

Python je vysokoúrovňový, univerzální programovací jazyk s důrazem na čitelnost kódu. Podporuje různá programovací paradigmata, například strukturované, objektově orientované a funkcionální programování. Python je často popisován jako “batteries included”, a to díky své komplexní standardní knihovně.
V tomto návodu se naučíme různé způsoby, jak v Pythonu odstranit bílé znaky (mezery) z řetězce.
Požadavky
K provedení kroků popsaných v tomto návodu budete potřebovat následující komponenty:
-
- Správně nakonfigurovaný stroj s Linuxem, například Ubuntu VPS na CloudSigma.
-
- Správně nakonfigurované vývojové prostředí pro Python. Podívejte se na konfiguraci vývojového prostředí Pythonu na Ubuntu.
-
- Vhodný textový editor, například Brackets, VS Code, Sublime Text, Vim/NeoVim atd.
Krok 1 – Vytvoření Python skriptu
Pro demonstrační účely vytvoříme Python skript remove-space.py a vložíme do něj veškerý náš kód. Poté skript spustíme pomocí interpretu Pythonu.
Nejprve vytvořte Python skript:
|
1 |
touch remove-space.py |

Otevřete skript v textovém editoru:
|
1 |
nano remove-space.py |
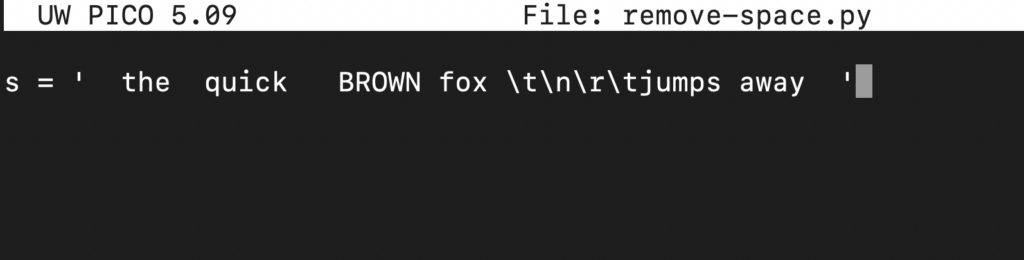
Dále vytvoříme řetězcovou proměnnou s a přiřadíme jí řetězec:
|
1 |
s = ' the quick BROWN fox \t\n\r\tjumps away ' |
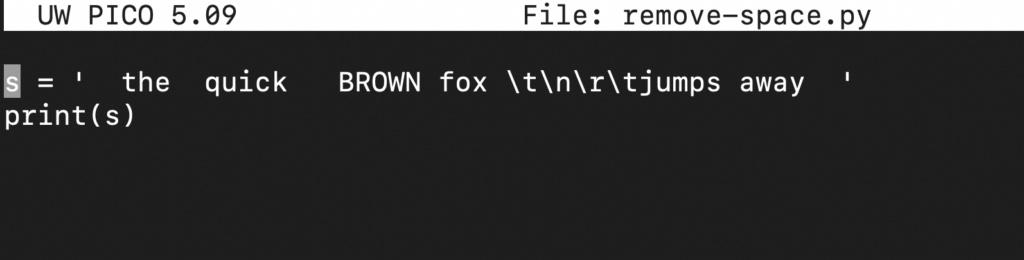
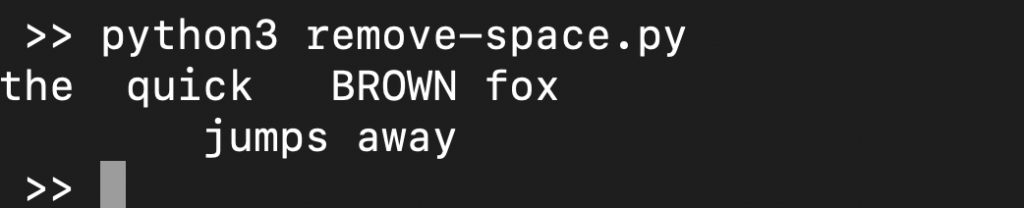
Pokud zahrneme print() funkci, uvidíme, jak je řetězec interpretován:
|
1 2 |
s = ' the quick BROWN fox \t\n\r\tjumps away ' print(s) |
Zde,
-
- Funkce
print()přijímá řetězec jako argument.
- Funkce
-
- Funkce
print()dokáže interpretovat znaky se zpětným lomítkem.
- Funkce
Spusťte skript:
|
1 |
python remove-space.py |

Krok 2 – Odstranění počátečních a koncových mezer
Pomocí funkce strip() můžeme odstranit počáteční a koncové znaky řetězce.
