

Web scraping, web crawling, web harvesting nebo web data extraction jsou synonyma označující činnost dolování dat z webových stránek na internetu. Webové scrapery nebo webové crawlery jsou nástroje, které programově procházejí webové stránky a extrahují požadovaná data. Tato data, což jsou obvykle velké sady textu, lze použít pro analytické účely, k porozumění produktům nebo k uspokojení zvědavosti o určité webové stránce.
Pokud vás zajímá, jak na web crawling, ukážeme vám základy web scrapingu na jednoduché sadě dat. Tento návod byste měli být schopni sledovat bez ohledu na úroveň vašich programátorských znalostí. Pro praktický příklad použijeme náš blog CloudSigma. Pokusíme se získat informace o návodech na naší blogové stránce. Než dočtete závěr tohoto návodu, budete mít funkční webový scraper vytvořený v Pythonu 3, který prochází několik stránek v naší sekci blogu a poté zobrazuje data na vaší obrazovce.
S využitím znalostí z vytvoření tohoto základního webového scraperu jej můžete rozšířit a vytvořit si vlastní webové scrapery. Měla by to být zábava, začněme!
Požadavky
Jedná se o praktický návod, takže byste měli mít lokální vývojové prostředí pro Python 3, abyste mohli dobře postupovat. Nejprve se můžete podívat na náš návod, jak nainstalovat Python 3 a nastavit lokální programovací prostředí na Ubuntu.
Scrapy
Web scraping zahrnuje dva kroky: prvním krokem je nalezení a stažení webových stránek, druhým krokem je jejich procházení a extrahování informací z těchto webových stránek.
Existuje řada způsobů a knihoven, které lze použít k vytvoření webového scraperu od nuly v mnoha programovacích jazycích. To však může v budoucnu přinést problémy, až se váš webový scraper stane složitým nebo když budete potřebovat procházet více stránek s různým nastavením a vzory najednou. Může být docela náročné přijít na to, jak transformovat získaná data mezi různými formáty, jako je CSV, XML nebo JSON.
Zatímco někteří mohou ocenit výzvu postavit si vlastní webový scraper od nuly, je lepší nevymýšlet znovu kolo a raději jej postavit na základech existující knihovny, která všechny tyto problémy řeší. Budeme používat Scrapy, knihovnu pro Python, společně s Pythonem 3 k implementaci webového scraperu v tomto návodu. Scrapy je open-source nástroj a jedna z nejpopulárnějších a nejvýkonnějších knihoven pro web scraping v Pythonu. Scrapy byl vytvořen tak, aby zvládal některé běžné funkce, které by měly mít všechny scrapery. Tímto způsobem nemusíte znovu vymýšlet kolo, kdykoli chcete implementovat webový crawler. Se Scrapy se proces vytváření scraperu stává snadným a zábavným.
Scrapy je k dispozici na PyPi, běžně známém jako pip – Python Package Index. PyPi je komunitní repozitář, který hostuje většinu balíčků pro Python. Když nainstalujete a nastavíte Python 3 ve svém lokálním vývojovém prostředí, nainstaluje se také pip, který můžete použít k instalaci balíčků pro Python.
Krok 1: Jak vytvořit jednoduchý webový scraper
Nejprve pro instalaci Scrapy spusťte následující příkaz:
|
1 |
pip install scrapy |
Volitelně můžete postupovat podle oficiálních pokynů k instalaci Scrapy na stránce dokumentace. Pokud jste úspěšně nainstalovali Scrapy, vytvořte složku pro projekt s názvem podle vašeho výběru:
|
1 |
mkdir cloudsigma-crawler |
Přejdete do složky a vytvořte hlavní soubor pro kód. Tento soubor bude obsahovat veškerý kód pro tento návod:
|
1 |
touch main.py |
Pokud si přejete, můžete soubor vytvořit pomocí textového editoru nebo IDE namísto výše uvedeného příkazu.
Dále otevřete soubor a začněme vytvořením základního scraperu, který používá Scrapy. Vytvoříme třídu v Pythonu, která rozšiřuje scrapy.Spider, základní třídu spideru ze Scrapy. Tato třída bude mít dva požadované atributy definované níže:
- name — řetězec pro identifikaci spideru (můžete zadat libovolný název).
- start_urls — pole obsahující seznam URL adres, ze kterých se má začít procházet. Začneme s jednou URL adresou.
