

網頁抓取、網頁爬取、網頁收割或網頁數據提取都是同義詞,指的是從整個網際網路的網頁中挖掘數據的行為。網頁抓取工具或網頁爬蟲是以程式化方式瀏覽網頁並提取所需數據的工具。這些數據通常是大量的文本,可用於分析目的、了解產品,或滿足對某個網頁的好奇心。
如果您想知道如何進行網頁爬取,我們將透過一個簡單的數據集向您展示網頁抓取的基礎知識。無論您的程式設計專業水平如何,您都應該能夠跟著本教學進行。在實際範例中,我們將使用我們的 CloudSigma blog。我們將嘗試獲取我們部落格頁面上教學的相關資訊。當您閱讀到本教學的結論時,您將擁有一個使用 Python 3 製作的實用網頁抓取工具,它會爬取我們部落格版塊中的多個頁面,然後在您的螢幕上顯示數據。
利用建立這個基礎網頁抓取工具所獲得的知識,您可以對其進行擴展並建立您自己的網頁抓取工具。這應該會很有趣,讓我們開始吧!
先決條件
這是一個動手實作的教學,因此您應該擁有一個 Python 3 的本機開發環境,以便很好地跟著步驟進行。首先,您可以參考我們關於如何 在 Ubuntu 上安裝 Python 3 並設定本機程式設計環境.
Scrapy
網頁抓取涉及兩個步驟:第一步是尋找並下載網頁,第二步是爬取這些網頁並從中提取資訊。
在許多程式語言中,有許多方法和函式庫可以用來從頭開始建立網頁抓取工具。然而,當您的網頁抓取工具變得複雜,或者當您需要同時爬取具有不同設定和模式的多個頁面時,這在未來可能會帶來問題。要弄清楚如何在不同的格式(例如 CSV、XML 或 JSON)之間轉換抓取到的數據,可能是一項相當繁重的任務。
雖然有些人可能喜歡從頭開始建立自己的網頁抓取工具的挑戰,但最好不要重複造輪子,而是將其建立在處理所有這些問題的現有函式庫之上。我們將使用 Scrapy(一個 Python 函式庫)以及 Python 3 來實作本教學中的網頁抓取工具。Scrapy 是一個開源工具,也是最受歡迎且功能強大的 Python 網頁抓取函式庫之一。Scrapy 的建立是為了處理所有抓取工具都應該具備的一些常用功能。這樣一來,每當您想實作網頁爬蟲時,就不用重複造輪子。使用 Scrapy,建立抓取工具的過程會變得簡單而有趣。
Scrapy 可從 PyPi 獲取,通常稱為 pip – Python 套件索引(Python Package Index)。PyPi 是一個社群擁有的儲存庫,託管了大多數 Python 套件。當您在本機開發環境中安裝並設定 Python 3 時,它也會安裝 pip,您可以使用它來安裝 Python 套件。
步驟 1:如何建立一個簡單的網頁抓取工具
首先,要安裝 Scrapy,請執行以下命令:
|
1 |
pip install scrapy |
或者,您可以按照 Scrapy 官方安裝說明 (來自文件頁面)。如果您已成功安裝 Scrapy,請使用您選擇的名稱為專案建立一個資料夾:
|
1 |
mkdir cloudsigma-crawler |
進入該資料夾並為程式碼建立主檔案。此檔案將包含本教學的所有程式碼:
|
1 |
touch main.py |
如果您願意,可以使用文字編輯器或 IDE 來建立檔案,而不是使用上述命令。
接下來,打開檔案,讓我們開始建立一個使用 Scrapy 的基礎抓取工具。我們將建立一個繼承 scrapy.Spider(Scrapy 的基礎爬蟲類別)的 Python 類別。此類別將具有如下定義的兩個必要屬性:
- name — 用於識別爬蟲的字串名稱(您可以輸入自己選擇的名稱)。
- start_urls — 包含要爬取的 URL 列表的陣列。我們將從一個 URL 開始。
在打開的文件中添加以下程式碼片段以建立基本的爬蟲:
|
1 2 3 4 5 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] |
以下是每行程式碼的說明:
第一行導入了 Scrapy,使我們能夠使用該套件提供的各種類別。
在下一行中,我們繼承了 Scrapy 提供的 Spider 類別,並建立了一個名為 CloudSigmaCrawler 的子類別。藉由繼承類別 (Spider),我們可以存取該類別的屬性,並在我們的程式碼中使用。在這種情況下,Spider 類別具有定義如何追蹤 URL 以及從網頁中擷取資料的方法和行為。然而,它不知道要追蹤哪些 URL 或要擷取哪些資料。藉由繼承它,我們可以向這些方法提供所需的資訊。要深入了解子類別化和繼承,請繼續閱讀 物件導向程式設計原則.
