

Este tutorial te guiará en la configuración de un clúster de Kubernetes desde cero utilizando Ansible y Kubeadm y en el posterior despliegue de una aplicación Nginx contenedorizada con él.
Introducción
Kubernetes (también conocido como k8s o “kube”) es una plataforma de orquestación de contenedores de código abierto que automatiza muchos de los procesos manuales involucrados en el despliegue, gestión y escalado de aplicaciones contenedorizadas. Kubernetes cuenta con una comunidad de código abierto en rápido crecimiento que contribuye activamente al proyecto. Echa un vistazo a nuestra publicación de blog que te presentará todo lo que necesitas saber sobre los conceptos básicos de la plataforma Kubernetes.
Kubeadm es una herramienta que configura varios elementos, partes y piezas integrados, como el servidor de API, el Controller Manager y Kube DNS. También ayuda a automatizar la instalación. Sin embargo, no crea usuarios ni gestiona la instalación de dependencias a nivel del sistema operativo y su configuración, y tampoco puede aprovisionar tu infraestructura.
Ansible es una herramienta de código abierto para el aprovisionamiento de software y el despliegue de aplicaciones. Saltstack es un software de código abierto para la automatización de tecnologías de la información impulsada por eventos. Estas son las dos herramientas que hacen que la creación de clústeres adicionales o la recreación de clústeres existentes sea menos vulnerable a errores y se pueden utilizar para estas tareas preliminares.
Objetivos:
Tu clúster incluirá los siguientes recursos físicos:
1. Un nodo maestro:
Un nodo maestro es un nodo que controla y gestiona un conjunto de nodos de trabajo (entorno de ejecución de cargas de trabajo) y se asemeja a un clúster en Kubernetes. También contiene el plan de recursos del nodo para determinar la acción adecuada para el evento desencadenado. Ejecuta etcd, un almacén de clave-valor distribuido de código abierto utilizado para almacenar y gestionar los datos del clúster entre los componentes que programan las cargas de trabajo en los nodos de trabajo.
Por ejemplo, el programador determinaría qué nodo de trabajo alojará un POD recién programado.
2. Dos nodos de trabajo:
Los nodos de trabajo son los nodos que continúan con su trabajo asignado incluso si el nodo maestro se cae una vez completada la programación. Los nodos de trabajo son los servidores donde se ejecutarán tus cargas de trabajo (es decir, aplicaciones y servicios contenedorizados). También puedes aumentar la capacidad del clúster añadiendo trabajadores.
Una vez que completes este tutorial, tendrás un clúster completamente funcional listo para ejecutar cargas de trabajo (es decir, aplicaciones y servicios contenedorizados) asumiendo que los servidores del clúster tienen suficientes recursos de CPU y RAM para que se ejecuten tus aplicaciones. Después de haber configurado con éxito el clúster, puedes ejecutar casi cualquier aplicación UNIX tradicional. Podría estar contenedorizada en tu clúster, incluyendo aplicaciones web, bases de datos, demonios y herramientas de línea de comandos.
El clúster en sí consumirá alrededor de 300-500 MB de memoria y el 10% de CPU en cada nodo.
Requisitos previos:
- Debes tener un par de claves SSH en tu máquina Linux local y saber cómo usar claves SSH. Sin embargo, si no has usado claves SSH antes, puedes ver este tutorial para ayudarte a configurar claves SSH en tu máquina local.
- Tres servidores que ejecuten Ubuntu 18.04 con al menos 4 GB de RAM y 4 vCPUs cada uno. Deberías poder acceder por SSH a cada servidor como usuario root con tu par de claves SSH. Sigue este tutorial para instalar tu servidor Ubuntu.
- Ansible instalado en tu máquina local.
- También debes estar familiarizado con los playbooks de Ansible.
- También necesitarás saber cómo iniciar un contenedor a partir de una imagen de Docker. Consulta “Paso 5 — Trabajar con imágenes de Docker en Ubuntu” en Cómo instalar y usar Docker en Ubuntu 18.04 si necesitas un repaso.
Paso 1 — Configuración del directorio del espacio de trabajo y del archivo de inventario de Ansible
Primero necesitas configurar Ansible en tu máquina local. Te ayudará a ejecutar comandos en tu servidor remoto. También facilita el esfuerzo de despliegue manual al automatizarlo. Para ello, necesitarás crear un directorio en tu máquina local que servirá como tu área de almacenamiento digital temporal (Espacio de trabajo).
