

El grep comando es una potente utilidad para buscar patrones en texto. Viene preinstalado en cualquier Linux distro. Aquí está nuestro tutorial que explica cómo configurar el LAMP Stack -Linux, Apache, MySQL y PHP.
El nombre grep significa global regular expression print. La herramienta busca el patrón especificado en la entrada. En principio, suena trivial. Sin embargo, su verdadero poder radica en cómo se define el patrón. Esta guía detalla cómo usar grep con expresiones regulares para realizar búsquedas complejas. ¡Comencemos!
Cómo usar Grep
El comando grep, por sí solo, no es complicado. Todo lo que requiere es el patrón y el contenido sobre el cual realizar la búsqueda. Así es como se ve la estructura básica del comando grep:
|
1 |
grep <regex> <file> |
Buscar texto
Primero, obtén un archivo de muestra para realizar la acción. Descarga la GNU General Public License v3.0 (en formato de texto). Es un archivo de texto bastante grande con muchas palabras y frases. Si estás usando Ubuntu puedes encontrarlo en el archivo de abajo. Sigue nuestro tutorial para una instalación rápida y fácil de Ubuntu.
|
1 |
curl -o gpl.txt https://www.gnu.org/licenses/gpl-3.0.txt |

A continuación, puedes realizar una búsqueda de texto básica usando grep:
|
1 |
grep <pattern> <text_file> |
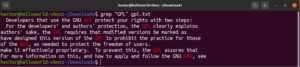
Es posible canalizar la salida de un comando a grep:
|
1 |
cat gpl.txt | grep <pattern> |
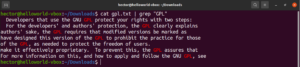
Sensibilidad a mayúsculas y minúsculas
Por defecto, grep se comporta distinguiendo entre mayúsculas y minúsculas. En muchas situaciones, ignorar esta distinción puede ser óptimo. Para desactivar la búsqueda sensible a mayúsculas y minúsculas, usa la opción “-i” o “–ignore-case”:
|
1 2 3 |
$ grep -i <pattern> <file> $ grep --ignore-case <pattern> <flag> |
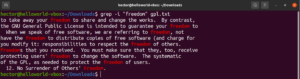
Invertir coincidencia
Por defecto, el comportamiento de grep es imprimir las líneas donde se encontró el patrón. Invertir coincidencia se refiere al fenómeno en el que no deseas ver las líneas que coinciden con el patrón. Para invertir la coincidencia, debes usar la opción “-v” o “–invert-match”:
|
1 2 3 |
$ grep -v <pattern> <file> $ grep --invert-match <pattern> <file> |
Número de línea
Al ejecutar grep en un archivo muy grande, es difícil realizar un seguimiento de la ubicación del resultado de la búsqueda. Para facilitar las cosas, grep tiene la función de mostrar el número de línea. Para habilitar la numeración de líneas, usa la opción “-n” o “–line-number”:
|
1 2 3 |
grep -n <pattern> <file> grep --line-number <pattern> <file> |
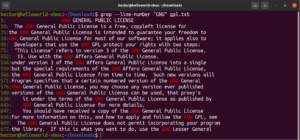
Es posible combinar múltiples argumentos de grep. El siguiente comando grep realizará una coincidencia invertida mientras imprime los números de línea:
|
1 |
grep -nv <pattern> <file> |
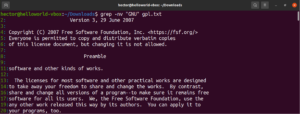
Expresión regular
Al inicio de esta guía, mencionamos que grep significa global regular expression print. El término “expresión regular” se define como una cadena especial que describe el patrón de búsqueda. La expresión regular tiene su propia estructura y reglas.
Existen numerosos algoritmos y herramientas de búsqueda de cadenas que utilizan expresiones regulares (regex para abreviar) para realizar búsquedas y acciones de reemplazo. Aunque es popular, diferentes aplicaciones y lenguajes de programación implementan regex de manera ligeramente diferente. En esta sección, mostraremos un puñado de métodos de regex usando grep.
Coincidencia literal
En los ejemplos anteriores de grep, grep realizó la búsqueda de una cadena específica en el archivo de texto dado. En realidad, grep estaba buscando utilizando la expresión regular más básica. Los patrones de regex que definen la búsqueda de la coincidencia exacta de una cadena dada se denominan “literales”. El nombre proviene del hecho de que coinciden con el patrón literalmente, carácter por carácter.
La coincidencia literal funciona con caracteres alfabéticos y numéricos (así como con algunos caracteres especiales). Sin embargo, dependiendo de otros mecanismos de expresión, este comportamiento puede cambiar:
|
1 |
grep "<string>" <file> |
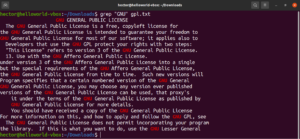
Coincidencia de anclaje
Las anclas son caracteres especiales que definen dónde debe estar la posición de la coincidencia en la línea para que sea una coincidencia válida. Aquí hay un ejemplo rápido para simplificarlo. Si buscamos encontrar solo las líneas que comienzan con la cadena “GNU”, entonces el grep con regex se verá así. Aquí, el carácter “^” es el ancla, que define que las coincidencias al principio de la línea son las únicas válidas:
|
1 |
grep -n "^GNU" <file> |

