
Súbor CSV je čistý textový súbor, ktorý ukladá údaje v tabuľkovom formáte. Vo väčšine prípadov súbory CSV používajú ako oddeľovač čiarky (,), odtiaľ pochádza aj názov CSV (Comma Separated Values). Používa sa v situáciách, keď ide o kompatibilitu údajov, pretože súbory CSV je možné otvoriť v akomkoľvek textovom editore, tabuľkovom procesore a iných špecializovaných nástrojoch. Mnohé programovacie jazyky dokonca ponúkajú vstavanú podporu pre CSV.
V tomto návode sa dozvieme o používaní CSV v ukážkovej Node.js aplikácii.
CSV v Node.js
Node.js je open-source a multiplatformové runtime prostredie pre JavaScript. Stalo sa jedným z najpopulárnejších backendov, ktoré poháňajú množstvo webových služieb po celom internete. Dokonca aj veľké spoločnosti ako Netflix a Uber používajú Node.js na pohon svojich služieb.
Node.js má tiež k dispozícii množstvo modulov, ktoré je možné nasadiť na pridanie ďalších funkcií do projektu. Pokiaľ ide o CSV, k dispozícii je mnoho modulov, napríklad node-csv, fast-csv, a papaparse atď.
Ako napovedá názov návodu, budeme používať node-csv na čítanie CSV súborov pomocou streamov Node.js. Ukážeme si tiež prácu s analyzovanými dátami, napríklad prenos dát do SQLite databázy.
Požiadavky
-
Na vykonanie krokov popísaných v tomto návode budete potrebovať nasledujúce komponenty:
-
Správne nakonfigurovaný systém Linux. Prečítajte si viac o inštalácii a konfigurácii cloudového servera Ubuntu na CloudSigma.
-
Prístup k používateľovi bez oprávnení root s sudo oprávneniami. Pozrite si správu oprávnení sudo pomocou sudoers.
-
Vhodný textový editor, napríklad Brackets, VS Code, Sublime Text, Vim/NeoVim, atď.
-
Iný softvér:
-
Node.js LTS
-
SQLite
-
Krok 1 – Inštalácia potrebného softvéru
Pre tento návod som vytvoril ľahký server so systémom Ubuntu 22.04 LTS (pripojený cez SSH):
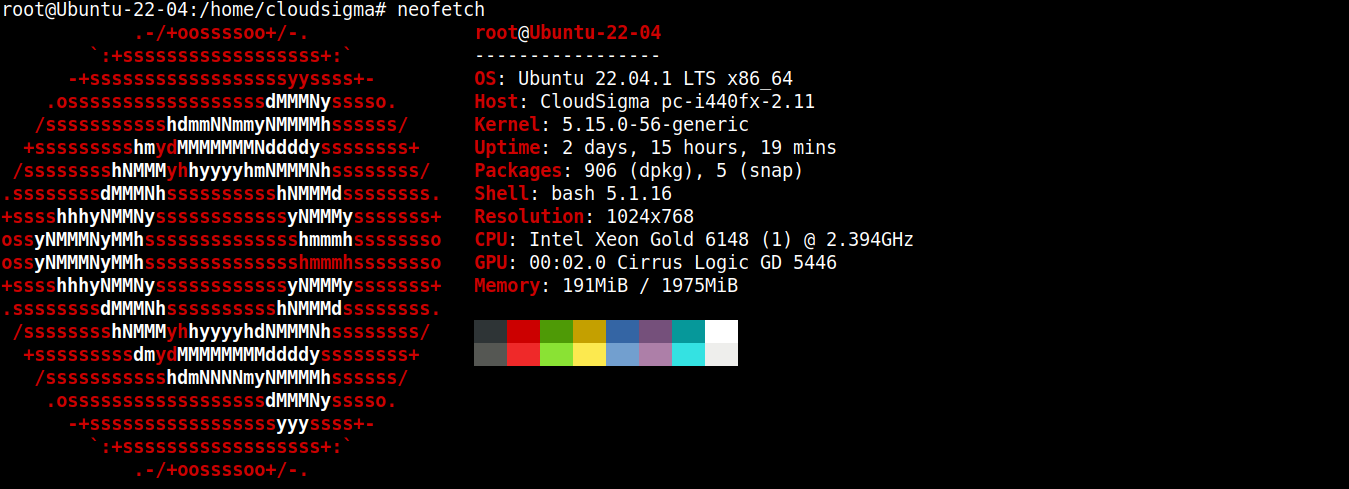
Teraz naň nainštalujeme Node.js a SQLite.
-
Inštalácia Node.js LTS
Node.js je priamo dostupný z oficiálnych repozitárov balíkov Ubuntu. Nie je to však najnovšia verzia. Preto sa spoľahneme na repozitár tretej strany (Nodesource) na získanie najnovších balíkov Node.js.