Una vez que crees un directorio, crearás un hosts archivo para almacenar toda la información sobre las direcciones IP y el grupo de cada servidor. Le ayudará a almacenar la información del inventario en su interior. Como se indicó anteriormente, habría tres servidores, un maestro y dos trabajadores. El servidor maestro será el maestro con una IP que se muestra como master_ip. Los otros dos servidores serán trabajadores y tendrán las IP worker_1_ip y worker_2_ip.
Debe crear un directorio llamado ~/kube-cluster en el directorio de inicio de su máquina local y acceder al directorio utilizando el comando cd:
|
1 2 |
mkdir ~/kube-cluster cd ~/kube-cluster |
El ~/kube-cluster directorio actuará ahora como el área de almacenamiento digital temporal (espacio de trabajo) dentro de la cual ejecutará todos los comandos locales para crear un clúster de Kubernetes utilizando kubeadm. El directorio contendrá todos sus playbooks de Ansible y se utilizará durante el resto del tutorial.
Creación del archivo de hosts
Cree un archivo llamado ~/kube-cluster/hosts utilizando nano o su editor de texto favorito:
|
1 |
nano ~/kube-cluster/hosts |
Ahora deberá agregar el siguiente texto, que especificará información sobre la estructura lógica de su clúster:
|
1 2 3 4 5 6 7 8 9 |
[masters] master ansible_host=master_ip ansible_user=root [workers] worker1 ansible_host=worker_1_ip ansible_user=root worker2 ansible_host=worker_2_ip ansible_user=root [all:vars] ansible_python_interpreter=/usr/bin/python3 |
Como se mencionó, ese archivo de inventario le ayudará a almacenar toda la información sobre las direcciones IP de sus servidores y los grupos a los que pertenece cada servidor. ~/kube-cluster/hosts será su archivo de inventario y (masters y workers) serán los dos grupos de Ansible que ha agregado al mismo especificando la estructura lógica de su clúster.
El grupo Master es el grupo que especifica que Ansible debe ejecutar comandos remotos como el usuario root. También enumera la IP del nodo maestro (master_ip) que puede ser listada por la entrada del servidor llamada “master”. Del mismo modo, el grupo Workers tiene dos entradas para los servidores trabajadores (worker_1_ip y worker_2_ip) que también especifican el ansible_user como root.
La última línea del archivo le indica a Ansible que utilice los intérpretes de Python 3 de los servidores remotos para sus operaciones de administración. Por último, debe guardar y cerrar el archivo después de haber agregado el texto. Después de configurar el directorio del espacio de trabajo y el archivo de inventario de Ansible, pasemos al siguiente paso de instalación de dependencias a nivel del sistema operativo y creación de ajustes de configuración.
Paso 2 — Creación de un usuario no root en todos los servidores remotos
En este paso, aprenderá a crear un usuario no root con privilegios de sudo en todos los servidores para que pueda acceder a ellos por SSH manualmente como un usuario sin privilegios.
Esto puede ser útil para operaciones realizadas con frecuencia para la preservación de un clúster. Además, este paso le ayudará a realizar la tarea de manera más precisa y con menos propensión a errores, disminuyendo las posibilidades de alterar o eliminar archivos importantes de forma involuntaria. Si desea cambiar la configuración de los archivos propiedad de root o ver la información del sistema con comandos como top/htop y ver una lista de contenedores en ejecución, el siguiente paso le ayudará a realizar todas las tareas.
Creación del playbook
Cree un archivo llamado ~/kube-cluster/initial.yml en el espacio de trabajo:
|
1 |
nano ~/kube-cluster/initial.yml |
A continuación, debe agregar la siguiente jugada (play). Una jugada en Ansible es una colección de pasos a realizar que se dirigen a servidores y grupos específicos. Puede haber una o muchas jugadas en un playbook.
