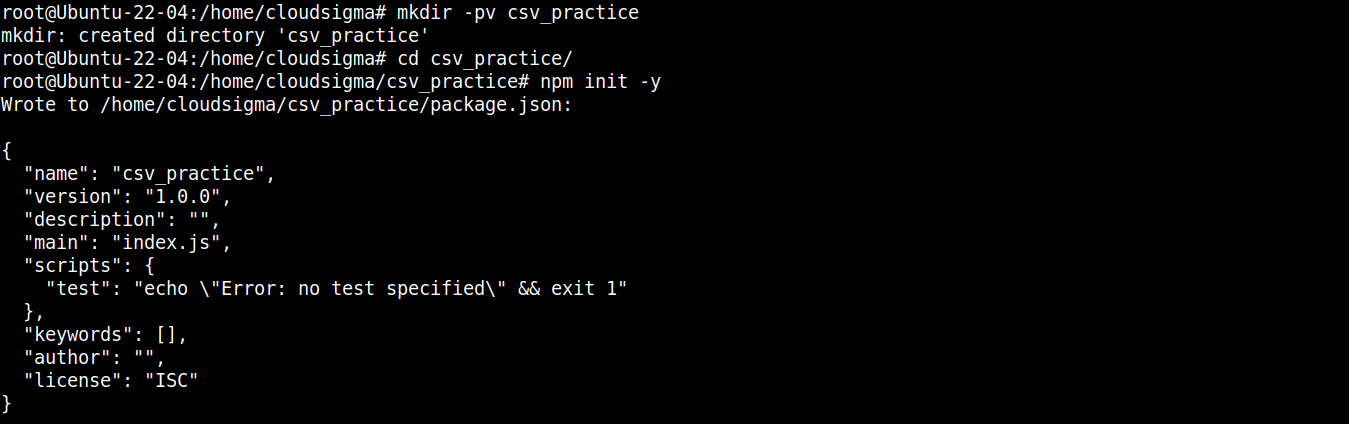
プロジェクトフォルダが初期化されたら、必要なパッケージとモジュールのインストールを開始できます。まず、 node-csv:
|
1 |
npm install csv |

node-csvモジュールは、実際には他のいくつかのモジュールのコレクションです:csv-generate, csv-parse(CSVファイルの解析)、csv-stringify(CSVへのデータ書き込み)、および stream-transform.
次に、SQLiteと通信するためのモジュールが必要です。次のコマンドで node-sqlite3 モジュールをインストールします:
|
1 |
npm install sqlite3 |

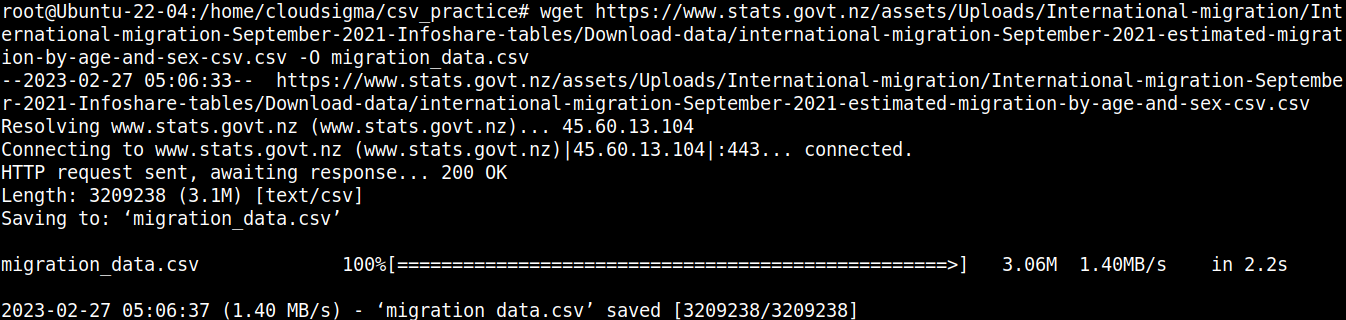
プロジェクトに必要なコンポーネントはCSVファイルです。デモンストレーションの目的で、ニュージーランドの移民CSVファイルを使用します:
|
1 |
wget https://www.stats.govt.nz/assets/Uploads/International-migration/International-migration-September-2021-Infoshare-tables/Download-data/international-migration-September-2021-estimated-migration-by-age-and-sex-csv.csv -O migration_data.csv |
ファイルの内容を簡単に見てみましょう:
|
1 |
cat migration_data.csv | less |
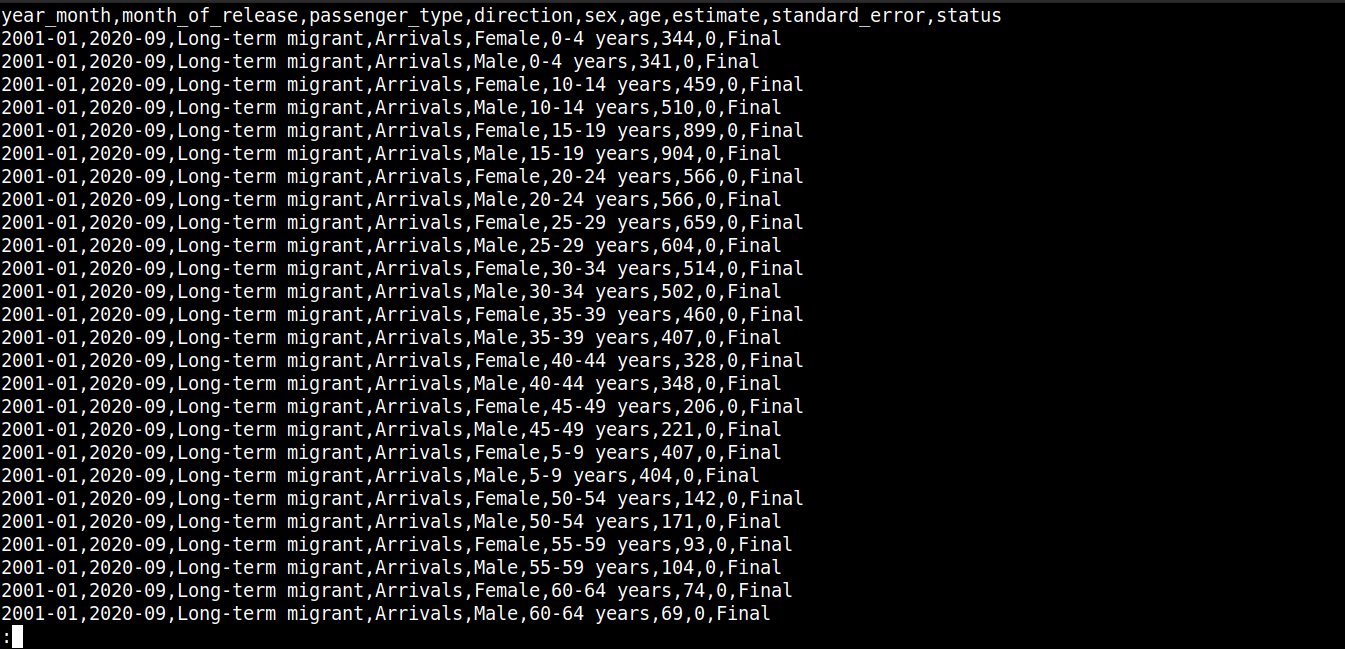
ここでは、
-
最初の行は列名を表しています。
-
続く行には、これらのフィールドの値が含まれています。
-
各行は改行(\n)で区切られています。
