

命令 sed 是 stream editor(串流編輯器)的縮寫。它是 Linux/UNIX 系統上廣受歡迎的工具。Sed 本身並不是文字編輯器。然而,它可以進行各種修改以操作指定的文字。文字輸入是以串流的形式傳送。Sed 接著對該串流執行指定的動作。本指南 概述了 sed 命令以及如何操作它,以便在 Linux 中成功操作文字。
Linux 中的 Sed
的輸入串流 sed 可以來自文字檔案或 STDIN(標準輸入)。我們可以處理另一個命令的輸出,或者直接處理文字檔案。sed 工具已預裝在所有 Linux 發行版中。
Sed 使用概述
The sed 命令遵循以下結構:
|
1 |
$ sed <options> <commands> <file> |
為了演示目的,我們獲取了文字版本的 GPL 授權條款第 3 版:
|
1 |
$ wget https://www.gnu.org/licenses/gpl-3.0.txt |

以下 sed 命令將列印該文字檔案的內容:
|
1 |
$ sed '' gpl-3.0.txt |
在這裡,sed 正在執行單引號內描述的操作並列印輸出。由於未定義任何選項,sed 將僅執行空白操作並列印檔案的完整內容。
Sed 也接受來自其他命令的輸出作為輸入串流。在下一個範例中,將 GPL v3 文字檔案的內容透過管線傳送至 sed 以執行空白操作:
|
1 |
$ cat gpl-3.0.txt | sed '' |
如何列印行
在未指定任何選項的情況下,sed 將直接列印檔案的所有內容。相反地,我們可以明確傳送列印命令,將結果直接列印到標準輸出 (STDOUT)。
要列印輸出,請使用字元 p:
|
1 |
$ sed 'p' gpl-3.0.txt |
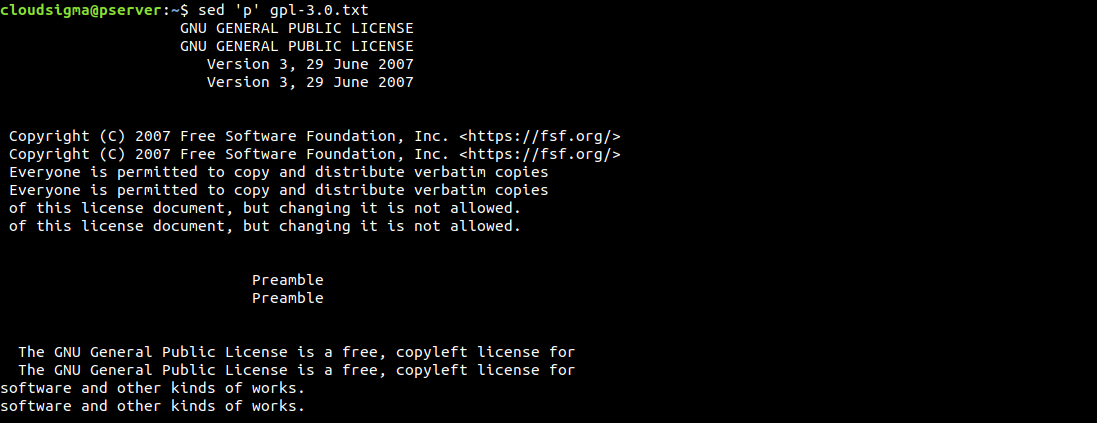
預設情況下,sed 會將輸出列印到螢幕上。因為我們特別使用了列印命令,sed 將會把每一行列印兩次。Sed 是逐行運作的。它讀取一行、執行特定操作、將其列印出來,然後移至下一行。
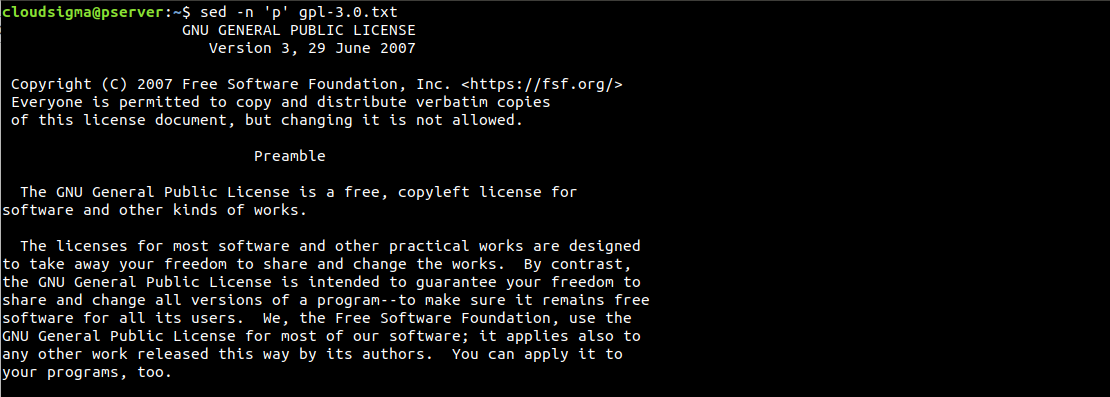
如我們所見,每一行都被列印了兩次。如果這樣的結果令人困惑,我們可以使用 -n 選項來清理它。它會抑制自動列印功能。因為我們正在傳送列印命令,所以不需要啟用預設的輸出列印功能:
|
1 |
$ sed -n 'p' gpl-3.0.txt |
Regex 字元類別
在正規表示式中,有各種字元類別。這些類別中的每一個都有一個範圍。許多類別也有多個運算式。大多數類別是字元範圍:
-
