

Η grep εντολή είναι ένα ισχυρό εργαλείο για την αναζήτηση μοτίβων σε κείμενο. Είναι προεγκατεστημένη σε οποιαδήποτε διανομή Linux . Εδώ είναι ο οδηγός μας που περιγράφει τη ρύθμιση του LAMP Stack - Linux, Apache, MySQL και PHP.
Το όνομα grep σημαίνει global regular expression print. Το εργαλείο αναζητά το καθορισμένο μοτίβο στην είσοδο. Θεωρητικά, ακούγεται απλό. Ωστόσο, η πραγματική του δύναμη έγκειται στον τρόπο με τον οποίο ορίζετε το μοτίβο. Αυτός ο οδηγός αναλύει πώς να χρησιμοποιήσετε το grep με κανονικές εκφράσεις για την εκτέλεση σύνθετων αναζητήσεων. Ας ξεκινήσουμε!
Πώς να χρησιμοποιήσετε το Grep
Η εντολή grep, από μόνη της, δεν είναι περίπλοκη. Το μόνο που απαιτεί είναι το μοτίβο και το περιεχόμενο στο οποίο θα γίνει η αναζήτηση. Δείτε πώς μοιάζει η βασική δομή της εντολής grep:
|
1 |
grep <regex> <file> |
Searching text
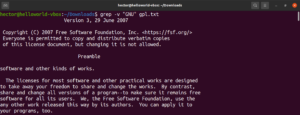
Αρχικά, πάρτε ένα δείγμα αρχείου για να εκτελέσετε την ενέργεια. Κατεβάστε το GNU General Public License v3.0 (σε μορφή κειμένου). Είναι ένα αρκετά μεγάλο αρχείο κειμένου με πολλές λέξεις και φράσεις. Εάν χρησιμοποιείτε Ubuntu μπορείτε να το βρείτε στο παρακάτω αρχείο. Ακολουθήστε τον οδηγό μας για μια γρήγορη και εύκολη εγκατάσταση του Ubuntu.
|
1 |
curl -o gpl.txt https://www.gnu.org/licenses/gpl-3.0.txt |

Στη συνέχεια, μπορείτε να εκτελέσετε μια βασική αναζήτηση κειμένου χρησιμοποιώντας το grep:
|
1 |
grep <pattern> <text_file> |
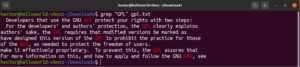
Είναι δυνατό να διοχετεύσετε την έξοδο μιας εντολής στο grep:
|
1 |
cat gpl.txt | grep <pattern> |
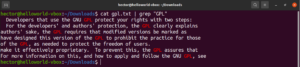
Διάκριση πεζών-κεφαλαίων
Από προεπιλογή, το grep λειτουργεί με διάκριση πεζών-κεφαλαίων. Σε πολλές περιπτώσεις, η παράβλεψη της διάκρισης πεζών-κεφαλαίων μπορεί να είναι η βέλτιστη επιλογή. Για να απενεργοποιήσετε την αναζήτηση με διάκριση πεζών-κεφαλαίων, χρησιμοποιήστε τη σημαία «-i» ή «–ignore-case»:
|
1 2 3 |
$ grep -i <pattern> <file> $ grep --ignore-case <pattern> <flag> |
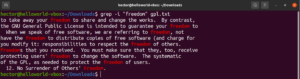
Αντιστροφή εύρεσης
Από προεπιλογή, η συμπεριφορά του grep είναι να εκτυπώνει τις γραμμές όπου βρέθηκε το μοτίβο. Η αντιστροφή αντιστοίχισης αναφέρεται στο φαινόμενο όπου δεν θέλετε να δείτε τις γραμμές που ταιριάζουν με το μοτίβο. Για να αντιστρέψετε την αντιστοίχιση, πρέπει να χρησιμοποιήσετε τη σημαία «-v» ή «–invert-match»:
|
1 2 3 |
$ grep -v <pattern> <file> $ grep --invert-match <pattern> <file> |
Αριθμός γραμμής
Όταν εκτελείτε το grep σε ένα πολύ μεγάλο αρχείο, είναι δύσκολο να παρακολουθήσετε τη θέση του αποτελέσματος αναζήτησης. Για να διευκολύνει τα πράγματα, το grep έχει τη δυνατότητα να εμφανίζει τον αριθμό γραμμής. Για να ενεργοποιήσετε την αρίθμηση γραμμών, χρησιμοποιήστε τη σημαία «-n» ή «–line-number»:
|
1 2 3 |
grep -n <pattern> <file> grep --line-number <pattern> <file> |
