

Podnikání s sebou nese velké množství dat, což ztěžuje jejich zpracování a správu. Tradičně se v tomto odvětví po celá desetiletí používaly systémy RDBMS, ale s příchodem Big Data v 21. století se na scéně objevily databáze NoSQL (Not only SQL) pro rozsáhlá nestrukturovaná a polostrukturovaná data.
V tomto příspěvku se chystám nastavit cluster MongoDB.
MongoDB je bezplatná a open-source NoSQL dokumentová databáze, která je široce používána díky vysoké úrovni škálovatelnosti a flexibility, kterou poskytuje.
Pro nasazení MongoDB v produkčním prostředí se doporučuje použít replikační sady (Replica Sets). Replikační sady jsou v MongoDB ekvivalentem nastavení Master/Slave v relačním světě, ale na rozdíl od něj je jejich nastavení velmi bezproblémové, protože vše je již vestavěné. Více informací o replikačních sadách naleznete v definici procesu replikace od TutorialsPoint’s.
Plánování vašeho cloudového serverového clusteru MongoDB
Chystám se vytvořit cluster se 3 uzly. Je důležité poskytnout jim stejné prostředky, protože kterýkoli z nich se může stát primárním (tj. master) serverem. Tyto uzly nebo stroje mohou běžet na jakémkoli operačním systému, ale v tomto návodu budu používat Ubuntu 18.04 LTS. Informace o tom, jak připojit a nastavit předinstalovaný obraz z knihovny CloudSigma’s, naleznete v tomto návodu.
Vzhledem k tomu, že celým smyslem replikační sady je, aby cluster přežil výpadek jednoho uzlu, bylo by poněkud bezpředmětné, kdyby všechny vaše servery běžely na stejném fyzickém hostiteli. CloudSigma naštěstí nabízí funkci nazvanou skupiny dostupnosti. To znamená, že můžete systému přikázat, aby seskupil všechny tři vaše servery do různých skupin. Tím zajistíte, že nikdy nebudou umístěny na stejném fyzickém hostiteli. Více informací o této a dalších funkcích pro zabezpečení a kontinuitu podnikání naleznete zde.
Důležité je také použít 64bitovou verzi Linuxu. Důvodem je jednoduše to, že MongoDB neběží dobře na 32bitových systémech (více o tom zde).
Instalace MongoDB v cloudu
Tato část je poměrně jednoduchá. Buď použijte jeden z předem nakonfigurovaných Ubuntu 18.04 obrazů, nebo si jej nainstalujte sami.
Konfigurace procesoru, paměti RAM a disku je opravdu individuální a závisí na vaší zátěži. Pro menší instalaci by měl stačit procesor 4 GHz, 4 GB RAM a 10 GB disk (pro systém). Při připojování disků se ujistěte, že používáte VirtIO. Pokud použijete IDE, výkon tím výrazně utrpí. Vzhledem k tomu, že vytváříte replikační sadu, musíte mít také všechny uzly (a aplikační servery) ve stejné VLAN.
Na rozdíl od mnoha jiných poskytovatelů cloudových služeb není pro zvýšení výkonu nutné konfigurovat úložiště pomocí RAID10 nebo podobně. Jak uvádí mnoho našich klientů, získáte u CloudSigma úžasný výkon ihned po vybalení, a to jak při použití SSD, tak magnetických disků.
Přesto doporučuji uchovávat data MongoDB na samostatném disku. Důvodem je jednoduše to, že v určitém okamžiku možná budete muset provést některé optimalizace souborového systému, které byste nechtěli provádět na celém souborovém systému.
S ohledem na to je nejjednodušší tento disk přidat až po nastavení serverů. Prozatím se zaměřme pouze na instalaci systému. Pokud instalaci provádíte sami (místo použití předem nakonfigurovaných systémů), doporučuji v bootovací nabídce stisknout klávesu F4 a vybrat ‘Install a minimal virtual machine’.
Vytvářím 3 stroje, každý s následující specifikací:
- CPU: 4 GHz
- RAM: 4 GB
- SSD: 10 GB (Ubuntu 18.04 LTS), 20 GB (disk navíc)
Jak je uvedeno v části o SSD, připojuji disk o velikosti 10 GB s nainstalovaným systémem Ubuntu 18.04 LTS.
Kromě toho k němu připojuji další prázdný disk o velikosti 20 GB pro ukládání dat MongoDB. Velikost velmi závisí na vašem využití, ale pro malý systém by 20 GB mělo pravděpodobně stačit. Protože je však někdy těžké předpovědět, kolik dat budete ukládat, použijeme LVM. To vám umožní jednoduše přidat další disk později a rozšířit svazek, aniž byste museli začínat znovu. Případně můžete použít jeden disk a později jej zvětšit pomocíresize2fs.
