

Web scraping, web crawling, web harvesting o extracción de datos web son sinónimos que se refieren al acto de extraer datos de páginas web a través de Internet. Los web scrapers o web crawlers son herramientas que recorren las páginas web de forma programada extrayendo los datos requeridos. Estos datos, que suelen ser grandes conjuntos de texto, pueden utilizarse con fines analíticos, para comprender productos o para satisfacer la curiosidad sobre una determinada página web.
Si se pregunta cómo puede realizar el web crawling, le mostraremos los conceptos básicos del web scraping a través de un conjunto de datos sencillo. Debería poder seguir el tutorial independientemente de su nivel de experiencia en programación. Para el ejemplo práctico, utilizaremos nuestro blog de CloudSigma. Intentaremos obtener información sobre los tutoriales en nuestra página de blog. Para cuando lea la conclusión de este tutorial, tendrá un web scraper en funcionamiento creado con Python 3 que rastrea varias páginas de nuestra sección de blog y luego muestra los datos en su pantalla.
Utilizando los conocimientos adquiridos al crear este web scraper básico, puede ampliarlo y crear sus propios web scrapers. ¡Esto debería ser divertido, empecemos!
Requisitos previos
Este es un tutorial práctico, por lo que debe tener un entorno de desarrollo local para Python 3 para poder seguirlo bien. En primer lugar, puede consultar nuestro tutorial sobre cómo instalar Python 3 y configurar un entorno de programación local en Ubuntu.
Scrapy
El web scraping implica dos pasos: el primer paso es encontrar y descargar páginas web, el segundo paso es rastrear y extraer información de esas páginas web.
Existen varias formas y librerías que se pueden utilizar para crear un web scraper desde cero en muchos lenguajes de programación. Sin embargo, esto puede traer problemas en el futuro cuando su web scraper se vuelva complejo, o cuando necesite rastrear múltiples páginas con diferentes configuraciones y patrones a la vez. Puede ser una tarea bastante pesada descubrir cómo transformar sus datos extraídos entre diferentes formatos como CSV, XML o JSON.
Aunque algunos puedan apreciar el desafío de crear su propio web scraper desde cero, es mejor no reinventar la rueda y, en su lugar, construirlo sobre una librería existente que maneje todos esos problemas. Utilizaremos Scrapy, una librería de Python, junto con Python 3 para implementar el web scraper en este tutorial. Scrapy es una herramienta de código abierto y una de las librerías de web scraping de Python más populares y potentes. Scrapy fue creada para manejar algunas de las funcionalidades comunes que todos los scrapers deberían tener. De esta manera, no tiene que reinventar la rueda cada vez que quiera implementar un web crawler. Con Scrapy, el proceso de creación de un scraper se vuelve fácil y divertido.
Scrapy está disponible en PyPi, comúnmente conocido como pip – el Python Package Index. PyPi es un repositorio de propiedad comunitaria que aloja la mayoría de los paquetes de Python. Cuando instala y configura Python 3 en su entorno de desarrollo local, también se instala pip, que puede utilizar para instalar paquetes de Python.
Paso 1: Cómo crear un web scraper sencillo
Primero, para instalar Scrapy, ejecute el siguiente comando:
|
1 |
pip install scrapy |
Opcionalmente, puede seguir las instrucciones oficiales de instalación de Scrapy de la página de documentación. Si ha instalado Scrapy correctamente, cree una carpeta para el proyecto utilizando el nombre que prefiera:
|
1 |
mkdir cloudsigma-crawler |
Navegue dentro de la carpeta y cree el archivo principal para el código. Este archivo contendrá todo el código de este tutorial:
|
1 |
touch main.py |
Si lo desea, puede crear el archivo utilizando su editor de texto o IDE en lugar del comando anterior.
A continuación, abra el archivo y comencemos creando un scraper básico que utilice Scrapy. Crearemos una clase de Python que extienda scrapy.Spider, una clase de spider básica de Scrapy. Esta clase tendrá dos atributos requeridos como se define a continuación:
- name — un nombre de tipo cadena (string) para identificar al spider (puede ingresar el nombre que prefiera).
- start_urls — un array que contiene una lista de URLs desde las cuales rastrear. Comenzaremos con una URL.