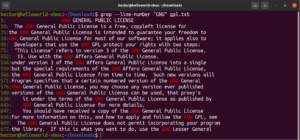
Είναι δυνατό να συνδυάσετε πολλαπλά ορίσματα του grep. Η ακόλουθη εντολή grep θα εκτελέσει μια αντίστροφη αντιστοίχιση ενώ παράλληλα θα εκτυπώσει τους αριθμούς των γραμμών:
|
1 |
grep -nv <pattern> <file> |
Κανονική έκφραση
Στην αρχή αυτού του οδηγού, αναφέραμε ότι το grep σημαίνει global regular expression print. Ο όρος «κανονική έκφραση» ορίζεται ως μια ειδική συμβολοσειρά που περιγράφει το μοτίβο αναζήτησης. Η κανονική έκφραση έχει τη δική της δομή και κανόνες.
Υπάρχουν πολυάριθμοι αλγόριθμοι και εργαλεία αναζήτησης συμβολοσειρών που χρησιμοποιούν κανονικές εκφράσεις (regex για συντομία) για την εκτέλεση αναζητήσεων και ενεργειών αντικατάστασης. Αν και είναι δημοφιλές, διαφορετικές εφαρμογές και γλώσσες προγραμματισμού υλοποιούν το regex ελαφρώς διαφορετικά. Σε αυτήν την ενότητα, θα παρουσιάσουμε μερικές μεθόδους regex χρησιμοποιώντας το grep.
Κυριολεκτική αντιστοίχιση
Στα προηγούμενα παραδείγματα του grep, το grep εκτελούσε αναζήτηση για μια συγκεκριμένη συμβολοσειρά στο δοθέν αρχείο κειμένου. Το grep στην πραγματικότητα έκανε αναζήτηση χρησιμοποιώντας την πολύ βασική κανονική έκφραση. Τα μοτίβα regex που ορίζουν την αναζήτηση για την ακριβή αντιστοίχιση μιας δεδομένης συμβολοσειράς ονομάζονται «literals» (κυριολεκτικά). Το όνομα προέρχεται από το γεγονός ότι ταιριάζουν με το μοτίβο κυριολεκτικά, χαρακτήρα προς χαρακτήρα.
Η κυριολεκτική αντιστοίχιση λειτουργεί με αλφαβητικούς και αριθμητικούς χαρακτήρες (καθώς και με ορισμένους ειδικούς χαρακτήρες). Ωστόσο, ανάλογα με άλλους μηχανισμούς έκφρασης, αυτή η συμπεριφορά ενδέχεται να αλλάξει:
|
1 |
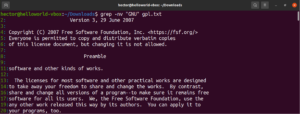
grep "<string>" <file> |
Αντιστοίχιση αγκύρωσης
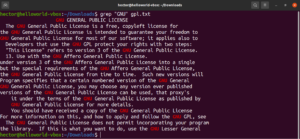
Οι άγκυρες είναι ειδικοί χαρακτήρες που ορίζουν πού πρέπει να βρίσκεται η θέση της αντιστοίχισης στη γραμμή προκειμένου να υπάρχει έγκυρη αντιστοίχιση. Ακολουθεί ένα γρήγορο παράδειγμα για να το απλοποιήσουμε. Αν θέλουμε να βρούμε μόνο τις γραμμές που ξεκινούν με τη συμβολοσειρά «GNU», τότε η grep με regex θα μοιάζει κάπως έτσι. Εδώ, ο χαρακτήρας «^» είναι η άγκυρα, που ορίζει ότι οι αντιστοιχίσεις στην αρχή της γραμμής είναι οι μόνες έγκυρες:
|
1 |
grep -n "^GNU" <file> |

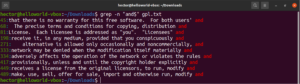
Παρομοίως, αν θέλουμε να βρούμε μόνο τις γραμμές που τελειώνουν με τη συμβολοσειρά «works», τότε η grep με regex θα μοιάζει κάπως έτσι. Εδώ, ο χαρακτήρας «$» είναι η άγκυρα, που ορίζει ότι μόνο οι αντιστοιχίσεις στο τέλος της γραμμής είναι έγκυρες:
|
1 |
grep -n "and$" <file> |
Αντιστοίχιση οποιουδήποτε χαρακτήρα
Κατά την εκτέλεση μιας αναζήτησης κειμένου, ίσως θέλετε να ορίσετε ότι σε μια συγκεκριμένη θέση, μπορεί να υπάρχει οποιοσδήποτε χαρακτήρας. Στις κανονικές εκφράσεις (regex), αυτό εκφράζεται με τον χαρακτήρα της τελείας (.).