-
各データポイントはカンマ(,)で区切られています。
ただし、CSVの区切り文字はカンマに限定されません。その他の一般的な区切り文字には、コロン(:)、セミコロン(;)、タブ(\td)などがあります。
ステップ 3 – CSVの読み込み
このセクションでは、CSVファイルからデータを読み込んで解析するサンプルプログラムの実装方法を説明します。
新しいJavaScriptファイルを作成します:
|
1 |
touch read_csv.js |
お好みのテキストエディタでファイルを開きます:
|
1 |
nano read_csv.js |
まず、次のモジュールをインポートします: fs および csv-parse モジュール:
|
1 2 |
const fs = require("fs"); const { parse } = require("csv-parse"); |
ここでは、
-
まず、 fs 変数には、モジュールをインポートする際にNode.jsの fs オブジェクトが割り当てられます。これは require() メソッドによって返されるものです。
-
次に、 require() メソッドによって返されたオブジェクトから、分割代入構文を使用して parse 変数に抽出されます。.
次に、CSVファイルを読み込むコードを追加します:
|
1 2 3 4 5 |
fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) |
ここでは、
-
fsモジュールから createReadStream() を呼び出し、読み込みたいCSVファイルを引数として渡しています。これにより、大きなファイルが小さなチャンクに分割され、読み取り可能なストリームが作成されます。
-
ストリームを作成した後、 pipe() メソッドがストリームデータのチャンクを別のストリームに転送します。この新しいストリームは、 parse() メソッドを csv-モジュールから呼び出すことで作成されます。.