Chcete-li disk přidat, přejděte do sekce ‘Drives’, klikněte na ikonu ‘Create a new drive’ nahoře, pojmenujte nový disk a nastavte jeho velikost na 20 GB. Jakmile je uložen, přejděte k jednotlivému stroji, ke kterému jej chcete připojit, a v sekci disků v podrobnostech o tomto stroji mohu kliknout na ‘Attach a drive’ a vybrat disk.
Nyní, když máte tři stroje, můžete přejít k připojení dalšího disku, který jste přidali pro ukládání dat MongoDB, ke každému stroji. Doporučuji přidat tento disk jako oddíl. Použití rozdělení na oddíly umožňuje operačnímu systému spravovat informace v každé oblasti samostatně. Pro přidání disku jako oddílu nejprve zkontroluji všechny disky připojené k našemu stroji. Za tímto účelem spustím následující příkaz:
|
1 |
fdisk -l |
Při spuštění příkazu získám výstup uvádějící disky a zařízení na mém stroji.
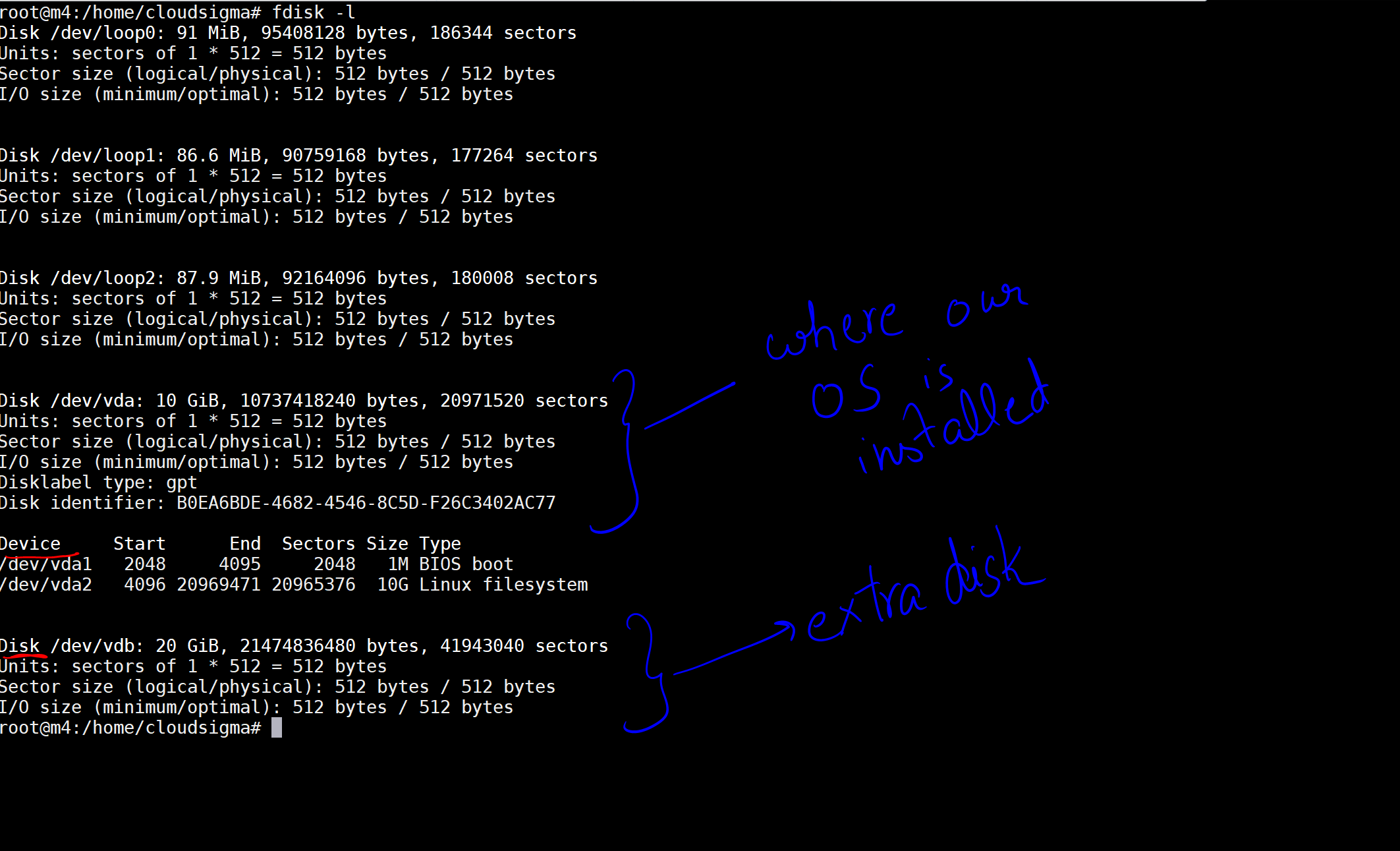
Na obrázku jsem označil 10 GB disk jako ten, kde je nainstalován náš operační systém. Poté je zde další disk o velikosti 20 GB, který byl nyní připojen. Umístění disku je /dev/vdb. Na tomto disku můžete vytvořit oddíl pomocí následujících příkazů:
|
1 |
sudo fdisk /dev/vdb |
Otevře se nástroj fdisk, nástroj příkazové řádky, který poskytuje funkce pro rozdělení disku, ve kterém můžete vytvářet oddíly na našem disku. Zobrazí se výzva “Command (m for help):”, kde musíte zadat n pro vytvoření nového oddílu a poté stačí stisknout enter pro přijetí výchozích hodnot. A poté, co vytvoří oddíl, zadejte w pro zápis změn. Bude to vypadat takto:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
Příkaz (m pro nápovědu): <strong>n</strong> Oddíl typ p primární (0 primární, 0 rozšířený, 4 volný) e rozšířený (kontejner pro logické oddíly) Vybrat (výchozí p): Použití výchozí odpověď p. Oddíl číslo (1-4, výchozí 1): První sektor (2048-41943039, výchozí 2048): Poslední sektor, +sektory nebo +velikost{K,M,G,T,P} (2048-41943039, výchozí 41943039): Vytvořen a nový oddíl 1 typu type 'Linux' a o velikosti 20 GiB. Příkaz (m pro nápovědu): <strong>w</strong> Tabulka oddílů byla změněnabeen altered. Volání ioctl() pro opětovné-načtení tabulky oddílů. Synchronizace disků. |
Byl vytvořen nový oddíl 1 typu ‘Linux’ a o velikosti 20 GiB. Nyní, když je oddíl vytvořen, vytvořme LVM pool:
