

CloudSigmaでは、お客様が仮想マシンにGPUを追加し、最も要求の厳しいワークロードに対応できる高性能でコスト効率の高いコンピューティングを利用できるようにしています。CloudSigmaのGPUサービスの中心となるのは、HPC、AI、データ分析向けに最適化されたNVIDIA A100 Tensor Core GPUです。A100はNVIDIA TESLA V100を凌駕し、AIアプリケーションが最大限に活用できる新機能を備えています。当社では、VMインスタンスがGPUおよびその内蔵メモリを直接制御できるように、パススルーモードで簡単に最適化されたNVIDIA A100搭載VMを構築できるようにしています。
ユースケース
クラウドで実行される計算集約型アプリケーションの増加が、近年のGPUアクセラレーテッド・クラウドコンピューティングの爆発的な普及を牽引しています。これらのアプリケーションには、AIのディープラーニングのトレーニングと推論、データ分析、科学技術計算、ゲノミクス、グラフィックスレンダリング、ゲーミングなどが含まれます。AIトレーニングや科学技術計算のスケールアップから、推論アプリケーションのスケールアウト、リアルタイムの対話型AIの実現に至るまで、GPUはクラウドで実行される数多くの複雑で予測不可能なワークロードを高速化するために必要なパワーを提供します。
NVIDIA A100 Tensor Core GPUは、あらゆる規模のAI、データ分析、HPCに対して前例のない高速化を実現する、大きな飛躍を遂げた製品です。NVIDIA Ampereアーキテクチャを搭載したA100は、前世代と比較して最大20倍のパフォーマンスを提供します。CloudSigmaでは、最大規模のモデルやデータセットを実行するために、毎秒2テラバイト(TB/s)を超える世界最速の帯域幅を持つ80GBメモリバージョンを提供しています。
NVIDIA GPUは、AIのトレーニングおよび推論ワークロードを大幅に高速化することで、AIを支える主要な計算エンジンの1つとなっています。さらに、NVIDIA GPUは多くの種類のHPCやデータ分析アプリケーションおよびシステムを高速化し、データをインサイトへと変換します。
AIとHPC
GPUアクセラレーションにより、複雑な機械学習モデルをより迅速かつ効率的にトレーニングできます。データ集約型のタスクに取り組み、AI主導のイノベーションにおいて画期的な成果を達成しましょう。NVIDIA AI Enterpriseは、あらゆる組織がAIを利用できるように最適化された、エンドツーエンドのクラウドネイティブなAIおよびデータ分析ソフトウェアスイートです。パブリッククラウドへのデプロイが認定されており、AIプロジェクトを軌道に乗せるためのグローバルなエンタープライズサポートが含まれています。A100を使用することで、研究者は現実世界の成果を迅速に提供し、ソリューションを大規模に本番環境へデプロイすることができます。
