

Tento návod vás prevedie nastavením Kubernetes klastra od nuly pomocou Ansible a Kubeadm a následným nasadením kontajnerizovanej Nginx aplikácie pomocou neho.
Úvod
Kubernetes (tiež známy ako k8s alebo “kube”) je open-source platforma na orchestráciu kontajnerov, ktorá automatizuje mnohé z manuálnych procesov spojených s nasadzovaním, správou a škálovaním kontajnerizovaných aplikácií. Kubernetes má rýchlo rastúcu open-source komunitu, ktorá aktívne prispieva do projektu. Pozrite si náš blogový príspevok, ktorý vás zoznámi so všetkým, čo potrebujete vedieť o základoch platformy Kubernetes.
Kubeadm je nástroj, ktorý konfiguruje niekoľko integrovaných prvkov, častí a komponentov, ako sú API server, Controller Manager a Kube DNS. Pomáha tiež automatizovať inštaláciu. Avšak nevytvára používateľov ani nerieši inštaláciu závislostí na úrovni operačného systému a ich konfiguráciu a nedokáže pripraviť vašu infraštruktúru.
Ansible je open-source nástroj na poskytovanie softvéru a nasadzovanie aplikácií. Saltstack je open-source softvér pre automatizáciu informačných technológií riadenú udalosťami. Toto sú dva nástroje, vďaka ktorým je vytváranie ďalších klastrov alebo opätovné vytváranie existujúcich klastrov menej náchylné na chyby a dajú sa použiť na tieto predbežné úlohy.
Ciele:
Váš klaster bude zahŕňať nasledujúce fyzické zdroje:
1. Jeden master uzol:
Master uzol je uzol, ktorý riadi a spravuje skupinu pracovných uzlov (runtime pre záťaže) a predstavuje klaster v Kubernetes. Obsahuje tiež plán zdrojov uzla na určenie správnej akcie pre spustenú udalosť. Beží na ňom etcd, distribuované úložisko kľúč-hodnota typu open-source, ktoré sa používa na uchovávanie a správu údajov klastra medzi komponentmi, ktoré plánujú záťaže pre pracovné uzly.
Plánovač (scheduler) by napríklad zistil, ktorý pracovný uzol bude hostiť novo naplánovaný POD.
2. Dva pracovné uzly:
Pracovné uzly sú uzly, ktoré pokračujú vo svojej pridelenej práci, aj keď master uzol po dokončení plánovania vypadne. Pracovné uzly sú servery, na ktorých pobežia vaše záťaže (t. j. kontajnerizované aplikácie a služby). Kapacitu klastra môžete zvýšiť aj pridaním ďalších pracovných uzlov.
Po dokončení tohto návodu budete mať plne funkčný klaster pripravený na spúšťanie záťaží (t. j. kontajnerizovaných aplikácií a služieb) za predpokladu, že servery v klastri majú dostatok prostriedkov CPU a RAM na beh vašich aplikácií. Po úspešnom nastavení klastra môžete spustiť takmer akúkoľvek tradičnú UNIX aplikáciu. Môže byť kontajnerizovaná vo vašom klastri, vrátane webových aplikácií, databáz, démonov a nástrojov príkazového riadku.
Samotný klaster spotrebuje približne 300-500 MB pamäte a 10 % CPU na každom uzle.
Požiadavky:
- Na svojom lokálnom Linux stroji musíte mať pár SSH kľúčov a musíte vedieť, ako SSH kľúče používať. Ak ste však SSH kľúče doteraz nepoužívali, môžete si pozrieť tento návod, ktorý vám pomôže nastaviť SSH kľúče na vašom lokálnom počítači.
- Tri servery so systémom Ubuntu 18.04, každý s minimálne 4 GB RAM a 4 vCPU. Mali by ste mať možnosť pripojiť sa cez SSH do každého servera ako používateľ root pomocou vášho páru SSH kľúčov. Postupujte podľa tohto návodu na inštaláciu vášho Ubuntu servera.
- Nainštalovaný Ansible na vašom lokálnom počítači.
- Musíte tiež poznať Ansible playbooky.