|
1 2 3 |
sudo pvcreate /dev/vdb1 sudo vgcreate mongodb /dev/vdb1 sudo lvcreate -n db -L 19.5g mongodb |
Zadal jsem ‘19.5g’, protože velikost mého oddílu je 20g. Dále spusťte následující příkaz, abyste zjistili název disku:
|
1 |
fdisk -l | grep mongo | awk '{print $2'} |
Poté naformátujte disk pomocí metody ext4 následujícím příkem:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
sudo mkfs.ext4 /dev/mapper/mongodb-db Výstup: root@m4:/home/cloudsigma# sudo mkfs.ext4 /dev/mapper/mongodb-db mke2fs 1.44.1 (24-Bře-2018) Vytváření souborového systému s 5217280 4k bloky a 1305600 inody Souborový systém UUID: 695a62e6-021d-4fc0-945c-cc51a92d86da Superblokové zálohy uloženy na blocích: 32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208, 4096000 Alokování skupinových tabulek: hotovo Zápis inode tabulek: hotovo Vytváření žurnálových (32768 bloků): hotovo Zápis superbloků a informací o využití souborového systému: hotovo |
Dále vytvořme místo pro připojení disku a složku, do které se budou ukládat data MongoDB.
|
1 |
sudo mkdir -p /mongodb/data |
Chcete-li do souboru fstab přidat záznam o novém disku, který má být připojen, můžete přímo použít níže uvedený příkaz:
|
1 |
echo -e "` blkid | grep mongodb | awk {'print $2'}`\t/mongodb\text4 auto,noexec,rw,sync,nouser\t0\t0" >> /etc/fstab |
V tomto příkazu blkid poskytuje UUID – univerzálně jedinečný identifikátor každého disku. Zde vyfiltruji ten pro disk MongoDB a zkombinuji toto UUID s umístěním složky pro připojení, typem souborového systému a dalšími možnostmi disku. Tento řádek přidávám do /etc/fstab. Pokud to neuděláte, při připojování disku dojde k chybě. Záznam vypadá takto:
UUID=”695a62e6-021d-4fc0-945c-cc51a92d86da” /mongodb ext4 auto,noexec,rw,sync,nouser 0 0
Nyní můžete disk připojit do umístění /mongodb:
|
1 |
sudo mount /mongodb |
Instalace MongoDB
S připraveným systémem přejděme k instalaci MongoDB. Přestože Ubuntu nabízí verzi MongoDB ve svém vlastním repozitáři, doporučuji místo toho použít oficiální verzi MongoDB. Důvodem je, že repozitář Ubuntu je ve vydáních poměrně pozadu, takže pokud chcete z MongoDB vytěžit maximum, budete se muset obrátit na oficiální vydání.