Añada el siguiente fragmento de código en el archivo abierto para crear el spider básico:
|
1 2 3 4 5 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] |
A continuación se presenta una explicación de cada línea de código:
La primera línea importa Scrapy, lo que nos permite utilizar las diversas clases que proporciona el paquete.
En la siguiente línea, extendemos la clase Spider proporcionada por Scrapy y creamos una subclase llamada CloudSigmaCrawler. Al extender una Clase (Spider), obtenemos acceso a las propiedades de la Clase que ahora podemos usar en nuestro código. En este caso, la clase Spider tiene métodos y comportamientos que definen cómo seguir las URL y extraer datos de las páginas web. Sin embargo, no sabe qué URL seguir ni qué datos extraer. Al extenderla, podemos proporcionar la información requerida a los métodos. Para comprender más sobre la creación de subclases y la extensión, siga leyendo sobre principios de programación orientada a objetos.
En nuestro CloudSigmaCrawler, definimos los atributos requeridos. Primero, nombramos a nuestro spider cloudsigma_crawler. Luego, proporcionamos una única URL para comenzar: https://blog.cloudsigma.com/blog/. Al abrir esta URL, se le dirigirá a la página 1 del blog de CloudSigma que contiene algunos de los muchos tutoriales.
Es hora de probar el scraper. Tiene algunas opciones. Si está utilizando un IDE, por ejemplo, la PyCharm Community Edition de JetBrains, probablemente venga con un botón en el que simplemente puede hacer clic para ejecutar el script. Otra opción es seguir la forma típica de ejecutar archivos de Python desde la línea de comandos: python ruta/al/archivo.py, o py ruta/al/archivo.py. Otra opción es la interfaz de línea de comandos de Scrapy. Scrapy viene con su propia interfaz de línea de comandos para ayudar a iniciar un scraper. Ingrese el siguiente comando para iniciar el scraper:
|
1 |
scrapy runspider main.py |
Dependiendo de la versión de la biblioteca de Scrapy que haya instalado, debería ver una salida similar a la siguiente:
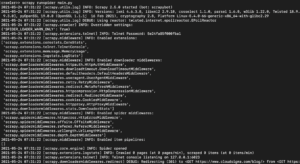
Como puede ver, la salida es bastante larga, por lo que solo seleccionamos algunas partes. Esto es lo que sucedió cuando ejecutó el comando:
- El scraper se inicializó. Por lo tanto, cargó los componentes y extensiones adicionales que necesita usar para seguir y leer datos de las URL.
- Al utilizar la URL proporcionada en la lista start_urls, obtuvo el HTML de la página. Este es un proceso similar al que sigue el navegador al abrir páginas web.
- Después de obtener el HTML, este se pasa al método parse que aún no hemos definido. Por ahora no hace nada, por lo tanto, el spider simplemente sale sin realizar ningún procesamiento. Definiremos el comportamiento del método parse en el siguiente paso.
Paso 2: Cómo extraer datos de una página
En el paso 1, solo implementamos un scraper básico que obtiene una página HTML pero no hace nada después. En esta sección, proporcionaremos instrucciones para extraer datos. En la página del Blog de CloudSigma de la que queremos extraer datos, hay algunas cosas que puede notar, como:
- El encabezado, presente en todas las páginas.
- El menú de navegación y el cuadro de filtro de búsqueda.
- La lista real de los tutoriales en formato de cuadrícula.
