

Web scraping, web crawling, web harvesting ili ekstrakcija web podataka sinonimi su koji se odnose na čin rudarenja podataka s web stranica diljem interneta. Web scraperi ili web crawleri alati su koji programski prolaze kroz web stranice izdvajajući potrebne podatke. Ti podaci, koji su obično veliki skupovi teksta, mogu se koristiti u analitičke svrhe, za razumijevanje proizvoda ili za zadovoljenje nečije znatiželje o određenoj web stranici.
Ako se pitate kako možete započeti s web crawlingom, pokazat ćemo vam osnove web scraping-a kroz jednostavan skup podataka. Trebali biste moći pratiti ovaj vodič bez obzira na vašu razinu programerskog znanja. Za praktični primjer koristit ćemo naš CloudSigma blog. Pokušat ćemo dobiti informacije o vodičima na našoj stranici bloga. Do trenutka kada budete čitali zaključak ovog vodiča, imat ćete funkcionalan web scraper napravljen pomoću Python 3 koji pretražuje nekoliko stranica u našem odjeljku bloga, a zatim prikazuje podatke na vašem zaslonu.
Koristeći znanje stečeno izradom ovog osnovnog web scrapera, možete ga proširiti i izraditi vlastite web scrapere. Ovo bi trebalo biti zabavno, počnimo!
Preduvjeti
Ovo je praktični vodič, pa biste trebali imati lokalno razvojno okruženje za Python 3 kako biste ga mogli uspješno pratiti. Najprije se možete referirati na naš vodič o tome kako instalirati Python 3 i postaviti lokalno programsko okruženje na Ubuntuu.
Scrapy
Web scraping uključuje dva koraka: prvi korak je pronalaženje i preuzimanje web stranica, a drugi korak je pretraživanje i ekstrakcija informacija s tih web stranica.
Postoji niz načina i biblioteka koje se mogu koristiti za izradu web scrapera od nule u mnogim programskim jezicima. Međutim, to može donijeti probleme u budućnosti kada vaš web scraper postane složen ili kada trebate istovremeno pretraživati više stranica s različitim postavkama i uzorcima. Može biti prilično težak zadatak shvatiti kako transformirati vaše prikupljene podatke između različitih formata kao što su CSV, XML ili JSON.
Iako bi neki mogli cijeniti izazov izrade vlastitog web scrapera od nule, bolje je da ne izmišljate ponovno kotač, već da ga izgradite na temelju postojeće biblioteke koja rješava sve te probleme. Koristit ćemo Scrapy, Python biblioteku, zajedno s Python 3 za implementaciju web scrapera u ovom vodiču. Scrapy je alat otvorenog koda i jedna od najpopularnijih i najmoćnijih Python biblioteka za web scraping. Scrapy je napravljen za rukovanje nekim od uobičajenih funkcionalnosti koje bi svi scraperi trebali imati. Na taj način ne morate ponovno izmišljati kotač svaki put kada želite implementirati web crawler. Uz Scrapy, proces izrade scrapera postaje jednostavan i zabavan.
Scrapy je dostupan na PyPi, općenito poznatom kao pip – Python Package Index. PyPi je repozitorij u vlasništvu zajednice koji hosta većinu Python paketa. Kada instalirate i postavite Python 3 u svom lokalnom razvojnom okruženju, instalira se i pip, koji možete koristiti za instalaciju Python paketa.
Korak 1: Kako izraditi jednostavan web scraper
Prvo, za instalaciju Scrapyja, pokrenite sljedeću naredbu:
|
1 |
pip install scrapy |
Po želji, možete pratiti službene upute za instalaciju Scrapyja s dokumentacijske stranice. Ako ste uspješno instalirali Scrapy, stvorite mapu za projekt koristeći naziv po vašem izboru:
|
1 |
mkdir cloudsigma-crawler |
Idite u mapu i stvorite glavnu datoteku za kod. Ova datoteka će sadržavati sav kod za ovaj vodič:
|
1 |
touch main.py |
Ako želite, datoteku možete stvoriti pomoću svog uređivača teksta ili IDE-a umjesto gornje naredbe.
Zatim otvorite datoteku i počnimo stvaranjem osnovnog scrapera koji koristi Scrapy. Stvorit ćemo Python klasu koja proširuje scrapy.Spider, osnovnu spider klasu iz Scrapyja. Ova klasa će imati dva obavezna atributa kako je definirano u nastavku:
- name — tekstualni naziv (string) za identifikaciju spidera (možete unijeti naziv po izboru).