Pridajte repozitár pre Node.js LTS:
|
1 |
curl -fsSL https://deb.nodesource.com/setup_lts.x | sudo -E bash - |
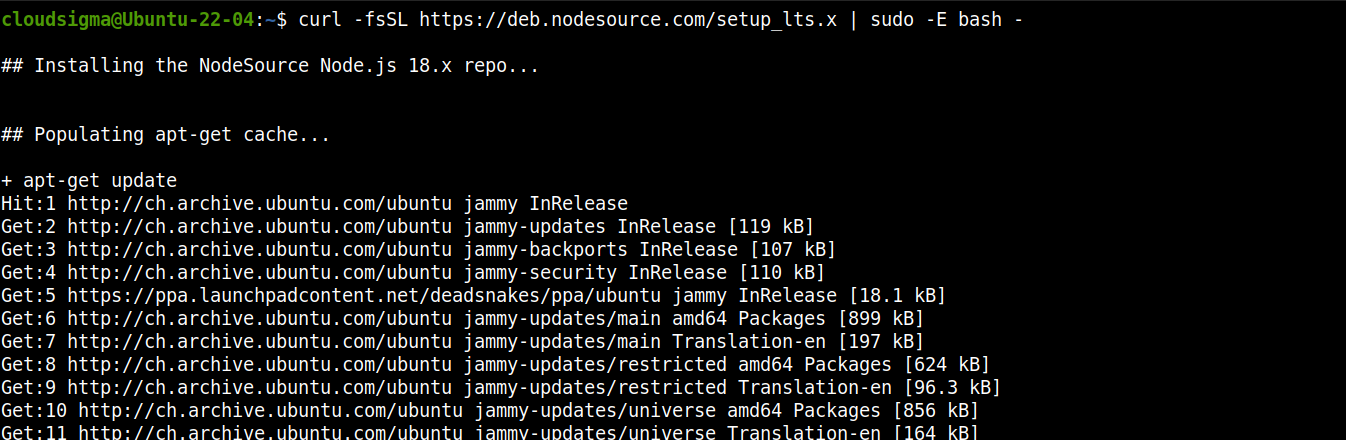
Teraz nainštalujte Node.js LTS:
|
1 |
sudo apt install nodejs -y |

-
Inštalácia SQLite
SQLite budeme inštalovať priamo z repozitárov balíkov Ubuntu. Spustite nasledujúce príkazy:
|
1 |
sudo apt install sqlite3 -y |

Krok 2 – Nastavenie adresára projektu
V tejto časti pripravíme vyhradený adresár pre náš projekt. Budú v ňom uložené všetky súbory projektu spolu s ďalšími modulmi.
Vytvorte nový adresár:
|
1 |
mkdir -pv csv_practice |
Prejdite do adresára:
|
1 |
cd csv_practice/ |
Potom spustením nasledujúceho príkazu deklarujte adresár ako npm projekt:
|
1 |
npm init -y |
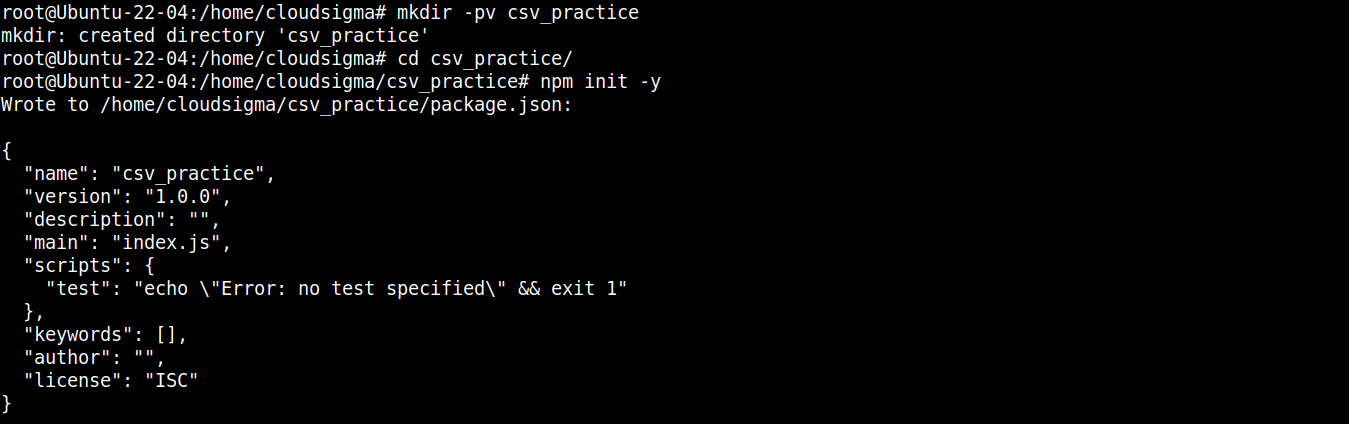
Po inicializácii priečinka projektu môžeme začať inštalovať potrebné balíky a moduly. Najprv nainštalujeme node-csv:
|
1 |
npm install csv |

Modul node-csv je v skutočnosti kolekcia niekoľkých ďalších modulov: csv-generate, csv-parse (analýza CSV súborov), csv-stringify (zápis dát do CSV) a stream-transform.