在我們的 CloudSigmaCrawler 中,我們定義了所需的屬性。首先,我們將爬蟲命名為 cloudsigma_crawler。然後,我們提供一個起步的 URL: https://blog.cloudsigma.com/blog/。打開此 URL 將帶您前往 CloudSigma 部落格的第 1 頁,其中包含許多教學課程中的一部分。
是時候測試爬蟲了。您有幾種選擇。如果您使用的是 IDE,例如 PyCharm community edition 來自 JetBrains,它可能配有一個按鈕,您只需點擊即可執行腳本。另一個選擇是按照從命令列執行 Python 檔案的典型方式:python path/to/file.py,或 py path/to/file.py。另一個選擇是 Scrapy 的命令列 介面。Scrapy 附帶了自己的命令列介面,以協助啟動爬蟲。輸入以下指令來啟動爬蟲:
|
1 |
scrapy runspider main.py |
根據您安裝的 Scrapy 函式庫版本,您應該會看到類似以下的輸出:
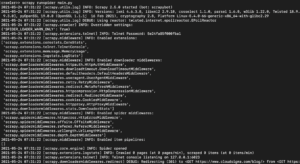
如您所見,輸出相當長,因此我們只挑選了部分內容。以下是您執行該指令時發生的情況:
- 爬蟲已初始化。因此,它載入了在追蹤和讀取來自 URL 的資料時需要使用的其他元件和擴充功能。
- 藉由使用 start_urls 清單中提供的 URL,它抓取了該頁面的 HTML。這與瀏覽器在打開網頁時遵循的過程類似。
- 抓取 HTML 後,它會被傳遞給我們尚未定義的 parse 方法。目前它不會執行任何操作,因此爬蟲直接退出而不進行任何處理。我們將在下一步中定義 parse 方法的行為。
步驟 2:如何從網頁中擷取資料
在步驟 1 中,我們僅實作了一個基本的爬蟲,它會抓取 HTML 網頁,但之後什麼也不做。在本節中,我們將提供擷取資料的說明。在 CloudSigma Blog 頁面上,我們想要從中擷取資料,您可以注意到一些事情,例如:
- 頁首,存在於所有頁面上。
- 導覽選單和搜尋篩選框。
- 網格格式的教學課程實際清單。
檢視您打算爬取的 HTML 網頁的原始碼,可以讓您對網頁的結構有一個大致的瞭解。這有助於您編寫爬蟲。您可以透過在網頁上按右鍵並選擇「檢視網頁原始碼」,或按下 Ctrl + U 來檢視原始碼。以下是原始碼的片段:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
<body> <div id="x-iso-container" class="x-iso-container x-iso-container-posts cols-3"> <article id="post-51691" class="post-51691 post type-post status-publish format-standard has-post-thumbnail hentry category-blog-posts category-tutorials tag-apache tag-certbot tag-cloud-guide tag-cloud-tutorial tag-https tag-lets-encrypt tag-ssl tag-ssl-certification tag-tutorial tag-ubuntu"> <div class="entry-wrap"> <header class="entry-header"> <h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="永久連結至:"在 Ubuntu 18.04 上使用 Let’s Encrypt 保護 Apache 安全"">保護 在 Ubuntu 18.04 上使用 Let’s Encrypt 的 Apache</a> </h2> </header> <div class="entry-content excerpt"> <p>網站與數據安全是不能輕忽的話題。高度敏感的資訊(包括 財務記錄和客戶的私人資訊)一直在 用戶的電腦與您的網站之間傳輸。當您考慮到這一點時,就不難理解為什麼未經安全保護的 網站可能會導致安全漏洞,從而嚴重損害您的業務。有許多 … </p> <div><a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="more-link">閱讀更多</a></div> </div> </div> ... </article> </div> </body> |
如您所見,每個部落格教學都被包在名為 <article> 的 HTML 標籤中。抓取該頁面將包含兩個步驟。第一步是透過尋找包含我們所需數據的頁面部分來獲取每個部落格教學。下一步是從該 HTML 標籤識別的每個教學中提取我們想要的數據。
Scrapy 根據您提供的選擇器來識別要抓取的數據。我們可以使用選擇器來尋找頁面上的一個或多個元素,並獲取這些元素中的數據。Scrapy 支援 XPath 和 CSS 選擇器。