La siguiente jugada creará un usuario sudo no root:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
- hosts: all become: yes tasks: - name: crear el 'ubuntu' usuario user: name=ubuntu append=yes state=present createhome=yes shell=/bin/bash - name: permitir 'ubuntu' a tener sin contraseña sudo lineinfile: dest: /etc/sudoers line: 'ubuntu ALL=(ALL) NOPASSWD: ALL' validate: 'visudo -cf %s' - name: configurar up autorizadas claves para el ubuntu usuario authorized_key: user=ubuntu key="{{item}}" with_file: - ~/.ssh/id_rsa.pub |
A continuación se detalla lo que hace nuestro playbook:
- Este playbook creará al usuario no raíz
ubuntu. - Como necesita ejecutar comandos
sudosin que se le solicite una contraseña, este play configurará el archivosudoerspara permitir que el usuarioubuntulo haga. - El propósito principal de la tarea anterior era permitirle acceder por SSH a cada servidor como usuario
ubuntu. Este playbook agrega la clave pública de su máquina local (normalmente~/.ssh/id_rsa.pub) al usuario remotoubuntuen su lista de claves autorizadas.
Ahora, después de agregar el texto, debe guardar y cerrar el archivo.
Ejecución del playbook
Después de eso, necesitamos ejecutar nuestro playbook que creará al usuario no raíz ubuntu simplemente ejecutando en las máquinas locales:
|
1 |
ansible-playbook -i hosts ~/kube-cluster/initial.yml |
La ejecución de este comando llevará algún tiempo, después del cual verá la siguiente salida:
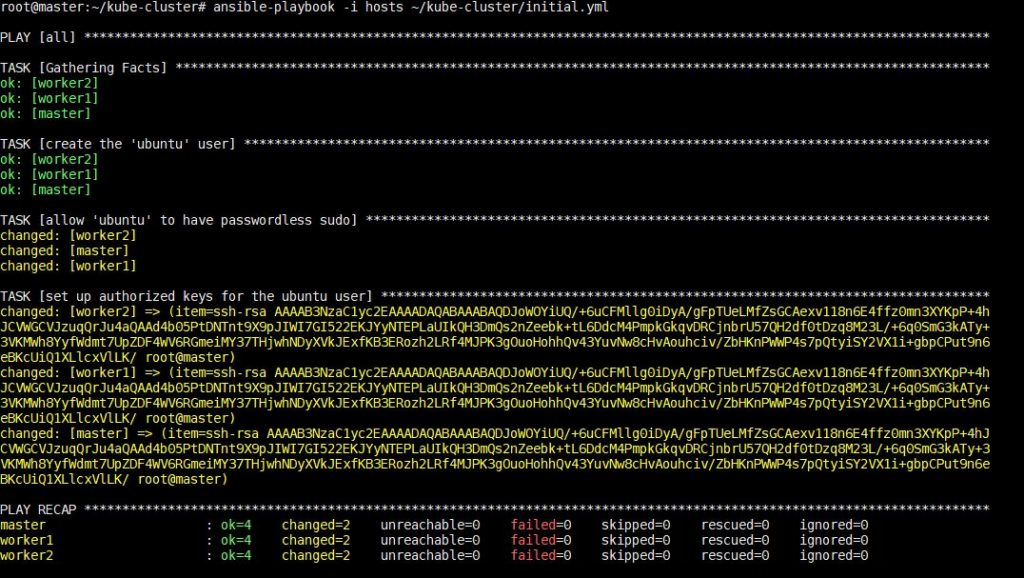
Una vez completado este paso, puede proceder a instalar las dependencias específicas de Kubernetes en el siguiente paso.
Paso 3 — Instalación de las dependencias de Kubernetes
En este paso, aprenderá a instalar los paquetes a nivel del sistema operativo requeridos por Kubernetes con el gestor de paquetes de Ubuntu.
Estos paquetes son:
- Docker: Docker es una plataforma y herramienta para crear, distribuir y ejecutar contenedores Docker. Puede configurar Docker fácilmente siguiendo nuestro tutorial sobre cómo instalar & operar Docker en Ubuntu en la nube pública. Sin embargo, el soporte para otros entornos de ejecución como rkt está en desarrollo activo en Kubernetes.
Kubeadm: kubeadm es una herramienta de CLI que realiza las acciones necesarias para poner en marcha un clúster mínimo viable. Eso le ayudará a instalar y compilar varios componentes del clúster de manera estándar.kubelet: El kubelet es el “agente de nodo” principal que se ejecuta en cada nodo y maneja las operaciones a nivel de nodo.kubectl: kubectl también es una herramienta de CLI que se comunica con su clúster y emite comandos a través de su API Server.