Vzhledem k tomu, že MongoDB nabízí svůj vlastní repozitář, můžete jej jednoduše přidat do svého systému a poté nainstalovat MongoDB běžným způsobem. Postupujte podle následujících kroků:
Nejprve importujte veřejný klíč používaný systémem správy balíčků:
|
1 |
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 9DA31620334BD75D9DCB49F368818C72E52529D4 |
Poté vytvořím soubor seznamu. Ten bude obsahovat repozitář, kde se MongoDB nachází, aby jej váš systém mohl odtud stáhnout:
|
1 |
echo "deb [ arch=amd64 ] https://repo.mongodb.org/apt/ubuntu bionic/mongodb-org/4.0 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-4.0.list |
Nyní aktualizuji svou lokální databázi balíčků, abych zohlednil změny.
|
1 |
sudo apt-get update |
Nyní mohu balíček nainstalovat pomocí následujícího příkazu:
|
1 |
sudo apt-get install -y mongodb-org |
Nainstaloval jsem MongoDB na každý ze strojů.
|
1 |
sudo service mongod start |
Nyní je MongoDB spuštěna a běží, přičemž data na disku jsou vytvořena. Pokud se očekává vysoké zatížení a/nebo velké množství připojení, možná budete muset zvýšit hodnoty ulimit hodnoty.
Pokud chcete získat lepší přehled o svých datech, možná se budete chtít zaregistrovat do služby MMS od MongoDB, což je bezplatná cloudová monitorovací služba pro MongoDB.
Vytvoření replikační sady pro váš MongoDB Cloud
Nyní vytvořme replikační sadu. Předtím se musíte ujistit, že každý ze strojů může komunikovat s ostatními. Za tímto účelem přidejte tyto záznamy do /etc/hosts
|
1 2 3 |
IP-1 m1.mongo.cluster m1 IP-2 m2.mongo.cluster m2 IP-3 m3.mongo.cluster m3 |
Pro ověření můžete zkusit pingnout stroje pomocí názvu hostitele. Pokud je tedy IP adresa mého stroje 1’s je IP-1, řekněme 213.189.123.12, pak místo psaní
|
1 |
ping 123.189.123.12 |
napíšu,
|
1 2 3 |
ping m1.mongo.cluster nebo ping m1. |
Pokud jste aktivovali firewall (což byste opravdu měli), ujistěte se, že uzly mohou odesílat a přijímat TCP provoz na portech 28017 a 27017 na interním rozhraní.
Nyní na každém ze strojů spusťte službu mongod pomocí následujících příkazů.
Na stroji m1,
|
1 |
mongod --dbpath /mongodb/data --replSet rs0 --bind_ip localhost,m1.mongo.cluster |
Dále na stroji m2,
|
1 |
mongod --dbpath /mongodb/data --replSet rs0 --bind_ip localhost,m2.mongo.cluster |
Na stroji m3,
|
1 |
mongod --dbpath /mongodb/data --replSet rs0 --bind_ip localhost,m3.mongo.cluster |
Zde,
mongod je název služby
dbpath je umístění adresáře naší databáze
replSet je název naší replikační sady. Měl by být stejný pro každý ze strojů ve stejné replikační sadě
bind_ip je název hostitele daného stroje, na kterém jej spouštíte.
Jakmile spustíte službu mongod, přejděte na primární server (v mém případě jsem zvolil m1) a spusťte mongo.
|
1 |
mongo |
Tím se spustí terminál MongoDB. V terminálu inicializujte replicaSet pomocí níže uvedeného příkazu. Vytvoří se replicaSet s výchozí konfigurací:
|
1 |
rs.initiate() |
Nyní přidejme další dva stroje jako repliky pomocí následujících příkazů:
|
1 2 |
rs.add("m2.mongo.cluster") rs.add("m3.mongo.cluster") |
Stav můžete sledovat pomocí příkazu:
|
1 |
rs.status() |
To je opravdu vše. Nyní byste měli mít spuštěný a funkční MongoDB cluster na bleskově rychlém cloudu CloudSigma’s.
Komentáře
Zatím žádné komentáře. Buďte první.