De manera similar, si buscamos encontrar solo las líneas que terminan con la cadena “works”, entonces el grep con regex se verá así. Aquí, el carácter “$” es el ancla, que define que solo las coincidencias al final de la línea son válidas:
|
1 |
grep -n "and$" <file> |
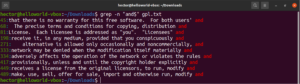
Coincidencia con cualquier carácter
Al realizar una búsqueda de texto, es posible que desee definir que en un lugar específico puede haber cualquier carácter. En regex, esto se expresa mediante el carácter de punto (.).
Eche un vistazo a este ejemplo. En el archivo de texto GNU GPL 3, las palabras “accept” y “except” tienen en común la parte “cept”. Además, ambas palabras tienen dos caracteres antes de la parte “cept”. El siguiente comando grep coincidirá con cualquier palabra que tenga dos caracteres antes de la parte “cept”:
|
1 |
grep -n "..cept" <file> |
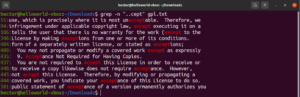
Según esta regex, otras palabras como suscept, unaccept, unexpected, etc. también son coincidencias válidas.
Corchetes
En regex, las expresiones entre corchetes definen que en la ubicación especificada puede haber cualquier carácter declarado dentro del corchete. Eche un vistazo a la siguiente cadena de expresión regular:
|
1 |
t[wo]o |
Al ponerlo en acción, las palabras too y two serán las coincidencias válidas:
|
1 |
grep -n "t[wo]o" <file> |
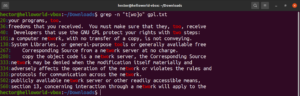
La expresión entre corchetes abre la posibilidad a cosas interesantes. Es posible utilizar expresiones entre corchetes para indicar que en la ubicación especificada puede haber cualquier carácter que no sea uno de los declarados dentro del corchete. Eche un vistazo a la siguiente cadena de regex. La coincidencia solo será válida si hay algún carácter que no sea “c” antes de “ode”:
|
1 |
"[^c]ode" |
Ejecútelo en el archivo de texto de la licencia GPL-3:
|
1 |
grep -n "[^c]ode" <file> |

Además del resultado del archivo, otros resultados válidos serían node, abode, anode, etc. Las expresiones entre corchetes también pueden describir un rango de caracteres. La siguiente regex indica que la coincidencia es válida si el inicio de la línea es un carácter en mayúscula:
|
1 |
"^[A-Z]" |
Ejecútelo en el archivo de texto de la licencia GPL-3. Mostrará todas las líneas del archivo de texto:
|
1 |
grep -n "^[A-Z]" <file> |
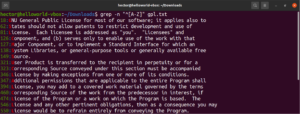
Para facilitar su uso, existen ciertas clases de caracteres que tienen etiquetas especificadas. En el ejemplo anterior, utilizamos el rango “A-Z” para definir los caracteres en mayúscula. En su lugar, también podemos usar “[:upper:]”. El resultado será el mismo:
|
1 |
grep -n "^[[:upper:]]" <file> |
Repetición de un patrón
En ciertas situaciones, es posible que desee hacer coincidir un patrón específico o regex cero o más veces. Para hacerlo, el metacarácter es el asterisco (*). La siguiente expresión regular coincidirá con todos los paréntesis que contengan únicamente letras y espacios simples entre ellas. Tenga en cuenta que la declaración de los conjuntos de caracteres en minúsculas, mayúsculas y espacios están juntos sin ningún signo de puntuación:
|
1 |
"([a-zA-Z ]*)" |
Ponga la regex en acción con grep:
|
1 |
grep -n "([A-Za-z ]*)" <file> |