Creación del playbook
Cree un archivo llamado ~/kube-cluster/kube-dependencies.yml en el espacio de trabajo:
|
1 |
nano ~/kube-cluster/kube-dependencies.yml |
Ahora debe agregar los siguientes plays al archivo para instalar estos paquetes en sus servidores:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
- hosts: all become: yes tasks: - name: instalar Docker apt: name: docker.io state: present update_cache: true - name: instalar APT Transport HTTPS apt: name: apt-transport-https state: present - name: agregar la clave apt de Kubernetes-key apt_key: url: https://packages.cloud.google.com/apt/doc/apt-key.gpg validate_certs: false state: present - name: agregar el repositorio APT de Kubernetes' APT repository apt_repository: repo: deb http://apt.kubernetes.io/ kubernetes-xenial main state: present filename: 'kubernetes' - name: instalar kubelet apt: name: kubelet=1.16.0-00 state: present update_cache: true - name: instalar kubeadm apt: name: kubeadm=1.16.0-00 state: present - hosts: master become: yes tasks: - name: instalar kubectl apt: name: kubectl=1.16.0-00 state: present force: yes |
La primera sección (play) del playbook hace lo siguiente:
- Esta sección le ayudará a instalar paquetes a nivel del sistema operativo, Docker – el entorno de ejecución de contenedores.
- Instala
apt-transport-https, lo que le permite agregar fuentes HTTPS externas a su lista de fuentes de APT. - Agrega la apt-key del repositorio APT de Kubernetes para la verificación de claves.
- Agrega el repositorio APT de Kubernetes a la lista de fuentes de APT de sus servidores remotos.
- Instala
kubeletykubeadm.
La segunda sección realiza una tarea única e importante que incluye la instalación de kubectl en su nodo maestro. Ahora, después de agregar el texto, debe guardar y cerrar el archivo.
Ejecución del playbook
Después de eso, necesitamos ejecutar nuestro playbook simplemente ejecutándolo en las máquinas locales:
|
1 |
ansible-playbook -i hosts ~/kube-cluster/kube-dependencies.yml |
La ejecución de este comando tomará algún tiempo, después del cual verá la siguiente salida:
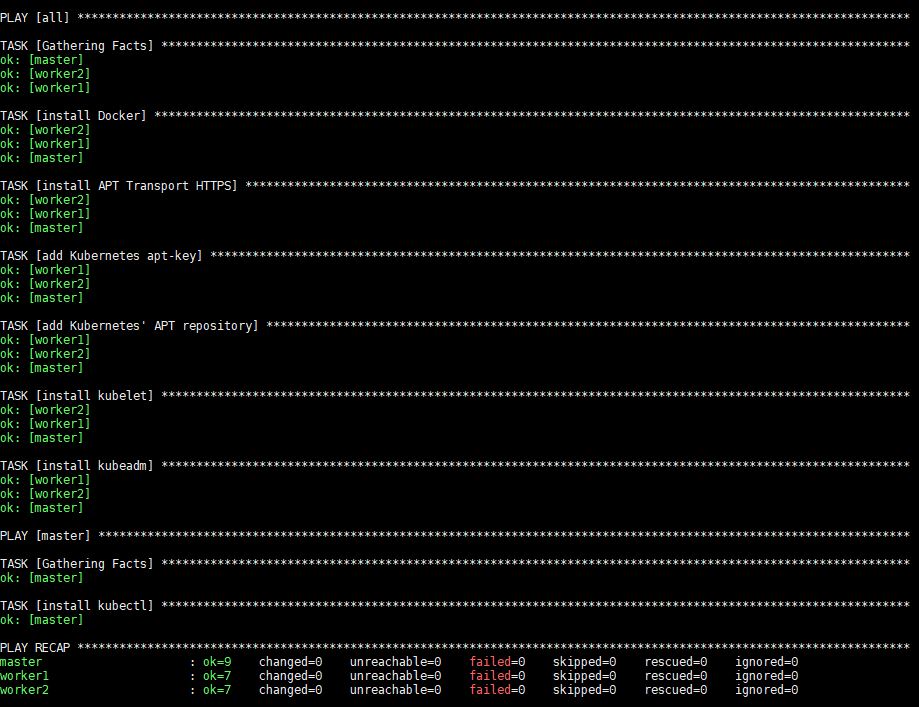
Después de la ejecución, Docker, kubeadm y kubelet se instalarán en todos los servidores remotos. Kubectl no es un componente obligatorio y solo se necesita para ejecutar comandos del clúster. Instalarlo solo en el nodo maestro tiene sentido en este contexto, ya que ejecutará comandos de kubectl solo desde el maestro. Tenga en cuenta, sin embargo, que kubectl los comandos se pueden ejecutar desde cualquiera de los nodos de trabajo o desde cualquier máquina donde se pueda instalar y configurar para apuntar a un clúster.
