

企業意味著大量的數據,這使得處理和管理數據的問題變得更加困難。傳統上,數十年來業界一直使用 RDBMS 系統,但隨著 21 世紀大數據的出現,NoSQL (Not only SQL) 資料庫開始應用於大規模的非結構化和半結構化數據。
在這篇文章中,我將建立一個 MongoDB 叢集。
MongoDB 是一款免費且開源的 NoSQL 文件資料庫,因其提供的高擴充性和靈活性而被廣泛使用。
要在生產環境中部署 MongoDB,建議使用 Replica Sets。Replica Sets 是 MongoDB 在關聯式世界中相當於主/從(Master/Slave)架構的設計,但相比之下,它們的設定非常輕鬆,因為一切都是內建的。欲了解更多關於 Replica Sets 的資訊,請參閱 TutorialsPoint’s 對於複製過程的定義.
規劃您的 MongoDB 雲端伺服器叢集
我將建立一個 3 節點的叢集。為它們分配相等的資源非常重要,因為其中任何一個都可能成為主(即 master)伺服器。這些節點或機器可以在任何作業系統上運行,但在本教學中,我將使用 Ubuntu 18.04 LTS。關於如何掛載和設定來自 CloudSigma’s 函式庫中預裝的映像檔,您可以參考 本教學.
由於 Replica Set 的核心意義在於叢集應該在單一節點故障時仍能存活,因此如果您的所有伺服器都位於同一個實體主機上,那就毫無意義了。幸運的是,CloudSigma 確實提供了一種稱為 可用性群組 的功能。這意味著您可以指示系統將您的三台伺服器分配到不同的群組中。這樣一來,它們就永遠不會位於同一個實體主機上。關於此功能以及其他安全性和業務連續性功能的更多資訊,可以在 這裡.
使用 64 位元版本的 Linux 也很重要。原因很簡單,因為 MongoDB 在 32 位元系統上運行效果不佳(更多相關資訊請參閱 這裡).
在雲端安裝 MongoDB
這個部分非常簡單。您可以使用預先設定好的 Ubuntu 18.04 映像檔,或者自行安裝。
CPU、RAM 和硬碟的配置因人而異,取決於您的負載。對於較小規模的安裝,4 GHz CPU、4 GB RAM 和 10 GB 硬碟(用於系統)應該就足夠了。當您掛載硬碟時,請確保您使用的是 VirtIO。如果您使用 IDE,效能將會顯著下降。此外,由於您正在建立 Replica Set,您需要所有節點(和應用程式伺服器)都位於同一個 VLAN 上。
與許多其他雲端廠商不同,您無需使用 RAID10 或類似配置來設定您的儲存空間以提高效能。正如我們的許多客戶所回報的,在 CloudSigma 同時使用 SSD 和磁性硬碟,您將能獲得出色的即用效能。
我仍然建議將 MongoDB 數據保存在獨立的硬碟上。原因很簡單,因為在某些時候您可能需要進行一些檔案系統優化,而您不希望對整個檔案系統都進行這些操作。
考慮到這一點,最簡單的方法是在設定好伺服器後再新增此硬碟。現在,讓我們專注於系統安裝。如果您是自行安裝(而不是使用預先設定好的系統),我建議您在開機選單中按 F4 並選擇 ‘安裝最小化虛擬機器’.
