

Web scraping, το web crawling, το web harvesting ή η εξαγωγή δεδομένων ιστού (web data extraction) είναι συνώνυμα που αναφέρονται στην πράξη της εξόρυξης δεδομένων από ιστοσελίδες στο Διαδίκτυο. Τα web scrapers ή web crawlers είναι εργαλεία που περιηγούνται σε ιστοσελίδες προγραμματιστικά, εξάγοντας τα απαιτούμενα δεδομένα. Αυτά τα δεδομένα, τα οποία είναι συνήθως μεγάλα σύνολα κειμένου, μπορούν να χρησιμοποιηθούν για αναλυτικούς σκοπούς, για την κατανόηση προϊόντων ή για την ικανοποίηση της περιέργειας κάποιου σχετικά με μια συγκεκριμένη ιστοσελίδα.
Αν αναρωτιέστε πώς μπορείτε να ξεκινήσετε με το web crawling, θα σας δείξουμε τα βασικά του web scraping μέσα από ένα απλό σύνολο δεδομένων. Θα πρέπει να είστε σε θέση να παρακολουθήσετε τον οδηγό ανεξάρτητα από το επίπεδο της προγραμματιστικής σας εμπειρίας. Για το πρακτικό παράδειγμα, θα χρησιμοποιήσουμε το δικό μας CloudSigma blog. Θα προσπαθήσουμε να λάβουμε πληροφορίες σχετικά με τους οδηγούς στη σελίδα του ιστολογίου μας. Μέχρι να διαβάσετε το συμπέρασμα αυτού του οδηγού, θα έχετε ένα λειτουργικό web scraper κατασκευασμένο με Python 3 που ανιχνεύει διάφορες σελίδες στην ενότητα του ιστολογίου μας και στη συνέχεια εμφανίζει τα δεδομένα στην οθόνη σας.
Χρησιμοποιώντας τις γνώσεις από τη δημιουργία αυτού του βασικού web scraper, μπορείτε να τις επεκτείνετε και να δημιουργήσετε τα δικά σας web scrapers. Αυτό θα έχει ενδιαφέρον, ας ξεκινήσουμε!
Προαπαιτούμενα
Αυτός είναι ένας πρακτικός οδηγός, επομένως θα πρέπει να έχετε ένα τοπικό περιβάλλον ανάπτυξης για την Python 3 για να τον παρακολουθήσετε εύκολα. Αρχικά, μπορείτε να ανατρέξετε στον οδηγό μας σχετικά με το πώς να εγκαταστήσετε την Python 3 και να ρυθμίσετε ένα τοπικό περιβάλλον προγραμματισμού στο Ubuntu.
Scrapy
Το web scraping περιλαμβάνει δύο βήματα: το πρώτο βήμα είναι η εύρεση και η λήψη ιστοσελίδων, το δεύτερο βήμα είναι η ανίχνευση και η εξαγωγή πληροφοριών από αυτές τις ιστοσελίδες.
Υπάρχουν διάφοροι τρόποι και βιβλιοθήκες που μπορούν να χρησιμοποιηθούν για τη δημιουργία ενός web scraper από το μηδέν σε πολλές γλώσσες προγραμματισμού. Ωστόσο, αυτό μπορεί να προκαλέσει προβλήματα στο μέλλον όταν το web scraper σας γίνει πολύπλοκο ή όταν χρειαστεί να ανιχνεύσετε πολλές σελίδες με διαφορετικές ρυθμίσεις και μοτίβα ταυτόχρονα. Μπορεί να είναι μια αρκετά δύσκολη εργασία να βρείτε πώς να μετατρέψετε τα δεδομένα που συλλέξατε μεταξύ διαφορετικών μορφών, όπως CSV, XML ή JSON.
