
Un CSV es un archivo de texto plano que almacena datos en formato tabular. En la mayoría de los casos, los archivos CSV utilizan comas (,) como delimitador, de ahí el nombre CSV (valores separados por comas). Se utiliza en situaciones donde la compatibilidad de los datos es una preocupación, ya que los CSV se pueden abrir con cualquier editor de texto, aplicaciones de hojas de cálculo y otras herramientas especializadas. De hecho, muchos lenguajes de programación ofrecen soporte integrado para CSV.
En esta guía, aprenderemos sobre el uso de CSV en una aplicación de Node.js de muestra.
CSV en Node.js
Node.js es un entorno de ejecución de JavaScript de código abierto y multiplataforma. Se ha convertido en uno de los backends más populares que impulsan numerosos servicios web en todo el internet. Incluso grandes empresas como Netflix y Uber utilizan Node.js para impulsar sus servicios.
Node.js también tiene numerosos módulos disponibles para ser implementados para agregar funcionalidad adicional a un proyecto. Cuando se trata de CSV, hay muchos módulos disponibles para usar, por ejemplo, node-csv, fast-csv, y papaparse etc.
Como sugiere el título de la guía, vamos a utilizar node-csv para leer archivos CSV utilizando flujos (streams) de Node.js. También demostraremos cómo trabajar con los datos analizados, por ejemplo, transfiriendo los datos a una base de datos SQLite .
Requisitos previos
-
Para realizar los pasos demostrados en esta guía, necesitará los siguientes componentes:
-
Un sistema Linux configurado correctamente. Obtenga más información sobre la instalación y configuración de un servidor en la nube Ubuntu en CloudSigma.
-
Acceso a un usuario no raíz con privilegios de sudo . Consulte la gestión de permisos de sudo con sudoers.
-
Un editor de texto adecuado, por ejemplo, Brackets, VS Code, Sublime Text, Vim/NeoVim, etc.
-
Otro software:
-
Node.js LTS
-
SQLite
-
Paso 1 – Instalación del software necesario
Para esta guía, he creado un servidor ligero que ejecuta Ubuntu 22.04 LTS (conectado a través de SSH):
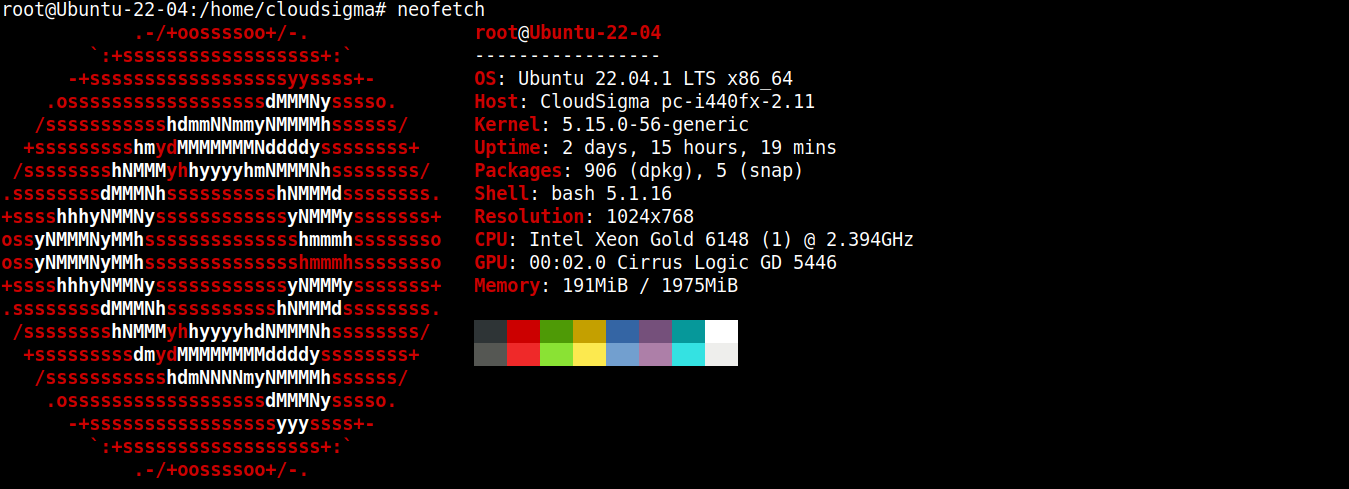
Ahora, instalaremos Node.js y SQLite en él.
-
Instalación de Node.js LTS
Node.js está disponible directamente desde los repositorios oficiales de paquetes de Ubuntu. Sin embargo, no es la versión más actualizada. Es por eso que vamos a confiar en un repositorio de terceros (Nodesource) para obtener los últimos paquetes de Node.js.