Ďalej potrebujeme modul na komunikáciu s SQLite. Nasledujúci príkaz nainštaluje modul node-sqlite3 modul:
|
1 |
npm install sqlite3 |

Komponent, ktorý pre náš projekt potrebujeme, je CSV súbor. Na demonštračné účely použijeme CSV súbor o migrácii na Novom Zélande:
|
1 |
wget https://www.stats.govt.nz/assets/Uploads/International-migration/International-migration-September-2021-Infoshare-tables/Download-data/international-migration-September-2021-estimated-migration-by-age-and-sex-csv.csv -O migration_data.csv |
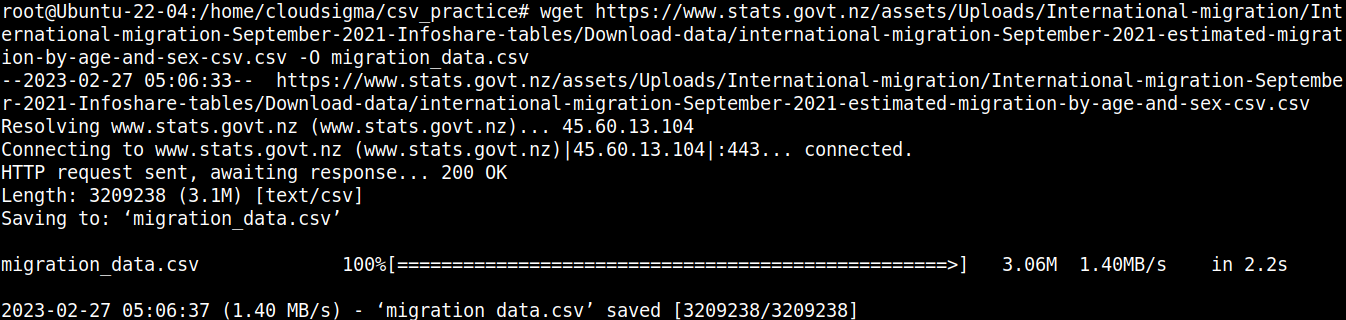
Pozrime sa v rýchlosti na obsah súboru:
|
1 |
cat migration_data.csv | less |
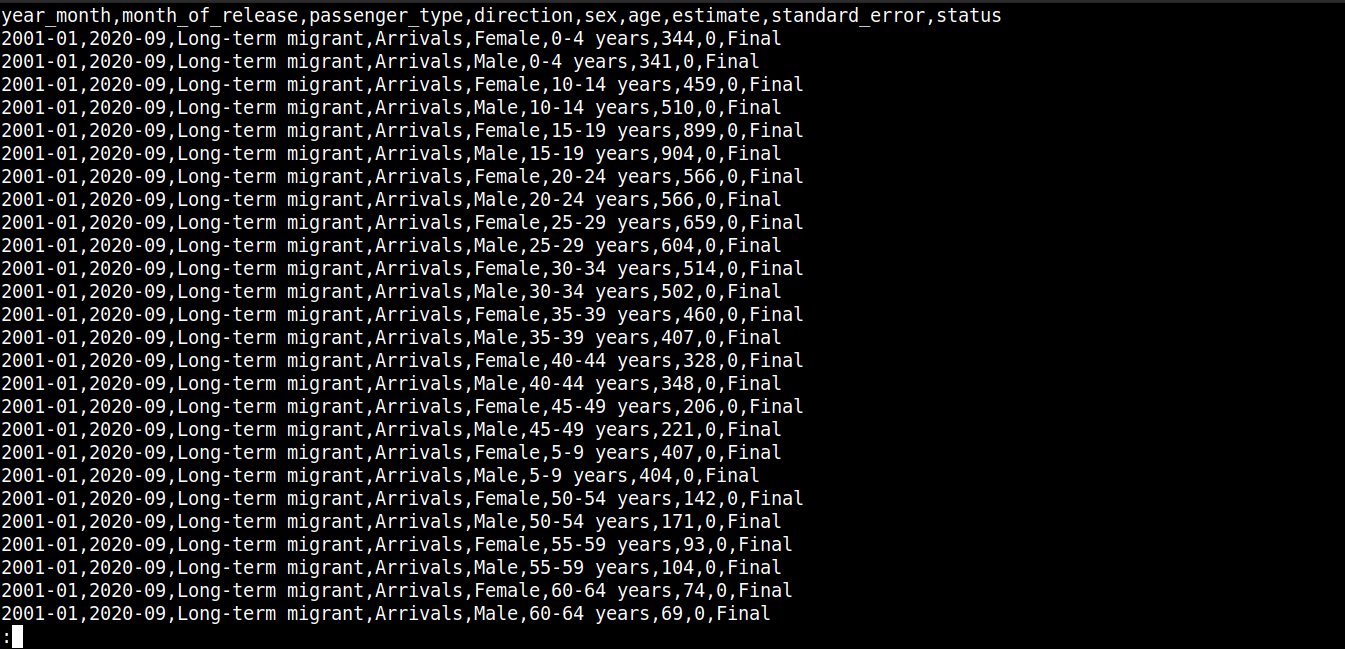
Tu,
-
Prvý riadok popisuje názvy stĺpcov.
-
Nasledujúce riadky obsahujú hodnoty pre tieto polia.
-
Každý riadok je oddelený novým riadkom (\n).
-
Každý údaj je oddelený čiarkou (,).
CSV sa však neobmedzuje len na používanie čiarok ako oddeľovača. Medzi ďalšie bežné oddeľovače patria dvojbodky (:), bodkočiarky (;) a tabulátory (\td).
Krok 3 – Čítanie CSV
V tejto časti si ukážeme implementáciu ukážkového programu, ktorý číta a analyzuje dáta zo súboru CSV.