Αν και ορισμένοι μπορεί να εκτιμούν την πρόκληση της δημιουργίας του δικού τους web scraper από το μηδέν, είναι καλύτερο να μην ανακαλύπτετε ξανά τον τροχό και να το δημιουργήσετε πάνω σε μια υπάρχουσα βιβλιοθήκη που χειρίζεται όλα αυτά τα ζητήματα. Θα χρησιμοποιήσουμε το Scrapy, μια βιβλιοθήκη Python, μαζί με την Python 3 για να υλοποιήσουμε το web scraper σε αυτόν τον οδηγό. Το Scrapy είναι ένα εργαλείο ανοιχτού κώδικα και μία από τις πιο δημοφιλείς και ισχυρές βιβλιοθήκες web scraping της Python. Το Scrapy δημιουργήθηκε για να χειρίζεται μερικές από τις κοινές λειτουργίες που πρέπει να έχουν όλα τα scrapers. Με αυτόν τον τρόπο δεν χρειάζεται να ανακαλύπτετε ξανά τον τροχό κάθε φορά που θέλετε να υλοποιήσετε έναν web crawler. Με το Scrapy, η διαδικασία δημιουργίας ενός scraper γίνεται εύκολη και διασκεδαστική.
Το Scrapy είναι διαθέσιμο από το PyPi, κοινώς γνωστό ως pip – το Python Package Index. Το PyPi είναι ένα αποθετήριο που ανήκει στην κοινότητα και φιλοξενεί τα περισσότερα πακέτα Python. Όταν εγκαθιστάτε και ρυθμίζετε την Python 3 στο τοπικό σας περιβάλλον ανάπτυξης, εγκαθίσταται επίσης και το pip, το οποίο μπορείτε να χρησιμοποιήσετε για να εγκαταστήσετε πακέτα Python.
Βήμα 1: Πώς να δημιουργήσετε ένα απλό Web Scraper
Αρχικά, για να εγκαταστήσετε το Scrapy, εκτελέστε την ακόλουθη εντολή:
|
1 |
pip install scrapy |
Προαιρετικά, μπορείτε να ακολουθήσετε τις επίσημες οδηγίες εγκατάστασης του Scrapy από τη σελίδα τεκμηρίωσης. Εάν έχετε εγκαταστήσει επιτυχώς το Scrapy, δημιουργήστε έναν φάκελο για το έργο χρησιμοποιώντας ένα όνομα της επιλογής σας:
|
1 |
mkdir cloudsigma-crawler |
Μεταβείτε στον φάκελο και δημιουργήστε το κύριο αρχείο για τον κώδικα. Αυτό το αρχείο θα περιέχει όλο τον κώδικα για αυτόν τον οδηγό:
|
1 |
touch main.py |
Εάν το επιθυμείτε, μπορείτε να δημιουργήσετε το αρχείο χρησιμοποιώντας το πρόγραμμα επεξεργασίας κειμένου ή το IDE σας αντί για την παραπάνω εντολή.
Στη συνέχεια, ανοίξτε το αρχείο και ας ξεκινήσουμε δημιουργώντας ένα βασικό scraper που χρησιμοποιεί το Scrapy. Θα δημιουργήσουμε μια κλάση Python που επεκτείνει το scrapy.Spider, μια βασική κλάση spider από το Scrapy. Αυτή η κλάση θα έχει δύο απαιτούμενα χαρακτηριστικά, όπως ορίζονται παρακάτω:
- name — ένα όνομα συμβολοσειράς (string) για την αναγνώριση του spider (μπορείτε να εισαγάετε ένα όνομα της επιλογής σας).
- start_urls — ένας πίνακας (array) που περιέχει μια λίστα με URL για ανίχνευση. Θα ξεκινήσουμε με ένα URL.
Προσθέστε το ακόλουθο απόσπασμα κώδικα στο ανοιχτό αρχείο για να δημιουργήσετε το βασικό spider:
|
1 2 3 4 5 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] |
Παρακάτω ακολουθεί μια εξήγηση για κάθε γραμμή κώδικα:
Η πρώτη γραμμή εισάγει το Scrapy, επιτρέποντάς μας να χρησιμοποιήσουμε τις διάφορες κλάσεις που παρέχει το πακέτο.
