

The Elastic Stack (anteriormente conocido como ELK Stack) es una solución potente para el registro centralizado. Es una colección de software de código abierto desarrollado por Elastic. Permite a los administradores buscar, analizar y visualizar registros generados desde cualquier fuente en cualquier formato. Es una forma de práctica conocida como registro centralizado. El registro centralizado puede ser muy útil al intentar identificar problemas con servidores y aplicaciones, ya que permite buscar en todos los registros desde un solo lugar. También puede ayudar a identificar problemas en múltiples servidores al correlacionar los registros en un momento específico.
En esta guía, descubre cómo instalar Elastic Stack en Ubuntu 18.04. Primero, sigue nuestro tutorial para instalar tu servidor Ubuntu en CloudSigma.
The Elastic Stack en Ubuntu
The Elastic Stack consta de los siguientes componentes:
- Elasticsearch: Un motor de búsqueda RESTful distribuido. Almacena todos los datos recopilados.
- Logstash: La pieza de procesamiento de datos de Elastic Stack. Envía los datos entrantes a Elasticsearch.
- Kibana: Una interfaz web que ofrece funciones de búsqueda y visualización de registros.
- Beats: Un transmisor de datos ligero y de un solo propósito. Puede enviar datos desde numerosas máquinas a Logstash o Elasticsearch.
Deberás instalar manualmente cada componente del stack.
Requisitos previos
Antes de proceder con la instalación de Elastic Stack, se deben cumplir varios requisitos del sistema:
- Requisitos de hardware:
- CPU: 2 CPUs (accesible desde un usuario sudo no raíz)
- RAM: 4GB
- OpenJDK 11 (la última versión LTS de Java). Para instalar esto, echa un vistazo a nuestro tutorial sobre cómo configurar Java en Ubuntu 18.04.
- Nginx con las configuraciones adecuadas. Puedes seguir nuestra guía para instalar Nginx en Ubuntu 18.04 para configurarlo.
Ten en cuenta que la cantidad de almacenamiento depende de la cantidad de registros que se recopilarán y almacenarán. Además, Elastic Stack también maneja información valiosa sobre el servidor. Para mantener segura la transmisión de datos, recomendamos encarecidamente configurar un certificado TLS/SSL. Sigue este tutorial para adquirir un certificado SSL gratuito en tu servidor Nginx.
Además de un servidor cifrado, también serán necesarios los siguientes pasos:
- Un FQDN (nombre de dominio completamente calificado). En esta guía, será <domain>.
- Ambos registros DNS de los siguientes dominios apuntan al servidor.
- Un registro A con <domain> apuntando a la IP pública del servidor.
- Un registro A con www.<domain> apuntando a la IP pública del servidor.
Instalación de Elastic Stack
-
Configuración del repositorio de Elastic
Los componentes de Elastic Stack no están disponibles directamente desde el repositorio oficial de Ubuntu. Afortunadamente, Ubuntu permite repositorios de 3as partes para instalar paquetes. Para nuestro propósito, agregaremos el repositorio de paquetes de Elastic. El repositorio ofrece todas las actualizaciones de paquetes más recientes de todos los paquetes de Elastic. Todos los paquetes de Elastic están firmados con la clave de firma de Elasticsearch para evitar la suplantación de paquetes. Primero, agrega la clave al llavero de Ubuntu:
|
1 |
curl -fsSL https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add - |
Luego, agrega la lista de fuentes de Elastic en el directorio “sources.list.d”. Es el directorio dedicado que utiliza APT para buscar nuevas fuentes:
|
1 |
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list |
Finalmente, actualiza la caché de APT:
|
1 |
sudo apt update |
Según la documentación oficial, se recomienda instalar cada uno de los componentes en el orden demostrado en esta guía. Esto asegura que los componentes de los que depende cada producto estén en el lugar correcto.
