

Naredba grep je moćan uslužni program za pretraživanje uzoraka u tekstu. Dolazi unaprijed instalirana na bilo kojoj Linux distribuciji. Ovdje je naš vodič koji prolazi kroz postavljanje LAMP stoga - Linux, Apache, MySQL i PHP.
Naziv grep označava „global regular expression print” (globalno ispisivanje regularnih izraza). Alat pretražuje navedeni uzorak u unosu. U načelu, to zvuči trivijalno. Međutim, njegova prava moć leži u tome kako definirate uzorak. Ovaj vodič detaljno objašnjava kako koristiti grep s regularnim izrazima za izvođenje složenih pretraživanja. Započnimo!
Kako koristiti Grep
Sama po sebi, naredba grep nije komplicirana. Sve što zahtijeva su uzorak i sadržaj na kojem se pretraživanje vrši. Evo kako izgleda osnovna struktura naredbe grep:
|
1 |
grep <regex> <file> |
Pretraživanje teksta
Prvo, uzmite oglednu datoteku na kojoj ćete izvršiti radnju. Preuzmite GNU General Public License v3.0 (u tekstualnom formatu). To je prilično velika tekstualna datoteka s mnogo riječi i fraza. Ako koristite Ubuntu možete je pronaći u datoteci u nastavku. Pratite naš vodič za brzu i jednostavnu instalaciju Ubuntua.
|
1 |
curl -o gpl.txt https://www.gnu.org/licenses/gpl-3.0.txt |

Zatim možete izvršiti osnovno pretraživanje teksta pomoću naredbe grep:
|
1 |
grep <pattern> <text_file> |
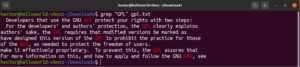
Moguće je preusmjeriti izlaz naredbe u grep:
|
1 |
cat gpl.txt | grep <pattern> |
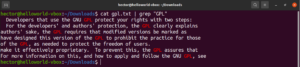
Osjetljivost na velika i mala slova
Prema zadanim postavkama, grep razlikuje velika i mala slova. U mnogim situacijama ignoriranje osjetljivosti na velika i mala slova može biti optimalno. Da biste onemogućili pretraživanje osjetljivo na velika i mala slova, upotrijebite zastavicu „-i” ili „–ignore-case”:
|
1 2 3 |
$ grep -i <pattern> <file> $ grep --ignore-case <pattern> <flag> |
Obrnuto pretraživanje
Prema zadanim postavkama, ponašanje naredbe grep je ispisivanje redaka u kojima je uzorak pronađen. Obrnuto podudaranje odnosi se na pojavu kada ne želite vidjeti retke koji odgovaraju uzorku. Da biste obrnuli podudaranje, trebate upotrijebiti zastavicu „-v” ili „–invert-match”:
|
1 2 3 |
$ grep -v <pattern> <file> $ grep --invert-match <pattern> <file> |
Broj retka
Kada pokrećete grep na vrlo velikoj datoteci, teško je pratiti lokaciju rezultata pretraživanja. Kako bi se stvari olakšale, grep ima značajku prikaza broja retka. Da biste omogućili numeriranje redaka, upotrijebite zastavicu „-n” ili „–line-number”:
|
1 2 3 |
grep -n <pattern> <file> grep --line-number <pattern> <file> |
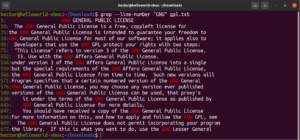
Moguće je kombinirati više argumenata naredbe grep. Sljedeća naredba grep izvršit će obrnuto podudaranje uz ispisivanje brojeva redaka:
|
1 |
grep -nv <pattern> <file> |
Regularni izraz
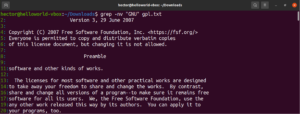
Na početku ovog vodiča spomenuli smo da grep označava „global regular expression print”. Pojam “regularni izraz” definira se kao poseban niz znakova koji opisuje uzorak pretraživanja. Regularni izraz ima vlastitu strukturu i pravila.
Postoje brojni algoritmi i alati za pretraživanje nizova znakova koji koriste regularne izraze (skraćeno regex) za izvođenje pretraživanja i zamjena. Iako je popularan, različite aplikacije i programski jezici implementiraju regex malo drugačije. U ovom odjeljku prikazat ćemo nekoliko regex metoda pomoću naredbe grep.
Doslovno podudaranje
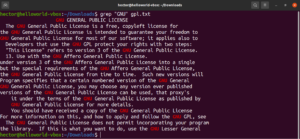
U prethodnim primjerima naredbe grep, grep je vršio pretraživanje određenog niza znakova u zadanoj tekstualnoj datoteci. Grep je zapravo pretraživao koristeći vrlo bazičan regularni izraz. Uzorci regularnih izraza koji definiraju pretraživanje točnog podudaranja zadanog niza nazivaju se „literali”. Naziv dolazi od činjenice da se podudaraju s uzorkom doslovno, znak po znak.
Doslovno podudaranje radi s abecednim i brojčanim znakovima (kao i s nekim posebnim znakovima). Međutim, ovisno o drugim mehanizmima izraza, ovo se ponašanje može promijeniti:
|
1 |
grep "<string>" <file> |
Podudaranje sidra
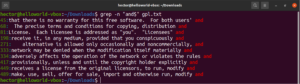
Sidra su posebni znakovi koji definiraju gdje bi se u retku trebala nalaziti pozicija podudaranja kako bi ono bilo valjano. Evo brzog primjera za pojednostavljenje. Ako želimo pronaći samo retke koji počinju nizom „GNU”, tada će grep s regularnim izrazom izgledati ovako. Ovdje je znak „^” sidro, koje definira da su podudaranja na početku retka jedina valjana:
|
1 |
grep -n "^GNU" <file> |