Agregue el repositorio para Node.js LTS:
|
1 |
curl -fsSL https://deb.nodesource.com/setup_lts.x | sudo -E bash - |
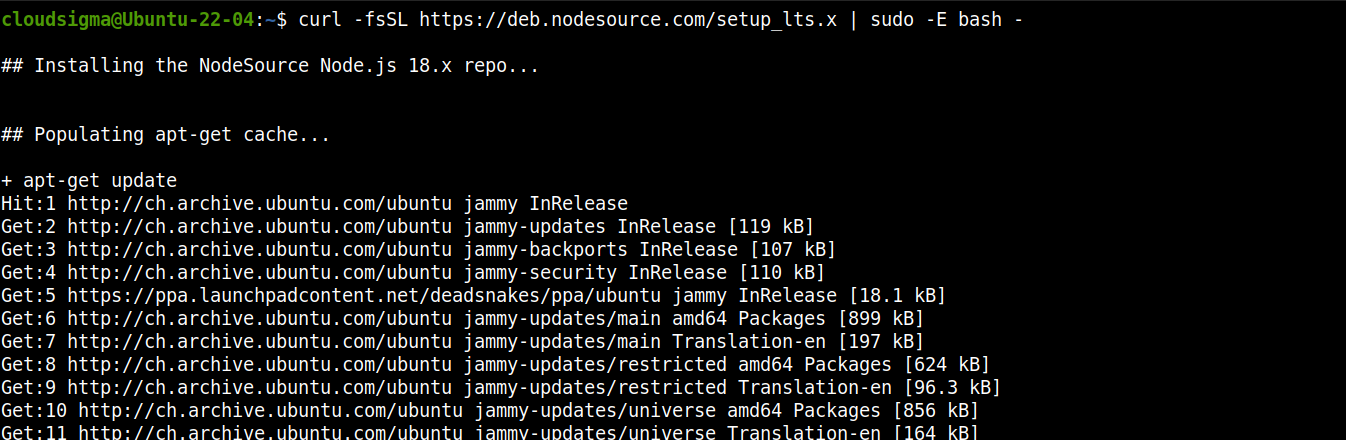
Ahora, instale Node.js LTS:
|
1 |
sudo apt install nodejs -y |

-
Instalar SQLite
Instalaremos SQLite directamente desde los repositorios de paquetes de Ubuntu. Ejecute los siguientes comandos:
|
1 |
sudo apt install sqlite3 -y |

Paso 2 – Configuración del directorio del proyecto
En esta sección, prepararemos un directorio dedicado para nuestro proyecto. Albergará todos los archivos del proyecto junto con módulos adicionales.
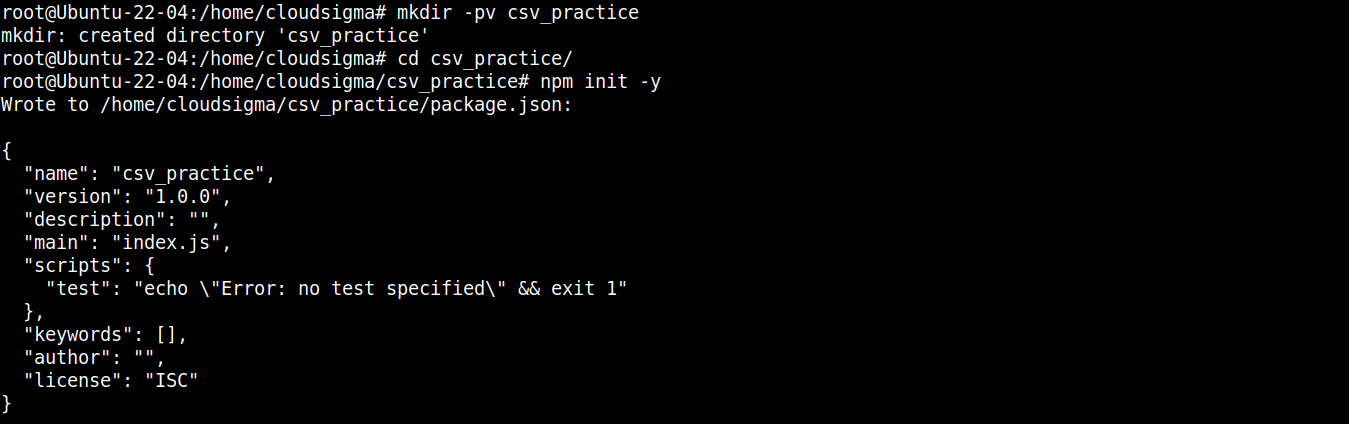
Cree un nuevo directorio:
|
1 |
mkdir -pv csv_practice |
Navegue dentro del directorio:
|
1 |
cd csv_practice/ |
A continuación, ejecute el siguiente comando para declarar el directorio como un proyecto npm :
|
1 |
npm init -y |
Una vez inicializada la carpeta del proyecto, podemos comenzar a instalar los paquetes y módulos necesarios. Primero, vamos a instalar node-csv:
|
1 |
npm install csv |

El módulo node-csv es en realidad una colección de varios otros módulos: csv-generate, csv-parse (para analizar archivos CSV), csv-stringify (para escribir datos en CSV) y stream-transform.