ディープラーニングのトレーニング
AIモデルのトレーニングには、膨大な計算能力とスケーラビリティが必要です。Tensor Float (TF32)を搭載したNVIDIA A100 Tensor Coreは、コードを変更することなくNVIDIA Voltaと比較して最大20倍のパフォーマンスを提供し、自動混合精度とFP16を使用することでさらに2倍の高速化を実現します。
BERTのようなトレーニングワークロードは、2,048基のA100 GPUによって1分未満で大規模に解決でき、これは解決時間における世界記録です。
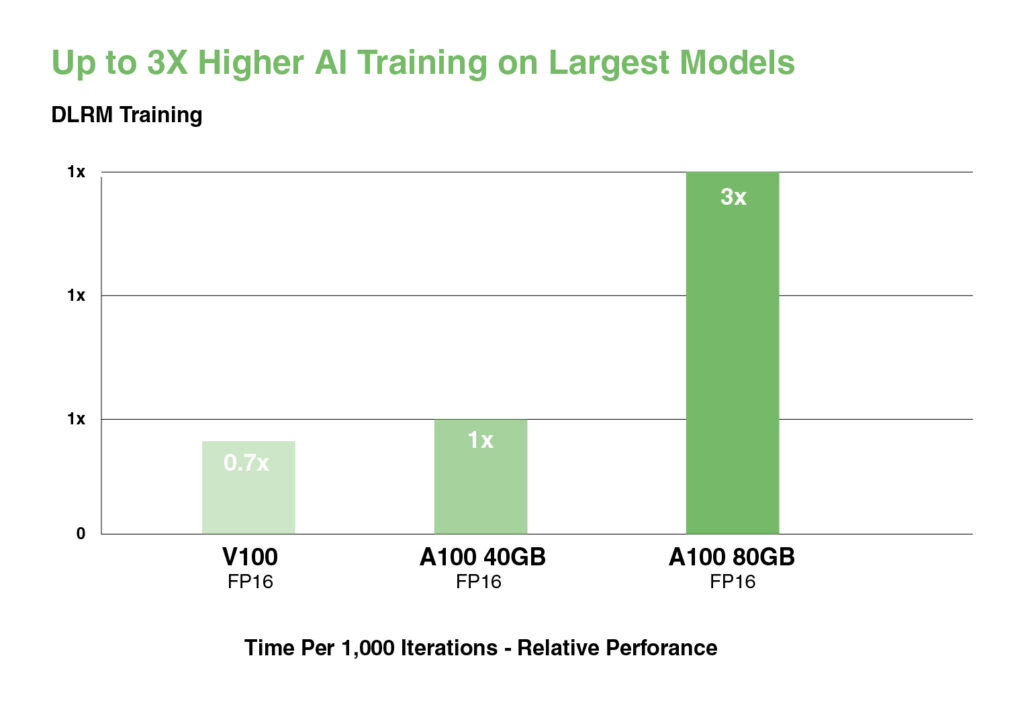
ディープラーニング推薦モデル(DLRM)のような大規模なデータテーブルを持つ最大規模のモデルにおいて、A100 80GBはノードあたり最大1.3 TBのユニファイドメモリに達し、A100 40GBと比較して最大3倍のスループット向上を実現します。
AIトレーニングの業界標準ベンチマークであるMLPerfにおいて、NVIDIAは複数のパフォーマンス記録を樹立し、リーダーシップを発揮しています。
ディープラーニングの推論
A100は、推論ワークロードを最適化するための画期的な機能を導入しています。FP32からINT4までの幅広い精度を高速化します。マルチインスタンスGPU(MIG)テクノロジーにより、単一のA100上で複数のネットワークを同時に動作させることができ、計算リソースの利用を最適化します。また、構造的スパース性のサポートにより、A100の他の推論パフォーマンス向上に加えて、最大2倍のパフォーマンスを提供します。
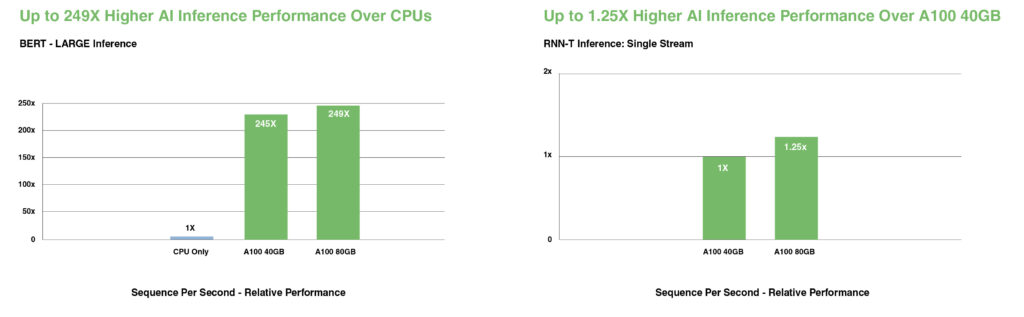
BERTのような最先端の対話型AIモデルにおいて、A100はCPUと比較して推論スループットを最大249倍高速化します。
自動音声認識用のRNN-Tなど、バッチサイズが制限される最も複雑なモデルにおいて、A100 80GBの増加したメモリ容量は各MIGのサイズを2倍にし、A100 40GBと比較して最大1.25倍高いスループットを実現します。
NVIDIAの市場をリードするパフォーマンスは、MLPerf Inferenceで実証されました。A100はさらに20倍のパフォーマンスをもたらし、そのリーダーシップをさらに拡大します。
ハイパフォーマンス コンピューティング
次世代の発見をもたらすために、科学者たちはシミュレーションを活用して、私たちの周りの世界をより深く理解しようとしています。
