

Příkaz sed je zkratka pro stream editor (proudový editor). Je to velmi populární nástroj v systémech Linux/UNIX. Sed sám o sobě není textový editor. Dokáže však provádět různé úpravy pro manipulaci se zadaným textem. Textový vstup je odesílán jako proud. Sed poté provede na tomto proudu instrukce. Tato příručka poskytuje přehled o příkazu sed a o tom, jak s ním pracovat, abyste mohli úspěšně manipulovat s textem v Linuxu.
Sed v Linuxu
Vstupní proud příkazu sed může pocházet buď z textového souboru, nebo ze STDIN (standardního vstupu). Můžeme pracovat s výstupem jiného příkazu nebo přímo s textovým souborem. Nástroj sed je předinstalován ve všech Linux distribucích.
Přehled použití příkazu Sed
Příkaz sed má následující strukturu:
|
1 |
$ sed <options> <commands> <file> |
Pro demonstrační účely jsme stáhli textovou verzi licence GPL verze 3:
|
1 |
$ wget https://www.gnu.org/licenses/gpl-3.0.txt |

Následující příkaz sed vytiskne obsah textového souboru:
|
1 |
$ sed '' gpl-3.0.txt |
V tomto případě sed provádí operace popsané v jednoduchých uvozovkách a tiskne výstup. Vzhledem k tomu, že není definována žádná volba, sed jednoduše provede prázdnou operaci a vytiskne celý obsah souboru.
Sed také přijímá výstup z jiného příkazu jako vstupní proud. V následujícím příkladu přesměrujte obsah textového souboru GPL v3 do příkazu sed pro provedení prázdné operace:
|
1 |
$ cat gpl-3.0.txt | sed '' |
Jak tisknout řádky
Bez zadání jakékoli volby vytiskne sed veškerý obsah souboru přímo. Místo toho můžeme explicitně odeslat příkaz k tisku, který vytiskne výsledky přímo na standardní výstup (STDOUT).
Chcete-li výstup vytisknout, použijte znak p:
|
1 |
$ sed 'p' gpl-3.0.txt |
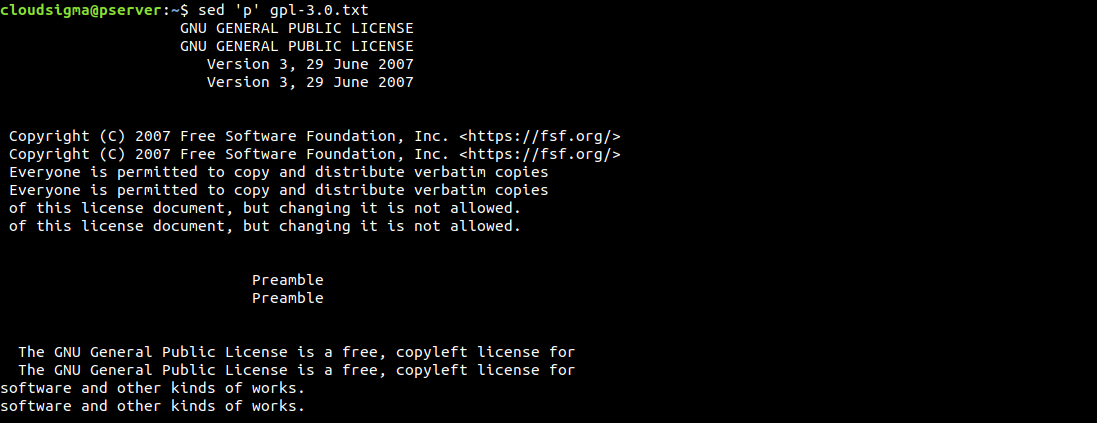
Ve výchozím nastavení tiskne sed výstup na obrazovku. Protože jsme konkrétně použili příkaz pro tisk, sed vytiskne každý řádek dvakrát. Sed pracuje řádek po řádku. Přečte jeden řádek, provede konkrétní operace, vytiskne jej a přejde na další řádek.