Vytvorte nový JavaScript súbor:
|
1 |
touch read_csv.js |
Otvorte súbor vo svojom obľúbenom textovom editore:
|
1 |
nano read_csv.js |
Najprv naimportujeme fs a csv-parse moduly:
|
1 2 |
const fs = require("fs"); const { parse } = require("csv-parse"); |
Tu,
-
Najprv sa do premennej fs priradí objekt fs, ktorý vracia metóda Node.js require() pri importe modulu.
-
Potom sa metóda parse extrahuje z objektu vráteného metódou require() do premennej parse pomocou syntaxe deštrukturalizácie.
Ďalej pridáme kód na čítanie súboru CSV:
|
1 2 3 4 5 |
fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) |
Tu,
-
Voláme metódu createReadStream() z modulu fs a ako argument odovzdávame CSV súbor, ktorý chceme čítať. Ten potom vytvorí čitateľný stream rozdelením väčšieho súboru na menšie časti.
-
Po vytvorení streamu metóda pipe() presmeruje časti dát streamu do iného streamu. Tento nový stream sa vytvorí po zavolaní metódy parse() z modulu csv-module.
-
Modul csv-module využíva čitateľný/zapisovateľný transformačný stream, ktorý prevezme časť dát a transformuje ju do inej podoby.
-
Metóda parse() prijíma objekty s vlastnosťami. Objekt ďalej spracováva analyzované dáta. V tomto prípade objekt preberá nasledujúce vlastnosti:
-
delimiter: Znak oddeľovača na oddelenie hodnôt. V prípade nášho cieľového CSV je to čiarka (,).
-
from_line: Číslo riadku, od ktorého parser začne analýzu. Pri zadanej hodnote 2 parser preskočí 1. riadok a začne na 2. riadku. Týmto usporiadaním zabránime tomu, aby sa názvy stĺpcov začlenili do analyzovaných dát.
-
Ďalej pripojíme udalosť streamu pomocou metódy on() z Node.js:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) .on("end", function () { console.log("finished"); }) .on("error", function (error) { console.log(error.message); }); |
Tu,
-
Po vyvolaní určitej udalosti umožňuje udalosť streamu metóde spracovať časť dát.
-
Keď sú dáta analyzované metódou parse() pripravené na spracovanie, spustí sa udalosť data event.
-
Na prístup k dátam odovzdávame metóde on() spätnú väzbu (callback), ktorá prijíma parameter row.
-
Parameter row je časť dát vo forme poľa (výsledok analýzy).
-
Nakoniec sa dáta zapíšu do konzoly pomocou console.log().
Na dokončenie programu pridáme ďalšie udalosti streamu na spracovanie chýb a vypísanie správy o úspechu, keď sa spotrebujú všetky dáta v súbore CSV. Aktualizujte kód nasledovne:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) .on("end", function () { console.log("finished"); }) .on("error", function (error) { console.log(error.message); }); |
Tu,
-
Udalosť end sa vyvolá, keď sa spracujú všetky údaje v súbore CSV. Výsledkom je volanie console.log() metódy, ktorá vytlačí správu o úspechu.
-
Udalosť error sa vyvolá, keď sa vyskytne chyba pri analýze údajov CSV. Výsledkom je volanie console.log() metódy, ktorá vytlačí chybovú správu.
Finálny kód by mal vyzerať takto:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
const fs = require("fs"); const { parse } = require("csv-parse"); fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) .on("end", function () { console.log("finished"); }) .on("error", function (error) { console.log(error.message); }); |
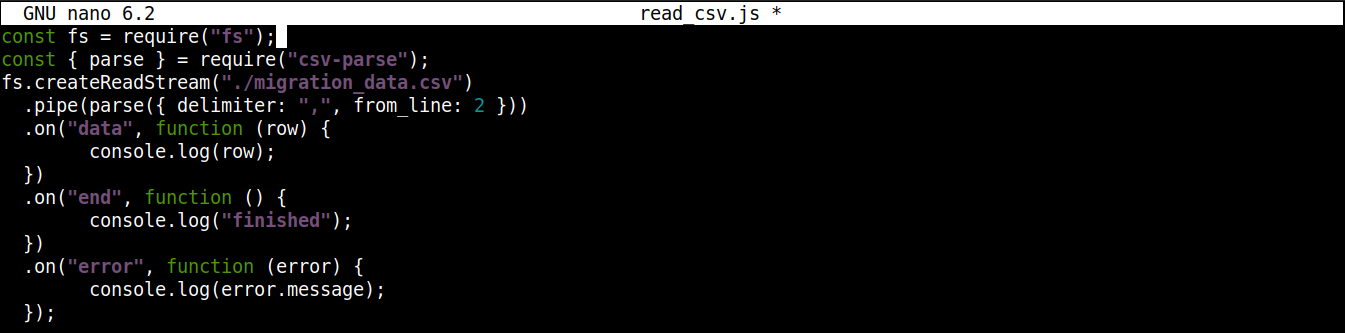
Uložte súbor a zatvorte editor. Teraz sme pripravení spustiť program. Spustite ho pomocou Node.js:
|
1 |
node read_csv.js |
Výstup by mal vyzerať približne takto:

Upozorňujeme, že údaje sa spracovávajú, transformujú a vypisujú do konzoly. Keďže ide o nepretržitý proces, bude to vyzerať, akoby sa údaje sťahovali, namiesto toho, aby sa celý výstup vypísal naraz.