Ver el código fuente de la página HTML que desea scrapear le da una idea general de la estructura de la página. Esto le ayuda a escribir un scraper. Puede ver el código fuente haciendo clic derecho en la página y seleccionando Ver código fuente, o presionando Ctrl + U. Aquí hay un fragmento del código fuente:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
<body> <div id="x-iso-container" class="x-iso-container x-iso-container-posts cols-3"> <article id="post-51691" class="post-51691 post type-post status-publish format-standard has-post-thumbnail hentry category-blog-posts category-tutorials tag-apache tag-certbot tag-cloud-guide tag-cloud-tutorial tag-https tag-lets-encrypt tag-ssl tag-ssl-certification tag-tutorial tag-ubuntu"> <div class="entry-wrap"> <header class="entry-header"> <h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Enlace permanente a: "Asegurar Apache con Let’s Encrypt en Ubuntu 18.04"">Asegurar Apache con Let’s Encrypt en Ubuntu 18.04</a> </h2> </header> <div class="entry-content excerpt"> <p>La seguridad del sitio web y de los datos son temas que no se pueden tomar a la ligera. Información altamente confidencial que incluye registros financieros e información privada de los clientes siempre está en tránsito entre la computadora del usuario y su sitio web. Cuando considera este hecho, no es difícil ver por qué los sitios web no seguros podrían resultar en una brecha que podría dañar seriamente su negocio. Hay una … </p> <div><a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="more-link">Leer más</a></div> </div> </div> ... </article> </div> </body> |
Como puede ver, cada tutorial del blog está encerrado dentro de una etiqueta HTML llamada <article>. Extraer los datos de la página implicará dos pasos. El primer paso será capturar cada tutorial del blog buscando las partes de la página que contienen los datos que queremos. El siguiente paso es extraer los datos que queremos de cada tutorial identificado por la etiqueta HTML.
Scrapy identifica los datos a capturar en función de los selectores que proporcione. Podemos usar selectores para encontrar uno o más elementos en una página y obtener los datos dentro de los elementos. Scrapy es compatible con XPath y CSS selectores.
A partir del código fuente que vimos anteriormente, los selectores CSS parecen ser más sencillos. Por lo tanto, esta será la opción que elegiremos, ya que nos ayudará a encontrar todos los tutoriales en la página. En el código fuente HTML, cada tutorial se especifica dentro de la clase CSS llamada post. Los nombres de las clases CSS generalmente se identifican con .nombre_clase (punto nombre_clase). Por lo tanto, usaremos .post para nuestro selector CSS. Dentro del código fuente de nuestro raspador main.py, pasaremos la clase .post al objeto de respuesta, de modo que su archivo ahora se verá así:
|
1 2 3 4 5 6 7 8 9 10 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): pass |
Este fragmento de código obtendrá todos los tutoriales de la página con las start_urls especificadas y recorrerá los tutoriales para extraer datos. En el siguiente paso querrá extraer y mostrar estos datos. Si examina el código fuente del blog de CloudSigma de nuevo, verá que el título de cada tutorial se almacena dentro de una etiqueta <a> que está dentro de una etiqueta <h2>, por ejemplo:
|
1 2 3 4 5 |
<h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Enlace permanente a: "Securing Apache with Let’s Encrypt on Ubuntu 18.04"">Securing Apache with Let’s Encrypt on Ubuntu 18.04</a> </h2> |
Cada objeto de tutorial sobre el que estamos iterando contiene un método CSS al que podemos pasar un selector para localizar y extraer elementos secundarios. Para este ejemplo, queremos extraer el título que está encerrado dentro de la etiqueta <a>. Esta etiqueta está dentro de la etiqueta <h2> dentro de la clase .entry-header dentro de la clase .entry-wrap. Podemos pasar estos selectores CSS al método del objeto para extraer el título, modifique el código para que se vea así:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), } |
La coma final después de extract_first() no es una errata, ya que agregaremos más código debajo de la sección.
Algunos puntos a tener en cuenta del código fuente anterior incluyen:
- ::text añadido al selector – este es un pseudo-selector CSS que indica al código que obtenga el texto dentro de la etiqueta y no la etiqueta en sí.
- llamada al método extract_first() dentro del objeto – indica al código que solo elija el primer elemento que coincida con el selector. Por lo tanto, obtenemos una cadena en lugar de una lista de elementos.
A continuación, guarde el archivo y ejecute el código ingresando el siguiente comando en su terminal:
|
1 |
scrapy runspider main.py |
En la salida, deberías ver los títulos de los tutoriales:
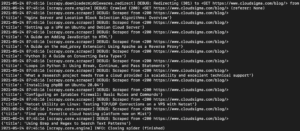
Podemos seguir ampliando esto agregando más selectores para obtener otros detalles sobre un tutorial, como la URL del tutorial, la imagen destacada y la leyenda.
