

Príkaz grep je výkonný nástroj na vyhľadávanie vzorov v texte. Je predinštalovaný v akejkoľvek distribúcii Linuxu. Tu je náš návod, ktorý sa zaoberá nastavením LAMP Stacku - Linux, Apache, MySQL a PHP.
Názov grep znamená „global regular expression print“ (globálna tlač regulárnych výrazov). Tento nástroj vyhľadáva zadaný vzor vo vstupe. V zásade to znie triviálne. Jeho skutočná sila však spočíva v tom, ako definujete vzor. Táto príručka podrobne popisuje, ako používať grep s regulárnymi výrazmi na vykonávanie zložitých vyhľadávaní. Začnime!
Ako používať Grep
Samotný príkaz grep nie je zložitý. Vyžaduje iba vzor a obsah, v ktorom sa má vyhľadávanie vykonať. Takto vyzerá základná štruktúra príkazu grep:
|
1 |
grep <regex> <file> |
Vyhľadávanie textu
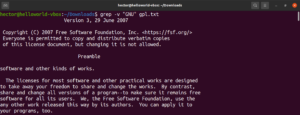
Najprv si zaobstarajte ukážkový súbor, na ktorom akciu vykonáte. Stiahnite si GNU General Public License v3.0 (v textovom formáte). Je to pomerne veľký textový súbor s množstvom slov a fráz. Ak používate Ubuntu môžete ho nájsť v súbore nižšie. Postupujte podľa nášho návodu na rýchlu a jednoduchú inštaláciu Ubuntu.
|
1 |
curl -o gpl.txt https://www.gnu.org/licenses/gpl-3.0.txt |

Ďalej môžete vykonať základné vyhľadávanie textu pomocou príkazu grep:
|
1 |
grep <pattern> <text_file> |
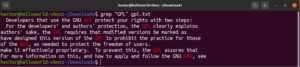
Výstup príkazu je možné presmerovať (pipe) do príkazu grep:
|
1 |
cat gpl.txt | grep <pattern> |
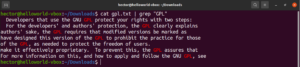
Rozlišovanie veľkosti písmen
V predvolenom nastavení grep rozlišuje veľkosť písmen. V mnohých situáciách môže byť ignorovanie veľkosti písmen optimálne. Ak chcete zakázať rozlišovanie veľkosti písmen, použite príznak „-i“ alebo „–ignore-case“:
|
1 2 3 |
$ grep -i <pattern> <file> $ grep --ignore-case <pattern> <flag> |
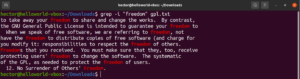
Invertované vyhľadávanie
V predvolenom nastavení grep vypisuje riadky, v ktorých sa našiel vzor. Invertovaná zhoda označuje prípad, keď nechcete vidieť riadky, ktoré zodpovedajú vzoru. Na invertovanie zhody musíte použiť príznak „-v“ alebo „–invert-match“:
|
1 2 3 |
$ grep -v <pattern> <file> $ grep --invert-match <pattern> <file> |
Číslo riadku
Pri spúšťaní príkazu grep na veľmi veľkom súbore je ťažké sledovať umiestnenie výsledku vyhľadávania. Na uľahčenie práce má grep funkciu zobrazenia čísla riadku. Ak chcete povoliť číslovanie riadkov, použite príznak „-n“ alebo „–line-number“:
|
1 2 3 |
grep -n <pattern> <file> grep --line-number <pattern> <file> |
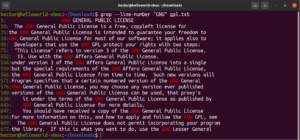
Je možné kombinovať viacero argumentov príkazu grep. Nasledujúci príkaz grep vykoná invertované vyhľadávanie a zároveň vypíše čísla riadkov:
|
1 |
grep -nv <pattern> <file> |
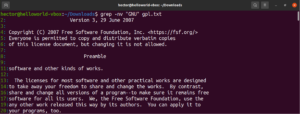
Regulárny výraz
Na začiatku tejto príručky sme spomenuli, že grep znamená „global regular expression print“. Pojem „regulárny výraz“ je definovaný ako špeciálny reťazec, ktorý popisuje vyhľadávací vzor. Regulárny výraz má svoju vlastnú štruktúru a pravidlá.
Existuje množstvo algoritmov a nástrojov na vyhľadávanie reťazcov, ktoré používajú regulárne výrazy (skrátene regex) na vyhľadávanie a nahradzovanie. Hoci je populárny, rôzne aplikácie a programovacie jazyky implementujú regex mierne odlišne. V tejto časti si ukážeme niekoľko metód regexu pomocou príkazu grep.
Doslovná zhoda
V predchádzajúcich príkladoch grep vyhľadával konkrétny reťazec v danom textovom súbore. Grep v skutočnosti vyhľadával pomocou veľmi základného regulárneho výrazu. Vzory regexu, ktoré definujú vyhľadávanie presnej zhody daného reťazca, sa nazývajú „literály“. Názov pochádza zo skutočnosti, že sa zhodujú so vzorom doslovne, znak po znaku.
Doslovná zhoda funguje s abecednými a číselnymi znakmi (ako aj s niektorými špeciálnymi znakmi). V závislosti od iných mechanizmov výrazov sa však toto správanie môže zmeniť:
|
1 |
grep "<string>" <file> |
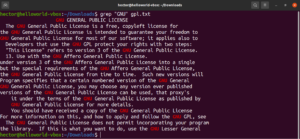
Zhoda s ukotvením
Kotvy sú špeciálne znaky, ktoré definujú, kde v riadku by sa mala nachádzať pozícia zhody, aby bola zhoda platná. Tu je rýchly príklad na zjednodušenie. Ak chceme nájsť iba riadky, ktoré začínajú reťazcom „GNU“, potom bude grep s regulárnym výrazom vyzerať takto. Znak „^“ je tu kotvou, ktorá definuje, že jediné platné zhody sú tie na začiatku riadku:
|
1 |
grep -n "^GNU" <file> |