- start_urls — niz koji sadrži popis URL-ova s kojih se počinje pretraživanje. Počet ćemo s jednim URL-om.
Dodajte sljedeći isječak koda u otvorenu datoteku kako biste kreirali osnovnog spidera:
|
1 2 3 4 5 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] |
U nastavku je objašnjenje svakog retka koda:
Prvi redak uvozi Scrapy, što nam omogućuje korištenje različitih klasa koje taj paket pruža.
U sljedećem retku proširujemo klasu Spider koju pruža Scrapy i kreiramo podklasu pod nazivom CloudSigmaCrawler. Proširivanjem klase (Spider) dobivamo pristup svojstvima klase koja sada možemo koristiti u našem kodu. U ovom slučaju, klasa Spider ima metode i ponašanja koja definiraju kako pratiti URL-ove i izdvojiti podatke s web stranica. Međutim, ona ne zna koje URL-ove treba pratiti niti koje podatke treba izdvojiti. Proširivanjem te klase možemo pružiti potrebne informacije metodama. Kako biste saznali više o stvaranju podklasa i proširivanju, pročitajte principe objektno orijentiranog programiranja.
U našem CloudSigmaCrawleru definiramo potrebne atribute. Prvo, našem spideru dajemo ime cloudsigma_crawler. Zatim navodimo jedan URL od kojeg se kreće: https://blog.cloudsigma.com/blog/. Otvaranje ovog URL-a odvest će vas na 1. stranicu bloga CloudSigma koja sadrži neke od brojnih vodiča.
Vrijeme je za testiranje scrapera. Imate nekoliko opcija. Ako koristite IDE, na primjer, PyCharm community edition od JetBrains, vjerojatno dolazi s gumbom koji možete jednostavno kliknuti za pokretanje skripte. Druga opcija je praćenje uobičajenog načina pokretanja Python datoteka iz naredbenog retka: python putanja/do/datoteke.py ili py putanja/do/datoteke.py. Još jedna opcija je Scrapyjevo naredbeno sučelje. Scrapy dolazi s vlastitim sučeljem naredbenog retka koje pomaže pri pokretanju scrapera. Unesite sljedeću naredbu za pokretanje scrapera:
|
1 |
scrapy runspider main.py |
Ovisno o verziji biblioteke Scrapy koju ste instalirali, trebali biste vidjeti izlaz koji izgleda otprilike ovako:
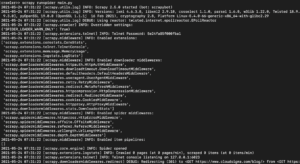
Kao što vidite, izlaz je prilično dugačak pa smo izdvojili samo neke dijelove. Evo što se dogodilo kada ste izvršili naredbu:
- Scraper je inicijaliziran. Stoga je učitao dodatne komponente i proširenja koja treba koristiti za praćenje i čitanje podataka s URL-ova.
- Koristeći URL naveden u popisu start_urls, preuzeo je HTML sa stranice. To je sličan proces onome koji preglednik slijedi prilikom otvaranja web stranica.
- Nakon preuzimanja HTML-a, on se prosljeđuje metodi parse koju još nismo definirali. Za sada ona ne radi ništa, pa spider jednostavno izlazi bez ikakve obrade. Definirat ćemo ponašanje metode parse u sljedećem koraku.
Korak 2: Kako izdvojiti podatke sa stranice
U 1. koraku implementirali smo samo osnovni scraper koji preuzima HTML stranicu, ali nakon toga ne radi ništa. U ovom odjeljku pružit ćemo upute za izdvajanje podataka. Na stranici CloudSigma Blog s koje želimo izdvojiti podatke, možete primijetiti nekoliko stvari kao što su:
- Zaglavlje, prisutno na svim stranicama.
- Navigacijski izbornik i okvir za filtriranje pretraživanja.
- Stvarni popis vodiča u obliku mreže.