A continuación, necesitamos el módulo para comunicarnos con SQLite. El siguiente comando instalará el módulo node-sqlite3 :
|
1 |
npm install sqlite3 |

El componente que necesitamos para nuestro proyecto es un archivo CSV. Para fines de demostración, utilizaremos el archivo CSV de migración de Nueva Zelanda:
|
1 |
wget https://www.stats.govt.nz/assets/Uploads/International-migration/International-migration-September-2021-Infoshare-tables/Download-data/international-migration-September-2021-estimated-migration-by-age-and-sex-csv.csv -O migration_data.csv |
Echemos un vistazo rápido al contenido del archivo:
|
1 |
cat migration_data.csv | less |
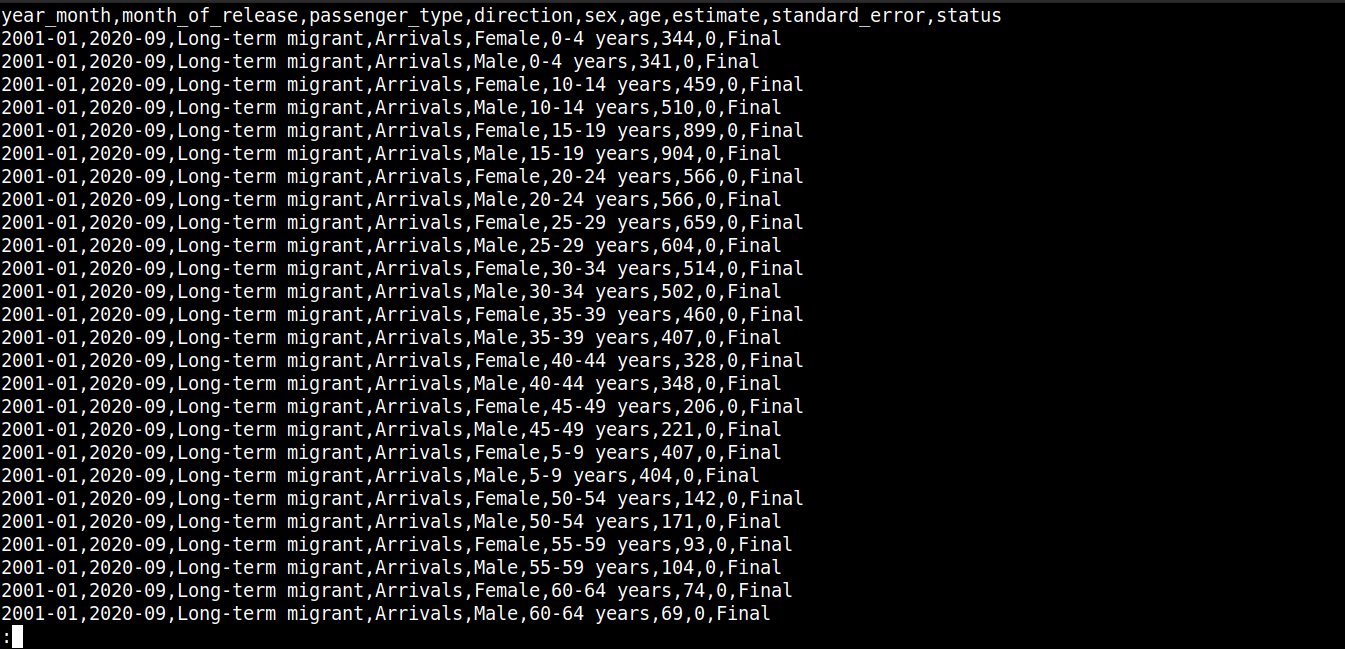
Aquí,
-
La primera línea describe los nombres de las columnas.
-
Las líneas siguientes contienen los valores para estos campos.
-
Cada fila está separada por una nueva línea (\n).
-
Cada punto de datos está separado por una coma (,).
Sin embargo, CSV no se limita a usar comas como delimitador. Otros delimitadores comunes incluyen dos puntos (:), puntos y comas (;) y tabulaciones (\td).
Paso 3 – Lectura de CSV
En esta sección, demostraremos la implementación de un programa de ejemplo que lee y analiza datos del archivo CSV.
Crea un nuevo archivo JavaScript:
|
1 |
touch read_csv.js |
Abre el archivo en tu editor de texto favorito:
|
1 |
nano read_csv.js |
Primero, vamos a importar los módulos fs y csv-parse:
|
1 2 |
const fs = require("fs"); const { parse } = require("csv-parse"); |
Aquí,
-
Primero, a la variable fs se le asigna el objeto fs que devuelve el método require() de Node.js al importar el módulo.
-
A continuación, el método parse se extrae del objeto devuelto por el método require() en la variable parse utilizando la sintaxis de desestructuración.
A continuación, vamos a agregar código para leer el archivo CSV:
|
1 2 3 4 5 |
fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) |
Aquí,
-
Estamos invocando el método createReadStream() del módulo fs y pasando como argumento el archivo CSV que queremos leer. Luego, crea un flujo de lectura (readable stream) dividiendo el archivo más grande en fragmentos más pequeños.
-
Después de crear el flujo, el método pipe() reenvía fragmentos de los datos del flujo a otro flujo. Este nuevo flujo se crea al invocar el método parse() del módulo csv-module.
-
El módulo csv-module despliega un flujo de transformación de lectura/escritura que toma un fragmento de datos y lo transforma en otra forma.
-
El método parse() acepta objetos con propiedades. El objeto procesa adicionalmente los datos analizados. Aquí, el objeto toma las siguientes propiedades:
-
delimiter: El carácter delimitador para separar valores. En el caso de nuestro CSV de destino, es la coma (,).
-
from_line: El número de líneas desde donde el analizador comenzará a analizar. Con el valor dado de 2, el analizador omitirá la línea 1 y comenzará en la línea 2. Con esta disposición, evitamos que los nombres de las columnas se integren en los datos analizados.
-
A continuación, vamos a adjuntar un evento de flujo utilizando el método on() de Node.js:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) .on("end", function () { console.log("finished"); }) .on("error", function (error) { console.log(error.message); }); |
Aquí,
-
Al emitir un evento determinado, un evento de flujo permite que un método consuma un fragmento de datos.
-
Cuando los datos analizados por el método parse() están listos para ser consumidos, se activa el evento data.
-
Para acceder a los datos, pasamos una función de devolución de llamada al método on() que toma un parámetro row.