Slično tome, ako želimo pronaći samo retke koji završavaju nizom „works”, tada će grep s regularnim izrazom izgledati ovako. Ovdje je znak „$” sidro, koje definira da su valjana samo podudaranja na kraju retka:
|
1 |
grep -n "and$" <file> |
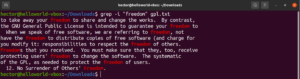
Podudaranje bilo kojeg znaka
Prilikom pretraživanja teksta, možda ćete htjeti definirati da se na određenom mjestu može nalaziti bilo koji znak. U regularnim izrazima to se izražava znakom točke (.).
Pogledajte ovaj primjer. U tekstualnoj datoteci GNU GPL 3, riječi „accept” i „except” imaju zajednički dio „cept”. Štoviše, obje riječi imaju dva znaka ispred dijela „cept”. Sljedeća naredba grep podudarat će se sa svakom riječi koja ima dva znaka ispred dijela „cept”:
|
1 |
grep -n "..cept" <file> |
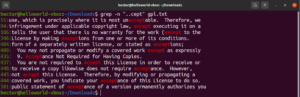
Prema ovom regularnom izrazu, druge riječi poput suscept, unaccept, unexpected itd. također su valjana podudaranja.
Uglate zagrade
U regularnim izrazima, izrazi u uglatim zagradama definiraju da se na navedenom mjestu može nalaziti bilo koji znak deklariran unutar zagrade. Pogledajte sljedeći niz regularnog izraza:
|
1 |
t[wo]o |
Kada se to primijeni u praksi, riječi too i two bit će valjana podudaranja:
|
1 |
grep -n "t[wo]o" <file> |
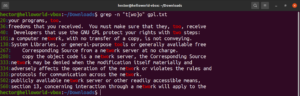
Izraz u uglatim zagradama otvara mogućnosti za neke zanimljive stvari. Moguće je koristiti izraze u uglatim zagradama kako bi se reklo da se na navedenom mjestu može nalaziti bilo koji znak osim onih deklariranih unutar zagrade. Pogledajte sljedeći niz regularnog izraza. Podudaranje će biti valjano samo ako se ispred „ode” nalazi bilo koji znak osim „c”:
|
1 |
"[^c]ode" |
Pokrenite to na tekstualnoj datoteci licence GPL-3:
|
1 |
grep -n "[^c]ode" <file> |

Osim rezultata iz datoteke, drugi valjani rezultati bili bi node, abode, anode itd. Izrazi u uglatim zagradama također mogu opisivati raspon znakova. Sljedeći regularni izraz govori da je podudaranje valjano ako je početak retka veliko slovo:
|
1 |
"^[A-Z]" |
Pokrenite to na tekstualnoj datoteci licence GPL-3. To će biti svi redci u tekstualnoj datoteci:
|
1 |
grep -n "^[A-Z]" <file> |
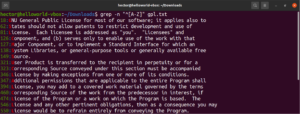
Radi lakšeg korištenja, postoje određene klase znakova koje imaju specificirane oznake. U prethodnom primjeru koristili smo raspon „A-Z” za definiranje velikih slova. Umjesto toga, možemo koristiti i „[:upper:]”. Rezultat će biti isti:
|
1 |
grep -n "^[[:upper:]]" <file> |
Ponavljanje uzorka
U određenim situacijama možda ćete htjeti podudarati određeni uzorak ili regularni izraz nula ili više puta. Da biste to učinili, metaznak je zvjezdica (*). Sljedeći regularni izraz podudarat će se sa svim zagradama koje sadrže samo slova i pojedinačne razmake između njih. Imajte na umu da su deklaracije skupova malih i velikih slova te razmaka zajedno bez ikakvih znakova interpunkcije:
|
1 |
"([a-zA-Z ]*)" |
Primijenite regularni izraz u praksi pomoću naredbe grep:
|
1 |
grep -n "([A-Za-z ]*)" <file> |