-
Instalación y configuración de Elasticsearch
Una vez configurado el repositorio de Elastic, APT está listo para descargar e instalar todos los paquetes de Elastic. Ejecuta el siguiente comando para instalar Elasticsearch:
|
1 |
sudo apt install elasticsearch |
Ahora puede configurar Elasticsearch. El archivo “elasticsearch.yml” proporciona opciones de configuración sobre clústeres, nodos, rutas, redes, memoria, puerta de enlace y otros. La mayoría de ellos vienen preconfigurados en el archivo. A continuación, abra el archivo de configuración de Elasticsearch con el editor de texto de su elección:
|
1 |
sudo vim /etc/elasticsearch/elasticsearch.yml |
Elasticsearch escucha en el puerto 9200 desde cualquier lugar. Recomendamos restringir el acceso externo a Elasticsearch para evitar que personas ajenas lean los datos o apaguen los clústeres de Elasticsearch utilizando su API REST. Para restringir el acceso a Elasticsearch y reforzar su seguridad, desactive el comentario de la siguiente línea y reemplace su valor:
|
1 |
network.host: localhost |
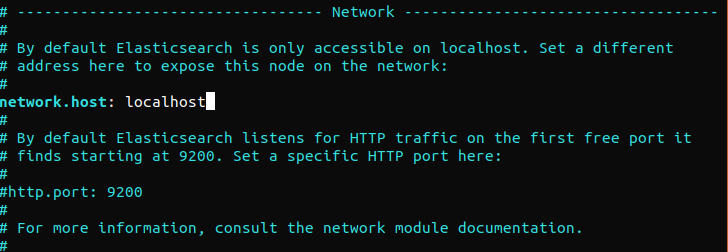
Si Elasticsearch debe escuchar en una dirección IP específica, reemplace “localhost” con la dirección IP de destino. Este es el requisito mínimo de configuración antes de ejecutar Elasticsearch. Guarde y cierre el archivo de configuración. A continuación, inicie el servicio Elasticsearch. Puede tardar unos momentos en iniciar Elasticsearch:
|
1 |
sudo systemctl start elasticsearch |
Después de eso, debe asegurarse de que Elasticsearch se inicie cada vez que arranque el servidor:
|
1 |
sudo systemctl enable elasticsearch |
El siguiente comando verificará si el servicio Elasticsearch se está ejecutando. Todo lo que requiere es enviar una solicitud HTTP:
|
1 |
curl -X GET "localhost:9200" |
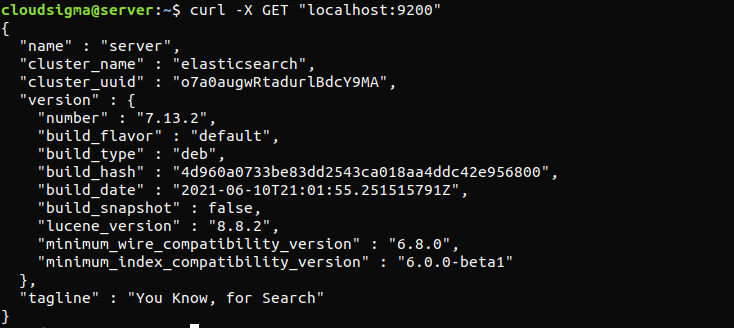
La respuesta se verá algo así. Será una respuesta que muestra información básica sobre el nodo local.