-
El parámetro row es un fragmento de datos en forma de matriz (resultado del análisis).
-
Finalmente, los datos se registran en la consola utilizando console.log().
Para finalizar el programa, vamos a agregar eventos de flujo adicionales para manejar errores e imprimir un mensaje de éxito cuando se hayan consumido todos los datos del archivo CSV. Actualiza el código de la siguiente manera:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) .on("end", function () { console.log("finished"); }) .on("error", function (error) { console.log(error.message); }); |
Aquí,
-
El evento end se emite cuando se consumen todos los datos del archivo CSV. Da como resultado la llamada al console.log() método que imprime un mensaje de éxito.
-
El evento error se emite al encontrar un error al analizar los datos CSV. Da como resultado la llamada al console.log() método que imprime un mensaje de error.
El código final debería verse así:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
const fs = require("fs"); const { parse } = require("csv-parse"); fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) .on("end", function () { console.log("finished"); }) .on("error", function (error) { console.log(error.message); }); |
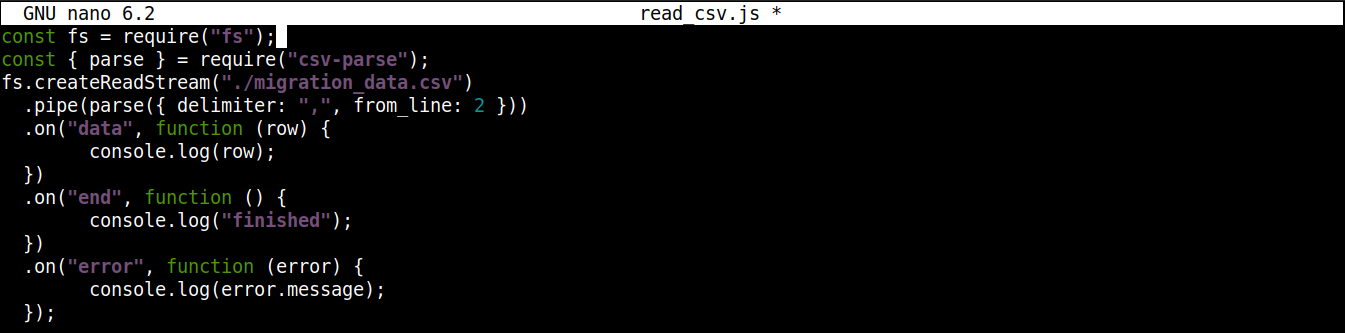
Guarde el archivo y cierre el editor. Ahora estamos listos para ejecutar el programa. Ejecútelo usando Node.js:
|
1 |
node read_csv.js |
La salida debería verse algo así:

Tenga en cuenta que los datos se consumen, transforman y se imprimen en la consola. Como es un proceso continuo, parecerá que los datos se están descargando en lugar de imprimir la salida toda de una vez.
Paso 4 – Transferencia de datos CSV a una base de datos
Hasta ahora, hemos aprendido cómo analizar un archivo CSV usando node-csv. Esta sección demostrará la transferencia de los datos analizados a una base de datos (SQLite).
Cree un nuevo archivo JavaScript para interactuar con la base de datos:
|
1 |
touch csv-to-sqlite3.js |
Ahora, abra el archivo en un editor de texto:
|
1 |
nano csv-to-sqlite3.js |
![]()
Comenzaremos nuestro programa con el siguiente código:
|
1 2 3 |
const fs = require("fs"); const sqlite3 = require("sqlite3").verbose(); const filepath = "./population.db"; |

Aquí,
-
En la primera línea, estamos importando el fs módulo.
-
En la tercera línea, la variable filepath contiene la ruta de la base de datos SQLite.
-
En este punto, la base de datos aún no existe. Sin embargo, será necesaria al trabajar con node-sqlite3.
A continuación, agregue las siguientes líneas para establecer una conexión con la base de datos SQLite:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
function connectToDatabase() { if (fs.existsSync(filepath)) { return new sqlite3.Database(filepath); } else { const db = new sqlite3.Database(filepath, (error) => { if (error) { return console.error(error.message); } console.log("Conectado a la base de datos con éxito"); }); return db; } } |
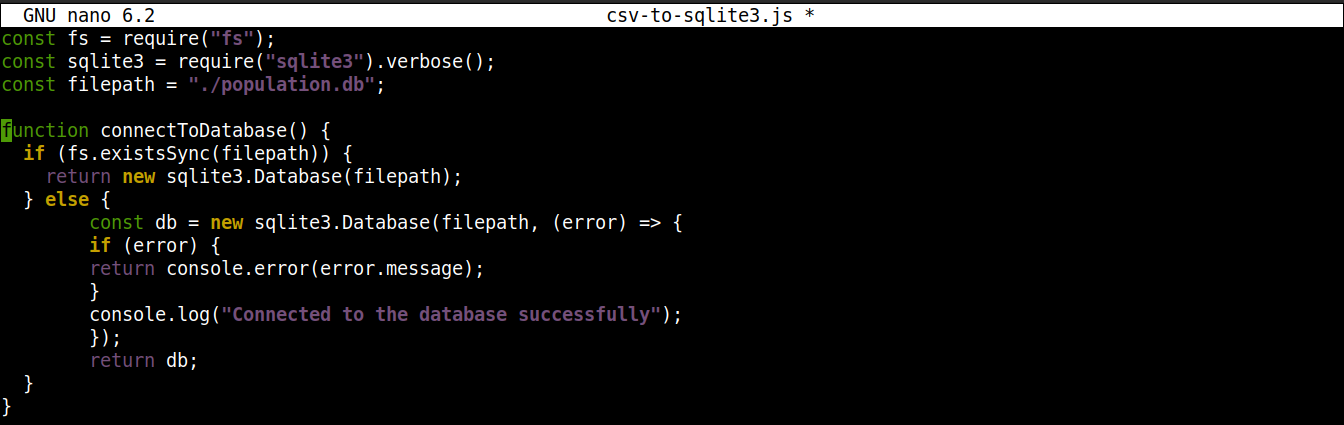
Aquí,
-
El método connectoToDatabase() establece una conexión con la base de datos.