Chcete-li vytvořit základního spidera, přidejte do otevřeného souboru následující fragment kódu:
|
1 2 3 4 5 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] |
Níže je vysvětlení každého řádku kódu:
První řádek importuje Scrapy, což nám umožňuje používat různé třídy, které tento balíček poskytuje.
Na dalším řádku rozšiřujeme třídu Spider poskytovanou knihovnou Scrapy a vytváříme podtřídu s názvem CloudSigmaCrawler. Rozšířením třídy (Spider) získáme přístup k vlastnostem této třídy, které nyní můžeme použít v našem kódu. V tomto případě má třída Spider metody a chování, které definují, jak sledovat adresy URL a extrahovat data z webových stránek. Neví však, které adresy URL má sledovat ani jaká data má extrahovat. Jejím rozšířením můžeme metodám poskytnout požadované informace. Chcete-li se dozvědět více o vytváření podtříd a rozšiřování, čtěte dále principy objektově orientovaného programování.
V našem CloudSigmaCrawler definujeme požadované atributy. Nejprve pojmenujeme našeho spidera cloudsigma_crawler. Poté zadáme jednu počáteční URL adresu: https://blog.cloudsigma.com/blog/. Otevřením této URL adresy se dostanete na 1. stránku blogu CloudSigma, která obsahuje některé z mnoha návodů.
Je čas otestovat scraper. Máte několik možností. Pokud používáte IDE, například PyCharm community edition od společnosti JetBrains, pravděpodobně obsahuje tlačítko, na které stačí kliknout pro spuštění skriptu. Další možností je klasický způsob spouštění Python souborů z příkazové řádky: python cesta/k/souboru.py nebo py cesta/k/souboru.py. Další možností je příkazové rozhraní Scrapy. Scrapy přichází s vlastním rozhraním příkazové řádky, které pomáhá se spuštěním scraperu. Pro spuštění scraperu zadejte následující příkaz:
|
1 |
scrapy runspider main.py |
V závislosti na nainstalované verzi knihovny Scrapy byste měli vidět výstup podobný následujícímu:
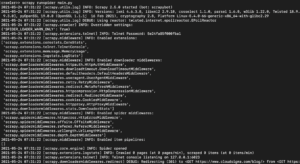
Jak vidíte, výstup je poměrně dlouhý, proto jsme vybrali pouze některé části. Zde je popis toho, co se stalo po spuštění příkazu:
- Scraper byl inicializován. Proto načetl další komponenty a rozšíření, které potřebuje k sledování a čtení dat z URL adres.
- Pomocí URL adresy uvedené v seznamu start_urls stáhl HTML kód stránky. Jedná se o podobný proces, jaký provádí prohlížeč při otevírání webových stránek.
- Po stažení HTML je toto předáno metodě parse, kterou jsme však ještě nedefinovali. Zatím nic nedělá, takže spider se pouze ukončí bez jakéhokoli zpracování. Chování metody parse definujeme v dalším kroku.
Krok 2: Jak extrahovat data ze stránky
V kroku 1 jsme implementovali pouze základní scraper, který stáhne HTML stránku, ale poté nic nedělá. V této části si ukážeme pokyny pro extrakci dat. Na stránce CloudSigma Blog, ze které chceme data extrahovat, si můžete všimnout několika věcí, jako jsou:
- Hlavička, která je přítomna na všech stránkách.
- Navigační menu a vyhledávací filtr.
- Samotný seznam návodů ve formátu mřížky.