Todas las dependencias del sistema ya están instaladas. Vamos a configurar el nodo maestro e inicializar el clúster.
Paso 4 — Configuración del nodo maestro
En este paso, aprenderá algunos conceptos como Pods y Plugins de red de Pods ya que su clúster incluirá ambos una vez que configure su nodo maestro.
Los Pods son los objetos desplegables más pequeños y básicos en Kubernetes. Los Pods contienen uno o más contenedores, como contenedores Docker. Cuando un Pod ejecuta múltiples contenedores, los contenedores se gestionan como una sola entidad y comparten los recursos del Pod.
Cada pod tiene su propia dirección IP, y un pod en un nodo debería poder acceder a un pod en otro nodo utilizando la IP del pod. Sin embargo, la comunicación entre los pods es más compleja. Necesita un componente independiente que pueda enrutar de forma transparente el tráfico de un pod en un nodo a un pod en otro. Los plugins de red de pods se utilizan para esta funcionalidad. Hay muchos plugins de red de pods disponibles, pero utilizaremos Flannel ya que es una opción estable y eficiente.
Creación del Playbook
Cree un playbook de Ansible llamado master.yml en su máquina local:
|
1 |
nano ~/kube-cluster/master.yml |
Además, debe agregar el siguiente play al archivo para inicializar el clúster e instalar Flannel:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
- hosts: master become: yes tasks: - name: inicializar el clúster shell: kubeadm init --pod-network-cidr=10.244.0.0/16 >> cluster_initialized.txt args: chdir: $HOME creates: cluster_initialized.txt become: yes become_user: root - name: crear el .directorio .kubedirectory become: yes become_user: ubuntu file: path: $HOME/.kube state: directory mode: 0755 - name: copiar admin.conf a la configuración 'de kube del usuario copy: src: /etc/kubernetes/admin.conf dest: /home/ubuntu/.kube/config remote_src: yes owner: ubuntu - name: instalar la red de Pods become: yes become_user: ubuntu shell: kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/2140ac876ef134e0ed5af15c65e414cf26827915/Documentation/kube-flannel.yml >> pod_network_setup.txt args: chdir: $HOME creates: pod_network_setup.txt |
Aquí tiene un desglose de esta jugada:
- La primera tarea de esta jugada configurará el clúster ejecutando
kubeadm init. Para especificar la subred privada a la que se asignarán las direcciones IP de los pods, pasamos el argumento--pod-network-cidr=10.244.0.0/16. Flannel utiliza la subred anterior de forma predeterminada. Estamos usando esto para decirle akubeadmque use la misma subred. - La segunda tarea se utiliza para crear un directorio
.kubeen/home/ubuntuLa información de configuración, como los archivos de clave de administrador, que son necesarios para conectarse al clúster y la dirección de la API del clúster, se guardará en este directorio. - La tercera tarea se utiliza para copiar el archivo
/etc/kubernetes/admin.confque se generó a partir dekubeadm inital directorio de inicio de su usuario no raíz. Esto le permitirá usarkubectlpara acceder al clúster recién creado. - La última tarea ejecuta
kubectl applypara instalarFlannel.kubectl apply -f descriptor.[yml|json]es la sintaxis para decirle akubectlque cree los objetos descritos en el archivodescriptor.[yml|json]. El archivokube-flannel.ymlcontiene las descripciones de los objetos necesarios para configurarFlannelen el clúster.
Ahora, después de agregar el texto, debe guardar y cerrar el archivo.