-
Dentro de connectToDatabase(), estamos invocando el existsSync() método del módulo fs dentro de una sentencia if. La sentencia if verifica la existencia de la base de datos en la ubicación especificada.
-
Si la evaluación de la condición es true, entonces la Database() clase del node-sqlite3 módulo se instancia. Una vez establecida la conexión, la función devuelve un objeto y finaliza.
-
Si la evaluación de la condición es false (la base de datos no existe), entonces la ejecución saltará al bloque else. Allí, la Database() clase se iniciará con dos argumentos: una ruta al archivo de la base de datos y un callback.
-
Básicamente, la base de datos se creará si no existe. Sin embargo, si ocurre algún error durante el proceso de creación, establecerá el objeto error e imprimirá el mensaje de error.
A continuación, vamos a introducir código para crear una tabla si la base de datos no existe:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
const fs = require("fs"); const sqlite3 = require("sqlite3").verbose(); const filepath = "./population.db"; function connectToDatabase() { if (fs.existsSync(filepath)) { return new sqlite3.Database(filepath); } else { const db = new sqlite3.Database(filepath, (error) => { if (error) { return console.error(error.message); } createTable(db); console.log("Conectado a la base de datos con éxito"); }); return db; } } function createTable(db) { db.exec(` CREATE TABLE migration ( year_month VARCHAR(10), month_of_release VARCHAR(10), passenger_type VARCHAR(50), direction VARCHAR(20), sex VARCHAR(10), age VARCHAR(50), estimate INT ) `); } module.exports = connectToDatabase(); |
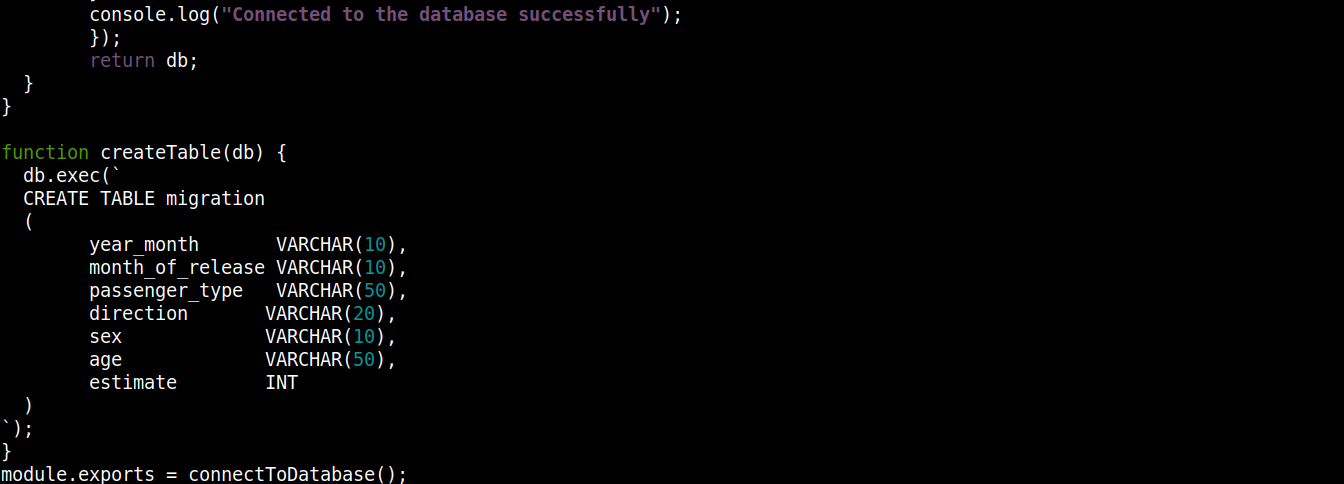
Aquí,
-
La función connectToDatabase() invoca la función createTable() que acepta el objeto almacenado en db como argumento.
-
Fuera de connectToDatabase(), definimos el método createTable() que acepta el objeto de conexión db como parámetro.
-
El método exec() en db toma una sentencia SQL como argumento. Dentro de esta sentencia SQL, definimos la creación de una tabla migration con 7 columnas, cada una correspondiente a los encabezados de columna en el archivo migration_data.csv .
-
Finalmente, estamos invocando connectToDatabase() método y exportando el objeto de conexión que devuelve para que podamos usarlo en otros archivos.
Guarde el archivo y cierre el editor.