Zobrazení zdrojového kódu HTML stránky, kterou chcete scrapovat, vám poskytne obecnou představu o její struktuře. To vám pomůže při psaní scraperu. Zdrojový kód můžete zobrazit kliknutím pravým tlačítkem myši na stránku a výběrem možnosti Zobrazit zdrojový kód, nebo stisknutím kláves Ctrl + U. Zde je ukázka zdrojového kódu:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
<body> <div id="x-iso-container" class="x-iso-container x-iso-container-posts cols-3"> <article id="post-51691" class="post-51691 post type-post status-publish format-standard has-post-thumbnail hentry category-blog-posts category-tutorials tag-apache tag-certbot tag-cloud-guide tag-cloud-tutorial tag-https tag-lets-encrypt tag-ssl tag-ssl-certification tag-tutorial tag-ubuntu"> <div class="entry-wrap"> <header class="entry-header"> <h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Trvalý odkaz na: "Zabezpečení Apache pomocí Let’s Encrypt na Ubuntu 18.04"">Zabezpečení Apache pomocí Let’s Encrypt na Ubuntu 18.04</a> </h2> </header> <div class="entry-content excerpt"> <p>Bezpečnost webových stránek a dat jsou témata, která nelze brát na lehkou váhu. Vysoce citlivé informace, které zahrnují finanční záznamy a soukromé informace zákazníků, se neustále přenášejí mezi počítačem uživatele a vaším webem. Když vezmete v úvahu tuto skutečnost, není těžké pochopit, proč by nezabezpečené webové stránky mohly vést k narušení bezpečnosti, které by mohlo vážně poškodit vaše podnikání. Existuje … </p> <div><a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="more-link">Číst více</a></div> </div> </div> ... </article> </div> </body> |
Jak vidíte, každý návod na blogu je uzavřen v HTML tagu nazvaném <article>. Scrapování stránky bude zahrnovat dva kroky. Prvním krokem bude získání každého návodu na blogu vyhledáním částí stránky, které obsahují data, jež chceme. Dalším krokem je vytáhnout požadovaná data z každého návodu identifikovaného HTML tagem.
Scrapy identifikuje data, která má získat, na základě selektorů, které poskytnete. Selektory můžeme použít k nalezení jednoho nebo více prvků na stránce a získání dat v rámci těchto prvků. Scrapy podporuje XPath a CSS selektory.
Ze zdrojového kódu, který jsme si prohlédli dříve, se zdají být CSS selektory jednodušší. Proto zvolíme tuto možnost, protože nám pomůže najít všechny návody na stránce. V HTML zdrojovém kódu je každý návod specifikován v rámci CSS třídy nazvané post. Názvy CSS tříd se obvykle identifikují pomocí .class_name (tečka class_name). Pro náš CSS selektor tedy použijeme .post. V našem zdrojovém kódu scraperu main.py předáme třídu .post objektu response, takže váš soubor bude nyní vypadat takto:
|
1 2 3 4 5 6 7 8 9 10 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): pass |
Tento fragment kódu stáhne všechny návody na stránce se zadanými start_urls a projde je ve smyčce, aby extrahoval data. V dalším kroku budete chtít tato data extrahovat a zobrazit. Pokud znovu prozkoumáte zdrojový kód blogu CloudSigma, uvidíte, že název každého návodu je uložen v tagu <a>, který je uvnitř tagu <h2>, například:
|
1 2 3 4 5 |
<h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Permalink to: "Securing Apache with Let’s Encrypt on Ubuntu 18.04"">Zabezpečení Apache pomocí Let’s Encrypt na Ubuntu 18.04</a> </h2> |
Každý objekt návodu, který procházíme, obsahuje metodu CSS, které můžeme předat selektor pro vyhledání a extrahování podřízených prvků. V tomto příkladu chceme extrahovat název, který je uzavřen uvnitř tagu <a>. Tento tag se nachází uvnitř tagu <h2> uvnitř třídy .entry-header uvnitř třídy .entry-wrap. Tyto CSS selektory můžeme předat metodě objektu pro extrahování názvu, upravte kód tak, aby vypadal takto:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), } |
Koncová čárka za extract_first() není překlep, protože pod tuto sekci budeme přidávat další kód.
Mezi body, které stojí za zmínku ve výše uvedeném zdrojovém kódu, patří:
- ::text připojený k selektoru – jedná se o CSS pseudo-selektor , který kódu říká, aby načetl text uvnitř tagu, a nikoli tag samotný.
- volání metody extract_first() v rámci objektu – instruuje kód, aby vybral pouze první prvek, který odpovídá selektoru. Díky tomu získáme řetězec namísto seznamu prvků.
Dále soubor uložte a spusťte kód zadáním následujícího příkazu do terminálu:
|
1 |
scrapy runspider main.py |
Ve výstupu byste měli vidět názvy tutoriálů:
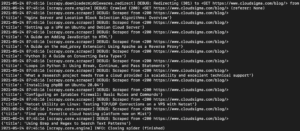
Můžeme to dále rozšiřovat přidáváním dalších selektorů, abychom získali další podrobnosti o tutoriálu, jako je URL tutoriálu, náhledový obrázek a popisek.