Krok 4 – Prenos údajov CSV do databázy
Doteraz sme sa naučili, ako analyzovať súbor CSV pomocou node-csv. Táto časť ukáže prenos analyzovaných údajov do databázy (SQLite).
Vytvorte nový súbor JavaScript na interakciu s databázou:
|
1 |
touch csv-to-sqlite3.js |
Teraz otvorte súbor v textovom editore:
|
1 |
nano csv-to-sqlite3.js |
![]()
Náš program začneme s nasledujúcim kódom:
|
1 2 3 |
const fs = require("fs"); const sqlite3 = require("sqlite3").verbose(); const filepath = "./population.db"; |

Tu,
-
Na prvom riadku importujeme fs modul.
-
Na treťom riadku premenná filepath obsahuje cestu k databáze SQLite.
-
V tomto bode databáza ešte neexistuje. Bude však potrebná pri práci s node-sqlite3.
Ďalej pridajte nasledujúce riadky na nadviazanie spojenia s databázou SQLite:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
function connectToDatabase() { if (fs.existsSync(filepath)) { return new sqlite3.Database(filepath); } else { const db = new sqlite3.Database(filepath, (error) => { if (error) { return console.error(error.message); } console.log("Pripojenie k databáze bolo úspešné"); }); return db; } } |
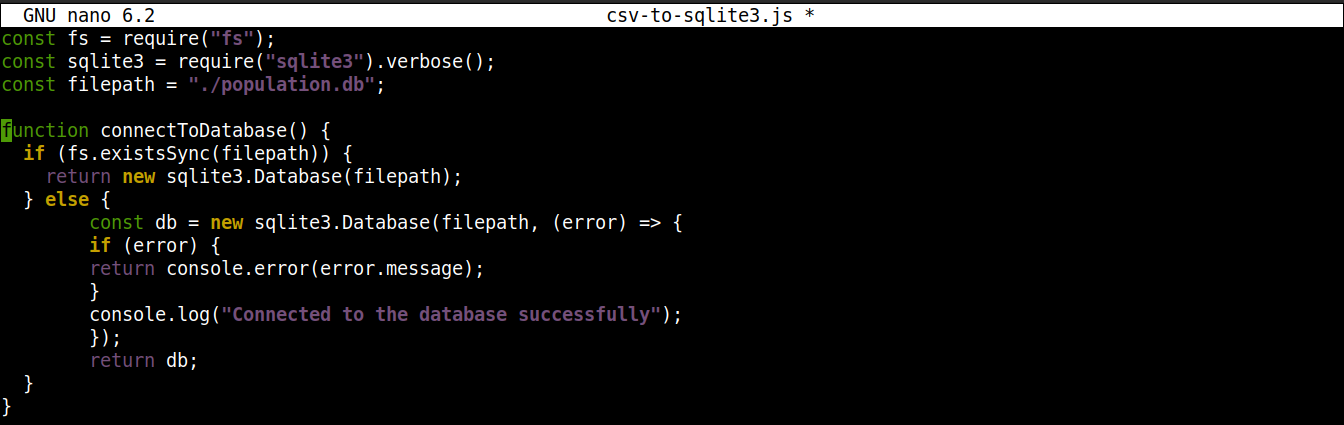
Tu,
-
Metóda connectoToDatabase() nadviaže pripojenie k databáze.
-
V rámci connectToDatabase(), voláme metódu existsSync() z modulu fs vo vnútri príkazu if. Príkaz if kontroluje existenciu databázy v zadanom umiestnení.
-
Ak je vyhodnotenie podmienky true, potom sa Database() trieda z node-sqlite3 modulu inicializuje. Po nadviazaní pripojenia funkcia vráti objekt a skončí.
-
Ak je vyhodnotenie podmienky false (databáza neexistuje), potom vykonávanie prejde do bloku else. Tam sa Database() trieda inicializuje s dvoma argumentmi: cestou k súboru databázy a spätným volaním (callback).
-
V zásade sa databáza vytvorí, ak neexistuje. Ak sa však počas procesu vytvárania vyskytne akákoľvek chyba, nastaví sa objekt error a vypíše sa chybové hlásenie.