-
The csv-モジュール は、データチャンクを受け取り、それを別の形式に変換する読み書き可能な変換(Transform)ストリームを展開します。
-
The parse() メソッドはプロパティを持つオブジェクトを受け取ります。このオブジェクトは、解析されたデータをさらに処理します。ここでは、オブジェクトは次のプロパティを受け取っています:
-
delimiter:値を区切るための区切り文字。今回の対象CSVの場合はカンマ(,)です。
-
from_line:パーサーが解析を開始する行番号。値に2を指定すると、パーサーは1行目をスキップして2行目から開始します。この設定により、列名が解析データに組み込まれるのを防ぎます。
-
次に、Node.jsの on() メソッドを使用して、ストリーミングイベントをアタッチします:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) .on("end", function () { console.log("finished"); }) .on("error", function (error) { console.log(error.message); }); |
ここでは、
-
ストリーミングイベントを使用すると、特定のイベントが発生したときに、メソッドがデータのチャンクを処理(消費)できるようになります。
-
When data parsed by parse() メソッドによって解析されたデータが処理可能になると、 data イベントがトリガーされます。
-
データにアクセスするために、 on() メソッドに、パラメータ row を受け取るコールバックを渡しています。
-
row パラメータは、配列形式のデータのチャンク(解析結果)です。
-
最後に、データは console.log().
を使用してコンソールに出力されます。プログラムを完成させるために、エラーを処理し、CSVファイル内のすべてのデータが処理されたときに完了メッセージを出力する追加のストリームイベントを追加します。コードを以下のように更新してください:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) .on("end", function () { console.log("finished"); }) .on("error", function (error) { console.log(error.message); }); |
ここでは、
-
end イベントは、CSV ファイル内のすべてのデータが消費されたときに発生します。これにより、次のメソッドが呼び出されます。 console.log() メソッドが呼び出され、成功メッセージが出力されます。
-
error イベントは、CSV データの解析中にエラーが発生したときに発生します。これにより、次のメソッドが呼び出されます。 console.log() メソッドが呼び出され、エラーメッセージが出力されます。
最終的なコードは次のようになります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
const fs = require("fs"); const { parse } = require("csv-parse"); fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) .on("end", function () { console.log("finished"); }) .on("error", function (error) { console.log(error.message); }); |
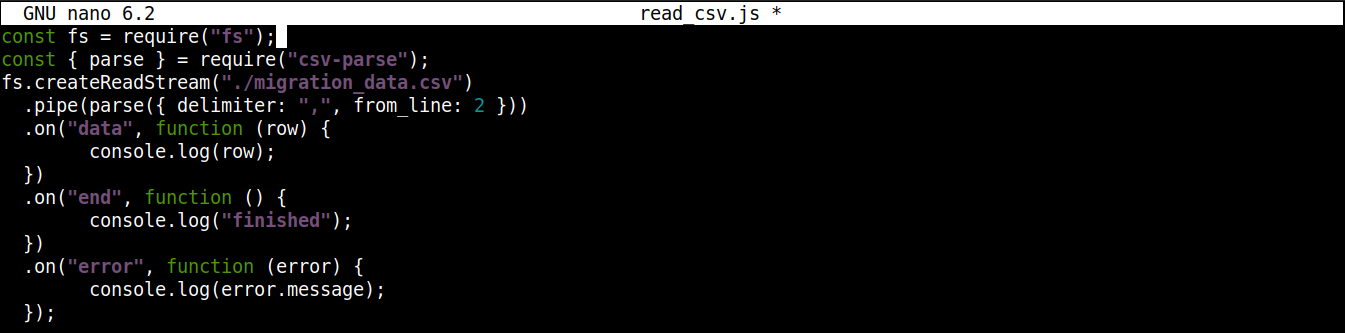
ファイルを保存してエディタを閉じます。これでプログラムを実行する準備が整いました。Node.js を使用して実行します。
|
1 |
node read_csv.js |
出力は次のようになります。

データが消費、変換され、コンソールに出力されていることに注意してください。これは継続的なプロセスであるため、出力を一度にすべて表示するのではなく、データがダウンロードされているかのように表示されます。
ステップ 4 – CSV データをデータベースに転送する
ここまでは、次のツールを使用して CSV ファイルを解析する方法を学びました。 node-csv。このセクションでは、解析されたデータをデータベース(SQLite)に転送する方法を説明します。
データベースとやり取りするための新しい JavaScript ファイルを作成します。
|
1 |
touch csv-to-sqlite3.js |
次に、テキストエディタでファイルを開きます。
|
1 |
nano csv-to-sqlite3.js |
![]()
次のコードからプログラムを開始します。
|
1 2 3 |
const fs = require("fs"); const sqlite3 = require("sqlite3").verbose(); const filepath = "./population.db"; |

ここでは、
-
1行目で、次のモジュールをインポートしています。 fs モジュール。
-
3行目で、変数 filepath には SQLite データベースのパスが含まれています。
-
現時点では、データベースはまだ存在していません。ただし、次のツールを使用する際には必要になります。 node-sqlite3.
