

CloudSigma 允許客戶將 GPU 新增至其虛擬機器,並使用高效能、具成本效益的運算,以滿足最嚴苛的工作負載。CloudSigma 的 GPU 產品核心是專為 HPC、AI 和數據分析優化的 NVIDIA A100 Tensor Core GPU。A100 的效能超越了 NVIDIA TESLA V100,並具有 AI 應用程式可以充分利用的新功能。我們允許客戶在直通(passthrough)模式下輕鬆建立優化的 NVIDIA A100 VM,以便 VM 執行個體能夠直接控制 GPU 及其內建記憶體。
使用案例
在雲端運行的運算密集型應用程式的增長,推動了近期 GPU 加速雲端運算的爆發式增長。這些應用程式包括 AI 深度學習訓練與推理、數據分析、科學運算、基因組學、圖形渲染和遊戲等等。從擴充 AI 訓練和科學運算,到擴充推理應用程式,再到實現即時對話式 AI,GPU 提供了必要的動力,以加速在雲端運行的眾多複雜且不可預測的工作負載。
NVIDIA A100 Tensor Core GPU 代表了巨大的飛躍,為各種規模的 AI、數據分析和 HPC 提供了前所未有的加速。A100 採用 NVIDIA Ampere 架構,提供比上一代高出達 20 倍的效能。CloudSigma 提供 80GB 記憶體版本,擁有每秒超過 2 兆位元組 (TB/s) 的全球最快頻寬,以運行最大的模型和數據集。
NVIDIA GPU 是推動 AI 發展的領先運算引擎之一,為 AI 訓練和推理工作負載提供了顯著的加速。此外,NVIDIA GPU 還加速了多種類型的 HPC 和數據分析應用程式與系統,將數據轉化為洞察。
AI 與 HPC
透過 GPU 加速,更快速、更高效地訓練複雜的機器學習模型。應對數據密集型任務,並在 AI 驅動的創新中取得突破。NVIDIA AI Enterprise 是一款端到端、雲端原生的 AI 和數據分析軟體套件,經過優化,可讓任何組織使用 AI。它已獲得在公有雲上部署的認證,並包含全球企業支援,以確保 AI 專案順利進行。A100 允許研究人員快速交付實際成果,並將解決方案大規模部署到生產環境中。
深度學習訓練
訓練 AI 模型需要強大的運算能力和擴充性。配備 Tensor Float (TF32) 的 NVIDIA A100 Tensor Core 在無需修改程式碼的情況下,提供比 NVIDIA Volta 高出達 20 倍的效能,並透過自動混合精度和 FP16 額外提升 2 倍。
像 BERT 這樣的訓練工作負載,可以由 2,048 個 A100 GPU 在不到一分鐘的時間內大規模解決,創下了解決時間的世界紀錄。
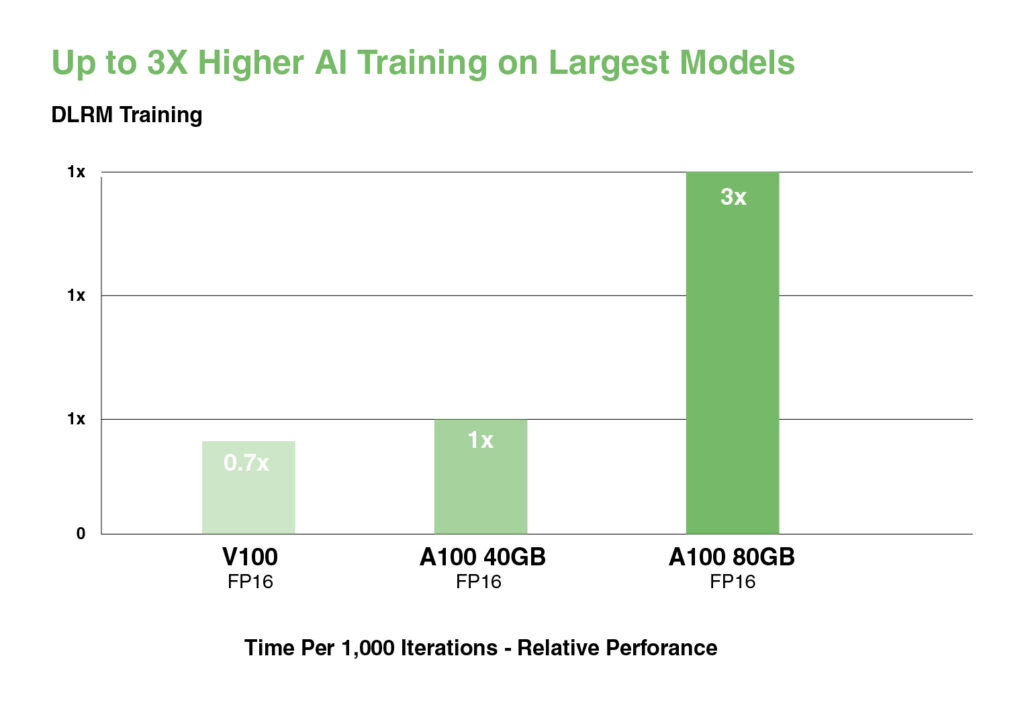
對於具有海量數據表的最大模型(如深度學習推薦模型 (DLRM)),A100 80GB 每個節點可達到高達 1.3 TB 的統一記憶體,並提供比 A100 40GB 高出達 3 倍的吞吐量。
NVIDIA 在 MLPerf 中處於領先地位,在 AI 訓練的行業通用基準測試中創下了多項效能紀錄。
深度學習推理