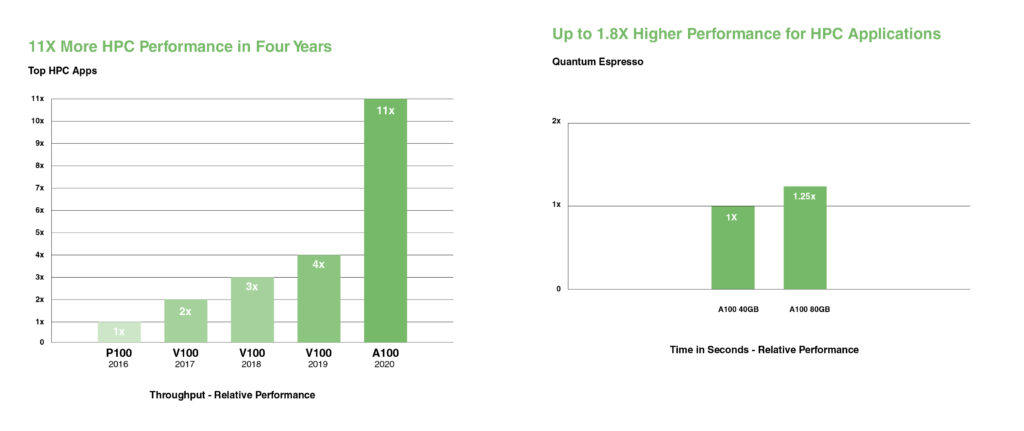
NVIDIA A100は、倍精度Tensorコアを導入し、GPUの登場以来、HPCパフォーマンスにおいて最大の飛躍をもたらします。80GBの超高速GPUメモリを搭載したA100により、研究者は10時間かかる倍精度シミュレーションを4時間未満に短縮できます。HPCアプリケーションはTF32を活用することで、単精度密行列乗算演算において最大11倍高いスループットを達成できます。
最大規模のデータセットを扱うHPCアプリケーションにおいて、A100 80GBの追加メモリは、材料シミュレーションであるQuantum Espressoで最大2倍のスループット向上を実現します。この大容量メモリと前例のないメモリ帯域幅により、A100 80GBは次世代のワークロードに最適なプラットフォームとなります。
ハイパフォーマンス データ アナリティクス
データサイエンティストは、大規模なデータセットを分析、可視化し、洞察へと変換する必要があります。しかし、スケールアウトソリューションは、複数のサーバーに分散したデータセットによって処理が滞ることがよくあります。
A100を搭載したアクセラレーテッド サーバーは、これらのワークロードに取り組むために必要なコンピューティング パワー(大容量メモリ、2 TB/秒を超えるメモリ帯域幅、NVIDIA® NVLink®およびNVSwitch™によるスケーラビリティ)を提供します。InfiniBand、NVIDIA Magnum IO™、そしてGPUアクセラレーテッド データ アナリティクス向けのRAPIDS Accelerator for Apache Sparkを含むオープンソース ライブラリ スイートであるRAPIDS™を組み合わせることで、NVIDIAデータセンター プラットフォームは、これらの巨大なワークロードを前例のないレベルのパフォーマンスと効率で高速化します。
ビッグデータ分析のベンチマークにおいて、A100 80GBはA100 40GBと比較して2倍の速度で洞察を提供し、データセットのサイズが爆発的に増加している新たなワークロードに最適です。
科学シミュレーション: 科学研究やシミュレーションを高速化し、物理学、化学、環境科学におけるより迅速な洞察と発見を可能にします。
メディア & エンターテインメント: 高解像度のグラフィックス、ビデオ、アニメーションを驚異的なスピードでレンダリングします。品質を損なうことなく、優れた視覚体験を視聴者に提供します。
金融モデリング: 膨大なデータセットを分析し、比類のないスピードで複雑な金融モデリングを実行して、情報に基づいた意思決定のための重要な洞察を提供します。
コメント
コメントはまだありません。最初のコメントを投稿しましょう。