- [a-z]:小寫字元
-
- [A-Z]:大寫字元
-
- [0-9]:數字
-
- [a-zA-z]:英文字母
-
- [a-zA-z0-9]:任何英數字元
這些字元類別也有不同的標記法:
-
- [:lower:]:小寫字元
-
- [:upper:]:大寫字元
-
- [:digit:]:數字
-
- [:alpha:]:英文字母
-
- [:alphanum:]:英數字元
例如,以下命令將列印包含至少一個數字的所有行:
|
1 |
$ sed -n 's/[[:digit:]]/&/p' gpl-3.0.txt |
位址範圍
我們可以指定要處理的文字串流的特定部分。它可以是某一行的靜態位置,也可以是某個行範圍。在第一個範例中,我們將列印 GPL v3 文字檔案的第 5 行:
|
1 |
$ sed -n '5p' gpl-3.0.txt |

除了單行之外,我們還可以指定要處理的行範圍。在這裡,我們指定了從第 5 行到第 9 行(共 5 行)的位址範圍,供 sed 進行處理:
|
1 |
$ sed -n '5,9p' gpl-3.0.txt |

指定行位址也有不同的方法。除了由我們自己確定行號之外,我們還可以重新調整前一個範例,以便 sed 將從第 5 行開始,並對接下來的 5 行進行操作:
|
1 |
$ sed -n '5,+5p' gpl-3.0.txt |

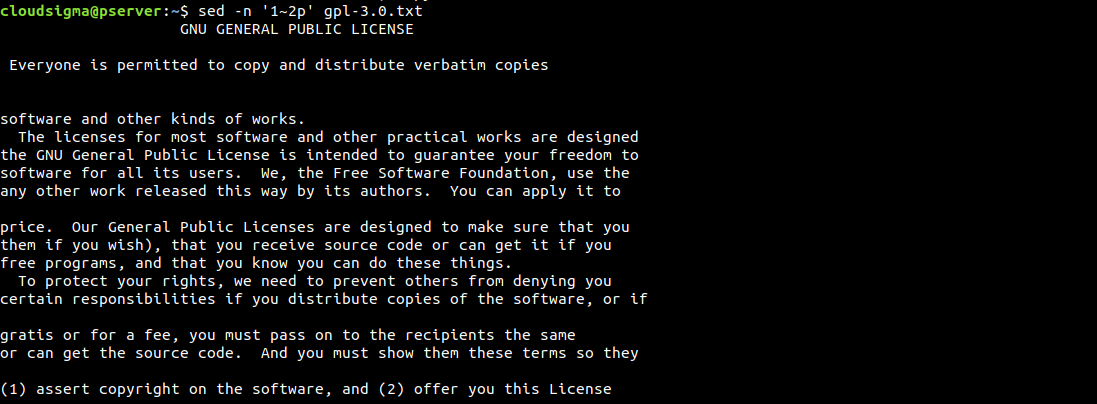
另一種指定行的方法是使用間隔。在下一個範例中,sed 將從第 1 行開始,並對每隔一行進行操作:
|
1 |
$ sed -n '1~2p' gpl-3.0.txt |
刪除文字
到目前為止,我們已經介紹了如何列印目標文字行。除了列印之外,我們還可以從輸出中刪除這些行。在接下來的範例中,我們將從開頭刪除多行。在這裡,我們不需要使用選項 -n,因為我們希望 sed 列印其他所有未被刪除的內容。對於刪除行,我們將使用選項 d:
|
1 |
$ sed '1~2d' gpl-3.0.txt |
請注意,來源檔案仍然完好無損。Sed 只是在輸出過程中執行行刪除。如果您願意,可以將 sed 輸出儲存到檔案中。您可以覆寫原始檔案或將其另存為其他檔案:
|
1 |
$ sed '1~2d' gpl-3.0.txt > gpl-3.0.modified.txt |
除了手動將輸出寫入檔案之外,sed 還可以對原始檔案進行就地編輯(in-place edit)。簡而言之,sed 將編輯原始檔案並寫入所做的任何變更。此方法會覆寫原始檔案,因此應謹慎使用:
|
1 |