Pojďme se znovu podívat na HTML kód pro jeden tutoriál:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
<body> <div id="x-iso-container" class="x-iso-container x-iso-container-posts cols-3"> <article id="post-51691" class="post-51691 post type-post status-publish format-standard has-post-thumbnail hentry category-blog-posts category-tutorials tag-apache tag-certbot tag-cloud-guide tag-cloud-tutorial tag-https tag-lets-encrypt tag-ssl tag-ssl-certification tag-tutorial tag-ubuntu"> <div class="entry-featured"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="entry-thumb" title="Trvalý odkaz na: "Zabezpečení Apache pomocí Let’s Encrypt na Ubuntu 18.04""> <img width="1000" height="522" src="data:image/svg+xml,%3Csvg%20xmlns='http://www.w3.org/2000/svg'%20viewBox='0%200%201000%20522'%3E%3C/svg%3E" class="attachment-entry-fullwidth size-entry-fullwidth wp-post-image" alt="Let’s Encrypt" loading="lazy" data-lazy-srcset="/media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04.jpg 1000w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-300x157.jpg 300w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-768x401.jpg 768w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-610x318.jpg 610w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-100x52.jpg 100w" data-lazy-sizes="(max-width: 1000px) 100vw, 1000px" data-lazy-src="/media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04.jpg"/> </a> </div> <div class="entry-wrap"> <header class="entry-header"> <h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Permalink to: "Zabezpečení Apache pomocí Let’s Encrypt na Ubuntu 18.04"">Zabezpečení Apache pomocí Let’s Encrypt na Ubuntu 18.04</a> </h2> </header> <div class="entry-content excerpt"> <p>Zabezpečení webových stránek a dat jsou témata, která nelze brát na lehkou váhu. Vysoce citlivé informace, které zahrnují finanční záznamy a soukromé informace zákazníků, jsou neustále přenášeny mezi počítačem uživatele a vaším webem. Když vezmete v úvahu tuto skutečnost, není těžké pochopit, proč by nezabezpečené webové stránky mohly vést k narušení bezpečnosti, které by mohlo vážně poškodit vaše podnikání. Existuje … </p> <div><a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="more-link">Číst dál</a></div> </div> </div> </article> </div> </body> |
Chceme se pokusit extrahovat zvýrazněné části, tj. URL návodu, náhledový obrázek a popisek.
- Z výše uvedeného fragmentu kódu je zřejmé, že obrázek pro blog je uložen uvnitř atributu data-lazy-src značky img uvnitř značky <a> uvnitř značky div na začátku návodu k blogu. K získání této hodnoty můžeme použít CSS selektor, stejně jako jsme to udělali u názvů návodů.
- Získání URL návodu je jednoduché, protože máme značku <a> uvnitř elementu <div>.
- Popisek je uzavřen uvnitř značky <p>, která je uvnitř značky <div>.
K získání toho, co chceme, použijeme CSS třídy. Upravme kód tak, aby vypadal následovně:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), 'caption': tutorial.css(CAPTION_SELECTOR).extract_first(), } |
Uložte změny a spusťte kód pomocí následujícího příkazu:
|
1 |
scrapy runspider main.py |
Ve výstupu uvidíte více dat, jako je URL, obrázek a popisek, které jsme přidali:

To je pro procházení jedné stránky vše. Dále se podívejme na to, jak můžeme vytvořit scraper, který sleduje odkazy.
Krok 3: Jak procházet více stránek
Až do tohoto okamžiku jsme vytvořili scraper, který dokáže získat data z jedné stránky. My však chceme víc. Chcete spidera, který dokáže programově sledovat odkazy a extrahovat data z více stránek webu.
Pokud přejdete na konec stránky blogu CloudSigma, všimnete si odkazů na stránkování a malé šipky ukazující doprava, která označuje další stránku. Zde je ukázka kódu HTML:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<div class="x-pagination"> <ul class="center-list center-text"> <li><span class="pages">Stránka 1 z 45</span></li> <li></li> <li><span class="current">1</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/2/" class="single_page" title="2">2</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="single_page" title="3">3</a></li> <li><span class="expand">...</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/45/" class="last" title="Poslední stránka">45</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/2/" class="prev-next hidden-phone">→</a></li> </ul> </div> |
Ukázka ukazuje několik odkazů pro navigaci na stránce v rámci značek <li>, pod značkou <div> s třídou CSS .x-pagination. Zaměřujeme se na odkaz ukazující na další stránku. Nachází se ve značce <a> posledního <li> ve značce <ul>.