A continuación, vamos a crear otro programa para insertar los datos analizados en la base de datos:
|
1 |
nano insert_data.js |
Introduzca el siguiente código en insert_data.js:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
const fs = require("fs"); const { parse } = require("csv-parse"); const db = require("./csv-to-sqlite3"); fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { db.serialize(function () { db.run( `INSERT INTO migration VALUES (?, ?, ? , ?, ?, ?, ?)`, [row[0], row[1], row[2], row[3], row[4], row[5], row[6]], function (error) { if (error) { return console.log(error.message); } console.log(`Fila insertada, ID: ${this.lastID}`); } ); }); }); |
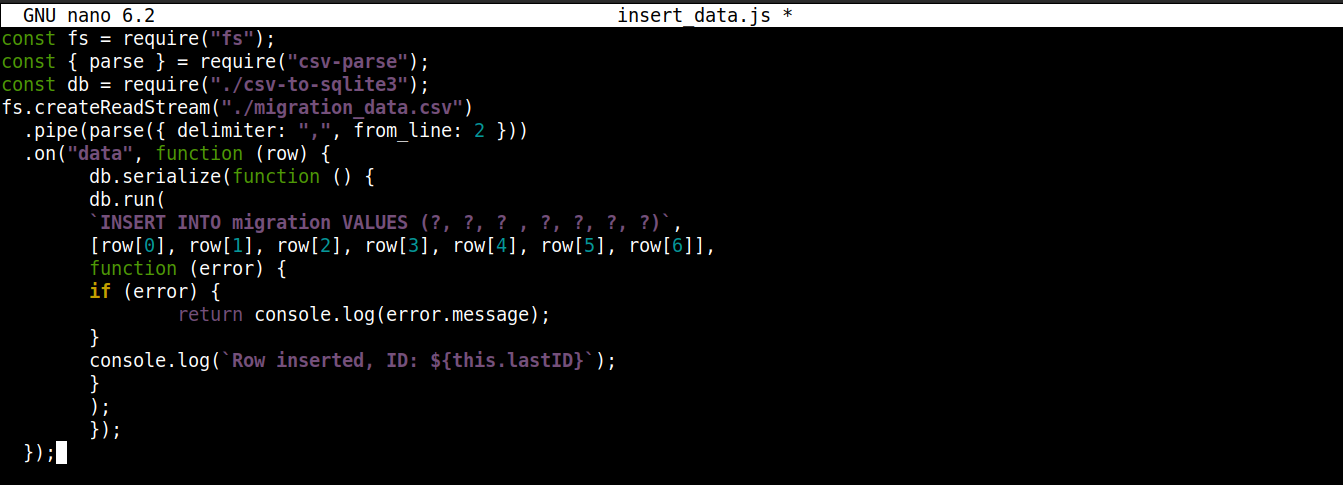
Aquí,
-
Estamos almacenando el objeto de conexión obtenido de csv-to-sqlite3.js en la variable db.
-
Dentro de la función de devolución de llamada (callback) del evento data (asociada al flujo del módulo fs), estamos invocando el serialize() método en el objeto de conexión. Asegura que una sentencia SQL termine de ejecutarse antes de que comience la siguiente, evitando condiciones de carrera en la base de datos (el sistema ejecutando operaciones competidoras simultáneamente).
-
El serialize() acepta tres argumentos:
-
El primer argumento es la sentencia SQL.
-
El segundo argumento es un array.
-
El tercer argumento es una función de devolución de llamada (callback) que se ejecuta cuando los datos se insertan con éxito o sin éxito en la base de datos.
-
Estamos listos para ejecutar el programa. Ejecute insert_data.js usando Node.js:
|
1 |
node insert_data.js |
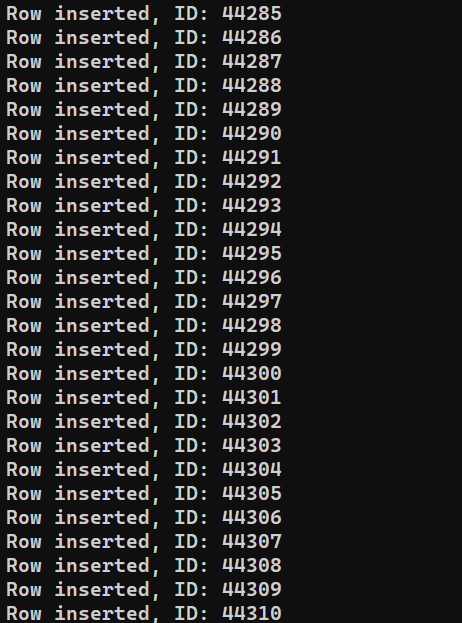
Dependiendo del rendimiento del sistema, el proceso puede tardar algún tiempo en finalizar. Sin embargo, al completarse, la salida debería verse algo así:
Paso 5 – Escritura de datos en CSV
Después de la última sección, tenemos una base de datos que contiene todos los registros que analizamos de migration_data.csv. En esta sección, vamos a leer los datos de la base de datos y a escribirlos en un archivo CSV separado.