Examinemos de nuevo el código HTML de un solo tutorial:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
<body> <div id="x-iso-container" class="x-iso-container x-iso-container-posts cols-3"> <article id="post-51691" class="post-51691 post type-post status-publish format-standard has-post-thumbnail hentry category-blog-posts category-tutorials tag-apache tag-certbot tag-cloud-guide tag-cloud-tutorial tag-https tag-lets-encrypt tag-ssl tag-ssl-certification tag-tutorial tag-ubuntu"> <div class="entry-featured"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="entry-thumb" title="Enlace permanente a: "Asegurar Apache con Let’s Encrypt en Ubuntu 18.04""> <img width="1000" height="522" src="data:image/svg+xml,%3Csvg%20xmlns='http://www.w3.org/2000/svg'%20viewBox='0%200%201000%20522'%3E%3C/svg%3E" class="attachment-entry-fullwidth size-entry-fullwidth wp-post-image" alt="Let’s Encrypt" loading="lazy" data-lazy-srcset="/media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04.jpg 1000w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-300x157.jpg 300w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-768x401.jpg 768w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-610x318.jpg 610w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-100x52.jpg 100w" data-lazy-sizes="(max-width: 1000px) 100vw, 1000px" data-lazy-src="/media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04.jpg"/> </a> </div> <div class="entry-wrap"> <header class="entry-header"> <h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Permalink to: "Asegurar Apache con Let’s Encrypt en Ubuntu 18.04"">Asegurar Apache con Let’s Encrypt en Ubuntu 18.04</a> </h2> </header> <div class="entry-content excerpt"> <p>La seguridad del sitio web y de los datos son temas que no se pueden tomar a la ligera. La información altamente confidencial que incluye registros financieros e información privada de los clientes siempre está en tránsito entre el ordenador del usuario y su sitio web. Al considerar este hecho, no es difícil ver por qué los sitios web no seguros podrían provocar una brecha de seguridad que podría dañar gravemente su negocio. Hay una … </p> <div><a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="more-link">Leer más</a></div> </div> </div> </article> </div> </body> |
Queremos intentar extraer las partes resaltadas, es decir, la URL del tutorial, la imagen destacada y la leyenda.
- A partir del fragmento de código anterior, la imagen del blog se almacena dentro del atributo data-lazy-src de una etiqueta img dentro de una etiqueta <a> dentro de una etiqueta div al comienzo del tutorial del blog. Podemos usar un selector CSS para obtener el valor como lo hicimos con los títulos de los tutoriales.
- Obtener la URL del tutorial es sencillo, ya que tenemos la etiqueta <a> dentro del elemento <div>.
- La leyenda está encerrada dentro de la etiqueta <p> que está dentro de la etiqueta <div>.
Utilizaremos las clases CSS para obtener lo que queremos. Modifiquemos el código para que se vea así:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), 'caption': tutorial.css(CAPTION_SELECTOR).extract_first(), } |
Guarda los cambios y ejecuta el código con el siguiente comando:
|
1 |
scrapy runspider main.py |
Verás más datos en la salida, como la URL, la imagen y el pie de foto que agregamos:

Eso es todo para rastrear una sola página. A continuación, veamos cómo podemos crear un scraper que siga enlaces.
Paso 3: Cómo rastrear múltiples páginas
Hasta este punto, hemos creado un scraper que puede obtener datos de una sola página. Sin embargo, queremos más que eso. Quieres una araña que pueda seguir enlaces y extraer datos de múltiples páginas de un sitio web de forma programada.
Si vas al final de la página del blog de CloudSigma, notarás los enlaces de paginación y una pequeña flecha que apunta a la derecha indicando la siguiente página. Aquí está el fragmento de código HTML:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<div class="x-pagination"> <ul class="center-list center-text"> <li><span class="pages">Página 1 de 45</span></li> <li></li> <li><span class="current">1</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/2/" class="single_page" title="2">2</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="single_page" title="3">3</a></li> <li><span class="expand">...</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/45/" class="last" title="Última página">45</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/2/" class="prev-next hidden-phone">→</a></li> </ul> </div> |
El fragmento muestra varios enlaces de navegación de página dentro de las etiquetas <li>, debajo de la etiqueta <div> con la clase CSS .x-pagination. Nuestro enfoque está en el enlace que apunta a la siguiente página. Está en la etiqueta <a> del último <li> en la etiqueta <ul>.