Odkaz ukazující na další stránku má třídu .prev-next v rámci značky <a>, jak je vidět v ukázce výše. Pokud se však přesunete na další stránku, všimnete si také, že odkazy na předchozí a další stránku mají tuto třídu CSS. Zvažte tuto ukázku pro stránku 2:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<div class="x-pagination"> <ul class="center-list center-text"> <li><span class="pages">Strana 2 z 45</span></li> <li><a href="https://blog.cloudsigma.com/blog/" class="prev-next hidden-phone">←</a></li> <li><a href="https://blog.cloudsigma.com/blog/" class="single_page" title="1">1</a></li> <li><span class="current">2</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="single_page" title="3">3</a></li> <li><span class="expand">...</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/45/" class="last" title="Poslední strana">45</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="prev-next hidden-phone">→</a></li> </ul> </div> |
Pokud použijeme metodu Scrapy extract_first(), bude fungovat na první stránce. Jakmile se dostane na další stránku, vybere první odkaz s třídou .prev-next, který ve výše uvedeném fragmentu kódu ukazuje na první stránku. To povede k nekonečné smyčce. Proto použijeme metodu Scrapy extract(). Tato metoda extrahuje všechny prvky odpovídající danému případu použití a vloží je do pole. Z tohoto pole pak můžeme vybrat poslední prvek, který bude obsahovat skutečný odkaz ukazující na další stránku. Upravte svůj kód tak, aby vypadal následovně:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), } NEXT_PAGE_SELECTOR = '.x-pagination > ul.center-list > li > a.prev-next::attr("href")' next_page = response.css(NEXT_PAGE_SELECTOR).extract() if next_page: yield scrapy.Request( response.urljoin(next_page[-1]), callback=self.parse ) |
Pojďme si projít kód pro výběr next_page.
Nejprve definujeme selektor pro odkazy na další a předchozí stránku. Poté použijeme metodu extract() k extrahování URL adres a jejich vložení do pole. Proměnná next_page bude pole se dvěma prvky jako:
|
1 |
next_page = [prev_page_url, next_page_url] |
Protože přecházíme na další stránku, vybereme poslední prvek v poli. Next_page[-1] vybere poslední prvek v poli.
Blok if kontroluje, zda proměnná next_page něco obsahuje, a pokud ano, zavolá metodu scrapy.Request(). V našem kódu této metodě přikážeme, aby prošla stránku s poskytnutou URL adresou a předala ji zpět metodě parse(), abychom ji mohli analyzovat, extrahovat data a opakovat proces pro další stránku. Tento proces se opakuje, dokud nenajde odkaz na další stránku, respektive pokud blok selže, pak se zastaví.
Uložte kód a spusťte jej. Všimnete si, že iterace pokračuje v procházení stránek, jakmile najde další stránky ke scrapování. Takto byste definovali scraper, který sleduje odkazy na webu. Náš příklad je poměrně přímočarý. Pouze přejdeme na stránku, najdeme odkaz na další stránku a proces opakujeme. V jiných případech použití můžete chtít sledovat tagy nebo odkazy, které ukazují na externí zdroje a další. Zde je kompletní zdrojový kód pro základní webový scraper v Pythonu 3:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), 'caption': tutorial.css(CAPTION_SELECTOR).extract_first(), } NEXT_PAGE_SELECTOR = '.x-pagination > ul.center-list > li > a.prev-next::attr("href")' next_page = response.css(NEXT_PAGE_SELECTOR).extract() if next_page: yield scrapy.Request( response.urljoin(next_page[-1]), callback=self.parse ) |
Závěr
V tomto návodu jsme vytvořili jednoduchý web scraper, který dokáže procházet blog CloudSigma adresář a zobrazit některé informace o návodech na blogu v pouhých přibližně 27 řádcích kódu.
To je samozřejmě možné, protože jsme jej postavili na Python knihovně Scrapy. Toto je pouze základ, který by vám měl pomoci vytvořit složitější scrapery, které sledují více tagů, výsledky vyhledávání na webových stránkách a další. Můžete se podívat na oficiální dokumentaci Scrapy pro více informací o práci se Scrapy.
Příjemné programování!
Komentáře
Zatím žádné komentáře. Buďte první.