- Budete tiež musieť vedieť, ako spustiť kontajner z Docker obrazu. Pozrite si “Krok 5 — Práca s Docker obrazmi v Ubuntu” v Ako nainštalovať a používať Docker na Ubuntu 18.04 , ak si potrebujete osviežiť vedomosti.
Krok 1 — Nastavenie pracovného adresára (Workspace) a súboru inventára Ansible
Najprv musíte nastaviť Ansible na svojom lokálnom počítači. Pomôže vám spúšťať príkazy na vzdialenom serveri. Taktiež uľahčuje manuálne nasadzovanie tým, že ho automatizuje. Na tento účel budete musieť na svojom lokálnom počítači vytvoriť adresár, ktorý bude slúžiť ako váš dočasný digitálny úložný priestor (Workspace).
Po vytvorení adresára vytvoríte hosts súbor na uloženie všetkých informácií o IP adresách a skupine každého servera. Pomôže vám uložiť informácie o inventári. Ako už bolo spomenuté, k dispozícii budú tri servery, jeden master a dva workery. Master server bude master s IP adresou zobrazenou ako master_ip. Ostatné dva servery budú workery a budú mať IP adresy worker_1_ip a worker_2_ip.
Musíte vytvoriť adresár s názvom ~/kube-cluster v domovskom adresári vášho lokálneho počítača a vstúpiť do tohto adresára pomocou príkazu cd:
|
1 2 |
mkdir ~/kube-cluster cd ~/kube-cluster |
Adresár ~/kube-cluster bude teraz fungovať ako dočasná digitálna úložná oblasť (pracovný priestor), v ktorej budete spúšťať všetky lokálne príkazy na vytvorenie Kubernetes klastra pomocou kubeadm. Adresár bude obsahovať všetky vaše Ansible playbooky a bude sa používať po zvyšok návodu.
Vytvorenie súboru Hosts
Vytvorte súbor s názvom ~/kube-cluster/hosts pomocou nano alebo vášho obľúbeného textového editora:
|
1 |
nano ~/kube-cluster/hosts |
Teraz budete musieť pridať nasledujúci text, ktorý špecifikuje informácie o logickej štruktúre vášho klastra:
|
1 2 3 4 5 6 7 8 9 |
[masters] master ansible_host=master_ip ansible_user=root [workers] worker1 ansible_host=worker_1_ip ansible_user=root worker2 ansible_host=worker_2_ip ansible_user=root [all:vars] ansible_python_interpreter=/usr/bin/python3 |
Ako už bolo spomenuté, tento inventárny súbor vám pomôže uložiť všetky informácie o IP adresách vašich serverov a skupinách, do ktorých jednotlivé servery patria. ~/kube-cluster/hosts bude váš inventárny súbor a (masters a workers) budú dve skupiny Ansible, ktoré ste doň pridali a ktoré špecifikujú logickú štruktúru vášho klastra.
Skupina Master špecifikuje, že Ansible by mal spúšťať vzdialené príkazy ako používateľ root. Obsahuje tiež IP adresu master uzla (master_ip) ktorú možno uviesť pod záznamom servera s názvom “master”. Podobne skupina Workers má dva záznamy pre worker servery (worker_1_ip a worker_2_ip) ktoré tiež špecifikujú ansible_user ako root.
Posledný riadok súboru hovorí Ansible, aby pre svoje riadiace operácie používal interprety Python 3 na vzdialených serveroch. Nakoniec musíte súbor po pridaní textu uložiť a zatvoriť. Po nastavení adresára pracovného priestoru a inventárneho súboru Ansible prejdime k ďalšiemu kroku, ktorým je inštalácia závislostí na úrovni operačného systému a vytvorenie konfiguračných nastavení.
Krok 2 — Vytvorenie používateľa bez oprávnení root na všetkých vzdialených serveroch
V tomto kroku sa dozviete, ako vytvoriť používateľa bez oprávnení root s privilégiami sudo na všetkých serveroch, aby ste sa do nich mohli manuálne prihlásiť cez SSH ako neprivilegovaný používateľ.