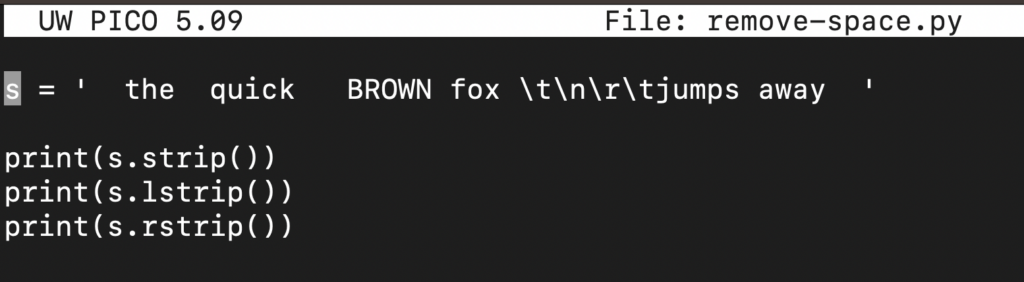
Následující kód ukazuje použití funkce strip() na proměnné s:
|
1 2 |
s = ' the quick BROWN fox \t\n\r\tjumps away ' print(s.strip()) |
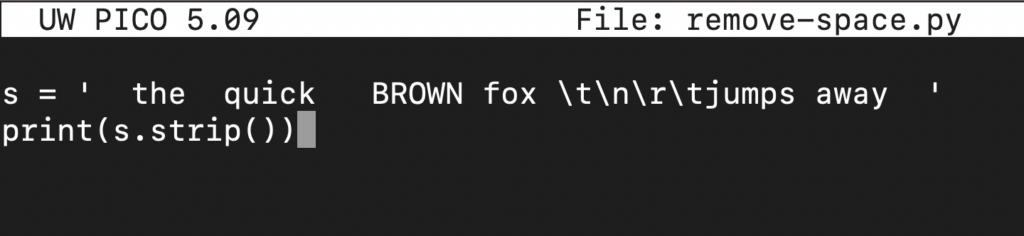
Všimněte si, že funkce strip() odstraňuje všechny počáteční a koncové mezery. Pokud chcete odstranit pouze počáteční nebo koncové mezery, použijte lstrip() nebo rstrip() v tomto pořadí:
|
1 2 3 4 5 |
s = ' the quick BROWN fox \t\n\r\tjumps away ' print(s.strip()) print(s.lstrip()) print(s.rstrip()) |
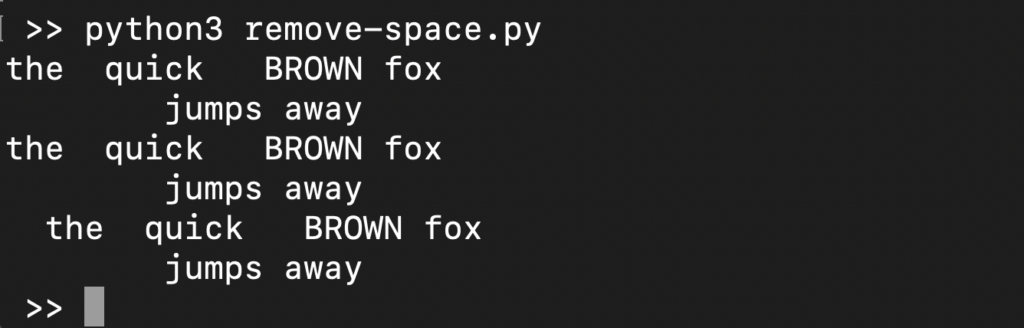
Krok 3 – Odstranění všech bílých znaků
Pomocí funkce replace() můžeme nahradit obsah v řetězci. Využitím této funkce můžeme nahradit všechny bílé znaky prázdným řetězcem, a tím je odstranit.
Pojďme uvést funkci replace() do praxe. Podívejte se na následující kód:
|
1 2 3 |
s = ' the quick BROWN fox \t\n\r\tjumps away ' print(s.replace(" ", "")) |
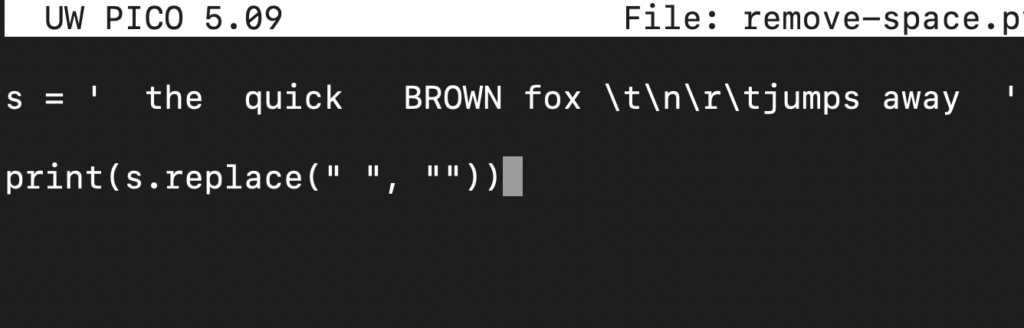

Zde,
-
- První parametr funkce
replace()určuje, jaký vzor se má v daném řetězci hledat.