Uso de metacaracteres como caracteres literales
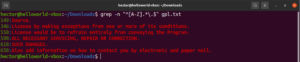
Hasta ahora, se nos han presentado varios metacaracteres como el asterisco (*), el punto (.), las anclas (^ y $), etc. Cada uno de ellos denota una función única en el contexto de las expresiones regulares. El problema surge cuando necesitan ser utilizados como literales, no como metacaracteres. En tales situaciones, una barra invertida (\) delante del metacarácter denotará que se debe utilizar en sentido literal, no como un metacarácter. Echa un vistazo a este ejemplo de expresión regular. Coincidirá con todas las líneas que comiencen con un carácter en mayúscula y terminen con un punto:
|
1 |
grep -n "^[A-Z].*\.$" <file> |
Alternancia
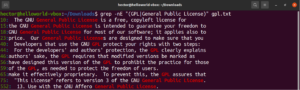
Usando expresiones entre corchetes, podemos especificar diferentes opciones posibles para la coincidencia de un solo carácter. Las expresiones regulares tienen la capacidad de hacer lo mismo con palabras y frases. Para indicar una alternancia, se utiliza el carácter de barra vertical (|). Las opciones permanecen entre paréntesis mientras que el carácter de barra vertical las separa entre sí. Puede haber dos o más opciones posibles para que la coincidencia sea válida. Echa un vistazo al siguiente ejemplo de expresión regular. Coincidirá tanto con “GPL” como con “General Public License”:
|
1 |
grep -nE "(GPL|General Public License)" <file> |
Cuantificadores
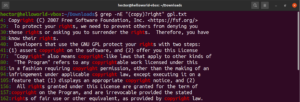
Usando el metacarácter asterisco (*), pudimos definir un patrón repetidamente cero o más veces. Sin embargo, hay más con lo que trabajar. Es más fácil explicar los cuantificadores con un ejemplo. La siguiente expresión regular describe que tanto “copyright” como “right” son coincidencias válidas. El signo de interrogación (?) indica que la parte “copy” es opcional para la coincidencia:
|
1 |
grep -nE "(copy)?right" <file> |
El siguiente cuantificador es el símbolo de suma (+). Se comporta de manera similar al asterisco. Sin embargo, el patrón definido debe coincidir al menos una vez. En el siguiente ejemplo, la expresión regular coincidirá con “soft” seguido de uno o más caracteres que no sean espacios en blanco:
|
1 |
grep -nE "soft[^[:space:]]+" <file> |
Especificar la repetición de coincidencia
Es posible especificar el número de veces que se repite una coincidencia. Para hacerlo, utiliza las llaves ({}). La siguiente expresión regular coincidirá con cualquier palabra que contenga un mínimo de tres vocales:
|
1 |
grep -nE "[aeiouAEIOU]{3}" <file> |

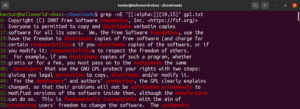
Esta característica también te permite definir el límite inferior y el límite superior de la longitud de la coincidencia. En el siguiente ejemplo, la expresión regular coincidirá con cualquier palabra que tenga entre 10 y 15 caracteres de longitud:
|
1 |
grep -nE "[[:alpha:]]{10,15}" <file> |
Conclusión
Buscar en archivos de texto con grep es bastante práctico. Las expresiones regulares hacen que buscar con grep sea más interesante y útil. También ajustan con precisión el patrón de búsqueda a tu gusto.
Aunque hemos demostrado algunas de las expresiones regulares más comunes, esto es solo el comienzo. Existen expresiones regulares más avanzadas que ofrecen un control más preciso sobre el comportamiento de la búsqueda. Además de grep, las expresiones regulares también son ampliamente utilizadas por otras herramientas y lenguajes de programación.
¡Feliz computación!
Comentarios
Aún no hay comentarios. Sea el primero.