Ďalej si predstavíme kód na vytvorenie tabuľky, ak databáza neexistuje:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
const fs = require("fs"); const sqlite3 = require("sqlite3").verbose(); const filepath = "./population.db"; function connectToDatabase() { if (fs.existsSync(filepath)) { return new sqlite3.Database(filepath); } else { const db = new sqlite3.Database(filepath, (error) => { if (error) { return console.error(error.message); } createTable(db); console.log("Pripojenie k databáze bolo úspešné"); }); return db; } } function createTable(db) { db.exec(` CREATE TABLE migration ( year_month VARCHAR(10), month_of_release VARCHAR(10), passenger_type VARCHAR(50), direction VARCHAR(20), sex VARCHAR(10), age VARCHAR(50), estimate INT ) `); } module.exports = connectToDatabase(); |
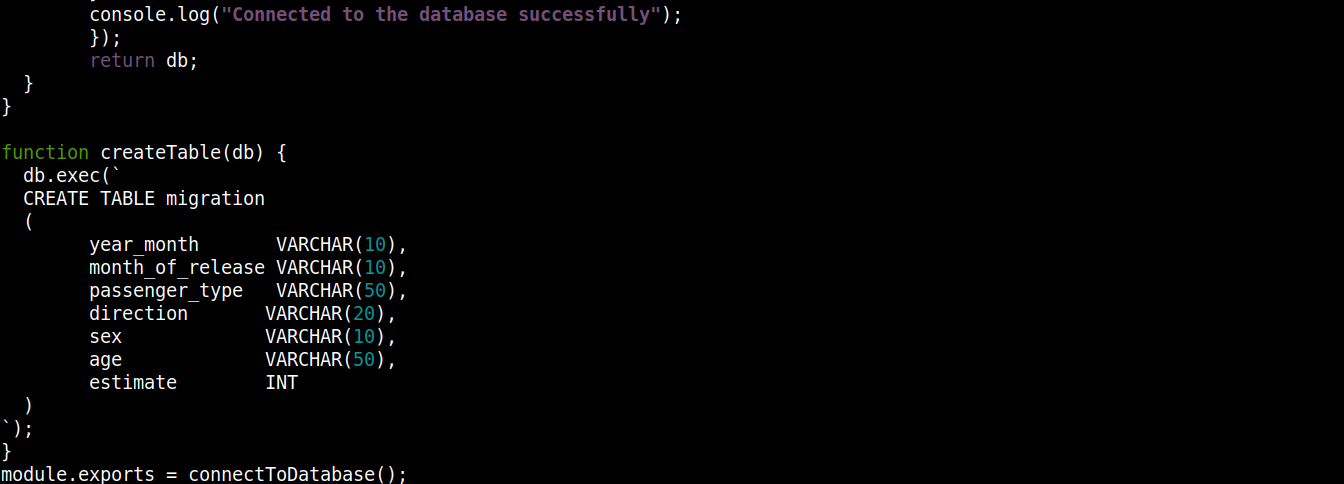
Tu,
-
Funkcia connectToDatabase() volá funkciu createTable(), ktorá ako argument prijíma objekt uložený v db ako argument.
-
Mimo connectToDatabase(), sme definovali metódu createTable(), ktorá ako parameter prijíma objekt pripojenia db ako parameter.
-
Metóda exec() na objekte db prijíma SQL príkaz ako argument. V rámci tohto SQL príkazu sme definovali vytvorenie tabuľky migration so 7 stĺpcami, pričom každý stĺpec zodpovedá hlavičkám stĺpcov v súbore migration_data.csv .
-
Na záver voláme funkciu connectToDatabase() metódu a exportovanie objektu pripojenia, ktorý vracia, aby sme ho mohli použiť v iných súboroch.
Uložte súbor a zatvorte editor.
Ďalej vytvoríme ďalší program na vloženie analyzovaných dát do databázy:
|
1 |
nano insert_data.js |
Zadajte nasledujúci kód do insert_data.js:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
const fs = require("fs"); const { parse } = require("csv-parse"); const db = require("./csv-to-sqlite3"); fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { db.serialize(function () { db.run( `INSERT INTO migration VALUES (?, ?, ? , ?, ?, ?, ?)`, [row[0], row[1], row[2], row[3], row[4], row[5], row[6]], function (error) { if (error) { return console.log(error.message); } console.log(`Row inserted, ID: ${this.lastID}`); } ); }); }); |
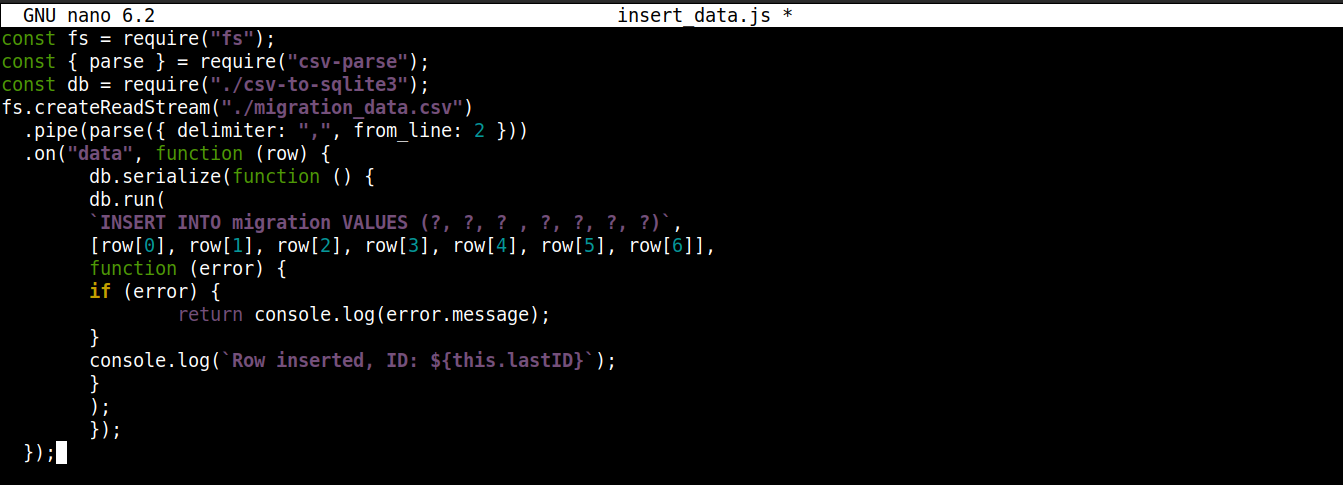
Tu,
-
Ukladáme objekt pripojenia získaný z csv-to-sqlite3.js v premennej db.