次に、以下の行を追加して SQLite データベースへの接続を確立します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
function connectToDatabase() { if (fs.existsSync(filepath)) { return new sqlite3.Database(filepath); } else { const db = new sqlite3.Database(filepath, (error) => { if (error) { return console.error(error.message); } console.log("Connected to the database successfully"); }); return db; } } |
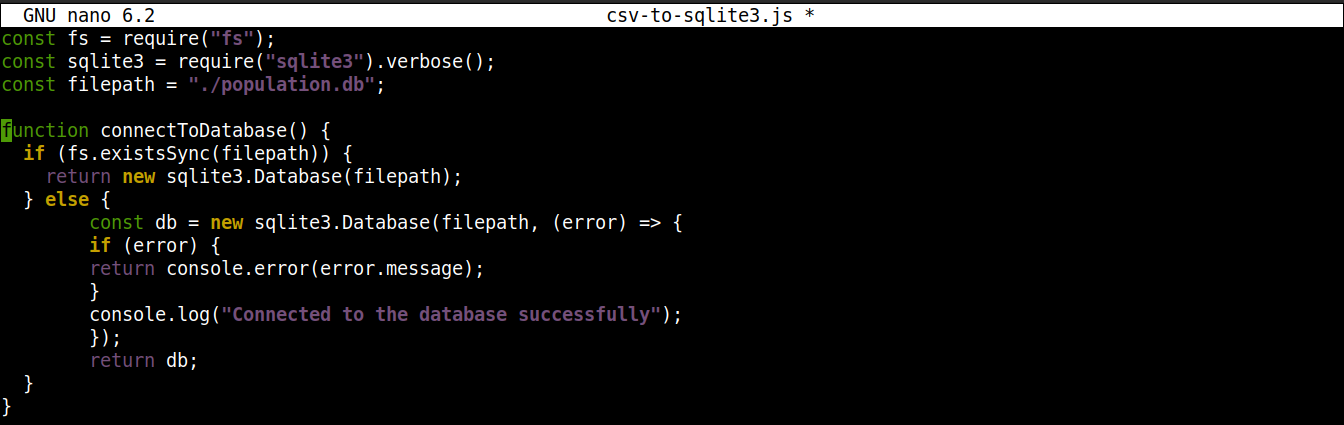
ここでは、
-
メソッド connectoToDatabase()はデータベースへの接続を確立します。
-
Within connectToDatabase()内では、 existsSync()メソッドをif文の中で呼び出しています。このif文は、指定された場所にデータベースが存在するかどうかを確認します。
-
条件の評価結果が trueの場合、 Database()クラスが、 node-sqlite3モジュールによってインスタンス化されます。接続が確立されると、関数はオブジェクトを返して終了します。
-
条件の評価結果が false(データベースが存在しない)場合、実行はelseブロックにジャンプします。そこでは、 Database()クラスが、データベースファイルへのパスとコールバックの2つの引数で初期化されます。
-
基本的には、データベースが存在しない場合は作成されます。ただし、作成プロセス中にエラーが発生した場合は、 errorオブジェクトを設定し、エラーメッセージを出力します。
次に、データベースが存在しない場合にテーブルを作成するコードを紹介します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
const fs = require("fs"); const sqlite3 = require("sqlite3").verbose(); const filepath = "./population.db"; function connectToDatabase() { if (fs.existsSync(filepath)) { return new sqlite3.Database(filepath); } else { const db = new sqlite3.Database(filepath, (error) => { if (error) { return console.error(error.message); } createTable(db); console.log("Connected to the database successfully"); }); return db; } } function createTable(db) { db.exec(` CREATE TABLE migration ( year_month VARCHAR(10), month_of_release VARCHAR(10), passenger_type VARCHAR(50), direction VARCHAR(20), sex VARCHAR(10), age VARCHAR(50), estimate INT ) `); } module.exports = connectToDatabase(); |