從我們之前查看的原始碼來看,CSS 選擇器似乎比較簡單。因此,這將是我們選擇的方案,因為它將幫助我們找到頁面上的所有教學。從 HTML 原始碼中,每個教學都指定在名為 post 的 CSS 類別中。CSS 類別名稱通常以 .class_name(點 類別名稱)來識別。因此,我們將使用 .post 作為我們的 CSS 選擇器。在我們的 main.py 爬蟲原始碼中,我們將把 .post 類別傳遞給 response 物件,這樣您的檔案現在看起來會像這樣:
|
1 2 3 4 5 6 7 8 9 10 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): pass |
此程式碼片段將抓取具有指定 start_urls 的頁面上的所有教學課程,並循環遍歷這些教學課程以提取數據。在下一步中,您將需要提取並顯示這些數據。如果您再次檢查 CloudSigma 部落格 的原始碼,您將會看到每個教學課程的標題都儲存在 <h2> 標籤內的 <a> 標籤中,例如:
|
1 2 3 4 5 |
<h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Permalink to: "Securing Apache with Let’s Encrypt on Ubuntu 18.04"">Securing Apache with Let’s Encrypt on Ubuntu 18.04</a> </h2> |
我們正在循環遍歷的每個教學課程物件都包含一個 CSS 方法,我們可以傳入一個選擇器來定位和提取子元素。在此範例中,我們想要提取封裝在 <a> 標籤內的標題。此標籤位於 .entry-wrap 類別內的 .entry-header 類別內的 <h2> 標籤內。我們可以將這些 CSS 選擇器傳遞給物件方法以提取標題,將程式碼修改為如下所示:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), } |
extract_first() 後面的逗號並非筆誤,因為我們將在該部分下方添加更多程式碼。
上述原始碼中需要注意的一些要點包括:
- 附加到選擇器的 ::text – 這是一個 CSS 偽選擇器 ,它指示程式碼獲取標籤內的文字,而不是標籤本身。
- 物件中的 extract_first() 方法呼叫 – 指示程式碼僅挑選與選擇器比對的第一個元素。因此,我們得到的是一個字串,而不是元素列表。
接下來,儲存檔案並在終端機中輸入以下命令來執行程式碼:
|
1 |
scrapy runspider main.py |
在輸出中,您應該會看到教學課程的標題:
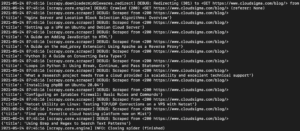
我們可以透過添加更多選擇器來獲取有關教學課程的其他詳細資訊(例如教學課程的 URL、精選圖片和說明文字),從而繼續對此進行擴展。
讓我們再次檢查單個教學課程的 HTML 程式碼:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
<body> <div id="x-iso-container" class="x-iso-container x-iso-container-posts cols-3"> <article id="post-51691" class="post-51691 post type-post status-publish format-standard has-post-thumbnail hentry category-blog-posts category-tutorials tag-apache tag-certbot tag-cloud-guide tag-cloud-tutorial tag-https tag-lets-encrypt tag-ssl tag-ssl-certification tag-tutorial tag-ubuntu"> <div class="entry-featured"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="entry-thumb" title="永久連結至:"在 Ubuntu 18.04 上使用 Let’s Encrypt 保護 Apache 安全""> <img width="1000" height="522" src="data:image/svg+xml,%3Csvg%20xmlns='http://www.w3.org/2000/svg'%20viewBox='0%200%201000%20522'%3E%3C/svg%3E" class="attachment-entry-fullwidth size-entry-fullwidth wp-post-image" alt="Let’s Encrypt" loading="lazy" data-lazy-srcset="/media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04.jpg 1000w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-300x157.jpg 300w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-768x401.jpg 768w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-610x318.jpg 