Pregledavanje izvornog koda HTML stranice koju namjeravate scrapati daje vam opću predodžbu o strukturi stranice. To vam pomaže u pisanju scrapera. Izvorni kod možete vidjeti desnim klikom na stranicu i odabirom Prikaži izvorni kod ili pritiskom na Ctrl + U. Evo isječka izvornog koda:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
<body> <div id="x-iso-container" class="x-iso-container x-iso-container-posts cols-3"> <article id="post-51691" class="post-51691 post type-post status-publish format-standard has-post-thumbnail hentry category-blog-posts category-tutorials tag-apache tag-certbot tag-cloud-guide tag-cloud-tutorial tag-https tag-lets-encrypt tag-ssl tag-ssl-certification tag-tutorial tag-ubuntu"> <div class="entry-wrap"> <header class="entry-header"> <h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Trajna poveznica na: "Osiguravanje Apachea s Let’s Encrypt na Ubuntu 18.04"">Osiguravanje Apachea s Let’s Encrypt na Ubuntu 18.04</a> </h2> </header> <div class="entry-content excerpt"> <p>Sigurnost web stranica i podataka teme su koje se ne smiju shvaćati olako. Vrlo osjetljive informacije koje uključuju financijske zapise i privatne podatke korisnika uvijek su u prijenosu između korisnikova računala i vaše web stranice. Kada uzmete u obzir ovu činjenicu, nije teško uvidjeti zašto bi neosigurane web stranice mogle dovesti do povrede koja bi mogla ozbiljno naštetiti vašem poslovanju. Postoji nekoliko … </p> <div><a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="more-link">Pročitajte više</a></div> </div> </div> ... </article> </div> </body> |
Kao što možete vidjeti, svaki je vodič na blogu zatvoren unutar HTML oznake pod nazivom <article>. Struganje (scraping) stranice uključivat će dva koraka. Prvi korak bit će dohvaćanje svakog vodiča na blogu traženjem dijelova stranice koji sadrže podatke koje želimo. Sljedeći korak je izvlačenje željenih podataka iz svakog vodiča identificiranog HTML oznakom.
Scrapy identificira podatke koje treba dohvatiti na temelju selektora koje navedete. Možemo koristiti selektore za pronalaženje jednog ili više elemenata na stranici i dobivanje podataka unutar tih elemenata. Scrapy ima podršku za XPath i CSS selektore.
Iz izvornog koda koji smo ranije pregledali, CSS selektori čine se jednostavnijima. Stoga ćemo odabrati tu opciju jer će nam pomoći pronaći sve vodiče na stranici. Iz HTML izvornog koda, svaki je vodič naveden unutar CSS klase pod nazivom post. Nazivi CSS klasa obično se identificiraju s .class_name (točka class_name). Stoga ćemo koristiti .post za naš CSS selektor. Unutar izvornog koda našeg scrapera main.py, proslijedit ćemo klasu .post objektu response, tako da će vaša datoteka sada izgledati ovako:
|
1 2 3 4 5 6 7 8 9 10 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): pass |
Ovaj isječak koda dohvatit će sve vodiče na stranici s navedenim start_urls i proći kroz njih kako bi izdvojio podatke. U sljedećem koraku htjet ćete izdvojiti i prikazati te podatke. Ako ponovno pregledate izvorni kod CloudSigma bloga opet, vidjet ćete da je naslov svakog vodiča pohranjen unutar oznake <a> koja se nalazi unutar oznake <h2>, na primjer:
|
1 2 3 4 5 |
<h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Permalink to: "Securing Apache with Let’s Encrypt on Ubuntu 18.04"">Securing Apache with Let’s Encrypt on Ubuntu 18.04</a> </h2> |
Svaki objekt vodiča kroz koji prolazimo sadrži CSS metodu kojoj možemo proslijediti selektor za lociranje i izdvajanje podređenih elemenata. Za ovaj primjer želimo izdvojiti naslov koji je zatvoren unutar oznake <a>. Ova se oznaka nalazi unutar oznake <h2> unutar klase .entry-header unutar klase .entry-wrap. Možemo proslijediti ove CSS selektore metodi objekta kako bismo izdvojili naslov, modificirajte kod da izgleda ovako:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), } |
Zarez na kraju nakon extract_first() nije tipfeler jer ćemo dodati još koda ispod tog odjeljka.
Neke od stavki koje treba uočiti u gornjem izvornom kodu uključuju:
- ::text dodan na kraj selektora – ovo je CSS pseudoselektor koji upućuje kod da dohvati tekst unutar oznake, a ne samu oznaku.
- poziv metode extract_first() unutar objekta – upućuje kod da odabere samo prvi element koji odgovara selektoru. Stoga dobivamo niz znakova umjesto popisa elemenata.
Zatim spremite datoteku i pokrenite kod unosom sljedeće naredbe u svoj terminal:
|
1 |
scrapy runspider main.py |
U izlazu biste trebali vidjeti naslove vodiča:
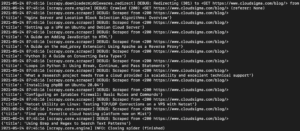
Ovo možemo nastaviti proširivati dodavanjem više selektora kako bismo dobili druge pojedinosti o vodiču, kao što su URL vodiča, istaknuta slika i opis.