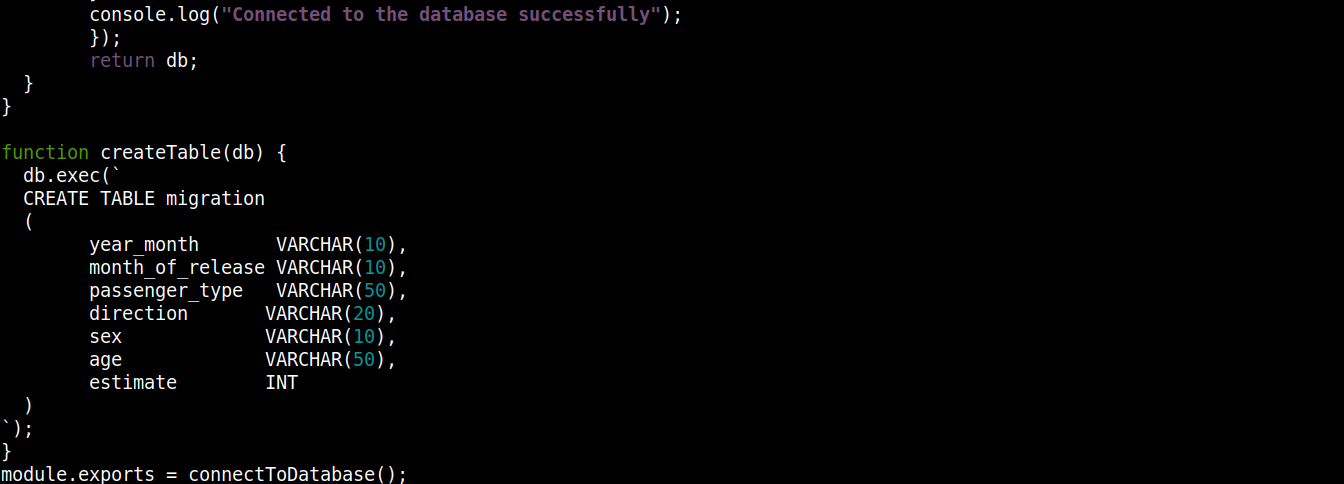
ここでは、
-
The connectToDatabase()は、 createTable()関数を呼び出し、この関数は dbに格納されているオブジェクトを引数として受け取ります。
-
の外側で、connectToDatabase()、私たちは createTable()メソッドを定義しました。このメソッドは、接続オブジェクト dbをパラメータとして受け取ります。
-
The exec()メソッド( db上)は、SQLステートメントを引数として受け取ります。このSQLステートメント内で、 migrationテーブルの作成を定義しています。このテーブルには7つのカラムがあり、各カラムは migration_data.csvファイルの列見出しに対応しています。
-
最後に、 connectToDatabaseを呼び出しています。() メソッドを使用し、返された接続オブジェクトをエクスポートして、他のファイルで使用できるようにします。
ファイルを保存してエディタを閉じます。
次に、解析されたデータをデータベースに挿入するための別のプログラムを作成します。
|
1 |
nano insert_data.js |
以下のコードを に入力します。insert_data.js:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
const fs = require("fs"); const { parse } = require("csv-parse"); const db = require("./csv-to-sqlite3"); fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { db.serialize(function () { db.run( `INSERT INTO migration VALUES (?, ?, ? , ?, ?, ?, ?)`, [row[0], row[1], row[2], row[3], row[4], row[5], row[6]], function (error) { if (error) { return console.log(error.message); } console.log(`Row inserted, ID: ${this.lastID}`); } ); }); }); |
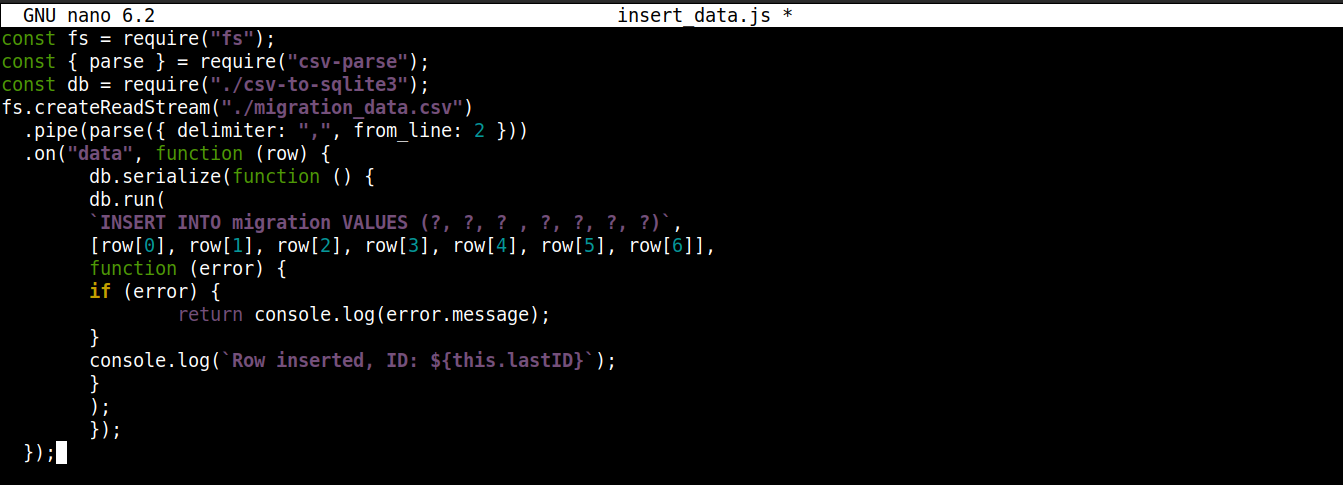
ここでは、
-
We are storing the connection object obtained from csv-to-sqlite3.js から取得した接続オブジェクトを、変数 db に格納しています。.