Ejecución del Playbook
Después de eso, debe ejecutar nuestro playbook simplemente ejecutando en las máquinas locales:
|
1 |
ansible-playbook -i hosts ~/kube-cluster/master.yml |
La ejecución de este comando llevará algún tiempo, después del cual verá la siguiente salida:
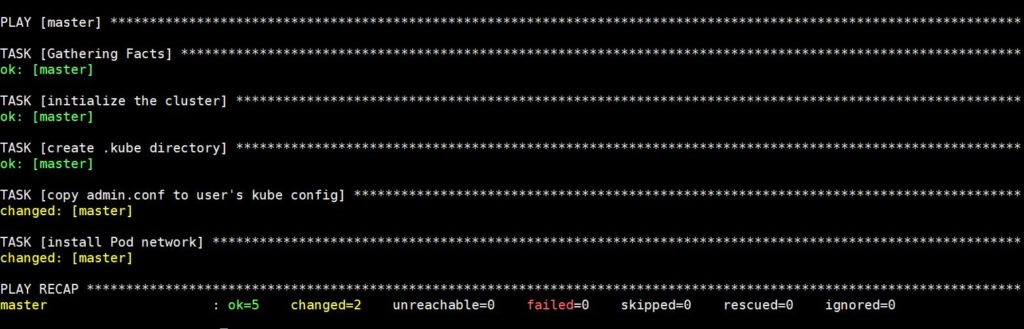
Ahora conéctese por SSH con el siguiente comando para verificar el estado del nodo maestro:
|
1 |
ssh ubuntu@master_ip |
Una vez dentro del nodo maestro, ejecute:
|
1 |
kubectl get nodes |
Ahora verá la siguiente salida:

Al obtener la salida anterior, puede proclamar que todas las tareas de configuración han sido realizadas por el nodo maestro y este puede comenzar a aceptar nodos de trabajo y ejecutar tareas a medida que entra en estado Ready (Listo). Ahora puede agregar los trabajadores desde su máquina local.
Paso 5 — Configuración de los nodos de trabajo
Después de configurar el nodo maestro, ahora podemos pasar a nuestro siguiente paso de configuración de los nodos de trabajo. Agregar nodos de trabajo al clúster se puede hacer simplemente ejecutando un solo comando en cada servidor de trabajo. En este comando se incluye la información importante, como la dirección IP, el puerto del servidor API del maestro y un token seguro. Aunque debe tener en cuenta que no todos los nodos podrán unirse al clúster, solo aquellos nodos que pasen el token seguro podrán unirse al clúster.
Creación del playbook
Este comando le ayudará a volver a su espacio de trabajo y crear un playbook llamado workers.yml:
|
1 |
nano ~/kube-cluster/workers.yml |
Agregue el siguiente texto al archivo para agregar los trabajadores al clúster:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
- hosts: master become: yes gather_facts: false tasks: - name: obtener comando de unión shell: kubeadm token create --print-join-command register: join_command_raw - name: establecer comando de unión set_fact: join_command: "{{ join_command_raw.stdout_lines[0] }}" - hosts: workers become: yes tasks: - name: unirse al clúster shell: "{{ hostvars['master'].join_command }} >> node_joined.txt" args: chdir: $HOME creates: node_joined.txt |
Esto es lo que hace el playbook. Hay dos plays en el código anterior:
- El primer play se utiliza para obtener el comando de unión que debe ejecutarse en los nodos de trabajo. El formato del comando será:
kubeadm join --token sha256:<hash><token><master-ip>:<master-port> --discovery-token-ca-cert-hash sha256:<hash>;. La tarea necesita obtener los valores correctos de token y hash. Una vez que obtiene la entrada correcta, la tarea la establece como un hecho (fact) para que el segundo play pueda acceder a esa información. - El segundo play está escrito únicamente para realizar una sola tarea – hacer que los dos nodos de trabajo formen parte del clúster simplemente ejecutando el comando de unión en todos los nodos de trabajo.
Después de agregar el texto, debe guardar y cerrar el archivo.