Instalación y configuración del panel de Kibana
Kibana está disponible directamente desde el repositorio de Elastic. Tenga en cuenta que solo debe instalar Kibana después de haber instalado Elasticsearch. Asumiendo que el repositorio ya está disponible, APT puede obtener e instalar Kibana directamente:
|
1 |
sudo apt install kibana |
Una vez instalado, habilite e inicie el servicio Kibana:
|
1 2 |
sudo systemctl enable kibana sudo systemctl start kibana |
Por defecto, Kibana está configurado para escuchar solo en “localhost”. Para el acceso externo, requiere la configuración de un proxy inverso. Aquí, Nginx será el proxy inverso. Utilice el comando openssl para crear un usuario administrador de Kibana. Será la cuenta de usuario para acceder a la interfaz web de Kibana. Aquí, el nombre de usuario de ejemplo será “kibana_admin”. Para garantizar una mejor seguridad, recomendamos utilizar un nombre de usuario no estándar. El siguiente comando creará un usuario administrador para Kibana. El nombre de usuario y la contraseña se generarán y almacenarán en el archivo “htpasswd.users”. Nginx tendrá que configurarse para usar el nombre de usuario y la contraseña:
|
1 |
echo "kibana_admin:`openssl passwd -apr1`" | sudo tee -a /etc/nginx/htpasswd.users |
Introduzca y confirme una contraseña cuando se le solicite. Esta contraseña será importante para acceder a la interfaz de Kibana. Después de eso, debe crear un archivo de bloque de servidor Nginx. Para la demostración, será example.com. También puede ser cualquier otro nombre descriptivo. Si hay registros FQDN y DNS configurados para el servidor, el nombre del archivo también puede coincidir con el FQDN:
|
1 |
sudo vim /etc/nginx/sites-available/example.com |
Si hay algún contenido preexistente, elimínelo y reemplácelo con las siguientes líneas de código:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
server { listen 80; server_name example.com; auth_basic "Acceso restringido"; auth_basic_user_file /etc/nginx/htpasswd.users; location / { proxy_pass http://localhost:5601; proxy_http_version 1.1; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection 'upgrade'; proxy_set_header Host $host; proxy_cache_bypass $http_upgrade; } } |
Guarde y cierre el archivo. Cree un enlace simbólico de la nueva configuración en el directorio “sites-enabled”. Si ya existe algún enlace con el mismo nombre de archivo, es posible que este paso no sea necesario:
|
1 |
sudo ln -s /etc/nginx/sites-available/example.com /etc/nginx/sites-enabled/example.com |
El siguiente comando indicará a Nginx que verifique si hay algún error de sintaxis:
|
1 |
sudo nginx -t |
Si hay algún problema de sintaxis, asegúrese de que el contenido del archivo se haya colocado correctamente. A continuación, reinicie el servicio Nginx:
|
1 |
sudo systemctl restart nginx |
Indique a UFW que permita la conexión a Nginx:
|
1 |
sudo ufw allow 'Nginx Full' |
Ahora debería poder acceder a Kibana a través del FQDN o de la dirección IP pública del servidor Elastic Stack. Compruebe la página de estado del servidor Kibana:
|
1 |
http://<server_ip>:5601/status |
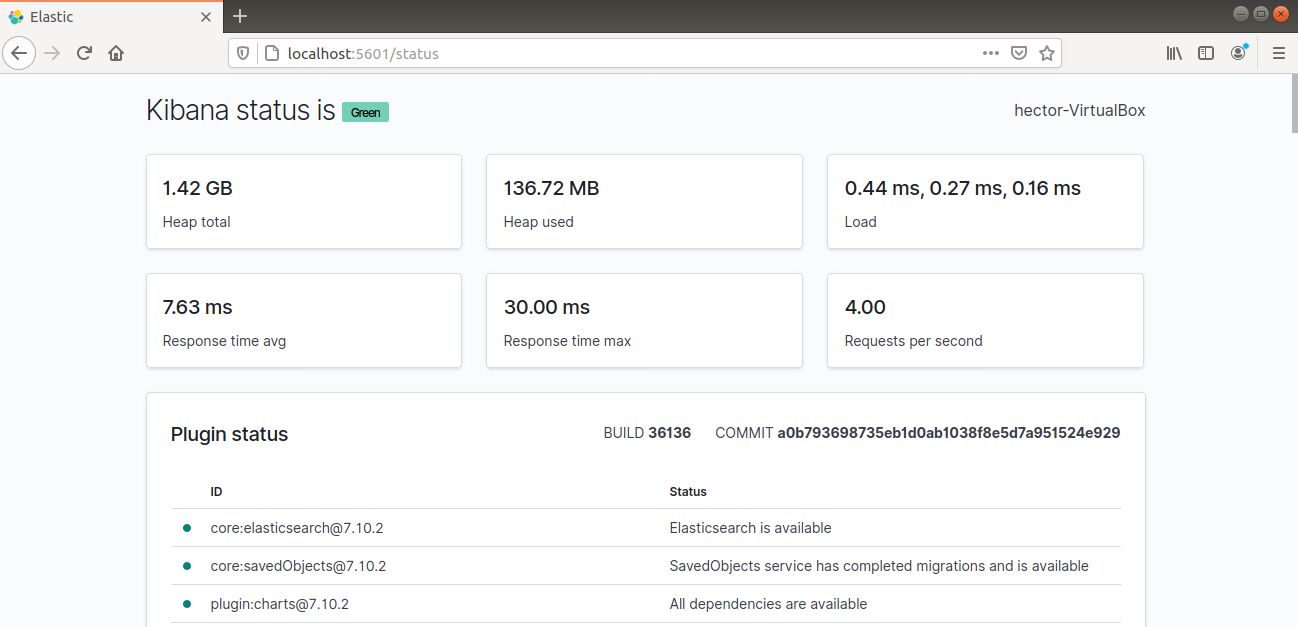
Instalación y configuración de Logstash
Aunque Beats puede enviar datos directamente a la base de datos de Elasticsearch’s, se recomienda utilizar Logstash para procesar los datos. Logstash puede recopilar los datos y convertirlos a un formato común antes de exportarlos a otra base de datos. Ejecute el siguiente comando APT para instalar Logstash:
|
1 |
sudo apt install logstash |