Podobne, ak chceme nájsť iba riadky, ktoré končia reťazcom „works“, potom bude grep s regulárnym výrazom vyzerať takto. Znak „$“ je tu kotvou, ktorá definuje, že platné sú iba zhody na konci riadku:
|
1 |
grep -n "and$" <file> |
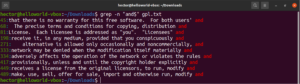
Zhoda s akýmkoľvek znakom
Pri vyhľadávaní textu môžete chcieť definovať, že na konkrétnom mieste môže byť akýkoľvek znak. V regulárnych výrazoch sa to vyjadruje znakom bodky (.).
Pozrite sa na tento príklad. V textovom súbore GNU GPL 3 majú slová „accept“ a „except“ spoločnú časť „cept“. Navyše, obe slová majú pred časťou „cept“ dva znaky. Nasledujúci príkaz grep nájde zhodu s akýmkoľvek slovom, ktoré má pred časťou „cept“ dva znaky:
|
1 |
grep -n "..cept" <file> |
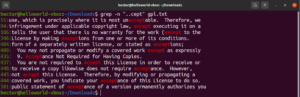
Podľa tohto regulárneho výrazu sú platnými zhodami aj iné slová ako suscept, unaccept, unexpected atď.
Hranaté zátvorky
V regulárnych výrazoch výrazy v hranatých zátvorkách definujú, že na zadanom mieste môže byť akýkoľvek znak deklarovaný v zátvorke. Pozrite sa na nasledujúci reťazec regulárneho výrazu:
|
1 |
t[wo]o |
Pri jeho použití budú platnými zhodami slová too a two:
|
1 |
grep -n "t[wo]o" <file> |
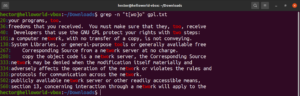
Výraz v hranatých zátvorkách otvára možnosti pre zaujímavé veci. Pomocou výrazov v hranatých zátvorkách je možné určiť, že na zadanom mieste môže byť akýkoľvek iný znak okrem tých, ktoré sú deklarované v zátvorke. Pozrite sa na nasledujúci reťazec regulárneho výrazu. Zhoda bude platná iba vtedy, ak je pred „ode“ akýkoľvek iný znak ako „c“:
|
1 |
"[^c]ode" |
Spustite ho na textovom súbore s licenciou GPL-3:
|
1 |
grep -n "[^c]ode" <file> |

Okrem výsledku zo súboru by ďalšími platnými výsledkami boli node, abode, anode atď. Výrazy v hranatých zátvorkách môžu popisovať aj rozsah znakov. Nasledujúci regulárny výraz hovorí, že zhoda je platná, ak je na začiatku riadku veľké písmeno:
|
1 |
"^[A-Z]" |
Spustite ho na textovom súbore s licenciou GPL-3. Budú to všetky riadky v textovom súbore:
|
1 |
grep -n "^[A-Z]" <file> |
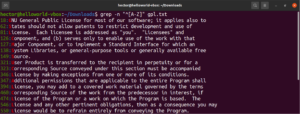
Pre jednoduchšie použitie existujú určité triedy znakov, ktoré majú špecifické označenia. V predchádzajúcom príklade sme na definovanie veľkých písmen použili rozsah „A-Z“. Namiesto toho môžeme použiť aj „[:upper:]“. Výsledok bude rovnaký:
|
1 |
grep -n "^[[:upper:]]" <file> |
Opakovanie vzoru
V určitých situáciách môžete chcieť nájsť zhodu pre konkrétny vzor alebo regulárny výraz nula alebo viackrát. Na tento účel slúži metaznak hviezdička (*). Nasledujúci regulárny výraz nájde zhodu pre všetky zátvorky, ktoré obsahujú iba písmená a jednoduché medzery medzi nimi. Všimnite si, že deklarácia sád malých, veľkých písmen a medzier je spolu bez akejkoľvek interpunkcie:
|
1 |
"([a-zA-Z ]*)" |
Uveďte regulárny výraz do praxe pomocou príkazu grep:
|
1 |
grep -n "([A-Za-z ]*)" <file> |