Cree un nuevo archivo JavaScript para almacenar el programa:
|
1 |
nano write_csv.js |
Primero, agregue las siguientes líneas para importar fs y csv-stringify junto con el objeto de conexión de la base de datos de csv-to-sqlite3.js:
|
1 2 3 |
const fs = require("fs"); const { stringify } = require("csv-stringify"); const db = require("./csv-to-sqlite3"); |
A continuación, vamos a añadir una variable que contiene el nombre del archivo CSV en el que escribir junto con un flujo de escritura:
|
1 2 3 4 5 6 7 8 9 10 11 |
const filename = "saved_from_db.csv"; const writableStream = fs.createWriteStream(filename); const columns = [ "year_month", "month_of_release", "passenger_type", "direction", "sex", "age", "estimate", ]; |
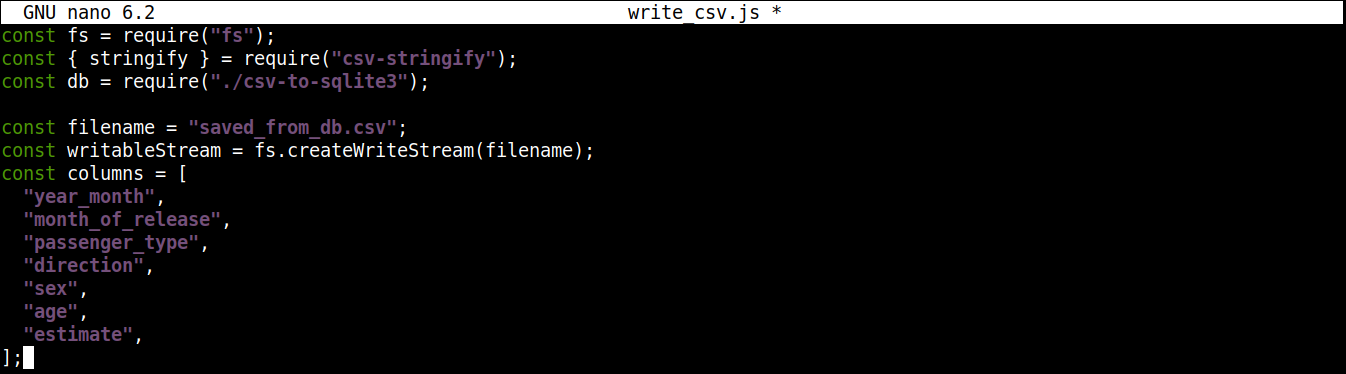
Aquí,
-
El método createWriteStream() toma como argumento el nombre del archivo en el que escribir. Vamos a nombrar al archivo saved_from_db.csv.
-
La variable column almacena un array que contiene todos los nombres de la cabecera para los datos CSV.
A continuación, añade las siguientes líneas de código para leer datos de la base de datos y escribirlos en saved_from_db.csv:
|
1 2 3 4 5 6 7 8 9 10 11 |
const stringifier = stringify({ header: true, columns: columns }); db.each(`select * from migration`, (error, row) => { if (error) { return console.log(error.message); } stringifier.write(row); }); stringifier.pipe(writableStream); console.log("finished writing to CSV"); |
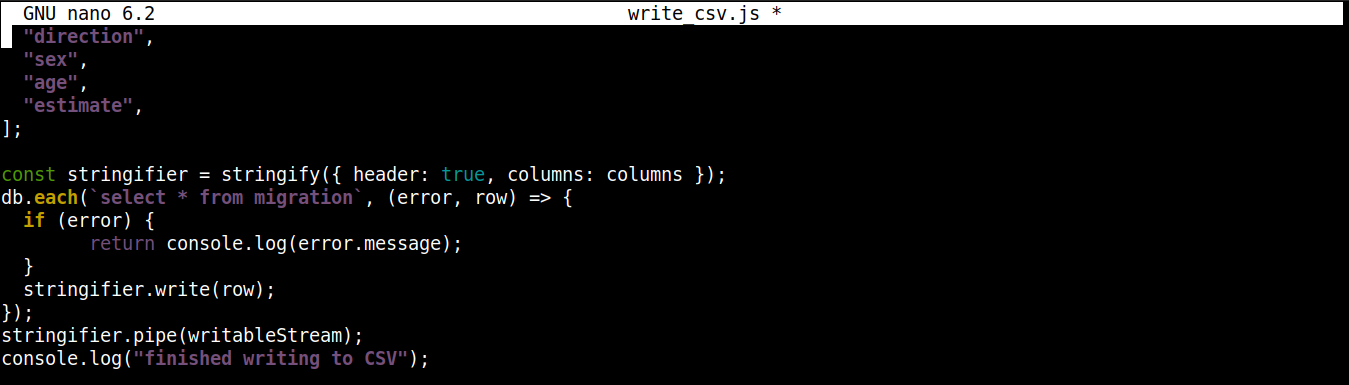
Aquí,
-
Invocamos el método stringify() con un objeto como argumento. Esto da como resultado un flujo de transformación que convierte los datos de un objeto al formato CSV. El objeto pasado a stringify() tiene dos propiedades:
-
header: Acepta un valor booleano. Si el valor es true, entonces se genera una cabecera.
-
columns: Acepta un array que contiene los nombres de las columnas que se escribirán en la primera línea del archivo CSV si header es true.
-
-
El método each() de la conexión csv-to-sqlite3 se invoca con dos argumentos: la sentencia SQL (que lee datos de la base de datos) y un callback (que maneja el éxito/error).
-
En cada iteración de each(), pipe() (desde el flujo stringifier) comienza a enviar datos en fragmentos al flujo de escritura writableStream. Cada fragmento de datos se escribe luego en saved_from_db.csv.
-
Cuando todos los datos se han escrito en el archivo CSV, se muestra un mensaje de éxito en la pantalla de la consola.