Una vez completada la instalación, es hora de configurar Logstash. Los archivos de configuración de Logstash están en formato JSON. Puede encontrarlos todos en el directorio “/etc/logstash/conf.d”. Es útil pensar en Logstash como una tubería, que recibe datos por un extremo, los procesa y los envía al destino. Una tubería de Logstash requiere dos elementos obligatorios – input y output con un elemento opcional – filter. El plugin input recibe los datos, el filter plugin procesa los datos, y el output plugin escribe los datos en el destino. El siguiente comando creará un archivo de configuración que configurará Logstash para la entrada de Filebeat:
|
1 |
sudo vim /etc/logstash/conf.d/02-beats-input.conf |
Introduzca la siguiente configuración de input. Describe una entrada beats que escuchará en el puerto 5044 en TCP:
|
1 2 3 4 5 |
input { beats { port => 5044 } } |
El siguiente paso es crear un archivo de configuración llamado “10-syslog-filter.conf”. Lo utilizaremos para establecer un filtro para syslogs (registros del sistema):
|
1 |
sudo vim /etc/logstash/conf.d/10-syslog-filter.conf |
Introduzca el siguiente código de configuración de syslog. Este código está disponible directamente en la guía de Elastic. Este código explica la configuración de input para Logstash:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
input{ beats{ port => 5044 host => "0.0.0.0" } } filter { if [fileset][module] == "system" { if [fileset][name] == "auth" { grok { match => { "message" => ["%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: %{DATA:[system][auth][ssh][event]} %{DATA:[system][auth][ssh][method]} for (invalid user )?%{DATA:[system][auth][user]} from %{IPORHOST:[system][auth][ssh][ip]} port %{NUMBER:[system][auth][ssh][port]} ssh2(: %{GREEDYDATA:[system][auth][ssh][signature]})?", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: %{DATA:[system][auth][ssh][event]} user %{DATA:[system][auth][user]} from %{IPORHOST:[system][auth][ssh][ip]}", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: Did not receive identification string from %{IPORHOST:[system][auth][ssh][dropped_ip]}", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sudo(?:\[%{POSINT:[system][auth][pid]}\])?: \s*%{DATA:[system][auth][user]} :( %{DATA:[system][auth][sudo][error]} ;)? TTY=%{DATA:[system][auth][sudo][tty]} ; PWD=%{DATA:[system][auth][sudo][pwd]} ; USER=%{DATA:[system][auth][sudo][user]} ; COMMAND=%{GREEDYDATA:[system][auth][sudo][command]}", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} groupadd(?:\[%{POSINT:[system][auth][pid]}\])?: new group: name=%{DATA:system.auth.groupadd.name}, GID=%{NUMBER:system.auth.groupadd.gid}", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} useradd(?:\[%{POSINT:[system][auth][pid]}\])?: new user: name=%{DATA:[system][auth][user][add][name]}, UID=%{NUMBER:[system][auth][user][add][uid]}, GID=%{NUMBER:[system][auth][user][add][gid]}, home=%{DATA:[system][auth][user][add][home]}, shell=%{DATA:[system][auth][user][add][shell]}$", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} %{DATA:[system][auth][program]}(?:\[%{POSINT:[system][auth][pid]}\])?: %{GREEDYMULTILINE:[system][auth][message]}"] } pattern_definitions => { "GREEDYMULTILINE"=> "(.|\n)*" } remove_field => "message" } date { match => [ "[system][auth][timestamp]", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ] } geoip { source => "[system][auth][ssh][ip]" target => "[system][auth][ssh][geoip]" } } else if [fileset][name] == "syslog" { grok { match => { "message" => ["%{SYSLOGTIMESTAMP:[system][syslog][timestamp]} %{SYSLOGHOST:[system][syslog][hostname]} %{DATA:[system][syslog][program]}(?:\[%{POSINT:[system][syslog][pid]}\])?: %{GREEDYMULTILINE:[system][syslog][message]}"] } pattern_definitions => { "GREEDYMULTILINE" => "(.|\n)*" } remove_field => "message" } date { match => [ "[system][syslog][timestamp]", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ] } } } } |