Ρίξτε μια ματιά σε αυτό το παράδειγμα. Στο αρχείο κειμένου GNU GPL 3, οι λέξεις «accept» και «except» έχουν και οι δύο κοινό το τμήμα «cept». Επιπλέον, και οι δύο λέξεις έχουν δύο χαρακτήρες πριν από το τμήμα «cept». Η ακόλουθη εντολή grep θα αντιστοιχίσει οποιαδήποτε λέξη έχει δύο χαρακτήρες πριν από το τμήμα «cept»:
|
1 |
grep -n "..cept" <file> |
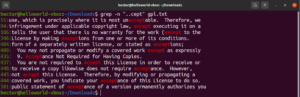
Σύμφωνα με αυτή τη regex, άλλες λέξεις όπως suscept, unaccept, unexpected, κ.λπ. είναι επίσης έγκυρες αντιστοιχίσεις.
Αγκύλες
Στις regex, οι εκφράσεις αγκυλών ορίζουν ότι στη συγκεκριμένη θέση, μπορεί να υπάρχει οποιοσδήποτε χαρακτήρας που δηλώνεται μέσα στην αγκύλη. Ρίξτε μια ματιά στην ακόλουθη συμβολοσειρά κανονικής έκφρασης:
|
1 |
t[wo]o |
Όταν εφαρμοστεί στην πράξη, οι λέξεις too και two θα είναι οι έγκυρες αντιστοιχίσεις:
|
1 |
grep -n "t[wo]o" <file> |
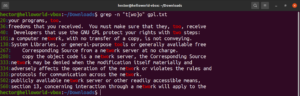
Η έκφραση αγκυλών ανοίγει τη δυνατότητα για μερικά ενδιαφέροντα πράγματα. Είναι δυνατό να χρησιμοποιήσετε εκφράσεις αγκυλών για να δηλώσετε ότι στη συγκεκριμένη θέση, μπορεί να υπάρχει οποιοσδήποτε χαρακτήρας εκτός από αυτούς που δηλώνονται μέσα στην αγκύλη. Ρίξτε μια ματιά στην ακόλουθη συμβολοσειρά regex. Η αντιστοίχιση θα είναι έγκυρη μόνο εάν υπάρχει οποιοσδήποτε χαρακτήρας εκτός από το «c» πριν από το «ode»:
|
1 |
"[^c]ode" |
Εκτελέστε το στο αρχείο κειμένου της άδειας GPL-3:
|
1 |
grep -n "[^c]ode" <file> |

Εκτός από το αποτέλεσμα από το αρχείο, άλλα έγκυρα αποτελέσματα θα ήταν node, abode, anode, κ.λπ. Οι εκφράσεις αγκυλών μπορούν επίσης να περιγράψουν ένα εύρος χαρακτήρων. Η ακόλουθη regex δηλώνει ότι η αντιστοίχιση είναι έγκυρη εάν η αρχή της γραμμής είναι κεφαλαίος χαρακτήρας:
|
1 |
"^[A-Z]" |
Εκτελέστε το στο αρχείο κειμένου της άδειας GPL-3. Θα εμφανιστούν όλες οι γραμμές του αρχείου κειμένου:
|
1 |
grep -n "^[A-Z]" <file> |
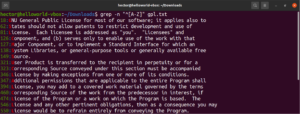
Για ευκολία στη χρήση, υπάρχουν ορισμένες κλάσεις χαρακτήρων που έχουν συγκεκριμένες ετικέτες. Στο προηγούμενο παράδειγμα, χρησιμοποιήσαμε το εύρος «A-Z» για να ορίσουμε τους κεφαλαίους χαρακτήρες. Αντ' αυτού, μπορούμε επίσης να χρησιμοποιήσουμε το «[:upper:]». Το αποτέλεσμα θα είναι το ίδιο:
|
1 |
grep -n "^[[:upper:]]" <file> |
Επανάληψη ενός μοτίβου
Σε ορισμένες περιπτώσεις, ίσως θέλετε να αντιστοιχίσετε ένα συγκεκριμένο μοτίβο ή regex μηδέν ή περισσότερες φορές. Για να το κάνετε αυτό, ο μετα-χαρακτήρας είναι ο αστερίσκος (*). Η ακόλουθη κανονική έκφραση θα αντιστοιχίσει όλες τις παρενθέσεις που περιέχουν μόνο γράμματα και μονούς χαρακτήρες διαστήματος μεταξύ τους. Σημειώστε ότι η δήλωση των συνόλων πεζών, κεφαλαίων χαρακτήρων και διαστημάτων είναι μαζί χωρίς σημεία στίξης:
|
1 |
"([a-zA-Z ]*)" |
Εφαρμόστε τη regex στην πράξη με τη grep:
|
1 |
grep -n "([A-Za-z ]*)" <file> |

Χρήση μετα-χαρακτήρων ως κυριολεκτικών χαρακτήρων
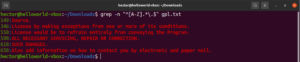
Μέχρι στιγμής, έχουμε γνωρίσει διάφορους μετα-χαρακτήρες όπως ο αστερίσκος (*), η τελεία (.), οι άγκυρες (^ και $), κ.λπ. Καθένας από αυτούς υποδηλώνει μια μοναδική λειτουργία στο πλαίσιο των regex. Το πρόβλημα προκύπτει όταν πρέπει να χρησιμοποιηθούν ως κυριολεκτικοί χαρακτήρες (literals) και όχι ως μετα-χαρακτήρες. Σε τέτοιες περιπτώσεις, η ανάστροφη κάθετος (\) μπροστά από τον μετα-χαρακτήρα θα υποδηλώνει ότι πρόκειται να χρησιμοποιηθεί με την κυριολεκτική του έννοια, όχι ως μετα-χαρακτήρας. Ρίξτε μια ματιά σε αυτό το παράδειγμα regex. Θα ταιριάξει με όλες τις γραμμές που ξεκινούν με κεφαλαίο χαρακτήρα και τελειώνουν με τελεία:
|
1 |
grep -n "^[A-Z].*\.$" <file> |
Εναλλαγή
Χρησιμοποιώντας εκφράσεις αγκυλών, μπορούμε να καθορίσουμε διαφορετικές πιθανές επιλογές για την αντιστοίχιση ενός μόνο χαρακτήρα. Η Regex έχει τη δυνατότητα να κάνει το ίδιο με λέξεις και φράσεις. Για να υποδηλωθεί μια εναλλαγή, χρησιμοποιείται ο χαρακτήρας κάθετης γραμμής (|). Οι επιλογές παραμένουν μέσα σε παρενθέσεις, ενώ ο χαρακτήρας της κάθετης γραμμής τις διαχωρίζει μεταξύ τους. Μπορεί να υπάρχουν δύο ή περισσότερες πιθανές επιλογές για να είναι έγκυρη η αντιστοίχιση. Ρίξτε μια ματιά στο ακόλουθο παράδειγμα regex. Θα ταιριάξει τόσο με το «GPL» όσο και με το «General Public License»:
|
1 |
grep -nE "(GPL|General Public License)" <file> |
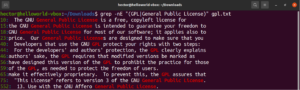