Ejecución del playbook
Después de eso, necesitamos ejecutar nuestro playbook ejecutando el siguiente comando en las máquinas de trabajo:
|
1 |
ansible-playbook -i hosts ~/kube-cluster/workers.yml |
La ejecución de este comando tomará algún tiempo, después del cual verá la siguiente salida:
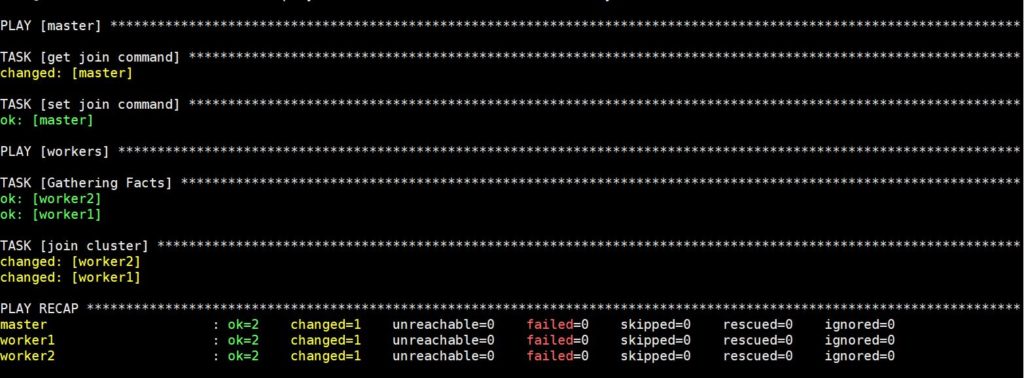
Ahora, su clúster de Kubernetes está completamente configurado y funcional, con los nodos de trabajo listos para ejecutar cargas de trabajo. Antes de pasar al siguiente paso, verifiquemos que el clúster esté funcionando según lo planeado.
Paso 6 — Verificación del clúster
Puede haber casos en los que un clúster falle durante la configuración. Podría deberse a un error de red entre el nodo maestro y el de trabajo, o a un problema del nodo. Por lo tanto, debemos verificar el clúster antes de programar aplicaciones y asegurarnos de que no ocurra ningún mal funcionamiento. Para esto, deberá verificar el estado actual del clúster desde el nodo maestro para asegurarse de que los nodos estén listos. Puede recuperar la conexión con el siguiente comando si los nodos no están listos o si se desconecta:
|
1 |
ssh ubuntu@master_ip |
Use los siguientes comandos para obtener el estado del clúster:
|
1 |
kubectl get nodes |
La ejecución de este comando tomará algún tiempo, después del cual verá la siguiente salida:

Debe verificar si todos los nodos que forman parte del clúster están en estado listo. Si algunos nodos tienen Not Ready como el STATUS, esto muestra que los nodos de trabajo aún no han terminado su configuración. Sin embargo, antes de volver a ejecutar kubectl get nodes y verificar la salida actualizada, debe esperar otros cinco a diez minutos. Si algunos de los nodos aún muestran Not Ready como su estado, debe ir a verificar los pasos anteriores y volver a ejecutar los comandos. Solo si los nodos tienen el valor Ready para STATUS, formarán parte del clúster y estarán listos para ejecutar cargas de trabajo. Después de ejecutar con éxito el sexto paso, su clúster ahora está verificado. Ahora programemos una aplicación Nginx de ejemplo en el clúster.
Paso 7 — Ejecución de una aplicación en el clúster
Creación del Deployment
Después de crear el clúster con éxito, puede implementar cualquier aplicación contenedorizada en su clúster. Puede usar los siguientes comandos a continuación para otras aplicaciones contenedorizadas si se encuentra dentro del nodo maestro. A continuación, ejecute el siguiente comando para crear un deployment llamado nginx :
|
1 |
kubectl create deployment nginx --image=nginx |
Debe cambiar el nombre de la imagen de Docker y cualquier etiqueta relevante (como puertos y volúmenes). Para mantener las cosas familiares, puede implementar Nginx utilizando deployments y servicios para ver cómo se pueden implementar aplicaciones en el clúster.
Un deployment de Kubernetes es un objeto de recurso en Kubernetes que proporciona actualizaciones declarativas para las aplicaciones. Un despliegue le permite describir el ciclo de vida de una aplicación, como la imagen del contenedor, las réplicas y la estrategia de actualización. Un despliegue garantiza que el número deseado de pods se esté ejecutando y esté disponible en todo momento. Si un pod falla durante la vida útil del clúster, lo vuelve a generar. El proceso de actualización también se registra por completo y se versiona con opciones para pausar, continuar y revertir a versiones anteriores. El comando anterior para crear un despliegue llamado Nginx le ayudará a desplegar un pod con un contenedor a partir de la imagen de Docker de Nginx del registro de Docker.