A100 引入了突破性的功能來優化推理工作負載。它加速了從 FP32 到 INT4 的全範圍精度。多執行個體 GPU (MIG) 技術允許在單個 A100 上同時運行多個網路,以實現最佳的運算資源利用率。而結構化稀疏性支援在 A100 其他推理效能提升的基礎上,提供了高達 2 倍的效能。
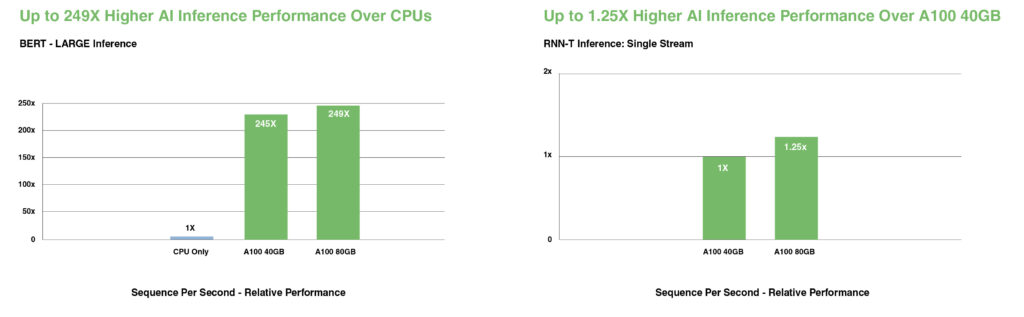
在 BERT 等最先進的對話式 AI 模型上,A100 的推理吞吐量比 CPU 加速高達 249 倍。
在受批次大小限制的最複雜模型(例如用於自動語音識別的 RNN-T)上,A100 80GB 增加的記憶體容量使每個 MIG 的大小翻倍,並提供比 A100 40GB 高出達 1.25 倍的吞吐量。
NVIDIA 市場領先的效能在 MLPerf Inference 中得到了證實。A100 帶來了 20 倍的效能提升,進一步擴大了這一領先優勢。
高效能運算
為了實現下一代的科學發現,科學家們仰賴模擬技術來更深入地瞭解我們周遭的世界。
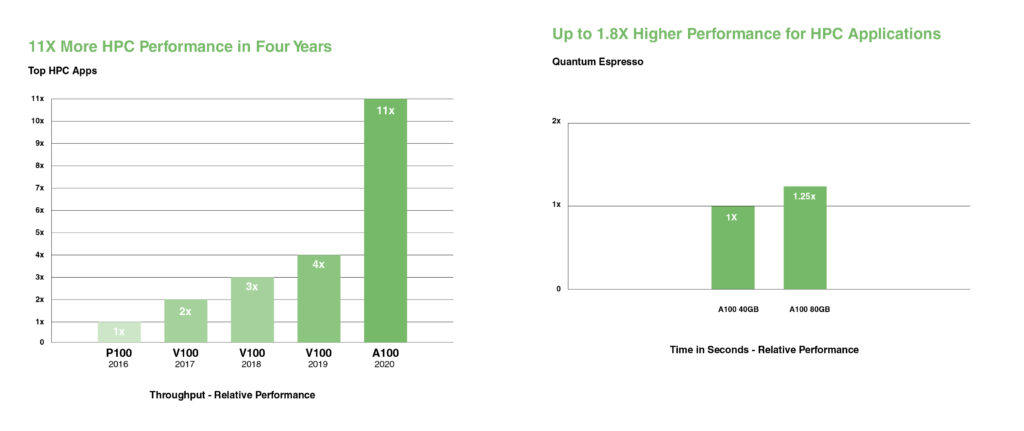
NVIDIA A100 推出雙精度 Tensor Cores,實現自 GPU 問世以來 HPC 效能的最大飛躍。憑藉 80GB 最快速的 GPU 記憶體,研究人員在 A100 上能將原本需要 10 小時的雙精度模擬縮短至 4 小時以內。HPC 應用程式可利用 TF32,在單精度、稠密矩陣乘法運算中實現高達 11X 的吞吐量。
對於具有最大資料集的 HPC 應用程式,A100 80GB 的額外記憶體在進行材料模擬軟體 Quantum Espresso 時,可提供高達 2X 的吞吐量提升。這種海量記憶體和前所未有的記憶體頻寬,使 A100 80GB 成為下一代工作負載的理想平台。
高效能資料分析
資料科學家需要能夠分析、視覺化海量資料集,並將其轉化為洞察。然而,橫向擴充(scale-out)解決方案往往會因為資料集分散在多台伺服器上而停滯不前。
配備 A100 的加速伺服器提供了所需的運算能力——海量記憶體、超過 2 TB/sec 的記憶體頻寬,以及透過 NVIDIA® NVLink® 和 NVSwitch™ 實現的可擴充性——以應對這些工作負載。結合 InfiniBand、NVIDIA Magnum IO™ 和 RAPIDS™ 開源函式庫套件(包括用於 GPU 加速資料分析的 RAPIDS Accelerator for Apache Spark),NVIDIA 資料中心平台以史無前例的效能和效率水準加速了這些龐大的工作負載。
在大數據分析基準測試中,A100 80GB 提供的洞察速度比 A100 40GB 提升了 2X,使其非常適合用於資料集規模呈爆炸式增長的新興工作負載。
科學模擬: 加速科學研究與模擬,在物理、化學和環境科學領域中實現更快速的洞察與發現。
媒體與娛樂: 以極快的速度渲染高解析度圖像、影片和動畫。在不犧牲品質的情況下,為您的觀眾提供卓越的視覺體驗。
金融建模: 以無與倫比的速度分析龐大的資料集並進行複雜的金融建模,為明智的決策提供關鍵洞察。
留言
目前尚無留言。成為第一個留言的人吧。