Korištenje metaznakova kao doslovnih znakova
Do sada smo se upoznali s raznim meta-znakovima kao što su zvjezdica (*), točka (.), sidra (^ i $), itd. Svaki od njih označava jedinstvenu funkciju u kontekstu regularnih izraza (regex). Problem se javlja kada ih je potrebno koristiti kao doslovne znakove (literale), a ne kao meta-znakove. U takvim situacijama, kosa crta unatrag (\) ispred meta-znaka označavat će da se on koristi u doslovnom smislu, a ne kao meta-znak. Pogledajte ovaj primjer regularnog izraza. Podudarat će se sa svim redcima koji počinju velikim slovom i završavaju točkom:
|
1 |
grep -n "^[A-Z].*\.$" <file> |
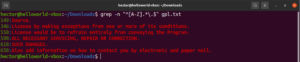
Alternacija
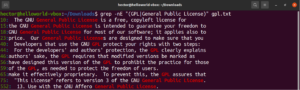
Pomoću izraza u zagradama možemo odrediti različite moguće izbore za podudaranje jednog znaka. Regex ima značajku da učini isto s riječima i frazama. Za označavanje alternacije koristi se znak okomite crte (|). Opcije ostaju unutar zagrada dok ih znak okomite crte odvaja jednu od druge. Mogu postojati dvije ili više mogućih opcija da bi podudaranje bilo valjano. Pogledajte sljedeći primjer regularnog izraza. Podudarat će se i s „GPL” i s „General Public License”:
|
1 |
grep -nE "(GPL|General Public License)" <file> |
Kvantifikatori
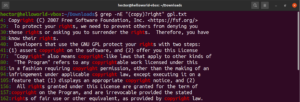
Koristeći meta-znak zvjezdice (*), mogli smo definirati uzorak koji se ponavlja nula ili više puta. Međutim, ima još toga s čime se može raditi. Kvantifikatore je lakše objasniti na primjeru. Sljedeći regularni izraz opisuje da su i „copyright” i „right” valjana podudaranja. Upitnik (?) označava da je dio „copy” neobavezan za podudaranje:
|
1 |
grep -nE "(copy)?right" <file> |
Sljedeći kvantifikator je simbol plus (+). Ponaša se slično kao i zvjezdica. Međutim, definirani uzorak mora se podudarati barem jednom. U sljedećem primjeru, regularni izraz će podudarati „soft” s jednim ili više znakova koji nisu praznine:
|
1 |
grep -nE "soft[^[:space:]]+" <file> |
Određivanje ponavljanja podudaranja
Moguće je odrediti broj ponavljanja podudaranja. Da biste to učinili, koristite vitičaste zagrade ({}). Sljedeći regularni izraz podudarat će se sa svakom riječi koja sadrži najmanje tri samoglasnika:
|
1 |
grep -nE "[aeiouAEIOU]{3}" <file> |

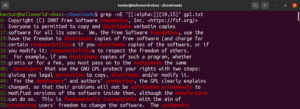
Ova značajka također vam omogućuje da definirate donju i gornju granicu duljine podudaranja. U sljedećem primjeru, regex će se podudarati sa svakom riječi koja je dugačka 10-15 znakova:
|
1 |
grep -nE "[[:alpha:]]{10,15}" <file> |
Zaključak
Pretraživanje tekstualnih datoteka pomoću naredbe grep prilično je praktično. Regularni izrazi čine pretraživanje s grep zanimljivijim i korisnijim. Oni također fino podešavaju uzorak pretraživanja prema vašim željama.
Iako smo prikazali neke od uobičajenih regularnih izraza, to je tek početak. Postoje napredniji regularni izrazi koji nude najprecizniju kontrolu nad ponašanjem pretraživanja. Osim naredbe grep, regularni izrazi također se široko koriste u drugim alatima i programskim jezicima.
Ugodan rad na računalu!
Komentari
Još nema komentara. Budite prvi.