-
Vo vnútri spätného volania udalosti data (pripojeného k streamu modulu fs) voláme serialize() metódu na objekte pripojenia. Zaisťuje, že jeden SQL príkaz dokončí vykonávanie pred spustením ďalšieho, čím sa predchádza súbehom v databáze (systém spúšťajúci konkurenčné operácie súčasne).
-
Metóda serialize() prijíma tri argumenty:
-
Prvým argumentom je SQL príkaz.
-
Druhým argumentom je pole.
-
Tretím argumentom je spätné volanie, ktoré sa spustí, keď sa dáta úspešne alebo neúspešne vložia do databázy.
-
Sme pripravení spustiť program. Spustite insert_data.js pomocou Node.js:
|
1 |
node insert_data.js |
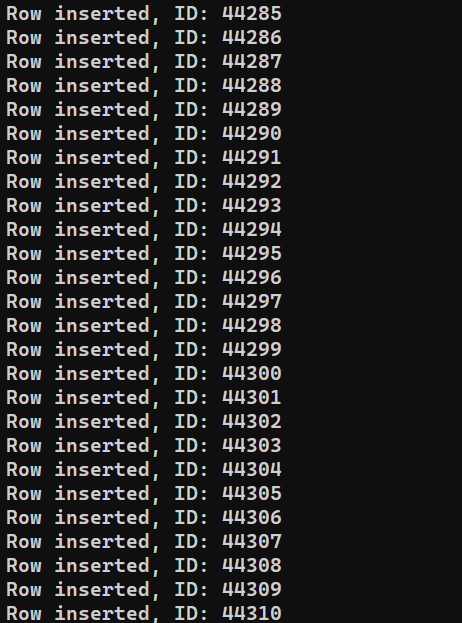
V závislosti od výkonu systému môže proces chvíľu trvať. Po dokončení by však výstup mal vyzerať približne takto:
Krok 5 – Zápis dát do CSV
Po predchádzajúcej časti máme databázu obsahujúcu všetky záznamy, ktoré sme analyzovali z migration_data.csv. V tejto časti budeme čítať dáta z databázy a zapisovať ich do samostatného súboru CSV.
Vytvorte nový JavaScript súbor na uloženie programu:
|
1 |
nano write_csv.js |
Najprv pridajte nasledujúce riadky na importovanie fs a csv-stringify spolu s objektom databázového pripojenia z csv-to-sqlite3.js:
|
1 2 3 |
const fs = require("fs"); const { stringify } = require("csv-stringify"); const db = require("./csv-to-sqlite3"); |
Ďalej pridáme premennú, ktorá obsahuje názov CSV súboru, do ktorého sa má zapisovať, spolu so zapisovateľným streamom:
|
1 2 3 4 5 6 7 8 9 10 11 |
const filename = "saved_from_db.csv"; const writableStream = fs.createWriteStream(filename); const columns = [ "year_month", "month_of_release", "passenger_type", "direction", "sex", "age", "estimate", ]; |
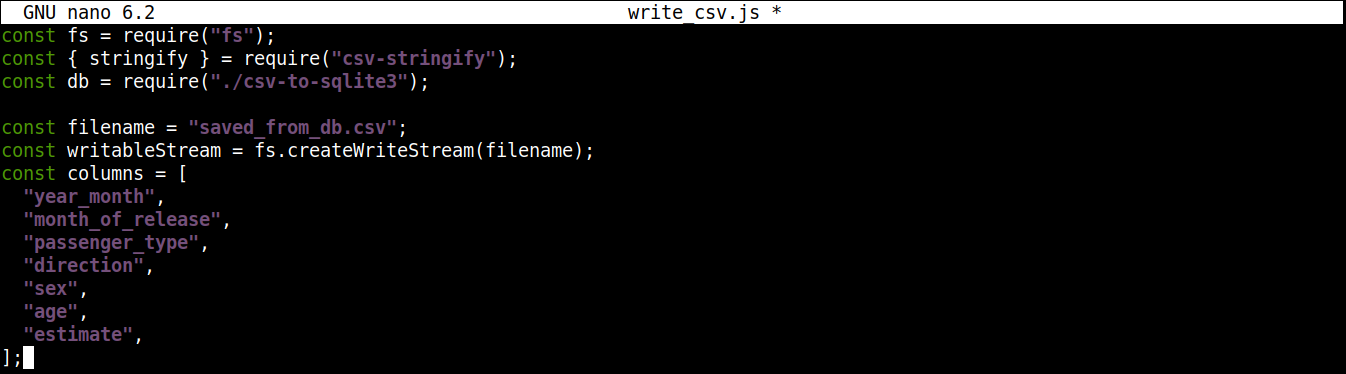
Tu,
-
Metóda createWriteStream() prijíma ako argument názov súboru, do ktorého sa má zapisovať. Súbor pomenujeme saved_from_db.csv.