Proučimo ponovno HTML kod za pojedinačni vodič:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
<body> <div id="x-iso-container" class="x-iso-container x-iso-container-posts cols-3"> <article id="post-51691" class="post-51691 post type-post status-publish format-standard has-post-thumbnail hentry category-blog-posts category-tutorials tag-apache tag-certbot tag-cloud-guide tag-cloud-tutorial tag-https tag-lets-encrypt tag-ssl tag-ssl-certification tag-tutorial tag-ubuntu"> <div class="entry-featured"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="entry-thumb" title="Trajna poveznica na: "Osiguravanje Apachea uz Let’s Encrypt na Ubuntu 18.04""> <img width="1000" height="522" src="data:image/svg+xml,%3Csvg%20xmlns='http://www.w3.org/2000/svg'%20viewBox='0%200%201000%20522'%3E%3C/svg%3E" class="attachment-entry-fullwidth size-entry-fullwidth wp-post-image" alt="Let’s Encrypt" loading="lazy" data-lazy-srcset="/media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04.jpg 1000w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-300x157.jpg 300w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-768x401.jpg 768w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-610x318.jpg 610w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-100x52.jpg 100w" data-lazy-sizes="(max-width: 1000px) 100vw, 1000px" data-lazy-src="/media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04.jpg"/> </a> </div> <div class="entry-wrap"> <header class="entry-header"> <h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Permalink to: "Securing Apache with Let’s Encrypt on Ubuntu 18.04"">Osiguravanje Apachea s Let’s Encrypt na Ubuntu 18.04</a> </h2> </header> <div class="entry-content excerpt"> <p>Sigurnost web stranica i podataka teme su koje se ne smiju shvaćati olako. Vrlo osjetljive informacije koje uključuju financijske zapise i privatne podatke korisnika uvijek su u prijenosu između korisnikova računala i vaše web stranice. Kada uzmete u obzir tu činjenicu, nije teško uvidjeti zašto bi neosigurane web stranice mogle dovesti do povrede sigurnosti koja bi mogla ozbiljno naštetiti vašem poslovanju. Postoji … </p> <div><a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="more-link">Pročitajte više</a></div> </div> </div> </article> </div> </body> |
Želimo pokušati izdvojiti istaknute dijelove, tj. URL vodiča, istaknutu sliku i opis.
- Iz gornjeg isječka koda, slika za blog pohranjena je unutar atributa data-lazy-src oznake img unutar oznake <a> unutar oznake div na početku vodiča za blog. Možemo upotrijebiti CSS selektor za dohvaćanje vrijednosti kao što smo to učinili s naslovima vodiča.
- Dobivanje URL-a vodiča je jednostavno, jer imamo oznaku <a> unutar elementa <div>.
- Opis je zatvoren unutar oznake <p> koja se nalazi unutar oznake <div>.
Koristit ćemo CSS klase kako bismo dobili ono što želimo. Izmijenimo kod tako da izgleda ovako:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), 'caption': tutorial.css(CAPTION_SELECTOR).extract_first(), } |
Spremite promjene i pokrenite kod sa sljedećom naredbom:
|
1 |
scrapy runspider main.py |
U izlazu ćete vidjeti više podataka, poput URL-a, slike i opisa koje smo dodali:

To je sve za indeksiranje jedne stranice. Zatim, pogledajmo kako možemo stvoriti scraper koji prati poveznice.
Korak 3: Kako indeksirati više stranica
Do ove točke stvorili smo scraper koji može dohvatiti podatke s jedne stranice. Međutim, želimo više od toga. Želite spidera koji može pratiti poveznice i programski izdvajati podatke s više stranica web-mjesta.
Ako odete na dno stranice bloga CloudSigma, primijetit ćete poveznice za paginaciju i malu strelicu usmjerenu udesno koja označava sljedeću stranicu. Evo isječka HTML koda:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<div class="x-pagination"> <ul class="center-list center-text"> <li><span class="pages">Stranica 1 od 45</span></li> <li></li> <li><span class="current">1</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/2/" class="single_page" title="2">2</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="single_page" title="3">3</a></li> <li><span class="expand">...</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/45/" class="last" title="Zadnja stranica">45</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/2/" class="prev-next hidden-phone">→</a></li> </ul> </div> |
Isječak prikazuje nekoliko poveznica za navigaciju stranicama unutar oznaka <li>, ispod oznake <div> s CSS klasom .x-pagination. Naš fokus je na poveznici koja vodi na sljedeću stranicu. Nalazi se u oznaci <a> posljednjeg <li> u oznaci <ul>.