El siguiente archivo de configuración se encargará de la salida. Abra un nuevo archivo llamado “30-elasticsearch-output.conf:”
|
1 |
sudo vim /etc/logstash/conf.d/30-elasticsearch-output.conf |
Introduzca el siguiente código. Este código explica la configuración de salida para Logstash:
|
1 2 3 4 5 6 7 |
output { elasticsearch { hosts => ["localhost:9200"] manage_template => false index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}" } } |
Pruebe la configuración de Logstash. Luego, ejecute el siguiente comando:
|
1 |
sudo -u logstash /usr/share/logstash/bin/logstash --path.settings /etc/logstash -t |
Si no hay ningún error, Logstash imprimirá el siguiente mensaje de éxito. Si no tuvo éxito, asegúrese de que todos los archivos de configuración tengan los códigos correctos. Finalmente, inicie y habilite el servicio Logstash:
|
1 2 |
sudo systemctl start logstash sudo systemctl enable logstash |
Ahora que Logstash se está ejecutando correctamente y está completamente configurado, instalemos Filebeat.
Instalación y configuración de Filebeat
Elastic Stack utiliza transportadores de datos, conocidos como “Beats”, para recopilar datos de diversas fuentes y transportarlos a Logstash/Elasticsearch. Aquí hay una lista corta de los Beats disponibles de Elastic:
- Filebeat: Recopilación/envío de archivos de registro.
- Metricbeat: Recopilación/envío de métricas de sistemas y servicios.
- Packetbeat: Recopilación/análisis de datos de red.
- Winlogbeat: Recopilación de registros de eventos de Windows.
- Auditbeat: Recopilación de datos del marco de auditoría de Linux y monitoreo de la integridad de los archivos.
- Heartbeat: Monitoreo de servicios para su disponibilidad.
Para los fines de este tutorial, necesitaremos Filebeat para enviar registros locales a Elastic Stack. Primero, instale Filebeat:
|
1 |
sudo apt install filebeat |
Ahora puede configurar Filebeat. Primero, debe conectarse a Logstash. Utilizaremos la configuración de ejemplo que viene con Filebeat. Abra el archivo de configuración en un editor de texto. Tenga en cuenta que, dado que el archivo está en formato YAML, la sangría correcta es importante:
|
1 |
sudo vim /etc/filebeat/filebeat.yml |
Busque la sección “output.elasticsearch” y comente las siguientes líneas. Esto configurará Filebeat para enviar eventos directamente a Elasticsearch/Logstash para un procesamiento adicional. A continuación, vaya a la sección “output.logstash”. Luego, descomente las líneas:
|
1 2 3 4 5 6 7 |
#output.elasticsearch: # Array de hosts a los que conectarse. # hosts: ["localhost:9200"] output.logstash: # Los hosts de Logstash hosts: ["localhost:5044"] |
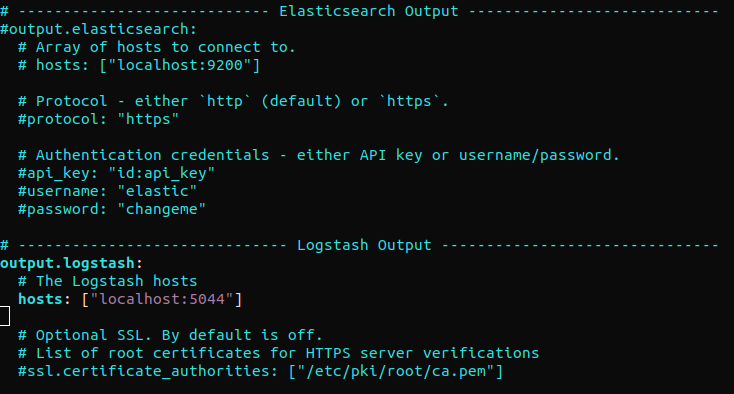
Filebeat admite módulos que pueden extender su funcionalidad. En este tutorial, utilizaremos el módulo system que recopila y analiza los registros generados por el servicio de registro del sistema de las distribuciones comunes de Linux. Habilite el módulo system de Filebeat:
|
1 |
sudo filebeat modules enable system |
El siguiente comando de Filebeat listará todos los módulos habilitados y deshabilitados:
|
1 |
sudo filebeat modules list |
Por defecto, Filebeat está configurado para seguir las rutas predeterminadas para los registros de syslog y de autorización. Los parámetros de los módulos están disponibles en el archivo de configuración “/etc/filebeat/modules.d/system.yml”.