Στην επόμενη γραμμή, επεκτείνουμε την κλάση Spider που παρέχεται από το Scrapy και δημιουργούμε μια υποκλάση με το όνομα CloudSigmaCrawler. Επεκτείνοντας μια Κλάση (Spider), αποκτούμε πρόσβαση στις ιδιότητες της Κλάσης τις οποίες μπορούμε τώρα να χρησιμοποιήσουμε στον κώδικά μας. Σε αυτήν την περίπτωση, η κλάση Spider έχει μεθόδους και συμπεριφορές που καθορίζουν πώς να ακολουθεί URLs και να εξάγει δεδομένα από ιστοσελίδες. Ωστόσο, δεν γνωρίζει ποια URLs να ακολουθήσει ή ποια δεδομένα να εξάγει. Επεκτείνοντάς την, μπορούμε να παρέχουμε τις απαιτούμενες πληροφορίες στις μεθόδους. Για να κατανοήσετε περισσότερα σχετικά με τη δημιουργία υποκλάσεων και την επέκταση, διαβάστε παρακάτω Αρχές Αντικειμενοστρεφούς Προγραμματισμού.
Στο CloudSigmaCrawler μας, ορίζουμε τα απαιτούμενα χαρακτηριστικά. Αρχικά, ονομάζουμε το spider μας cloudsigma_crawler. Στη συνέχεια, παρέχουμε ένα μόνο URL για να ξεκινήσουμε: https://blog.cloudsigma.com/blog/. Ανοίγοντας αυτό το URL θα μεταφερθείτε στη σελίδα 1 του ιστολογίου της CloudSigma που περιέχει μερικούς από τους πολλούς οδηγούς.
Ώρα να δοκιμάσετε το scraper. Έχετε μερικές επιλογές. Εάν χρησιμοποιείτε ένα IDE, για παράδειγμα, την PyCharm community edition από την JetBrains, πιθανότατα διαθέτει ένα κουμπί που μπορείτε απλώς να κάνετε κλικ για να εκτελέσετε το σενάριο. Μια άλλη επιλογή είναι να ακολουθήσετε τον τυπικό τρόπο εκτέλεσης αρχείων Python από τη γραμμή εντολών: python path/to/file.py, ή py path/to/file.py. Μια άλλη επιλογή είναι η διεπαφή γραμμής εντολών του Scrapy. Το Scrapy διαθέτει τη δική του διεπαφή γραμμής εντολών για να βοηθήσει στην εκκίνηση ενός scraper. Εισαγάγετε την ακόλουθη εντολή για να ξεκινήσετε το scraper:
|
1 |
scrapy runspider main.py |
Ανάλογα με την έκδοση της βιβλιοθήκης Scrapy που εγκαταστήσατε, θα πρέπει να δείτε ένα αποτέλεσμα παρόμοιο με το ακόλουθο:
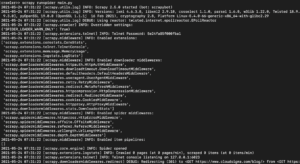
Όπως μπορείτε να δείτε, το αποτέλεσμα είναι αρκετά μεγάλο, οπότε επιλέξαμε μόνο ορισμένα μέρη. Δείτε τι συνέβη όταν εκτελέσατε την εντολή:
- Το scraper αρχικοποιήθηκε. Επομένως, φόρτωσε πρόσθετα στοιχεία και επεκτάσεις που πρέπει να χρησιμοποιήσει για να ακολουθήσει και να διαβάσει δεδομένα από URLs.
- Χρησιμοποιώντας το URL που παρέχεται στη λίστα start_urls, έλαβε το HTML από τη σελίδα. Αυτή είναι μια παρόμοια διαδικασία με αυτήν που ακολουθεί το πρόγραμμα περιήγησης κατά το άνοιγμα ιστοσελίδων.
- Μετά τη λήψη του HTML, αυτό μεταβιβάζεται στη μέθοδο parse την οποία δεν έχουμε ορίσει ακόμα. Προς το παρόν δεν κάνει τίποτα, επομένως το spider απλώς τερματίζει χωρίς να κάνει καμία επεξεργασία. Θα ορίσουμε τη συμπεριφορά της μεθόδου parse στο επόμενο βήμα.
Βήμα 2: Πώς να εξάγετε δεδομένα από μια σελίδα
Στο βήμα 1, υλοποιήσαμε μόνο ένα βασικό scraper που λαμβάνει μια σελίδα HTML αλλά δεν κάνει τίποτα μετά. Σε αυτήν την ενότητα, θα παρέχουμε οδηγίες για την εξαγωγή δεδομένων. Στη σελίδα του CloudSigma Blog από την οποία θέλουμε να εξάγουμε δεδομένα, υπάρχουν ορισμένα πράγματα που μπορείτε να παρατηρήσετε, όπως:
- Η κεφαλίδα, που υπάρχει σε όλες τις σελίδες.