El enlace que apunta a la siguiente página tiene la clase .prev-next dentro de la etiqueta <a> como se ve en el fragmento anterior. Sin embargo, si te mueves a la siguiente página, también notarás que los enlaces a la página anterior y siguiente tienen esta clase CSS. Considera este fragmento para la Página 2:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<div class="x-pagination"> <ul class="center-list center-text"> <li><span class="pages">Página 2 de 45</span></li> <li><a href="https://blog.cloudsigma.com/blog/" class="prev-next hidden-phone">←</a></li> <li><a href="https://blog.cloudsigma.com/blog/" class="single_page" title="1">1</a></li> <li><span class="current">2</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="single_page" title="3">3</a></li> <li><span class="expand">...</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/45/" class="last" title="Última página">45</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="prev-next hidden-phone">→</a></li> </ul> </div> |
Si usamos el método extract_first() de Scrapy, funcionará en la primera página. Cuando llegue a la siguiente página, seleccionará el primer enlace con la clase .prev-next, que en el fragmento anterior apunta a la primera página. Esto resultará en un bucle. Por lo tanto, utilizaremos el método extract() de Scrapy. Este método extrae todos los elementos que coinciden con un caso de uso y los coloca en un array. De este array, podemos seleccionar el último elemento que contendrá el enlace real que apunta a la siguiente página. Modifica tu código para que se vea así:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), } NEXT_PAGE_SELECTOR = '.x-pagination > ul.center-list > li > a.prev-next::attr("href")' next_page = response.css(NEXT_PAGE_SELECTOR).extract() if next_page: yield scrapy.Request( response.urljoin(next_page[-1]), callback=self.parse ) |
Repasemos el código para la selección de next_page.
Primero definimos un selector para los enlaces de la página siguiente y anterior. Luego usamos el método extract() para extraer las URL y ponerlas en un array. La variable next_page será un array con dos elementos como:
|
1 |
next_page = [prev_page_url, next_page_url] |
Dado que estamos navegando a la siguiente página, elegiremos el último elemento del array. Next_page[-1] elige el último elemento del array.
El bloque if comprueba si la variable next_page tiene algo y luego llama al método scrapy.Request(). En nuestro código, indicamos a este método que rastree la página con la URL proporcionada y la devuelva al método parse() para que podamos analizarla para extraer los datos y repetir el proceso para la siguiente página. Este proceso se repite hasta que no encuentra un enlace a la siguiente página, o mejor dicho, si el bloque falla, entonces se detiene.
Guarda tu código y ejecútalo. Notarás que la iteración continúa recorriendo las páginas a medida que encuentra más páginas para raspar. Así es como definirías un scraper que sigue enlaces en un sitio web. Nuestro ejemplo es bastante sencillo. Solo vamos a una página, buscamos el enlace a la siguiente página y repetimos el proceso. En otros casos de uso, es posible que desees seguir etiquetas o enlaces que apunten a fuentes externas y más. Aquí está el código fuente completo para el web scraper básico en Python 3:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), 'caption': tutorial.css(CAPTION_SELECTOR).extract_first(), } NEXT_PAGE_SELECTOR = '.x-pagination > ul.center-list > li > a.prev-next::attr("href")' next_page = response.css(NEXT_PAGE_SELECTOR).extract() if next_page: yield scrapy.Request( response.urljoin(next_page[-1]), callback=self.parse ) |
Conclusión
En este tutorial, creamos un web scraper básico que puede rastrear el directorio del blog de CloudSigma y mostrar información sobre los tutoriales del blog en solo unas 27 líneas de código.
Por supuesto, esto es posible porque lo creamos sobre la biblioteca Scrapy de Python. Esto es solo una base que debería ayudarte a crear scrapers más complejos que sigan más etiquetas, resultados de búsqueda de sitios web y más. Puedes consultar la documentación oficial de Scrapy para obtener más información sobre cómo trabajar con Scrapy.
¡Feliz informática!
Comentarios
Aún no hay comentarios. Sea el primero.