-
data イベントコールバック(fs モジュールストリームにアタッチされています)の内部で、接続オブジェクトの serialize() メソッドを呼び出しています。これにより、1つの SQL ステートメントの実行が完了してから次のステートメントが開始されるようになり、データベースの競合状態(システムが競合する操作を同時に実行すること)を防ぐことができます。
-
The serialize() メソッドは3つの引数を受け取ります:
-
最初の引数は SQL ステートメントです。
-
2番目の引数は配列です。
-
3番目の引数は、データがデータベースに正常に挿入されたとき、または挿入に失敗したときに実行されるコールバックです。
-
プログラムを実行する準備が整いました。Node.js を使用して insert_data.js を実行します:
|
1 |
node insert_data.js |
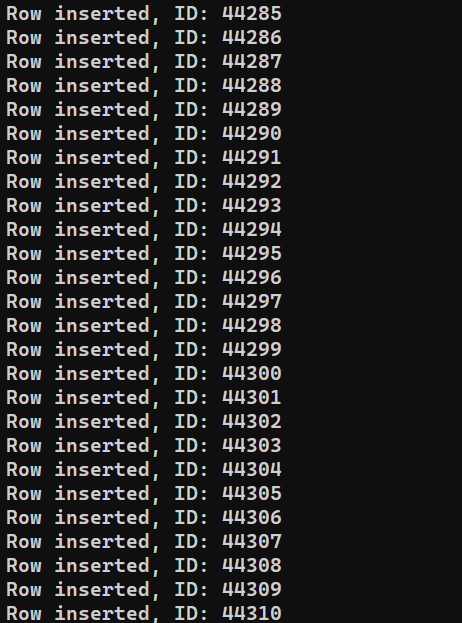
システムのパフォーマンスによっては、処理が完了するまでに時間がかかる場合があります。ただし、完了すると、出力は次のようになります。
ステップ 5 – CSV へのデータの書き込み
前回のセクションを終えると、 migration_data.csv から解析したすべてのレコードを含むデータベースが作成されています。このセクションでは、データベースからデータを読み取り、別の CSV ファイルに書き込みます。
プログラムを保存するための新しい JavaScript ファイルを作成します。
|
1 |
nano write_csv.js |
まず、次の行を追加して、 fs と csv-stringify、および csv-to-sqlite3.js からのデータベース接続オブジェクトをインポートします。:
|
1 2 3 |
const fs = require("fs"); const { stringify } = require("csv-stringify"); const db = require("./csv-to-sqlite3"); |
次に、書き込み先のCSVファイル名を含む変数と、書き込み可能なストリームを追加します:
|
1 2 3 4 5 6 7 8 9 10 11 |
const filename = "saved_from_db.csv"; const writableStream = fs.createWriteStream(filename); const columns = [ "year_month", "month_of_release", "passenger_type", "direction", "sex", "age", "estimate", ]; |
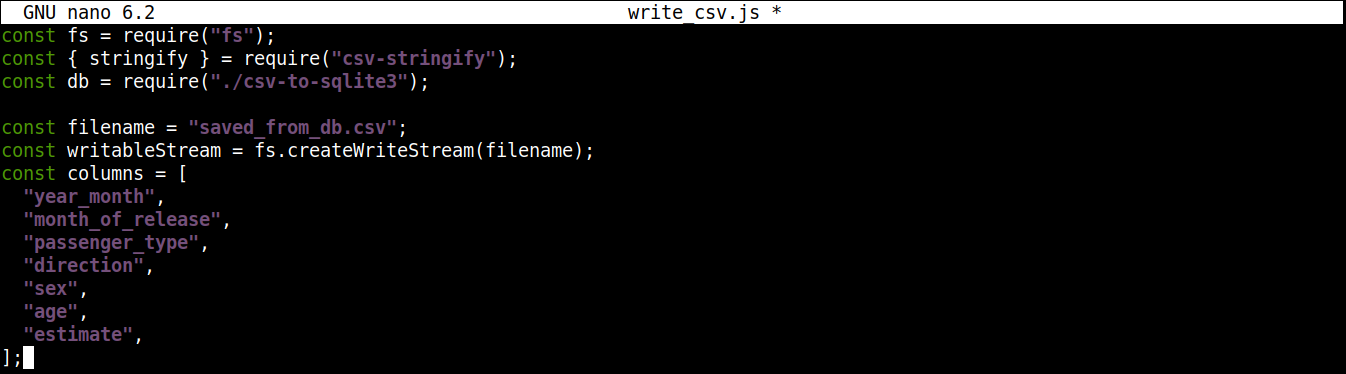
ここで、
-
The createWriteStream() メソッドは、書き込み先のファイル名を引数として受け取ります。ファイル名は saved_from_db.csv とします。.