El siguiente paso es cargar la plantilla de índice en Elasticsearch. Un índice de Elasticsearch denota una colección de documentos que comparten características similares. Cada índice viene con un nombre. El nombre es necesario al realizar varias operaciones dentro de él. La plantilla de índice se aplica automáticamente cada vez que se genera un nuevo índice. A continuación, cargue la plantilla:
|
1 |
sudo filebeat setup --template -E output.logstash.enabled=false -E 'output.elasticsearch.hosts=["localhost:9200"]' |
Filebeat contiene un panel de control de muestra para Kibana por defecto. Ayuda a visualizar los datos de Filebeat en Kibana. Sin embargo, antes de usar el panel de control, es necesario crear el patrón de índice y cargar los paneles de control en Kibana. Mientras se cargan los paneles de control, Filebeat se comunica con Elasticsearch para obtener información de la versión. Para cargar los paneles de control, mientras Logstash está habilitado, es necesario tener deshabilitada la salida de Logstash y habilitada la salida de Elasticsearch. El siguiente comando hará el trabajo:
|
1 |
sudo filebeat setup -e -E output.logstash.enabled=false -E output.elasticsearch.hosts=['localhost:9200'] -E setup.kibana.host=localhost:5601 |
Finalmente, puede iniciar Filebeat:
|
1 2 |
sudo systemctl start filebeat sudo systemctl enable filebeat |
Ahora, es el momento de probar la configuración de Elastic Stack. Si se configuró correctamente, la salida se verá algo así:
|
1 |
curl -XGET 'http://localhost:9200/filebeat-*/_search?pretty' |
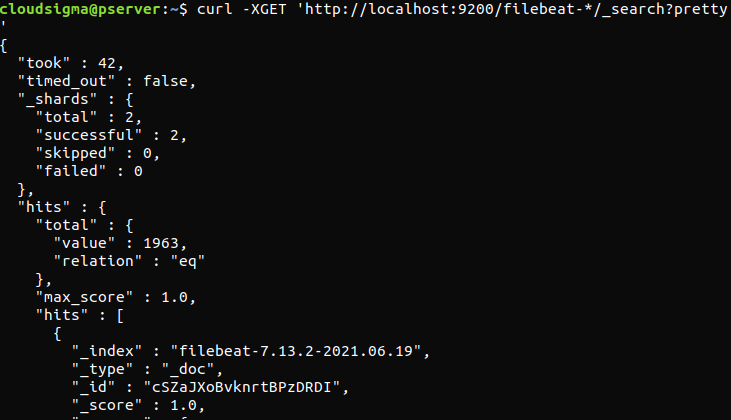
Si la salida informa 0 resultados totales, Elasticsearch no está cargando ningún registro bajo el índice que buscamos. Esto indica que hubo un error con la configuración. Si la salida fue la esperada, entonces Elastic Stack se ha configurado correctamente.