- Το μενού πλοήγησης και το πλαίσιο φίλτρου αναζήτησης.
- Η πραγματική λίστα των οδηγών σε μορφή πλέγματος.
Η προβολή του πηγαίου κώδικα της σελίδας HTML που σκοπεύετε να κάνετε scrap σάς δίνει μια γενική ιδέα για τη δομή της σελίδας. Αυτό σας βοηθά στη συγγραφή ενός scraper. Μπορείτε να δείτε τον πηγαίο κώδικα κάνοντας δεξί κλικ στη σελίδα και επιλέγοντας Προβολή πηγαίου κώδικα, ή πατώντας Ctrl + U. Δείτε ένα απόσπασμα του πηγαίου κώδικα:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
<body> <div id="x-iso-container" class="x-iso-container x-iso-container-posts cols-3"> <article id="post-51691" class="post-51691 post type-post status-publish format-standard has-post-thumbnail hentry category-blog-posts category-tutorials tag-apache tag-certbot tag-cloud-guide tag-cloud-tutorial tag-https tag-lets-encrypt tag-ssl tag-ssl-certification tag-tutorial tag-ubuntu"> <div class="entry-wrap"> <header class="entry-header"> <h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Permalink to: "Ασφάλιση του Apache με το Let’s Encrypt στο Ubuntu 18.04"">Ασφάλιση του Apache με το Let’s Encrypt στο Ubuntu 18.04</a> </h2> </header> <div class="entry-content excerpt"> <p>Η ασφάλεια των ιστοτόπων και των δεδομένων είναι θέματα που δεν πρέπει να λαμβάνονται ελαφρά τη καρδία. Εξαιρετικά ευαίσθητες πληροφορίες, οι οποίες περιλαμβάνουν χρηματοοικονομικά αρχεία και προσωπικές πληροφορίες πελατών, βρίσκονται πάντα σε κίνηση μεταξύ του υπολογιστή του χρήστη και του ιστοτόπου σας. Όταν αναλογίζεστε αυτό το γεγονός, δεν είναι δύσκολο να καταλάβετε γιατί οι μη ασφαλείς ιστότοποι θα μπορούσαν να οδηγήσουν σε μια παραβίαση που θα μπορούσε να βλάψει σοβαρά την επιχείρησή σας. Υπάρχουν … </p> <div><a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="more-link">Διαβάστε Περισσότερα</a></div> </div> </div> ... </article> </div> </body> |
Όπως μπορείτε να δείτε, κάθε οδηγός ιστολογίου περικλείεται μέσα σε μια ετικέτα HTML που ονομάζεται <article>. Η εξαγωγή δεδομένων (scraping) από τη σελίδα θα περιλαμβάνει δύο βήματα. Το πρώτο βήμα θα είναι η λήψη κάθε οδηγού ιστολογίου κοιτάζοντας τα μέρη της σελίδας που περιέχουν τα δεδομένα που θέλουμε. Το επόμενο βήμα είναι να αντλήσουμε τα δεδομένα που θέλουμε από κάθε οδηγό που προσδιορίζεται από την ετικέτα HTML.
Το Scrapy αναγνωρίζει τα δεδομένα που πρέπει να συλλέξει με βάση τους επιλογείς που παρέχετε. Μπορούμε να χρησιμοποιήσουμε επιλογείς για να βρούμε ένα ή περισσότερα στοιχεία σε μια σελίδα και να λάβουμε τα δεδομένα μέσα σε αυτά τα στοιχεία. Το Scrapy υποστηρίζει XPath και CSS επιλογείς.