$ sed -i '1~2d' gpl-3.0.txt |
因為就地編輯很危險,sed 提供了備份功能。在進行就地編輯時,請使用 -i.bak 代替 -i,以便在編輯前進行備份。Sed 將建立帶有 .bak 副檔名的備份檔案:
|
1 |
$ sed -i.bak '1~2d' gpl-3.0.txt |
文字替換
到目前為止,這是 sed 最常見的應用之一。它會搜尋文字模式,並用指定的文字替換該模式。在這裡,文字模式是用正規表示式(簡稱 regex)來描述的。要了解更多關於使用正規表示式的資訊,請參考這篇概述如何結合使用 Grep 與正規表示式來搜尋文字模式 的教學。
以下是使用正規表示式進行最基本文字替換的範例:
|
1 |
$ 's/<search_pattern>/<replacement>' |
在這裡,s 是用於替換的命令。斜線是模式和替換內容的分隔符號。讓我們來實際操作一下:
|
1 |
$ echo "hello world" | sed 's/hello/HELLO/' |
![]()
下一個範例將示範底線(_)的用法。在這裡,底線將作為分隔符號:
|
1 |
$ echo http://example.com/index.html | sed 's_com/index_net/home_' |
在這裡,我們正在搜尋 com/index 並將其變更為 net/home。 請注意底線的位置,因為它們非常關鍵。例如,如果您漏掉了最後一個底線,sed 將會拋出錯誤:
|
1 |
$ echo "http://www.example.com/index.html" | sed 's_com/index_net/home' |
![]()
我們需要一個虛擬檔案來練習一些替換。在這裡,我有一個裁剪版的 GPL v3 文字檔:
|
1 |
$ cat gpl-3.0.cropped.txt |
讓我們來進行一些基本的文字替換:
|
1 |
$ cat gpl-3.0.cropped.txt | sed 's/GNU/GNU is Not Unix/' |
看看下一個範例。我們想要將所有出現的 the 變更為 THE :
|
1 |
$ echo "the the quick brown fox jumps over the lazy dog" | sed 's/the/THE/' |
![]()
注意到什麼了嗎?Sed 並沒有變更所有出現的 the。 事實上,它只變更了第一個。這是怎麼回事?這是選項 s 的預設行為。它僅匹配指定行的第一個出現位置,然後移至下一行。為了確保 sed 會檢查整行以尋找搜尋模式,我們需要使用一個選用旗標 g。讓我們修正這個命令:
|
1 |
$ echo "the the quick brown fox jumps over the lazy dog" | sed 's/the/THE/g' |
現在它已如預期般運作。另一種有趣的使用命令方式是指定要變更的出現次數。在前面的範例中,有 3 個 the,對吧?如果我們指定只變更第 3 個 出現位置?變更將發生在選用旗標處:
|
1 |
$ echo "the the quick brown fox jumps over the lazy dog" | sed 's/the/THE/3' |
如果您正在處理大型文字檔案,那麼如果 sed 僅列印發生替換的那些行,這將會很有幫助。為了實現這一點,我們需要添加另一個額外的旗標 p:
|
1 |
$ sed -n 's/GNU/GNU is Not Unix/gp' gpl-3.0.txt |

區分大小寫
預設情況下,所有的 sed 操作都是區分大小寫的。以下命令將演示區分大小寫的預設行為:
|
1 |
$ echo "HELLO WORLD" | sed 's/hello/hElLo/' |
![]()
由於大小寫不匹配,因此沒有任何變化。在這種情況下,我們可以告訴 sed 停用區分大小寫。為此,請添加選用旗標 i:
|
1 |
$ echo "HELLO WORLD" | sed 's/hello/hElLo/i' |
如何替換和引用文字
要說到 sed 的強大之處,主要在於它使用正規表示式的能力。透過更進階且複雜的 regex 模式,我們可以完成更多工作。例如,我們可以替換從檔案開頭到特定位置的文字。請看以下運算式:
|
1 |
$ sed 's/^.*GNU/GNU_replaced/' gpl-3.0.txt |
在這裡,插入符號文字 (^) 表示行首。比對任何字元的運算子是用句點表示 (.). 星號 (*) 是萬用字元運算式,比對從行首一直到 GNU.
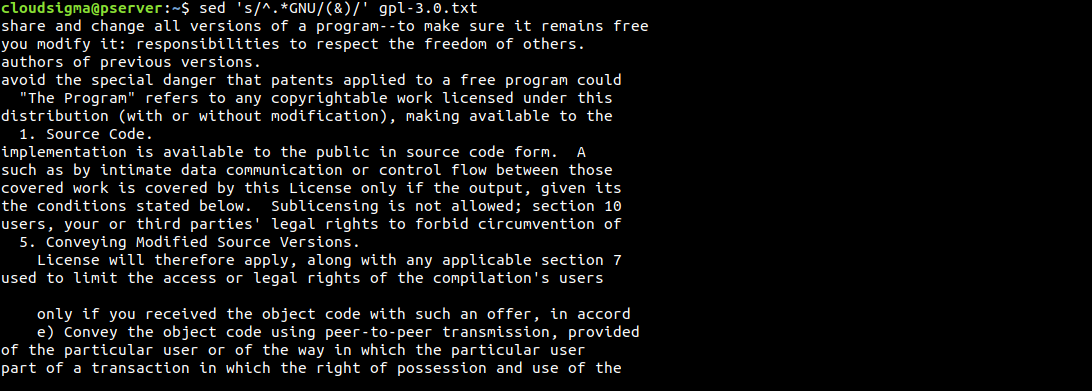
另一個有趣的技巧是使用 & 符號。我們可以用它來突顯 sed 找到搜尋模式的區域:
|
1 |
$ sed 's/^.*GNU/(&)/' gpl-3.0.txt |
結語
在本教學中,我們探索了 sed 命令的基本用法。我們學習了如何列印特定行、搜尋文字、刪除和替換文字、覆寫文字以及使用正規表示式。一個建構得當的 sed 命令可以顯著地改變文字文件。現在,在 sed.
的幫助下,您已可以成功地在 Linux 中操作文字。祝您使用愉快!
留言
目前尚無留言。成為第一個留言的人吧。