-
The column 変数は、CSVデータのヘッダーのすべての名前を含む配列を格納します。
次に、データベースからデータを読み込み、 saved_from_db.csv に書き込むための以下のコードを追加します。:
|
1 2 3 4 5 6 7 8 9 10 11 |
const stringifier = stringify({ header: true, columns: columns }); db.each(`select * from migration`, (error, row) => { if (error) { return console.log(error.message); } stringifier.write(row); }); stringifier.pipe(writableStream); console.log("finished writing to CSV"); |
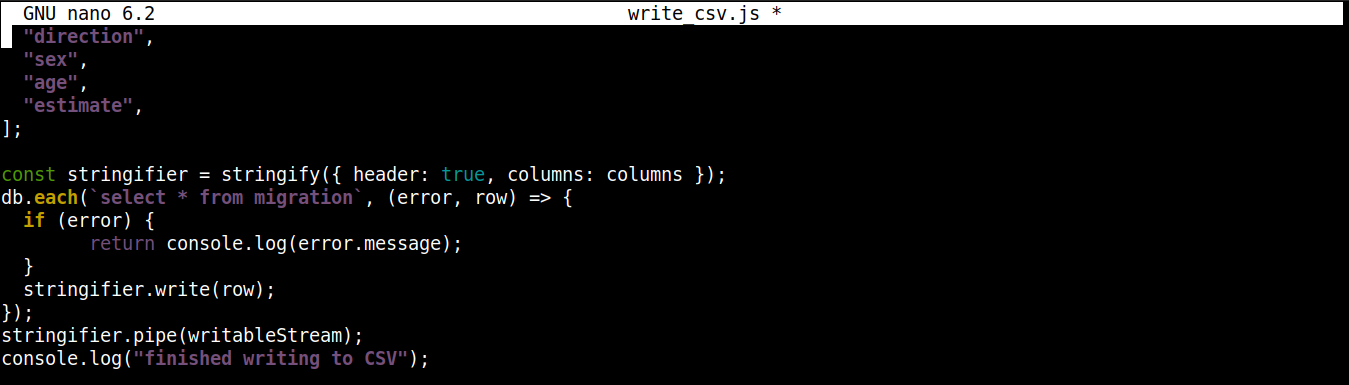
ここで、
-
ここでは、 stringify() メソッドをオブジェクトを引数として呼び出しています。これにより、オブジェクトからCSV形式にデータを変換する変換ストリーム(Transform stream)が得られます。 stringify() に渡されるオブジェクトには、次の2つのプロパティがあります。
-
header: Boolean値を受け入れます。値が true の場合、ヘッダーが生成されます。
-
columns: header が true の場合に、CSVファイルの最初の行に書き込まれる列名を含む配列を受け入れます。.
-
-
The each() メソッド( csv-to-sqlite3 接続オブジェクトのメソッド)は、SQLステートメント(データベースからのデータの読み取り)とコールバック(成功/エラーの処理)の2つの引数を指定して呼び出されます。
-
Upon each iteration of each(), の各反復において、pipe()( stringifier ストリームから)は、書き込み可能ストリーム writableStream にデータをチャンク単位で送信し始めます。その後、データの各チャンクが saved_from_db.csv に書き込まれます。.