我正在建立 3 台機器,每台機器的規格如下:
- CPU: 4 GHz
- RAM: 4 GB
- SSD: 10 GB (Ubuntu 18.04 LTS), 20 GB (額外硬碟)
如 SSD 部分所述,我正在掛載一個容量為 10 GB 且已安裝 Ubuntu 18.04 LTS 的硬碟。
此外,我還掛載了另一個容量為 20 GB 的空白硬碟,用於儲存 MongoDB 數據。其大小很大程度上取決於您的使用情況,但對於小型系統,20GB 應該足夠了。然而,由於有時很難預測您將儲存多少數據,我們將使用 LVM. 這將使您以後能夠簡單地添加另一個硬碟並擴充磁碟區,而無需重新開始。或者,您可以使用單個硬碟,並在以後使用以下工具進行擴充:resize2fs。
要添加硬碟,只需轉到 ‘Drives’(硬碟)部分,點擊頂部的 ‘Create a new drive’(創建新硬碟)圖示,為新硬碟命名並將其大小設置為 20 GB。儲存後,轉到要附加該硬碟的個別機器,在該機器詳細資訊的硬碟部分下,點擊 ‘Attach a drive’(附加硬碟)並選擇該硬碟。
現在您有了三台機器,您可以開始將為 MongoDB 數據存儲添加的額外硬碟掛載到每台機器上。我建議將此硬碟添加為分割區。使用分割區允許操作系統分別管理每個區域中的資訊。為了將硬碟添加為分割區,我將首先檢查連接到我們機器的所有硬碟。為此,我將執行以下命令:
|
1 |
fdisk -l |
當我執行該命令時,我會得到說明我機器上的硬碟和設備的輸出。
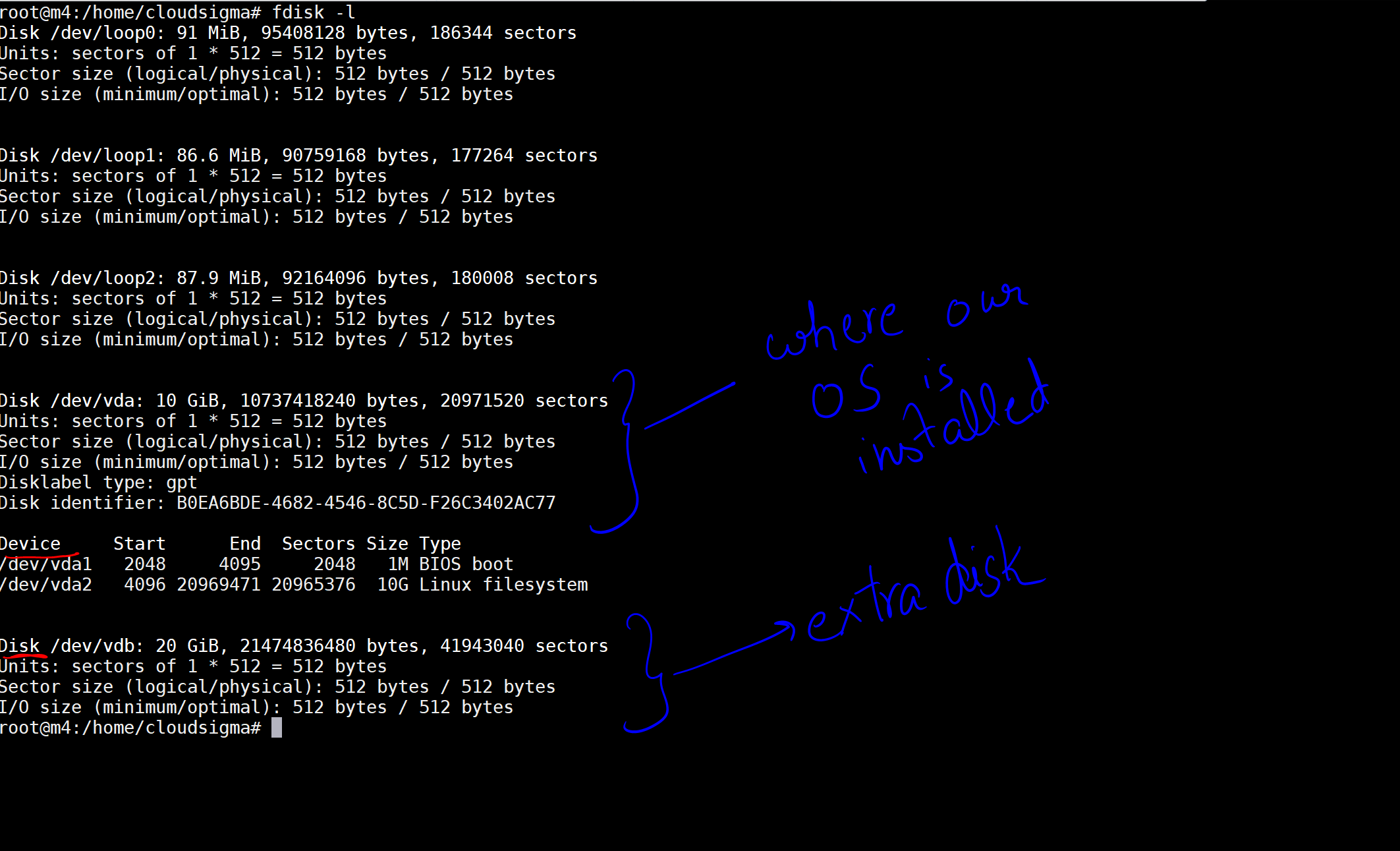
在圖片中,我已將一個 10 GB 的硬碟標記為安裝了我們操作系統的硬碟。然後是另一個現在已附加的 20 GB 硬碟。硬碟位置是 /dev/vdb。您可以使用以下命令在此硬碟上創建分割區:
|
1 |
sudo fdisk /dev/vdb |
它將打開 fdisk 工具,這是一個提供硬碟分割功能的命令列工具,您可以在其中在我們的硬碟上創建分割區。它會給出一個提示 “Command (m for help):”,您需要在其中輸入 n 以創建新分割區,然後只需繼續按 Enter 鍵以接受預設值。在創建分割區後,輸入 w 以寫入變更。它看起來會像這樣:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
命令 (m 以獲取 說明): <strong>n</strong> 分割區類型 p 主要 (0 主要, 0 延伸, 4 空閒) e 延伸 (容器用於 邏輯分割區) 選擇 (預設 p): 使用預設 回應 p. 分割區編號 (1-4, 預設 1): 第一個磁區 (2048-41943039, 預設 2048): 最後一個磁區, +磁區 或 +大小{K,M,G,T,P} (2048-41943039, 預設 41943039): 已創建 一個 新 分割區 1 類型為類型 'Linux' 且 大小為大小 20 GiB. 命令 (m 以獲取 說明): <strong>w</strong> 該分割表已被修改. 正在呼叫ioctl() 以 重新-讀取分割表. 正在同步磁碟. |
它已創建一個類型為 ‘Linux’ 且大小為 20 GiB 的新分割區 1。現在分割區已創建,讓我們創建一個 LVM 池:
|
1 2 3 |
sudo pvcreate /dev/vdb1 sudo vgcreate mongodb /dev/vdb1 sudo lvcreate -n db -L 19.5g mongodb |