Použitie metaznakov ako doslovných znakov
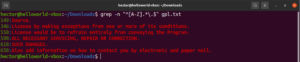
Doteraz sme sa zoznámili s rôznymi metaznakmi, ako je hviezdička (*), bodka (.), ukotvenia (^ a $), atď. Každý z nich označuje jedinečnú funkciu v kontexte regulárnych výrazov. Problém nastáva, keď ich treba použiť ako literály, nie ako metaznaky. V takýchto situáciách spätné lomítko (\) pred metaznakom označuje, že sa má použiť v doslovnom zmysle, nie ako metaznak. Pozrite sa na tento príklad regulárneho výrazu. Bude zodpovedať všetkým riadkom, ktoré začínajú veľkým písmenom a končia bodkou:
|
1 |
grep -n "^[A-Z].*\.$" <file> |
Alternácia
Pomocou zátvorkových výrazov môžeme určiť rôzne možné voľby pre zhodu jedného znaku. Regulárne výrazy majú funkciu robiť to isté so slovami a frázami. Na označenie alternácie sa používa znak zvislej čiary (|). Možnosti zostávajú v zátvorkách, zatiaľ čo znak zvislej čiary ich od seba oddeľuje. Pre platnosť zhody môžu existovať dve alebo viac možných možností. Pozrite sa na nasledujúci príklad regulárneho výrazu. Bude zodpovedať výrazom „GPL“ aj „General Public License“:
|
1 |
grep -nE "(GPL|General Public License)" <file> |
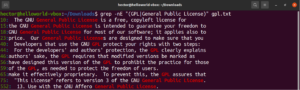
Kvantifikátory
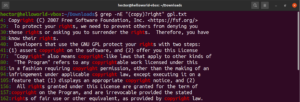
Pomocou metaznaku hviezdičky (*) sme dokázali definovať vzor opakovane nula alebo viackrát. Je tu však viac možností. Kvantifikátory je jednoduchšie vysvetliť na príklade. Nasledujúci regulárny výraz popisuje, že „copyright“ aj „right“ sú platné zhody. Otáznik (?) označuje časť „copy“ ako voliteľnú pre zhodu:
|
1 |
grep -nE "(copy)?right" <file> |
Ďalším kvantifikátorom je symbol plus (+). Správa sa podobne ako hviezdička. Definovaný vzor sa však musí zhodovať aspoň raz. V nasledujúcom príklade bude regulárny výraz zodpovedať slovu „soft“ s jedným alebo viacerými nebielymi znakmi:
|
1 |
grep -nE "soft[^[:space:]]+" <file> |
Určenie opakovania zhody
Je možné určiť, koľkokrát sa má zhoda opakovať. Na tento účel použite zložené zátvorky ({}). Nasledujúci regulárny výraz bude zodpovedať akémukoľvek slovu, ktoré obsahuje minimálne tri samohlásky:
|
1 |
grep -nE "[aeiouAEIOU]{3}" <file> |

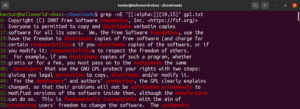
Táto funkcia vám tiež umožňuje definovať dolnú a hornú hranicu dĺžky zhody. V nasledujúcom príklade sa regulárny výraz zhoduje s akýmkoľvek slovom, ktoré má dĺžku 10 až 15 znakov:
|
1 |
grep -nE "[[:alpha:]]{10,15}" <file> |
Záver
Vyhľadávanie v textových súboroch pomocou príkazu grep je celkom praktické. Regulárne výrazy robia vyhľadávanie pomocou grep zaujímavejším a užitočnejším. Taktiež doladia vyhľadávací vzor presne podľa vašich predstáv.
Hoci sme si ukázali niektoré z bežných regulárnych výrazov, je to len začiatok. Existujú pokročilejšie regulárne výrazy, ktoré ponúkajú najjemnejšiu kontrolu nad správaním pri vyhľadávaní. Okrem príkazu grep sú regulárne výrazy široko používané aj inými nástrojmi a programovacími jazykmi.
Príjemnú prácu s počítačom!
Komentáre
Zatiaľ žiadne komentáre. Buďte prvý.