Descripción general de los paneles de control de Kibana
Ahora, es el momento de explorar la interfaz web de Kibana que ya hemos instalado. Primero, abra el panel de control de Kibana. Debería estar ubicado en el FQDN o en la dirección IP pública del servidor de Elastic Stack:
|
1 |
http://<server_ip>:5601 |
Introduzca las credenciales de inicio de sesión que generamos anteriormente. Una vez que haya iniciado sesión, el panel de control se verá así:
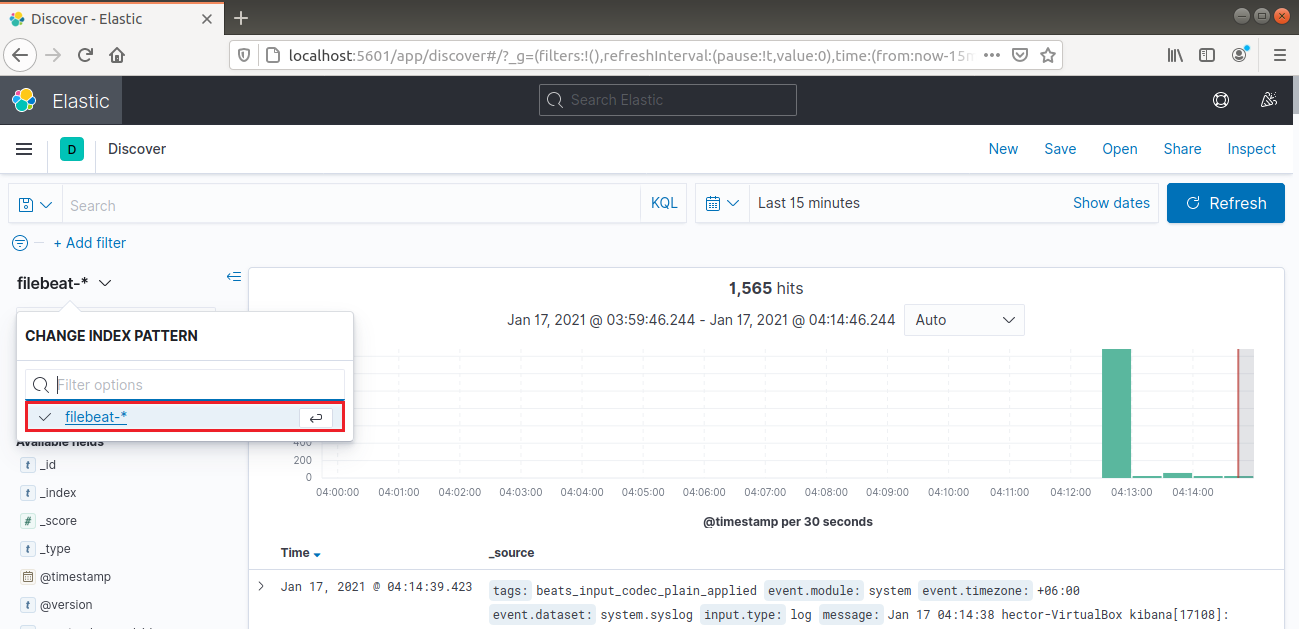
Desde la barra de navegación izquierda, selecciona “Discover”. Luego, selecciona el patrón “filebeat-*”. Muestra todos los registros recopilados durante los últimos 15 minutos. Es posible buscar y explorar registros y personalizar el panel:
Desde la barra de navegación izquierda, ve a Dashboard >> Filebeat System. Aquí están disponibles todos los paneles de muestra del módulo de sistema de Filebeat.