-
Premenná column uchováva pole, ktoré obsahuje všetky názvy hlavičiek pre CSV dáta.
Ďalej pridajte nasledujúce riadky kódu na čítanie dát z databázy a ich zápis do saved_from_db.csv:
|
1 2 3 4 5 6 7 8 9 10 11 |
const stringifier = stringify({ header: true, columns: columns }); db.each(`select * from migration`, (error, row) => { if (error) { return console.log(error.message); } stringifier.write(row); }); stringifier.pipe(writableStream); console.log("finished writing to CSV"); |
Tu,
-
Voláme metódu stringify() s objektom ako argumentom. Výsledkom je transformačný stream, ktorý prevádza dáta z objektu do formátu CSV. Objekt odovzdaný metóde stringify() má dve vlastnosti:
-
header: Prijíma boolovskú hodnotu. Ak je hodnota true, vygeneruje sa hlavička.
-
columns: Prijíma pole, ktoré obsahuje názvy stĺpcov, ktoré sa majú zapísať do prvého riadku CSV súboru, ak header je true.
-
-
Metóda each() z objektu pripojenia csv-to-sqlite3 sa volá s dvoma argumentmi: SQL príkazom (čítanie dát z databázy) a callbackom (spracovanie úspechu/chyby).
-
Pri každej iterácii each(), pipe() (zo streamu stringifier) začne posielať dáta po častiach do zapisovateľného streamu writableStream. Každá časť dát sa potom zapíše do saved_from_db.csv.
-
Po zapísaní všetkých dát do CSV súboru sa na obrazovke konzoly zobrazí správa o úspechu.
Finálny kód by mal vyzerať takto:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
const fs = require("fs"); const { stringify } = require("csv-stringify"); const db = require("./csv-to-sqlite3"); const filename = "saved_from_db.csv"; const writableStream = fs.createWriteStream(filename); const columns = [ "year_month", "month_of_release", "passenger_type", "direction", "sex", "age", "estimate", ]; const stringifier = stringify({ header: true, columns: columns }); db.each(`select * from migration`, (error, row) => { if (error) { return console.log(error.message); } stringifier.write(row); }); stringifier.pipe(writableStream); console.log("dokončené zapisovanie do CSV"); |
Uložte súbor a zatvorte editor. Teraz môžeme program spustiť pomocou Node.js:
|
1 |
node write_csv.js |
Ak chcete overiť, či boli dáta úspešne exportované, skontrolujte obsah saved_from_db.csv:
|
1 |
cat saved_from_db.csv | less |
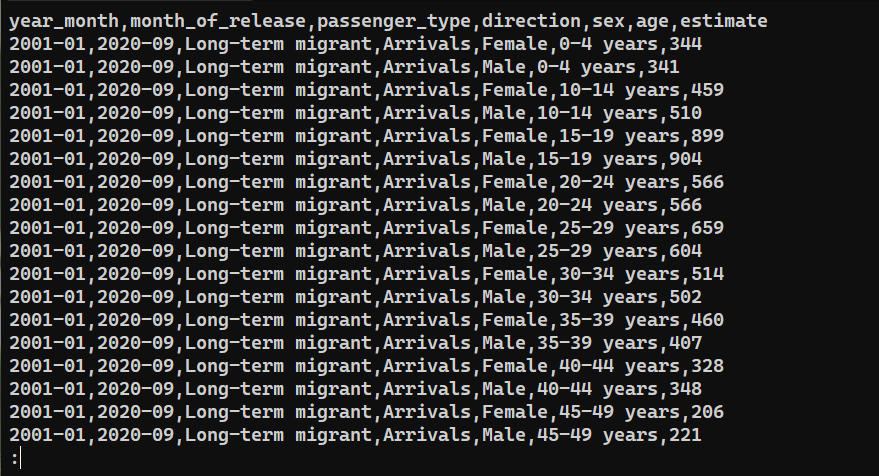
Záverečné myšlienky
V tomto návode sme si ukázali prácu so súbormi CSV v Node.js pomocou modulov node-csv a node-sqlite3. Vytvorili sme niekoľko programov na dosiahnutie rôznych úloh, napríklad parsovanie dát z CSV, vloženie dát do databázy SQLite a zápis dát do nového súboru CSV.
Tento návod ukazuje iba malú časť možností node-csv modulu. Viac o všetkých jeho funkciách sa dozviete na CSV Project. Ak sa chcete dozvedieť viac o node-sqlite3, pozrite si oficiálnu dokumentáciu na GitHube. Ďalším modulom, ktorý stojí za zmienku, je event-stream na zjednodušenie práce so streamami.
Máte záujem o ďalší rozvoj svojho projektu v Node.js? Tu je niekoľko návodov pre Node.js, ktoré by ste si mali pozrieť:
-
Ako nasadiť aplikáciu Node.js (Express.js) pomocou Dockeru na Ubuntu 20.04
-
Nastavenie aplikácií Node.js: Ako vykonávať produkčné úlohy na Ubuntu 20.04 s Node.js
Príjemné programovanie!
Komentáre
Zatiaľ žiadne komentáre. Buďte prvý.