- První parametr funkce
-
- Druhý parametr funkce
replace()určuje, jaký bude náhradní obsah.
- Druhý parametr funkce
Krok 4 – Odstranění bílých znaků pomocí split() a join()
V této části budeme používat funkce split() a join().
-
split(): Vezme řetězec a rozdělí ho na seznam. Body rozdělení jsou určeny oddělovačem.
-
join(): Vezme seznam a spojí ho zpět do jednoho řetězce. Části jsou spojeny pomocí jednoho bílého znaku (” “).
Pojďme tyto funkce uvést do praxe. Podívejte se na následující kód:
|
1 2 3 |
s = ' the quick BROWN fox \t\n\r\tjumps away ' print(" ".join(s.split())) |
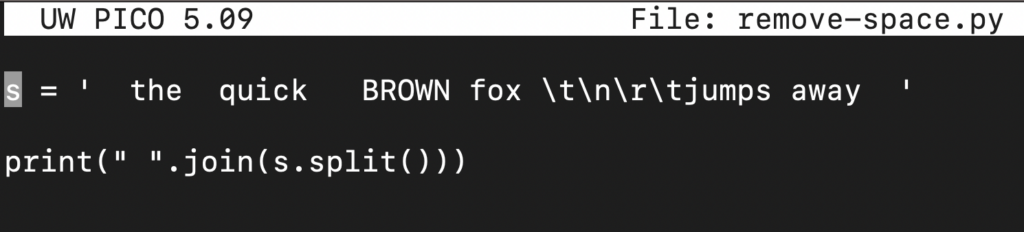
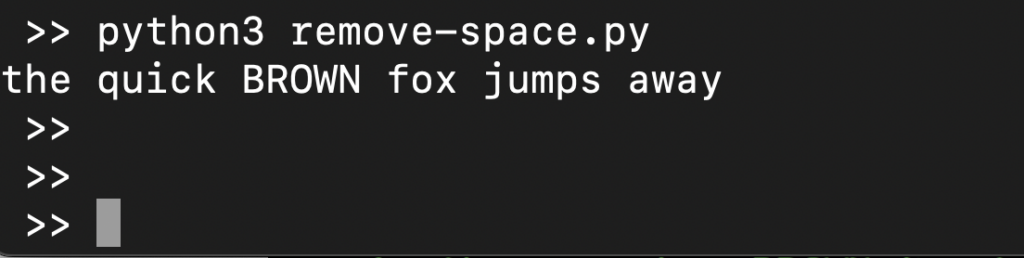
Zde,
-
- Zkombinovali jsme použití
split(),join(), aprint()na jednom řádku.
- Zkombinovali jsme použití
-
- Výstup funkce
split()je předán jako argument pro funkcijoin().
- Výstup funkce
-
- Výstup funkce
join()funkce se předává jako argument proprint()funkci.
- Výstup funkce
Step 5 – Odstranění bílých znaků pomocí translate()
V Pythonu funkce translate() nahrazuje zadané znaky znaky definovanými ve slovníku nebo mapovací tabulce.
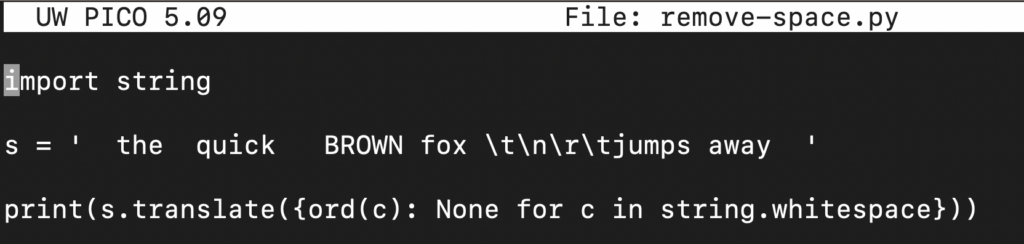
V tomto příkladu použijeme slovník string.whitespace, který obsahuje všechny bílé znaky.
Podívejte se na následující kód:
|
1 2 3 4 5 |
import string s = ' the quick BROWN fox \t\n\r\tjumps away ' print(s.translate({ord(c): None for c in string.whitespace})) |

Step 6 – Odstranění bílých znaků pomocí regulárních výrazů
Regulární výraz (zkráceně “regex”) je mocná funkce v mnoha programovacích jazycích. Každý regulární výraz se skládá z řady znaků, které tvoří vyhledávací vzor. Regulární výraz lze použít ke kontrole, zda řetězec obsahuje zadaný vzor.