610w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-100x52.jpg 100w" data-lazy-sizes="(max-width: 1000px) 100vw, 1000px" data-lazy-src="/media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04.jpg"/> </a> </div> <div class="entry-wrap"> <header class="entry-header"> <h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Permalink to: "Securing Apache with Let’s Encrypt on Ubuntu 18.04"">保護 Apache with Let’s Encrypt on Ubuntu 18.04</a> </h2> </header> <div class="entry-content excerpt"> <p>網站與資料安全是不可輕忽的議題。高度敏感的資訊,包括 包括財務紀錄和客戶的隱私資訊,總是在 使用者的電腦與您的網站之間進行傳輸。當您考慮到這個事實時,不難理解為什麼未經安全加密的 網站可能會導致安全漏洞,從而嚴重損害您的業務。有許多 … </p> <div><a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="more-link">閱讀更多</a></div> </div> </div> </article> </div> </body> |
我們想要嘗試提取標記的部分,即教學的 URL、特色圖片和說明文字。
- 從上面的程式碼片段中,部落格的圖片儲存在部落格教學開頭的 div 標籤內的 <a> 標籤內的 img 標籤的 data-lazy-src 屬性中。我們可以像處理教學標題一樣,使用 CSS 選擇器來獲取該值。
- 獲取教學的 URL 非常簡單,因為我們在 <div> 元素內有 <a> 標籤。
- 說明文字包含在 <div> 標籤內的 <p> 標籤中。
我們將使用 CSS 類別來獲取我們想要的內容。讓我們修改程式碼,使其看起來像這樣:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), 'caption': tutorial.css(CAPTION_SELECTOR).extract_first(), } |
儲存變更並使用以下指令執行程式碼:
|
1 |
scrapy runspider main.py |
您將在輸出中看到更多資料,例如我們新增的 URL、圖片和說明文字:

單頁網頁爬取的介紹就到這裡。接下來,讓我們看看如何建立一個能夠跟隨連結的爬蟲。
步驟 3:如何爬取多個頁面
到目前為止,我們已經建立了一個可以從單一頁面獲取資料的爬蟲。然而,我們想要的遠不止於此。您會需要一個能夠以程式化方式跟隨連結,並從網站的多個頁面中擷取資料的爬蟲。
如果您前往 CloudSigma 部落格頁面的底部,您會注意到分頁連結,以及一個指向右側、表示下一頁的小箭頭。以下是 HTML 程式碼片段:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<div class="x-pagination"> <ul class="center-list center-text"> <li><span class="pages">第 1 頁,共 45 頁</span></li> <li></li> <li><span class="current">1</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/2/" class="single_page" title="2">2</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="single_page" title="3">3</a></li> <li><span class="expand">...</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/45/" class="last" title="最後一頁">45</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/2/" class="prev-next hidden-phone">→</a></li> </ul> </div> |
此片段顯示了在具有 .x-pagination CSS 類別的 <div> 標籤下,<li> 標籤內的幾個頁面導覽連結。我們的重點是指向下一頁的連結。它位於 <ul> 標籤中最後一個 <li> 的 <a> 標籤內。