我輸入了 ‘19.5g’,因為我的分割區大小是 20g。接下來,執行以下命令以找出硬碟的名稱:
|
1 |
fdisk -l | grep mongo | awk '{print $2'} |
之後,使用以下命令以 ext4 方式格式化硬碟:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
sudo mkfs.ext4 /dev/mapper/mongodb-db 輸出: root@m4:/home/cloudsigma# sudo mkfs.ext4 /dev/mapper/mongodb-db mke2fs 1.44.1 (24-3月-2018) 正在建立 檔案系統 使用 5217280 4k 區塊 和 1305600 inodes 檔案系統 UUID: 695a62e6-021d-4fc0-945c-cc51a92d86da 超級區塊 備份 儲存於 在 區塊: 32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208, 4096000 正在分配 群組 表: 完成 正在寫入 inode 表: 完成 正在建立 日誌 (32768 區塊): 完成 正在寫入 超級區塊 和 檔案系統 記帳 資訊: 完成 |
接下來,讓我們建立一個掛載磁碟的位置,以及一個用來存放 MongoDB 資料的資料夾。
|
1 |
sudo mkdir -p /mongodb/data |
為了在 fstab 中新增一條關於要掛載之新磁碟的項目,您可以直接使用以下命令:
|
1 |
echo -e "` blkid | grep mongodb | awk {'print $2'}`\t/mongodb\text4 auto,noexec,rw,sync,nouser\t0\t0" >> /etc/fstab |
在該命令中,blkid 會提供您每個磁碟的 UUID – 通用唯一識別碼。在這裡,我篩選出 MongoDB 磁碟的 UUID,並將此 UUID 分別與掛載資料夾的位置、檔案系統類型以及磁碟的其他選項結合。我正在將此行新增至 /etc/fstab。如果您不這樣做,在掛載磁碟時將會出錯。該項目看起來像這樣:
UUID=”695a62e6-021d-4fc0-945c-cc51a92d86da” /mongodb ext4 auto,noexec,rw,sync,nouser 0 0
現在,您可以將磁碟掛載到 /mongodb 位置:
|
1 |
sudo mount /mongodb |
安裝 MongoDB
系統準備就緒後,讓我們繼續安裝 MongoDB。雖然 Ubuntu 的官方套件庫中確實提供了 MongoDB 版本,但我建議您改用官方的 MongoDB 版本。原因在於 Ubuntu 套件庫的版本釋出相當落後,因此如果您想充分利用 MongoDB,就必須求助於官方釋出的版本。
由於 MongoDB 提供了自己的套件庫,您只需將其新增至您的系統,然後照常安裝 MongoDB 即可。以下是要遵循的步驟:
首先,匯入套件管理系統所使用的公鑰:
|
1 |
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 9DA31620334BD75D9DCB49F368818C72E52529D4 |
然後,我建立一個清單檔案。這將包含 MongoDB 所在的套件庫,以便您的系統可以從那裡下載它:
|
1 |
echo "deb [ arch=amd64 ] https://repo.mongodb.org/apt/ubuntu bionic/mongodb-org/4.0 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-4.0.list |