Poveznica koja vodi na sljedeću stranicu ima klasu .prev-next unutar oznake <a> kao što se vidi u gornjem isječku. Međutim, ako prijeđete na sljedeću stranicu, također ćete primijetiti da poveznice na prethodnu i sljedeću stranicu imaju ovu CSS klasu. Razmotrite ovaj isječak za Stranicu 2:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<div class="x-pagination"> <ul class="center-list center-text"> <li><span class="pages">Stranica 2 od 45</span></li> <li><a href="https://blog.cloudsigma.com/blog/" class="prev-next hidden-phone">←</a></li> <li><a href="https://blog.cloudsigma.com/blog/" class="single_page" title="1">1</a></li> <li><span class="current">2</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="single_page" title="3">3</a></li> <li><span class="expand">...</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/45/" class="last" title="Zadnja stranica">45</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="prev-next hidden-phone">→</a></li> </ul> </div> |
Ako koristimo Scrapy metodu extract_first(), ona će raditi na prvoj stranici. Kada dođe do sljedeće stranice, odabrat će prvu poveznicu s klasom .prev-next, koja u gornjem isječku upućuje na prvu stranicu. To će rezultirati petljom. Stoga ćemo koristiti Scrapy metodu extract(). Ova metoda izdvaja sve elemente koji odgovaraju slučaju upotrebe i stavlja ih u niz. Iz tog niza možemo odabrati posljednji element koji će sadržavati stvarnu poveznicu koja vodi na sljedeću stranicu. Izmijenite svoj kod da izgleda ovako:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), } NEXT_PAGE_SELECTOR = '.x-pagination > ul.center-list > li > a.prev-next::attr("href")' next_page = response.css(NEXT_PAGE_SELECTOR).extract() if next_page: yield scrapy.Request( response.urljoin(next_page[-1]), callback=self.parse ) |
Prođimo kroz kod za odabir next_page.
Najprije definiramo selektor za poveznice na sljedeću i prethodnu stranicu. Zatim koristimo metodu extract() za izdvajanje URL-ova i njihovo stavljanje u niz. Varijabla next_page bit će niz s dva elementa poput:
|
1 |
next_page = [prev_page_url, next_page_url] |
Budući da navigiramo na sljedeću stranicu, odabrat ćemo posljednji element u nizu. Next_page[-1] odabire posljednji element u nizu.
Blok if provjerava ima li varijabla next_page neku vrijednost, a zatim poziva metodu scrapy.Request(). U našem kodu upućujemo ovu metodu da pretraži stranicu s priloženim URL-om i proslijedi je natrag metodi parse() kako bismo je mogli parsirati za izdvajanje podataka i ponoviti postupak za sljedeću stranicu. Ovaj se postupak ponavlja sve dok ne prestane pronalaziti poveznicu na sljedeću stranicu, odnosno ako blok ne uspije, tada se zaustavlja.
Spremite svoj kod i pokrenite ga. Primijetit ćete da se iteracija nastavlja vrtjeti kroz stranice kako pronalazi više stranica za struganje. Ovako biste definirali scraper koji prati poveznice na web stranici. Naš je primjer prilično jednostavan. Samo idemo na stranicu, pronalazimo poveznicu na sljedeću stranicu i ponavljamo postupak. U drugim slučajevima upotrebe možda ćete htjeti pratiti oznake ili poveznice koje upućuju na vanjske izvore i više. Evo dovršenog izvornog koda za osnovni web scraper u jeziku Python 3:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), 'caption': tutorial.css(CAPTION_SELECTOR).extract_first(), } NEXT_PAGE_SELECTOR = '.x-pagination > ul.center-list > li > a.prev-next::attr("href")' next_page = response.css(NEXT_PAGE_SELECTOR).extract() if next_page: yield scrapy.Request( response.urljoin(next_page[-1]), callback=self.parse ) |
Zaključak
U ovom vodiču izradili smo osnovni web scraper koji može pretraživati CloudSigma blog direktorij i prikazati neke informacije o vodičima na blogu u samo oko 27 redaka koda.
Naravno, to je moguće jer smo ga izgradili na temelju Scrapy Python knjižnice. Ovo je samo temelj koji bi vam trebao pomoći u izgradnji složenijih scrapera koji prate više oznaka, rezultate pretraživanja web stranica i još mnogo toga. Možete pogledati službenu dokumentaciju Scrapyja za više informacija o radu sa Scrapyjem.
Sretno računanje!
Komentari
Još nema komentara. Budite prvi.