En el siguiente ejemplo, se detallan varias estadísticas basadas en los mensajes de syslog:
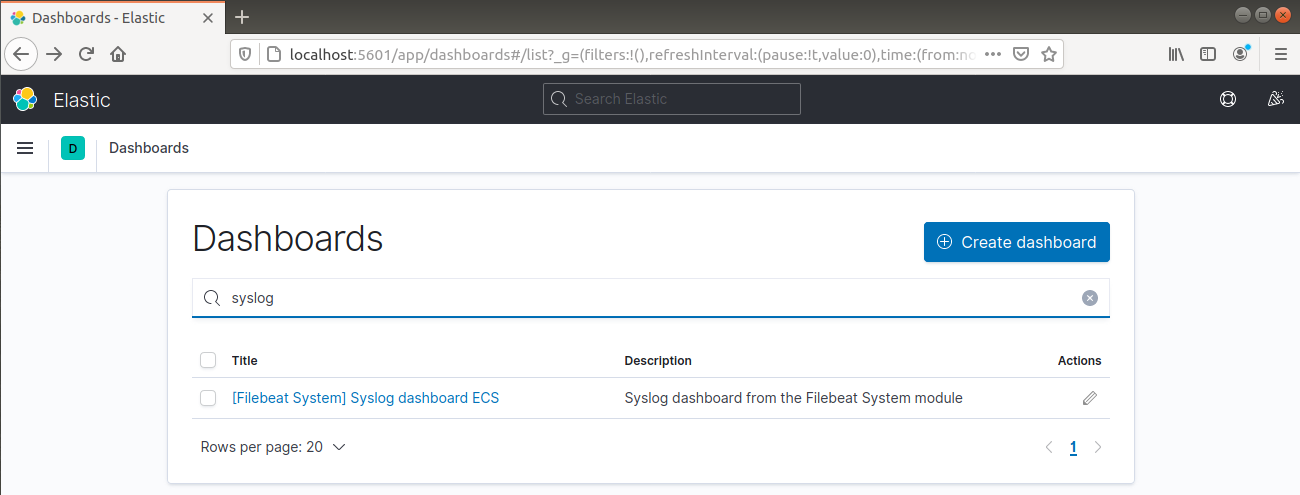
También puede informar qué usuarios han ejecutado comandos con sudo:
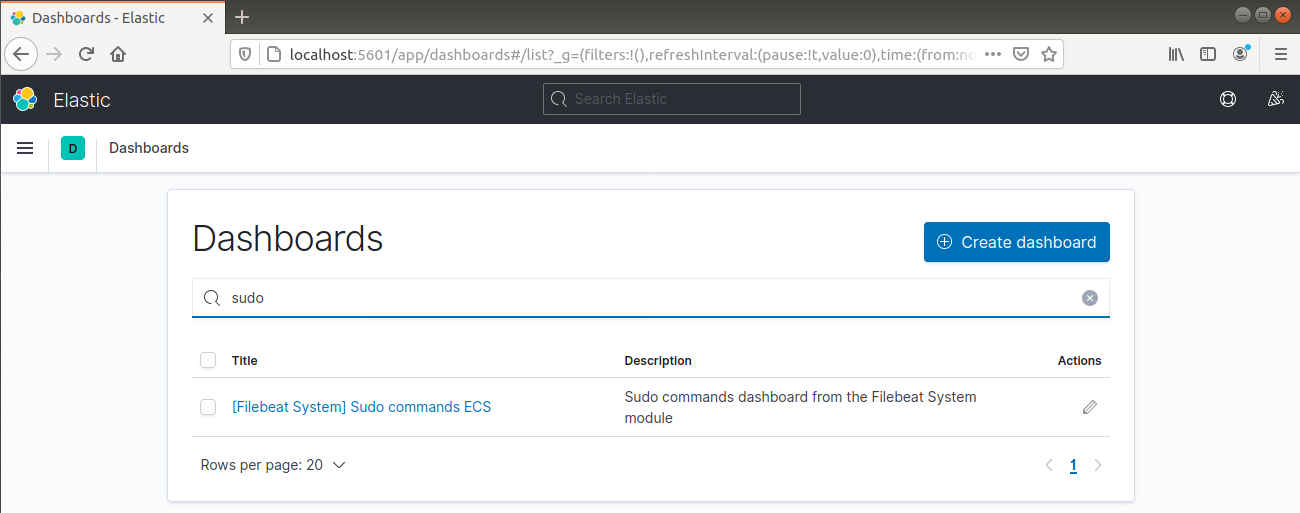
Finalmente, Kibana te brinda la oportunidad de explorar muchas otras funcionalidades, como gráficos y filtrado, así que siéntete libre de explorar por tu cuenta.
Reflexiones finales
Elastic Stack es una solución potente para analizar registros del sistema. Ten en cuenta que, aunque cualquier registro o dato indexado se puede enviar a Logstash utilizando Beats, se vuelve más útil cuando se analiza y estructura a través de los filtros de Logstash.
¡Feliz computación!
Comentarios
Aún no hay comentarios. Sea el primero.