現在,我正在更新本地套件資料庫,以便套用這些變更。
|
1 |
sudo apt-get update |
現在,我只需使用以下命令安裝該套件:
|
1 |
sudo apt-get install -y mongodb-org |
我已在每台機器上安裝了 MongoDB。
|
1 |
sudo service mongod start |
現在 MongoDB 已啟動並執行,且已在建立的磁碟機上存放資料。如果預期會有高負載和/或大量連線,您可能需要提高 ulimit 值。
如果您想更深入地瞭解您的資料,您可能還想註冊 MongoDB 的 MMS,這是一個針對 MongoDB 的免費雲端監控服務。
為您的 MongoDB 雲端建立副本集
現在,讓我們建立一個副本集。在此之前,您需要確保每台機器之間可以互相通訊。為此,請在 /etc/hosts 中新增這些項目
|
1 2 3 |
IP-1 m1.mongo.cluster m1 IP-2 m2.mongo.cluster m2 IP-3 m3.mongo.cluster m3 |
為了進行驗證,您可以嘗試使用主機名稱來 ping 這些機器。因此,如果我的機器 1 的 IP 是 IP-1,例如 213.189.123.12,那麼與其輸入
|
1 |
ping 123.189.123.12 |
我會輸入,
|
1 2 3 |
ping m1.mongo.cluster 或 ping m1. |
如果您已啟用防火牆(您確實應該這樣做),請確保節點可以在內部介面上傳送和接收連接埠 28017 和 27017 的 TCP 流量。
現在,在每台機器上,使用以下命令啟動 mongod 服務。
在機器 m1 上,
|
1 |
mongod --dbpath /mongodb/data --replSet rs0 --bind_ip localhost,m1.mongo.cluster |
接下來,在機器 m2 上,
|
1 |
mongod --dbpath /mongodb/data --replSet rs0 --bind_ip localhost,m2.mongo.cluster |
在機器 m3 上,
|
1 |
mongod --dbpath /mongodb/data --replSet rs0 --bind_ip localhost,m3.mongo.cluster |
在這裡,
mongod 是服務的名稱
dbpath 是我們資料庫目錄的位置
replSet 是我們副本集的名稱。同一個副本集中的每台機器都應該相同
bind_ip 是您正在執行該服務的機器的主機名稱。
一旦您啟動了 mongod 服務,請前往主要伺服器(在我的例子中,我選擇了 m1),然後執行 mongo。
|
1 |
mongo |
這將啟動 MongoDB 終端機。在終端機上,使用以下命令初始化 replicaSet。它將使用預設設定建立 replicaSet:
|
1 |
rs.initiate() |
現在,讓我們使用以下命令將另外兩台機器新增為副本:
|
1 2 |
rs.add("m2.mongo.cluster") rs.add("m3.mongo.cluster") |
您可以使用以下命令監控狀態:
|
1 |
rs.status() |
就是這樣。您現在應該已經在 CloudSigma’s 極速雲端上啟動並執行您的 MongoDB 叢集了。
留言
目前尚無留言。成為第一個留言的人吧。