Ποσοτικοποιητές
Χρησιμοποιώντας τον μετα-χαρακτήρα αστερίσκο (*), ήμασταν σε θέση να ορίσουμε ένα μοτίβο επαναλαμβανόμενο μηδέν ή περισσότερες φορές. Ωστόσο, υπάρχουν περισσότερα εργαλεία. Είναι ευκολότερο να εξηγήσουμε τους ποσοτικοποιητές με ένα παράδειγμα. Η ακόλουθη κανονική έκφραση περιγράφει ότι τόσο το «copyright» όσο και το «right» είναι έγκυρες αντιστοιχίσεις. Το ερωτηματικό (?) υποδηλώνει ότι το τμήμα «copy» είναι προαιρετικό για την αντιστοίχιση:
|
1 |
grep -nE "(copy)?right" <file> |
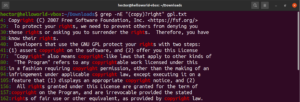
Ο επόμενος ποσοτικοποιητής είναι το σύμβολο της πρόσθεσης (+). Συμπεριφέρεται παρόμοια με τον αστερίσκο. Ωστόσο, το ορισμένο μοτίβο πρέπει να ταιριάζει τουλάχιστον μία φορά. Στο ακόλουθο παράδειγμα, η κανονική έκφραση θα ταιριάξει τη λέξη «soft» με έναν ή περισσότερους χαρακτήρες που δεν είναι κενοί:
|
1 |
grep -nE "soft[^[:space:]]+" <file> |
Καθορισμός επανάληψης αντιστοίχισης
Είναι δυνατό να καθορίσετε τον αριθμό των φορών που επαναλαμβάνεται μια αντιστοίχιση. Για να το κάνετε αυτό, χρησιμοποιήστε τις αγκύλες ({}). Η ακόλουθη κανονική έκφραση θα ταιριάξει με οποιαδήποτε λέξη περιέχει τουλάχιστον τρία φωνήεντα:
|
1 |
grep -nE "[aeiouAEIOU]{3}" <file> |

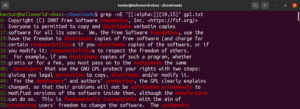
Αυτή η δυνατότητα σάς επιτρέπει επίσης να ορίσετε το κατώτερο και το ανώτερο όριο του μήκους της αντιστοίχισης. Στο ακόλουθο παράδειγμα, η regex θα ταιριάξει με οποιαδήποτε λέξη έχει μήκος 10-15 χαρακτήρες:
|
1 |
grep -nE "[[:alpha:]]{10,15}" <file> |
Συμπέρασμα
Η αναζήτηση σε αρχεία κειμένου με το grep είναι αρκετά βολική. Οι κανονικές εκφράσεις κάνουν την αναζήτηση με το grep πιο ενδιαφέρουσα και χρήσιμη. Επίσης, προσαρμόζουν με ακρίβεια το μοτίβο αναζήτησης σύμφωνα με τις επιθυμίες σας.
Αν και έχουμε παρουσιάσει μερικές από τις κοινές κανονικές εκφράσεις, αυτή είναι μόνο η αρχή. Υπάρχουν πιο προηγμένες κανονικές εκφράσεις που προσφέρουν τον καλύτερο δυνατό έλεγχο στη συμπεριφορά αναζήτησης. Εκτός από το grep, οι κανονικές εκφράσεις χρησιμοποιούνται επίσης ευρέως από άλλα εργαλεία και γλώσσες προγραμματισμού.
Καλή συνέχεια!
Σχόλια
Δεν υπάρχουν σχόλια ακόμα. Γράψτε το πρώτο.