如上方的片段所示,指向下一頁的連結在 <a> 標籤內具有 .prev-next 類別。然而,如果您移至下一頁,您還會注意到指向上一頁和下一頁的連結都具有此 CSS 類別。請參考第 2 頁的此片段:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<div class="x-pagination"> <ul class="center-list center-text"> <li><span class="pages">第 2 頁,共 45 頁</span></li> <li><a href="https://blog.cloudsigma.com/blog/" class="prev-next hidden-phone">←</a></li> <li><a href="https://blog.cloudsigma.com/blog/" class="single_page" title="1">1</a></li> <li><span class="current">2</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="single_page" title="3">3</a></li> <li><span class="expand">...</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/45/" class="last" title="最後一頁">45</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="prev-next hidden-phone">→</a></li> </ul> </div> |
如果我們使用 Scrapy 的 extract_first() 方法,它將在第一頁上運作。當它到達下一頁時,它會選擇第一個具有 .prev-next 類別的連結,在上述程式碼片段中,該連結指向第一頁。這將導致無限循環。因此,我們將使用 Scrapy 的 extract() 方法。此方法會提取所有符合特定使用案例的元素並將它們放入陣列中。從這個陣列中,我們可以選擇最後一個元素,它將包含指向下一頁的實際連結。請將您的程式碼修改為如下所示:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), } NEXT_PAGE_SELECTOR = '.x-pagination > ul.center-list > li > a.prev-next::attr("href")' next_page = response.css(NEXT_PAGE_SELECTOR).extract() if next_page: yield scrapy.Request( response.urljoin(next_page[-1]), callback=self.parse ) |
讓我們逐步看一遍 next_page 選擇器的程式碼。
我們首先為下一頁和上一頁的連結定義一個選擇器。然後,我們使用 extract() 方法來提取 URL 並將它們放入一個陣列中。next_page 變數將會是一個包含兩個元素的陣列,如下所示:
|
1 |
next_page = [prev_page_url, next_page_url] |
由於我們要導覽到下一頁,我們將選擇陣列中的最後一個元素。Next_page[-1] 會選擇陣列中的最後一個元素。
if 區塊會檢查 next_page 變數是否含有內容,如果有,則會呼叫 scrapy.Request() 方法。在我們的程式碼中,我們指示此方法去爬取提供之 URL 的頁面,並將其傳回給 parse() 方法,以便我們可以解析它以提取資料,並對下一頁重複此過程。此過程會一直重複,直到找不到下一頁的連結,或者如果該區塊失敗,它就會停止。
儲存您的程式碼並執行它。您會注意到,當它找到更多要爬取的頁面時,迭代會繼續迴圈遍歷這些頁面。這就是您定義一個會跟隨網站上連結的爬蟲程式的方式。我們的範例非常簡單直接。我們只是前往一個頁面,找到下一頁的連結,然後重複此過程。在其他使用場景中,您可能想要跟隨指向外部來源等的標籤或連結。以下是 Python 3 基礎網頁爬蟲程式的完整原始碼:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), 'caption': tutorial.css(CAPTION_SELECTOR).extract_first(), } NEXT_PAGE_SELECTOR = '.x-pagination > ul.center-list > li > a.prev-next::attr("href")' next_page = response.css(NEXT_PAGE_SELECTOR).extract() if next_page: yield scrapy.Request( response.urljoin(next_page[-1]), callback=self.parse ) |
結論
在本教學中,我們建立了一個基本的網頁爬蟲,可以爬取 CloudSigma 部落格 目錄,並僅用大約 27 行程式碼顯示有關部落格教學的一些資訊。
當然,這之所以可行,是因為我們是基於 Scrapy Python 函式庫建立的。這只是一個基礎,應該能幫助您建立更複雜的爬蟲,以追蹤更多標籤、網站搜尋結果等。您可以查看 Scrapy 的官方文件 以獲取更多關於使用 Scrapy 的資訊。
祝您運算愉快!
留言
目前尚無留言。成為第一個留言的人吧。