-
すべてのデータがCSVファイルに書き込まれると、コンソール画面に成功メッセージが表示されます。
最終的なコードは次のようになります:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
const fs = require("fs"); const { stringify } = require("csv-stringify"); const db = require("./csv-to-sqlite3"); const filename = "saved_from_db.csv"; const writableStream = fs.createWriteStream(filename); const columns = [ "year_month", "month_of_release", "passenger_type", "direction", "sex", "age", "estimate", ]; const stringifier = stringify({ header: true, columns: columns }); db.each(`select * from migration`, (error, row) => { if (error) { return console.log(error.message); } stringifier.write(row); }); stringifier.pipe(writableStream); console.log("finished writing to CSV"); |
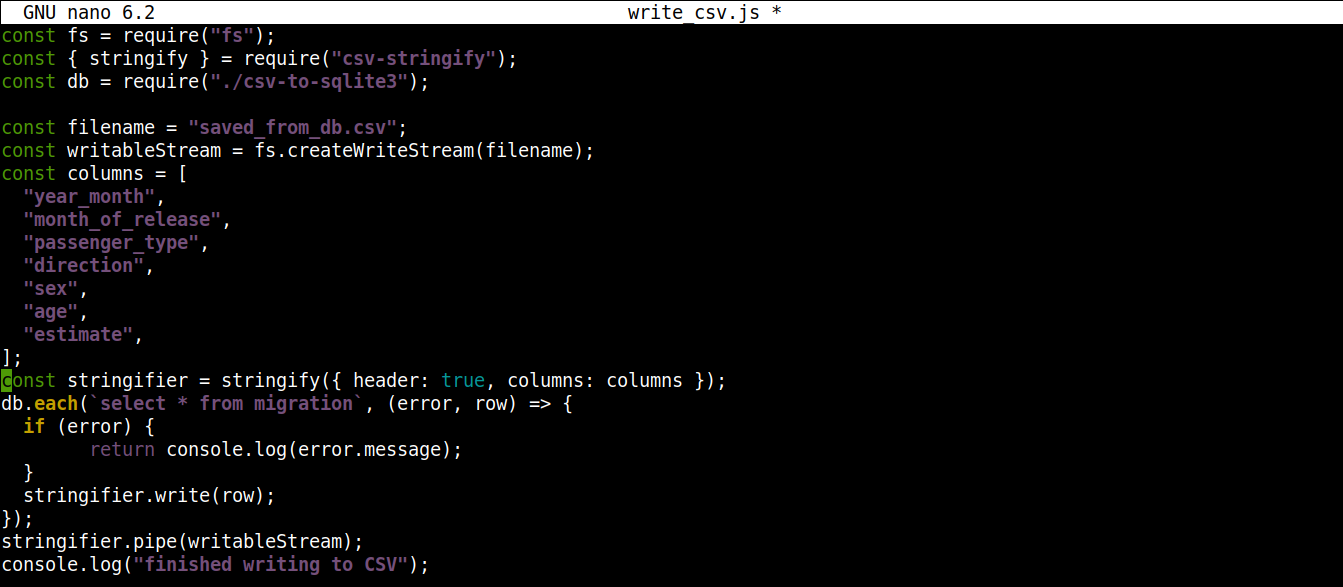
ファイルを保存してエディタを閉じます。これで、Node.jsを使用してプログラムを実行できます。
|
1 |
node write_csv.js |
データが正常にエクスポートされたか確認するには、次の内容を確認してください。 saved_from_db.csv:
|
1 |
cat saved_from_db.csv | less |
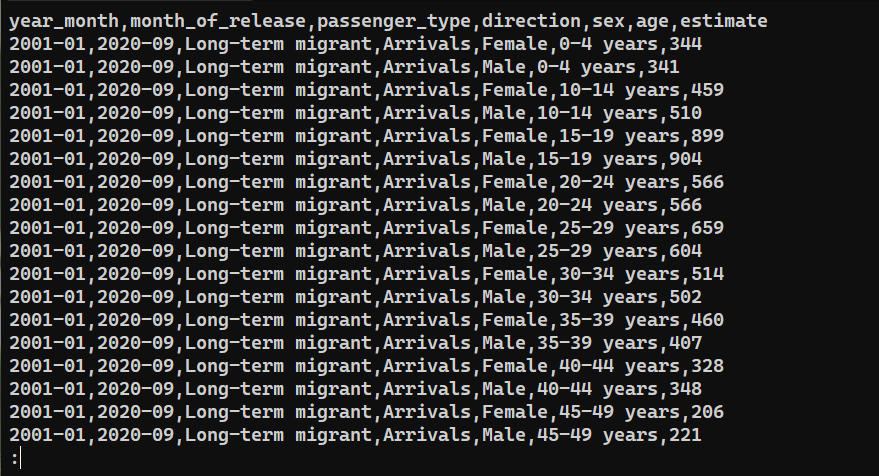
まとめ
このガイドでは、node-csvおよびnode-sqlite3モジュールを使用して、Node.jsでCSVファイルを操作する方法を説明しました。CSVからのデータの解析、SQLiteデータベースへのデータの挿入、新しいCSVファイルへのデータの書き込みなど、さまざまなタスクを実行するための複数のプログラムを作成しました。
このガイドでは、次の機能のほんの一部のみを紹介しています。 node-csv モジュール。すべての機能の詳細については、以下を参照してください。CSV Project。node-sqlite3の詳細については、以下を参照してください。GitHubの公式ドキュメント。また、言及する価値のあるもう1つのモジュールは、event-stream で、ストリームの操作を簡素化します。
Node.jsプロジェクトをさらに発展させることに興味がありますか?ぜひチェックしていただきたいNode.jsのチュートリアルをいくつかご紹介します。
ハッピーコンピューティング!
コメント
コメントはまだありません。最初のコメントを投稿しましょう。