Python také podporuje regex, což výrazně zlepšuje jeho možnosti manipulace s textem. V této části použijeme regex k odstranění jakéhokoli bílého znaku nalezeného v našem testovacím řetězci.
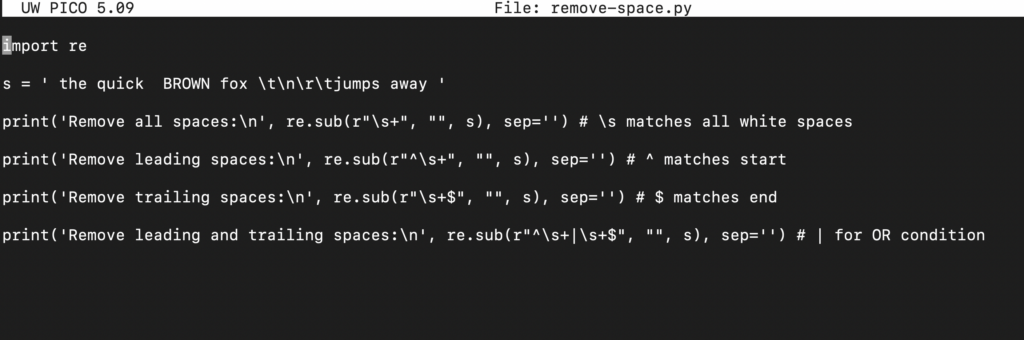
Podívejte se na následující kód:
|
1 2 3 4 5 6 7 8 9 10 11 |
import re s = ' the quick BROWN fox \t\n\r\tjumps away ' print('Odstranit všechny mezery:\n', re.sub(r"\s+", "", s), sep='') # \s odpovídá všem bílým znakům print('Odstranit počáteční mezery:\n', re.sub(r"^\s+", "", s), sep='') # ^ odpovídá začátku print('Odstranit koncové mezery:\n', re.sub(r"\s+$", "", s), sep='') # $ odpovídá konci print('Odstranit počáteční a koncové mezery:\n', re.sub(r"^\s+|\s+$", "", s), sep='') # | pro podmínku NEBO |
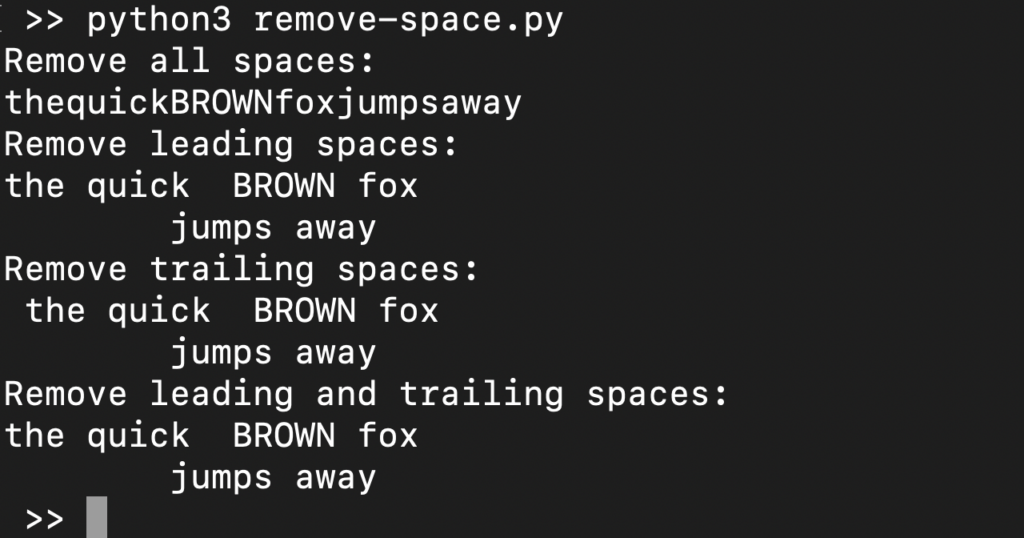
Zde,
-
- Importujeme
re, což je specializovaný balíček pro práci s regulárními výrazy.
- Importujeme
Závěr
V této příručce jsme si ukázali různé způsoby, jak se v Pythonu vypořádat s bílými znaky v řetězci. Během toho jsme se také naučili jednoduché použití různých funkcí jako split(), join(), replace(), translate(), atd.
Máte zájem dozvědět se o Pythonu více? Podívejte se na následující příručky:
Komentáře
Zatím žádné komentáře. Buďte první.