To môže byť užitočné pre často vykonávané operácie na zachovanie klastra. Tento krok vám navyše pomôže vykonať úlohu presnejšie a s menším rizikom chýb, čím sa zníži pravdepodobnosť neúmyselnej zmeny alebo vymazania dôležitých súborov. Ak chcete zmeniť nastavenie súborov vlastnených rootom alebo zobraziť systémové informácie pomocou príkazov ako top/htop a zobraziť zoznam spustených kontajnerov, nasledujúci krok vám pomôže vykonať všetky tieto úlohy.
Vytvorenie playbooku
Vytvorte súbor s názvom ~/kube-cluster/initial.yml v pracovnom priestore:
|
1 |
nano ~/kube-cluster/initial.yml |
Ďalej musíte pridať nasledujúci play. Play v Ansible je kolekcia krokov, ktoré sa majú vykonať a ktoré sú zamerané na konkrétne servery a skupiny. V playbooku môže byť jeden alebo viacero playov.
Nasledujúci play vytvorí sudo používateľa bez oprávnení root:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
- hosts: all become: yes tasks: - name: vytvoriť ten 'ubuntu' používateľ user: name=ubuntu append=yes state=present createhome=yes shell=/bin/bash - name: povoliť 'ubuntu' aby mal bez hesla sudo lineinfile: dest: /etc/sudoers line: 'ubuntu ALL=(ALL) NOPASSWD: ALL' validate: 'visudo -cf %s' - name: nastaviť up autorizované kľúče pre the ubuntu používateľa authorized_key: user=ubuntu key="{{item}}" with_file: - ~/.ssh/id_rsa.pub |
Nasleduje rozbor toho, čo náš playbook robí:
- Tento playbook vytvorí používateľa bez oprávnení root
ubuntu. - Keďže potrebujete spúšťať
sudopríkazy bez výzvy na zadanie hesla, tento play nakonfiguruje súborsudoers, aby umožnil používateľoviubuntutak urobiť. - Hlavným účelom vyššie uvedenej úlohy bolo umožniť vám pripojiť sa cez SSH do každého servera ako
ubuntupoužívateľ. Tento playbook pridá verejný kľúč vášho lokálneho stroja (zvyčajne~/.ssh/id_rsa.pub) do zoznamu autorizovaných kľúčov vzdialenéhoubuntupoužívateľa.
Teraz, po pridaní textu, musíte súbor uložiť a zatvoriť.
Spustenie playbooku
Potom musíme spustiť náš playbook, ktorý vytvorí používateľa ubuntu bez oprávnení root, jednoduchým spustením na lokálnych strojoch:
|
1 |
ansible-playbook -i hosts ~/kube-cluster/initial.yml |
Vykonanie tohto príkazu bude nejaký čas trvať, po ktorom uvidíte nasledujúci výstup:
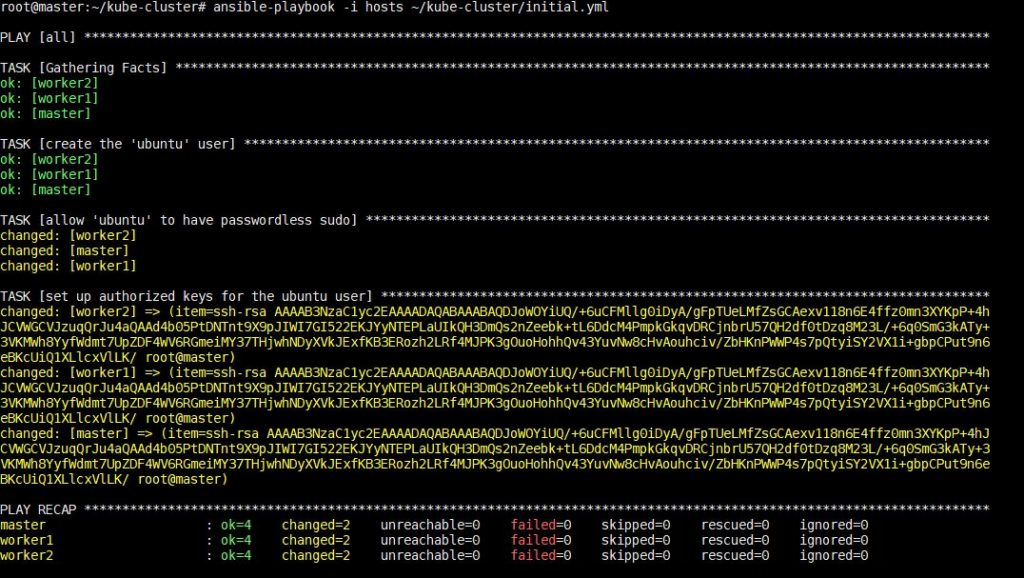
Po dokončení tohto kroku môžete v ďalšom kroku prejsť na inštaláciu závislostí špecifických pre Kubernetes.