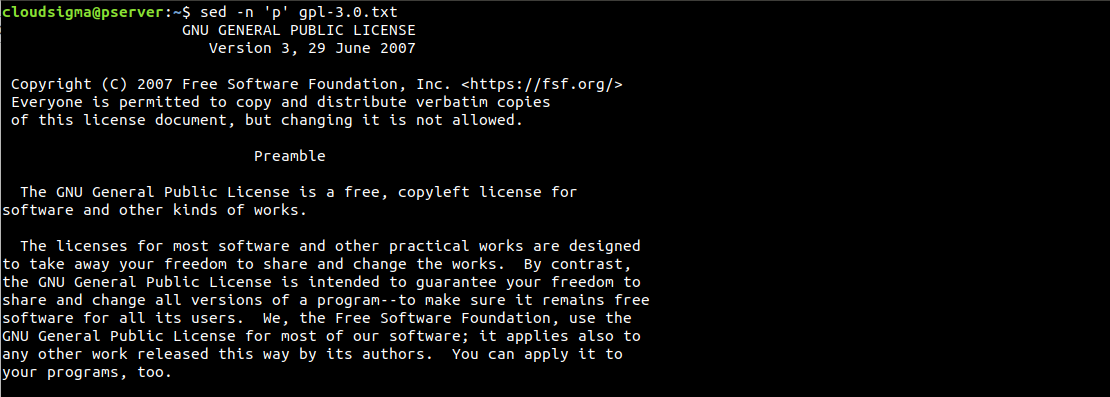
Jak vidíme, každý řádek je vytištěn dvakrát. Pokud je výsledek takto matoucí, můžeme jej vyčistit pomocí volby -n. Ta potlačuje funkci automatického tisku. Protože posíláme příkaz k tisku, nepotřebujeme mít povolenou výchozí funkci tisku výstupu:
|
1 |
$ sed -n 'p' gpl-3.0.txt |
Třídy znaků v regulárních výrazech
V regulárních výrazech existují různé třídy znaků. Každá z těchto tříd má svůj rozsah. Mnoho tříd má také více výrazů. Většina tříd jsou rozsahy znaků:
-
- [a-z]: Malé písmeno
-
- [A-Z]: Velké písmeno
-
- [0-9]: Číslice
-
- [a-zA-z]: Abeceda
-
- [a-zA-z0-9]: Jakýkoli alfanumerický znak
Tyto třídy znaků mají také různé zápisy:
-
- [:lower:]: Malé písmeno
-
- [:upper:]: Velké písmeno
-
- [:digit:]: Číslice
-
- [:alpha:]: Abeceda
-
- [:alphanum:]: Alfanumerický znak
Například následující příkaz vytiskne všechny řádky, které obsahují alespoň jednu číslici:
|
1 |
$ sed -n 's/[[:digit:]]/&/p' gpl-3.0.txt |
Rozsahy adres
Můžeme určit konkrétní část textového proudu, se kterou chceme pracovat. Může to být statické umístění řádku nebo rozsah řádků. V prvním příkladu vytiskneme řádek 5 z textového souboru GPL v3:
|
1 |
$ sed -n '5p' gpl-3.0.txt |

Místo jednoho řádku můžeme také určit rozsah řádků, se kterými se má pracovat. Zde jsme zadali rozsah adres od řádku 5 do řádku 9 (celkem 5 řádků), na kterých bude sed pracovat:
|
1 |
$ sed -n '5,9p' gpl-3.0.txt |

Existují také různé způsoby zadání adresy řádku. Místo toho, abychom sami určovali čísla řádků, můžeme předchozí příklad upravit tak, aby sed začal od řádku 5 a pracoval na následujících 5 řádcích:
|
1 |
$ sed -n '5,+5p' gpl-3.0.txt |

Dalším způsobem, jak určit řádky, je použití intervalů. V následujícím příkladu sed začne od řádku 1 a bude pracovat na každém druhém řádku:
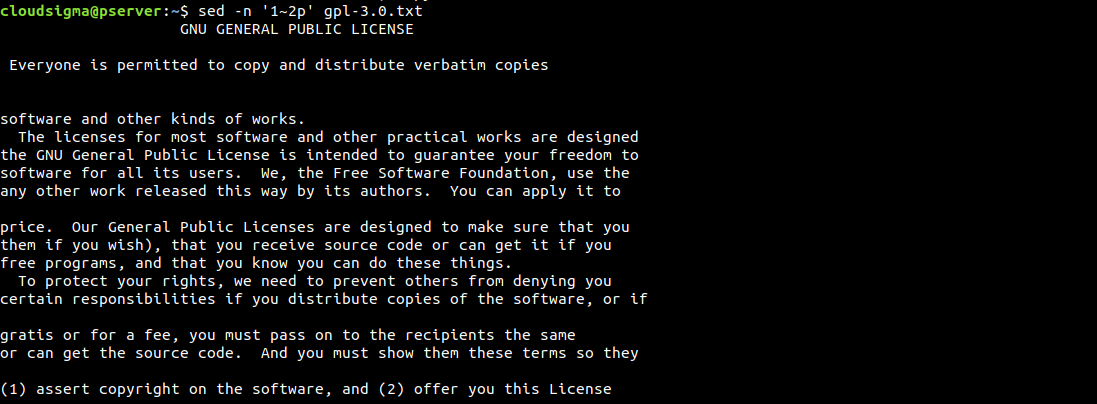
|
1 |
$ sed -n '1~2p' gpl-3.0.txt |
Mazání textu
Dosud jsme pracovali na tisku cílových řádků textu. Místo tisku můžeme řádky z výstupu odstranit. V následujícím příkladu odstraníme několik řádků od začátku. Zde nemusíme použít volbu -n protože chceme, aby sed vytiskl vše ostatní, co není smazáno. Pro mazání řádků použijeme volbu d:
|
1 |
$ sed '1~2d' gpl-3.0.txt |
Všimněte si, že zdrojový soubor je stále nedotčen. Sed pouze provádí mazání řádků během výstupu. Pokud chcete, můžete uložit výstup sed do souboru. Můžete přepsat původní soubor nebo jej uložit jako jiný:
|
1 |
$ sed '1~2d' gpl-3.0.txt > gpl-3.0.modified.txt |
Místo ručního zápisu výstupu do souboru může sed provést úpravu přímo v původním souboru. Stručně řečeno, sed upraví původní soubor a zapíše všechny provedené změny. Tato metoda přepíše původní soubor, proto by se měla používat opatrně:
|
1 |
$ sed -i '1~2d' gpl-3.0.txt |
Protože úprava přímo v souboru je nebezpečná, sed přichází s funkcí zálohování. Při provádění úprav přímo v souboru použijte -i.bak namísto -i k vytvoření zálohy před úpravou. Sed vytvoří záložní soubor s příponou .bak:
|
1 |
$ sed -i.bak '1~2d' gpl-3.0.txt |
Nahrazování textu
Toto je zdaleka jedna z nejčastějších implementací nástroje sed. Vyhledává textový vzor a nahrazuje jej zadaným textem. Zde je textový vzor popsán regulárními výrazy (zkráceně regex). Chcete-li se dozvědět více o používání regulárních výrazů, postupujte podle tohoto návodu, který popisuje, jak použít Grep s regulárními výrazy k vyhledávání textových vzorů v souborech.
Zde je příklad nejzákladnějšího nahrazení textu pomocí regulárních výrazů:
|
1 |
$ 's/<search_pattern>/<replacement>' |
Zde je s příkaz pro nahrazení. Lomítka jsou oddělovače pro vzor a náhradu. Pojďme to uvést do praxe:
|
1 |
$ echo "hello world" | sed 's/hello/HELLO/' |
![]()
Následující příklad bude demonstrovat použití podtržítka (_). Zde budou podtržítka fungovat jako oddělovače:
|
1 |
$ echo http://example.com/index.html | sed 's_com/index_net/home_' |
Zde hledáme com/index, abychom to změnili na net/home. Všimněte si umístění podtržítek, protože jsou velmi důležitá. Pokud například vynecháte poslední podtržítko, sed vyhodí chybu:
|
1 |
$ echo "http://www.example.com/index.html" | sed 's_com/index_net/home' |
![]()
K procvičení nahrazování potřebujeme nějaký testovací soubor. Zde mám oříznutou verzi textového souboru GPL v3:
|
1 |
$ cat gpl-3.0.cropped.txt |
Provedeme několik základních nahrazení textu:
|
1 |
$ cat gpl-3.0.cropped.txt | sed 's/GNU/GNU is Not Unix/' |
Podívejte se na další příklad. Chceme změnit všechny výskyty the na THE :
|
1 |
$ echo "the the quick brown fox jumps over the lazy dog" | sed 's/the/THE/' |
![]()
Všimli jste si něčeho? Sed nezměnil všechny výskyty the. Ve skutečnosti pouze první výskyt. Co se děje? Toto je výchozí chování volby s. Odpovídá pouze prvnímu výskytu na daném řádku a přechází na další. Abychom zajistili, že sed zkontroluje celý řádek na hledaný vzor, musíme použít volitelný příznak g. Pojďme příkaz opravit:
|
1 |
$ echo "the the quick brown fox jumps over the lazy dog" | sed 's/the/THE/g' |
Nyní to funguje podle představ. Dalším zajímavým způsobem použití příkazu je určení počtu výskytů, které se mají změnit. V předchozím příkladu byly 3 výskyty the, že? Co kdybychom určili, že se má změnit pouze 3. výskyt? Změna se projeví u volitelného příznaku:
|
1 |
$ echo "the the quick brown fox jumps over the lazy dog" | sed 's/the/THE/3' |
Pokud pracujete s velkým textovým souborem, může pomoci, když sed vytiskne pouze ty řádky, ve kterých došlo k nahrazení. Chceme-li toho dosáhnout, musíme přidat další dodatečný příznak p:
|
1 |
$ sed -n 's/GNU/GNU is Not Unix/gp' gpl-3.0.txt |

Citlivost na velikost písmen
Ve výchozím nastavení jsou všechny sed operace citlivé na velikost písmen. Následující příkaz demonstruje výchozí chování citlivosti na velikost písmen:
|
1 |
$ echo "HELLO WORLD" | sed 's/hello/hElLo/' |
![]()
Kvůli neshodě ve velikosti písmen nedojde k žádné změně. V takové situaci můžeme příkazu sed říct, aby citlivost na velikost písmen ignoroval. Chcete-li tak učinit, přidejte volitelný příznak i:
|
1 |
$ echo "HELLO WORLD" | sed 's/hello/hElLo/i' |
Jak nahrazovat a odkazovat na texty
Síla nástroje sed spočívá především v jeho schopnosti používat regulární výrazy. S pokročilejšími a složitějšími regulárními výrazy toho dokážeme mnohem více. Můžeme například nahradit text od začátku souboru až po určité místo. Podívejte se na následující výraz:
|
1 |
$ sed 's/^.*GNU/GNU_replaced/' gpl-3.0.txt |
Zde znak stříšky (^) označuje začátek řádku. Operátor pro shodu s jakýmkoli znakem je vyjádřen tečkou (.). Hvězdička (*) je zástupný výraz, který odpovídá textu od začátku řádku až po GNU.
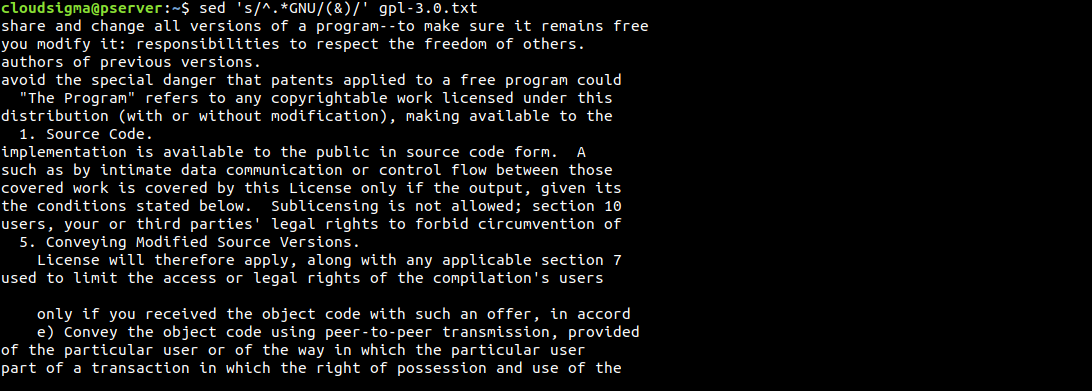
Dalším zajímavým trikem je použití symbolu &. Můžeme jej použít ke zvýraznění oblastí, které sed najde jako vyhledávaný vzor:
|
1 |
$ sed 's/^.*GNU/(&)/' gpl-3.0.txt |
Závěrečné shrnutí
V tomto návodu jsme prozkoumali základy příkazu sed . Naučili jsme se tisknout konkrétní řádky, vyhledávat texty, mazat a nahrazovat texty, přepisovat texty a používat regulární výrazy. Správně sestavený příkaz sed dokáže dramaticky změnit textový dokument. Nyní můžete úspěšně manipulovat s textem v Linuxu pomocí nástroje sed.
Příjemnou práci s počítačem!
Komentáře
Zatím žádné komentáře. Buďte první.