Από τον πηγαίο κώδικα που είδαμε νωρίτερα, οι επιλογείς CSS φαίνεται να είναι ευκολότεροι. Επομένως, αυτή θα είναι η επιλογή με την οποία θα προχωρήσουμε, καθώς θα μας βοηθήσει να βρούμε όλους τους οδηγούς στη σελίδα. Από τον πηγαίο κώδικα HTML, κάθε οδηγός καθορίζεται μέσα στην κλάση CSS που ονομάζεται post. Τα ονόματα κλάσεων CSS συνήθως αναγνωρίζονται με .class_name (τελεία class_name). Έτσι, θα χρησιμοποιήσουμε το .post για τον επιλογέα CSS μας. Μέσα στον πηγαίο κώδικα του scraper main.py, θα περάσουμε την κλάση .post στο αντικείμενο response, έτσι ώστε το αρχείο σας να μοιάζει πλέον με αυτό:
|
1 2 3 4 5 6 7 8 9 10 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): pass |
Αυτό το απόσπασμα κώδικα θα πάρει όλα τα μαθήματα στη σελίδα με τα καθορισμένα start_urls και θα κάνει επανάληψη μέσω των μαθημάτων για να εξαγάγει δεδομένα. Στο επόμενο βήμα θα θέλετε να εξαγάγετε και να εμφανίσετε αυτά τα δεδομένα. Εάν εξετάσετε ξανά τον πηγαίο κώδικα του CloudSigma blog, θα δείτε ξανά ότι ο τίτλος κάθε μαθήματος είναι αποθηκευμένος μέσα σε μια ετικέτα <a> που βρίσκεται μέσα σε μια ετικέτα <h2>, για παράδειγμα:
|
1 2 3 4 5 |
<h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Permalink to: "Securing Apache with Let’s Encrypt on Ubuntu 18.04"">Securing Apache with Let’s Encrypt on Ubuntu 18.04</a> </h2> |
Κάθε αντικείμενο tutorial στο οποίο κάνουμε επανάληψη περιέχει μια μέθοδο CSS στην οποία μπορούμε να περάσουμε έναν επιλογέα για να εντοπίσουμε και να εξαγάγουμε θυγατρικά στοιχεία. Για αυτό το παράδειγμα, θέλουμε να εξαγάγουμε τον τίτλο που περικλείεται μέσα στην ετικέτα <a>. Αυτή η ετικέτα βρίσκεται μέσα στην ετικέτα <h2> μέσα στην κλάση .entry-header μέσα στην κλάση .entry-wrap. Μπορούμε να περάσουμε αυτούς τους επιλογείς CSS στη μέθοδο του αντικειμένου για να εξαγάγουμε τον τίτλο, τροποποιώντας τον κώδικα ώστε να μοιάζει με αυτόν:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), } |
Το κόμμα στο τέλος μετά το extract_first() δεν είναι τυπογραφικό λάθος, καθώς θα προσθέσουμε περισσότερο κώδικα κάτω από αυτήν την ενότητα.
Μερικά σημεία που πρέπει να σημειωθούν από τον παραπάνω πηγαίο κώδικα περιλαμβάνουν:
- Το ::text που προσαρτάται στον επιλογέα – αυτό είναι ένα CSS pseudo-selector που καθοδηγεί τον κώδικα να ανακτήσει το κείμενο μέσα στην ετικέτα και όχι την ίδια την ετικέτα.
- Η κλήση της μεθόδου extract_first() μέσα στο αντικείμενο – καθοδηγεί τον κώδικα να επιλέξει μόνο το πρώτο στοιχείο που ταιριάζει με τον επιλογέα. Επομένως, λαμβάνουμε μια συμβολοσειρά αντί για μια λίστα στοιχείων.
Στη συνέχεια, αποθηκεύστε το αρχείο και εκτελέστε τον κώδικα εισάγοντας την ακόλουθη εντολή στο τερματικό σας:
|
1 |
scrapy runspider main.py |
Στο αποτέλεσμα, θα πρέπει να δείτε τους τίτλους των οδηγών:
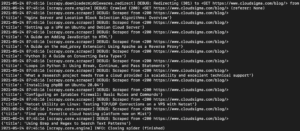
Μπορούμε να συνεχίσουμε να το επεκτείνουμε προσθέτοντας περισσότερους επιλογείς για να λάβουμε άλλες λεπτομέρειες σχετικά με έναν οδηγό, όπως το URL του οδηγού, την προτεινόμενη εικόνα και τη λεζάντα.