El código final debería verse así:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
const fs = require("fs"); const { stringify } = require("csv-stringify"); const db = require("./csv-to-sqlite3"); const filename = "saved_from_db.csv"; const writableStream = fs.createWriteStream(filename); const columns = [ "year_month", "month_of_release", "passenger_type", "direction", "sex", "age", "estimate", ]; const stringifier = stringify({ header: true, columns: columns }); db.each(`select * from migration`, (error, row) => { if (error) { return console.log(error.message); } stringifier.write(row); }); stringifier.pipe(writableStream); console.log("finalizó la escritura en CSV"); |
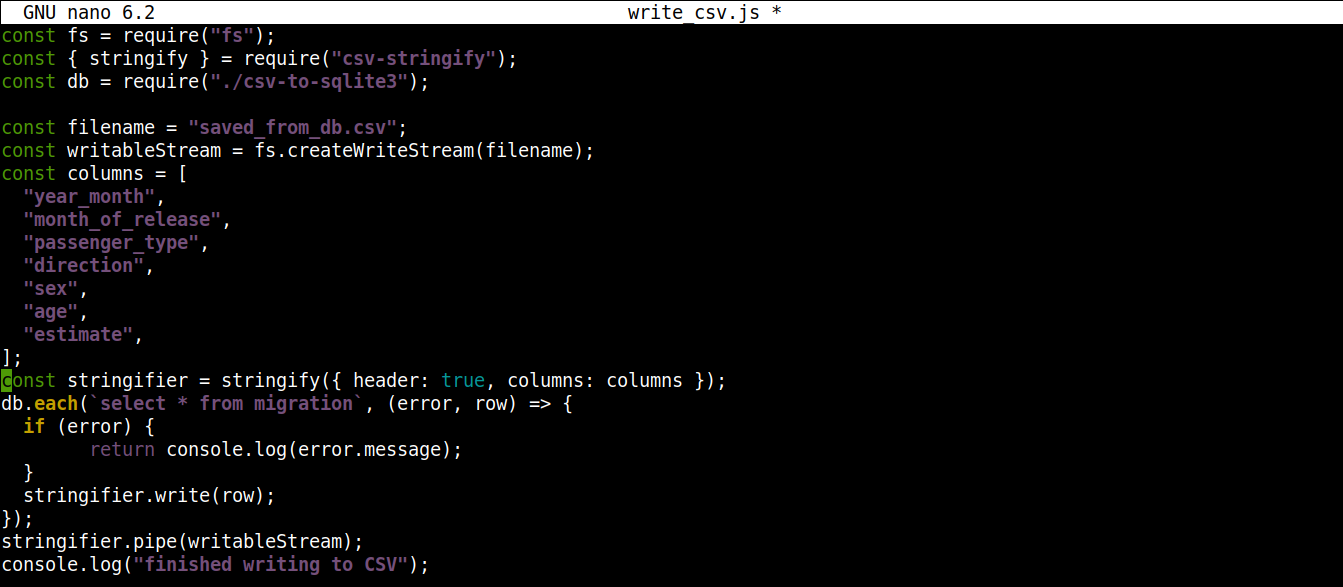
Guarde el archivo y cierre el editor. Ahora podemos ejecutar el programa usando Node.js:
|
1 |
node write_csv.js |
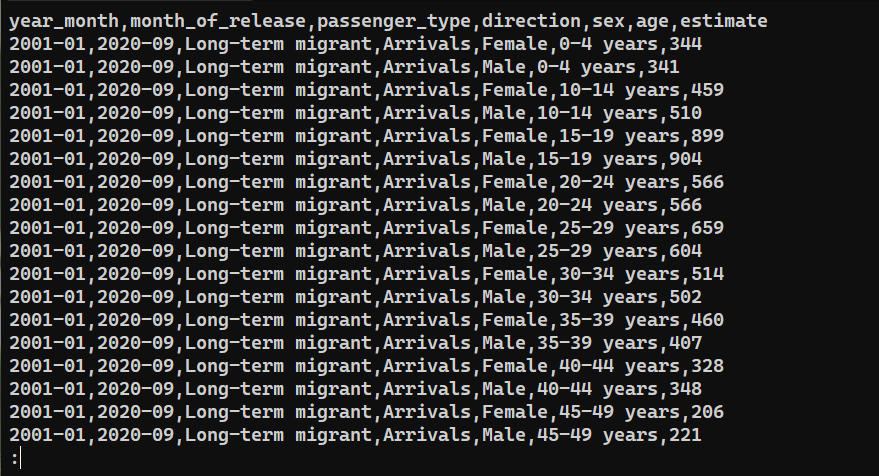
Para confirmar si los datos se exportaron correctamente, verifique el contenido de saved_from_db.csv:
|
1 |
cat saved_from_db.csv | less |
Consideraciones finales
En esta guía, demostramos cómo trabajar con archivos CSV en Node.js utilizando los módulos node-csv y node-sqlite3. Creamos múltiples programas para realizar diversas tareas, por ejemplo, analizar datos de un CSV, insertar los datos en una base de datos SQLite y escribir datos en un nuevo archivo CSV.
Esta guía demuestra solo una pequeña parte de la capacidad del node-csv módulo. Obtenga más información sobre todas sus funciones en CSV Project. Para obtener más información sobre node-sqlite3, consulte la documentación oficial en GitHub. Otro módulo que vale la pena mencionar es event-stream para simplificar el trabajo con streams.
¿Le interesa hacer crecer aún más su proyecto de Node.js? Aquí tiene algunos tutoriales de Node.js que debería consultar:
-
Uso de módulos de Node.js con npm y package.json: un tutorial
-
Cómo implementar una aplicación Node.js (Express.js) con Docker en Ubuntu 20.04
-
Conexión de PostgreSQL con aplicaciones Node.js: un tutorial
¡Feliz programación!
Comentarios
Aún no hay comentarios. Sea el primero.