Configuración de Node Port
A continuación, necesitamos crear un NodePort. NodePort es un puerto abierto en cada nodo de su clúster. Kubernetes enruta de forma transparente el tráfico entrante en el NodePort a su servicio, incluso si su aplicación se está ejecutando en otro nodo. Para esto podemos usar este comando para crear un recurso NodePort llamado Nginx que expondrá la aplicación públicamente:
|
1 |
kubectl expose deploy nginx --port 80 --target-port 80 --type NodePort |
Un servicio es otro objeto de Kubernetes responsable de exponer una interfaz a esos pods, lo que permite el acceso a la red ya sea desde dentro del clúster o entre procesos externos y el servicio. Se puede definir como una abstracción sobre el pod que proporciona una única dirección IP y un nombre DNS mediante el cual se puede acceder a los pods. Con el servicio, es muy fácil administrar la configuración de equilibrio de carga.
Ejecute el siguiente comando:
|
1 |
kubectl get services |
Esto mostrará un texto similar al siguiente:

Después de obtener la salida, Kubernetes asignará automáticamente un puerto aleatorio que sea mayor que 30000 , al mismo tiempo que se asegura de que el puerto asignado no esté ya vinculado por otro servicio. La tercera línea de la salida anterior le ayudará a recuperar el puerto en el que se está ejecutando Nginx.
Para verificar que está funcionando, visite http://worker_1_ip:nginx_port o http://worker_2_ip:nginx_port a través de un navegador en su máquina local. Verá la conocida página de bienvenida de Nginx.
Eliminación del despliegue
Si desea eliminar la aplicación Nginx, primero debe eliminar el servicio nginx del nodo maestro:
|
1 |
kubectl delete service nginx |
Para verificar que la aplicación finalmente se ha eliminado, debe ejecutar este comando:
|
1 |
kubectl get services |
Obtendrá la siguiente salida:

Después de eso, debe eliminar el despliegue utilizando el siguiente comando:
|
1 |
kubectl delete deployment nginx |
Puede usar este comando para verificar si el despliegue finalmente se ha eliminado:
|
1 |
kubectl get deployments |
![]()
Conclusión:
Este tutorial le ayudará a configurar correctamente un clúster en Ubuntu 18.04 utilizando Kubeadm y Ansible. Ahora que su clúster está configurado, puede comenzar fácilmente a desplegar sus propias aplicaciones y servicios.
Aquí tiene una lista de enlaces con detalles adicionales que le guiarán en el proceso:
- Dockerizar aplicaciones – Este enlace contiene ejemplos que le guían sobre cómo cargar aplicaciones utilizando Docker. Como dockerizar PostgreSQL, un servicio CouchDB, etc.
- Descripción general de los Pods – Este enlace muestra detalles sobre cómo usar un pod, el funcionamiento de los pods y cómo se relacionan los pods con otros objetos de Kubernetes. Los pods son una parte importante de Kubernetes, por lo que comprenderlos le ayudará a tener éxito en su tarea.
- Descripción general de los despliegues – Le ayudará a aprender sobre los despliegues. Un despliegue proporciona actualizaciones declarativas para Pods y ReplicaSets. Aprenderá cómo actualizar, transferir y revertir un despliegue.
- Descripción general de los servicios -Este enlace le guiará sobre los servicios, que son otro objeto de uso frecuente en los clústeres de Kubernetes. Un servicio en Kubernetes es una abstracción que define un conjunto lógico de Pods y una política mediante la cual se puede acceder a ellos. Comprender los tipos de servicios y las opciones que tienen es esencial para ejecutar aplicaciones tanto con estado como sin estado.
Además, eche un vistazo a nuestros otros tutoriales centrados en Docker y Kubernetes que puede encontrar en nuestro blog:
- Conociendo Kubernetes
- Limpiar recursos de Docker – Imágenes, contenedores y volúmenes
- Cómo ejecutar Docker en CloudSigma (con CloudInit) Actualizado
- Instalación y configuración de Docker en CentOS 7
- Cómo instalar & operar Docker en Ubuntu en la nube pública
También hay muchos otros conceptos importantes como Volúmenes, Ingresses, y Secretos que puede utilizar al implementar aplicaciones de producción.
¡Feliz computación!
Comentarios
Aún no hay comentarios. Sea el primero.