Ας εξετάσουμε ξανά τον κώδικα HTML για έναν μεμονωμένο οδηγό:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
<body> <div id="x-iso-container" class="x-iso-container x-iso-container-posts cols-3"> <article id="post-51691" class="post-51691 post type-post status-publish format-standard has-post-thumbnail hentry category-blog-posts category-tutorials tag-apache tag-certbot tag-cloud-guide tag-cloud-tutorial tag-https tag-lets-encrypt tag-ssl tag-ssl-certification tag-tutorial tag-ubuntu"> <div class="entry-featured"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="entry-thumb" title="Μόνιμος σύνδεσμος προς: "Ασφάλιση του Apache με το Let’s Encrypt σε Ubuntu 18.04""> <img width="1000" height="522" src="data:image/svg+xml,%3Csvg%20xmlns='http://www.w3.org/2000/svg'%20viewBox='0%200%201000%20522'%3E%3C/svg%3E" class="attachment-entry-fullwidth size-entry-fullwidth wp-post-image" alt="Let’s Encrypt" loading="lazy" data-lazy-srcset="/media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04.jpg 1000w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-300x157.jpg 300w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-768x401.jpg 768w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-610x318.jpg 610w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-100x52.jpg 100w" data-lazy-sizes="(max-width: 1000px) 100vw, 1000px" data-lazy-src="/media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04.jpg"/> </a> </div> <div class="entry-wrap"> <header class="entry-header"> <h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Permalink to: "Securing Apache with Let’s Encrypt on Ubuntu 18.04"">Ασφάλιση Apache με Let’s Encrypt σε Ubuntu 18.04</a> </h2> </header> <div class="entry-content excerpt"> <p>Η ασφάλεια του ιστότοπου και των δεδομένων είναι θέματα που δεν πρέπει να λαμβάνονται ελαφρά τη καρδία. Εξαιρετικά ευαίσθητες πληροφορίες οι οποίες περιλαμβάνουν οικονομικά αρχεία και ιδιωτικές πληροφορίες πελατών βρίσκονται πάντα σε κίνηση μεταξύ του υπολογιστή του χρήστη και του ιστότοπού σας. Όταν αναλογίζεστε αυτό το γεγονός, δεν είναι δύσκολο να καταλάβετε γιατί οι μη ασφαλείς ιστότοποι θα μπορούσαν να οδηγήσουν σε παραβίαση που θα μπορούσε να βλάψει σοβαρά την επιχείρησή σας. Υπάρχουν μερικοί … </p> <div><a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="more-link">Διαβάστε περισσότερα</a></div> </div> </div> </article> </div> </body> |
Θέλουμε να προσπαθήσουμε να εξαγάγουμε τα επισημασμένα κομμάτια, δηλαδή τη διεύθυνση URL του οδηγού, την προβεβλημένη εικόνα και τη λεζάντα.
- Από το παραπάνω απόσπασμα κώδικα, η εικόνα για το ιστολόγιο είναι αποθηκευμένη μέσα στο χαρακτηριστικό data-lazy-src μιας ετικέτας img μέσα σε μια ετικέτα <a> μέσα σε μια ετικέτα div στην αρχή του οδηγού του ιστολογίου. Μπορούμε να χρησιμοποιήσουμε έναν επιλογέα CSS για να πάρουμε την τιμή όπως κάναμε με τους τίτλους των οδηγών.
- Η λήψη της διεύθυνσης URL του οδηγού είναι απλή, καθώς έχουμε την ετικέτα <a> μέσα στο στοιχείο <div>.
- Η λεζάντα περικλείεται μέσα στην ετικέτα <p> η οποία βρίσκεται μέσα στην ετικέτα <div>.
Θα χρησιμοποιήσουμε τις κλάσεις CSS για να πάρουμε αυτό που θέλουμε. Ας τροποποιήσουμε τον κώδικα ώστε να μοιάζει με αυτό:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), 'caption': tutorial.css(CAPTION_SELECTOR).extract_first(), } |
Αποθηκεύστε τις αλλαγές και εκτελέστε τον κώδικα με την ακόλουθη εντολή:
|
1 |
scrapy runspider main.py |
Θα δείτε περισσότερα δεδομένα στο αποτέλεσμα, όπως το URL, την εικόνα και τη λεζάντα που προσθέσαμε:

Αυτά είναι όλα για το crawling μιας μεμονωμένης σελίδας. Στη συνέχεια, ας δούμε πώς μπορούμε να δημιουργήσουμε ένα scraper που ακολουθεί συνδέσμους.
Βήμα 3: Πώς να κάνετε Crawl σε πολλαπλές σελίδες
Μέχρι αυτό το σημείο, έχουμε δημιουργήσει ένα scraper που μπορεί να λάβει δεδομένα από μια μεμονωμένη σελίδα. Ωστόσο, θέλουμε περισσότερα από αυτό. Θέλετε ένα spider που μπορεί να ακολουθεί συνδέσμους και να εξάγει δεδομένα από πολλαπλές σελίδες ενός ιστότοπου προγραμματιστικά.
Αν πάτε στο κάτω μέρος της σελίδας του ιστολογίου της CloudSigma, θα παρατηρήσετε τους συνδέσμους σελιδοποίησης και ένα μικρό βέλος που δείχνει προς τα δεξιά, υποδεικνύοντας την επόμενη σελίδα. Δείτε το απόσπασμα κώδικα HTML:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<div class="x-pagination"> <ul class="center-list center-text"> <li><span class="pages">Σελίδα 1 από 45</span></li> <li></li> <li><span class="current">1</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/2/" class="single_page" title="2">2</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="single_page" title="3">3</a></li> <li><span class="expand">...</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/45/" class="last" title="Τελευταία Σελίδα">45</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/2/" class="prev-next hidden-phone">→</a></li> </ul> </div> |
Το απόσπασμα δείχνει αρκετούς συνδέσμους πλοήγησης σελίδων μέσα σε ετικέτες <li>, κάτω από την ετικέτα <div> με την κλάση CSS .x-pagination. Η εστίασή μας είναι στον σύνδεσμο που δείχνει προς την επόμενη σελίδα. Βρίσκεται στην ετικέτα <a> του τελευταίου <li> στην ετικέτα <ul>.
Ο σύνδεσμος που δείχνει προς την επόμενη σελίδα έχει την κλάση .prev-next μέσα στην ετικέτα <a>, όπως φαίνεται στο παραπάνω απόσπασμα. Ωστόσο, αν μεταβείτε στην επόμενη σελίδα, θα παρατηρήσετε επίσης ότι οι σύνδεσμοι προς την προηγούμενη και την επόμενη σελίδα έχουν αυτήν την κλάση CSS. Δείτε αυτό το απόσπασμα για τη Σελίδα 2:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<div class="x-pagination"> <ul class="center-list center-text"> <li><span class="pages">Σελίδα 2 από 45</span></li> <li><a href="https://blog.cloudsigma.com/blog/" class="prev-next hidden-phone">←</a></li> <li><a href="https://blog.cloudsigma.com/blog/" class="single_page" title="1">1</a></li> <li><span class="current">2</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="single_page" title="3">3</a></li> <li><span class="expand">...</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/45/" class="last" title="Τελευταία Σελίδα">45</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="prev-next hidden-phone">→</a></li> </ul> </div> |
Αν χρησιμοποιήσουμε τη μέθοδο extract_first() του Scrapy, θα λειτουργήσει στην πρώτη σελίδα. Όταν φτάσει στην επόμενη σελίδα, θα επιλέξει τον πρώτο σύνδεσμο με την κλάση .prev-next, ο οποίος στο παραπάνω απόσπασμα δείχνει στην πρώτη σελίδα. Αυτό θα οδηγήσει σε έναν βρόχο (loop). Επομένως, θα χρησιμοποιήσουμε τη μέθοδο extract() του Scrapy. Αυτή η μέθοδος εξάγει όλα τα στοιχεία που ταιριάζουν με μια περίπτωση χρήσης και τα τοποθετεί σε έναν πίνακα (array). Από αυτόν τον πίνακα, μπορούμε να επιλέξουμε το τελευταίο στοιχείο το οποίο θα περιέχει τον πραγματικό σύνδεσμο που δείχνει στην επόμενη σελίδα. Τροποποιήστε τον κώδικά σας ώστε να μοιάζει κάπως έτσι:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), } NEXT_PAGE_SELECTOR = '.x-pagination > ul.center-list > li > a.prev-next::attr("href")' next_page = response.css(NEXT_PAGE_SELECTOR).extract() if next_page: yield scrapy.Request( response.urljoin(next_page[-1]), callback=self.parse ) |
Ας δούμε αναλυτικά τον κώδικα για την επιλογή του next_page.
Ορίζουμε πρώτα έναν επιλογέα για τους συνδέσμους της επόμενης και της προηγούμενης σελίδας. Στη συνέχεια χρησιμοποιούμε τη μέθοδο extract() για να εξαγάγουμε τα URL και να τα τοποθετήσουμε σε έναν πίνακα. Η μεταβλητή next_page θα είναι ένας πίνακας με δύο στοιχεία όπως:
|
1 |
next_page = [prev_page_url, next_page_url] |
Εφόσον πλοηγούμαστε στην επόμενη σελίδα, θα επιλέξουμε το τελευταίο στοιχείο του πίνακα. Το next_page[-1] επιλέγει το τελευταίο στοιχείο του πίνακα.
Το μπλοκ if ελέγχει αν η μεταβλητή next_page περιέχει κάτι και στη συνέχεια καλεί τη μέθοδο scrapy.Request(). Στον κώδικά μας, δίνουμε εντολή σε αυτή τη μέθοδο να ανιχνεύσει τη σελίδα με το παρεχόμενο URL και να τη μεταβιβάσει πίσω στη μέθοδο parse(), ώστε να μπορέσουμε να την αναλύσουμε για να εξαγάγουμε τα δεδομένα και να επαναλάβουμε τη διαδικασία για την επόμενη σελίδα. Αυτή η διαδικασία επαναλαμβάνεται μέχρι να μην βρεθεί σύνδεσμος για την επόμενη σελίδα, ή μάλλον αν το μπλοκ αποτύχει, τότε σταματά.
Αποθηκεύστε τον κώδικά σας και εκτελέστε τον. Θα παρατηρήσετε ότι η επανάληψη συνεχίζει να διατρέχει τις σελίδες καθώς βρίσκει περισσότερες σελίδες για scraping. Με αυτόν τον τρόπο ορίζετε έναν scraper που ακολουθεί συνδέσμους σε έναν ιστότοπο. Το παράδειγμά μας είναι αρκετά απλό. Απλώς μεταβαίνουμε σε μια σελίδα, βρίσκουμε τον σύνδεσμο για την επόμενη σελίδα και επαναλαμβάνουμε τη διαδικασία. Σε άλλες περιπτώσεις χρήσης, ίσως θέλετε να ακολουθήσετε ετικέτες ή συνδέσμους που οδηγούν σε εξωτερικές πηγές και άλλα. Δείτε τον ολοκληρωμένο πηγαίο κώδικα για τον βασικό web scraper σε Python 3:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), 'caption': tutorial.css(CAPTION_SELECTOR).extract_first(), } NEXT_PAGE_SELECTOR = '.x-pagination > ul.center-list > li > a.prev-next::attr("href")' next_page = response.css(NEXT_PAGE_SELECTOR).extract() if next_page: yield scrapy.Request( response.urljoin(next_page[-1]), callback=self.parse ) |
Συμπέρασμα
Σε αυτόν τον οδηγό, δημιουργήσαμε έναν βασικό web scraper που μπορεί να ανιχνεύσει το CloudSigma blog κατάλογο και να εμφανίσει ορισμένες πληροφορίες σχετικά με τους οδηγούς του blog σε περίπου 27 γραμμές κώδικα μόνο.
Φυσικά, αυτό είναι δυνατό επειδή το δημιουργήσαμε πάνω στη βιβλιοθήκη Scrapy της Python. Αυτό είναι μόνο μια βάση που θα σας βοηθήσει να δημιουργήσετε πιο περίπλοκους scrapers που ακολουθούν περισσότερες ετικέτες, αποτελέσματα αναζήτησης ιστότοπων και πολλά άλλα. Μπορείτε να ανατρέξετε στα επίσημα έγγραφα του Scrapy για περισσότερες πληροφορίες σχετικά με την εργασία με το Scrapy.
Καλή υπολογιστική!
Σχόλια
Δεν υπάρχουν σχόλια ακόμα. Γράψτε το πρώτο.