Krok 3 — Inštalácia závislostí Kubernetes
V tomto kroku sa dozviete, ako nainštalovať balíky na úrovni operačného systému vyžadované systémom Kubernetes pomocou správcu balíkov systému Ubuntu.
Tieto balíky sú:
- Docker: Docker je platforma a nástroj na zostavovanie, distribúciu a spúšťanie kontajnerov Docker. Docker môžete jednoducho nastaviť podľa nášho návodu na ako nainštalovať a prevádzkovať Docker na Ubuntu vo verejnom cloude. Podpora pre iné runtime prostredia, ako napríklad rkt, je v Kubernetes pod aktívnym vývojom.
Kubeadm: kubeadm je nástroj príkazového riadka (CLI), ktorý vykonáva akcie potrebné na sprevádzkovanie minimálneho životaschopného klastra. To vám pomôže štandardným spôsobom nainštalovať a zostaviť rôzne komponenty klastra.kubelet: kubelet je hlavný “agent uzla”, ktorý beží na každom uzle a spracováva operácie na úrovni uzla.kubectl: kubectl je tiež nástroj príkazového riadka (CLI), ktorý komunikuje s vaším klastrom a vydáva príkazy prostredníctvom jeho API servera.
Vytvorenie playbooku
Vytvorte súbor s názvom ~/kube-cluster/kube-dependencies.yml v pracovnom priestore:
|
1 |
nano ~/kube-cluster/kube-dependencies.yml |
Teraz musíte do súboru pridať nasledujúce play, aby ste do svojich serverov nainštalovali tieto balíky:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
- hosts: all become: yes tasks: - name: nainštalovať Docker apt: name: docker.io state: present update_cache: true - name: nainštalovať APT Transport HTTPS apt: name: apt-transport-https state: present - name: pridať Kubernetes apt-key apt_key: url: https://packages.cloud.google.com/apt/doc/apt-key.gpg validate_certs: false state: present - name: pridať Kubernetes APT repozitár apt_repository: repo: deb http://apt.kubernetes.io/ kubernetes-xenial main state: present filename: 'kubernetes' - name: nainštalovať kubelet apt: name: kubelet=1.16.0-00 state: present update_cache: true - name: nainštalovať kubeadm apt: name: kubeadm=1.16.0-00 state: present - hosts: master become: yes tasks: - name: nainštalovať kubectl apt: name: kubectl=1.16.0-00 state: present force: yes |
Prvá časť (play) v playbooku robí nasledovné:
- Táto časť vám pomôže nainštalovať balíky na úrovni operačného systému, Docker – kontajnerové runtime prostredie.
- Inštaluje
apt-transport-https, čo vám umožňuje pridávať externé HTTPS zdroje do vášho zoznamu zdrojov APT. - Pridáva apt-key repozitára Kubernetes APT na overenie kľúča.
- Pridáva APT repozitár Kubernetes do zoznamu zdrojov APT vašich vzdialených serverov.
- Inštaluje
kubeletakubeadm.
Druhá časť vykonáva dôležitú a samostatnú úlohu, ktorá zahŕňa inštaláciu kubectl na vašom uzle master. Teraz po pridaní textu musíte súbor uložiť a zatvoriť.
Spustenie playbooku
Potom musíme spustiť náš playbook jednoduchým spustením na lokálnych počítačoch:
|
1 |
ansible-playbook -i hosts ~/kube-cluster/kube-dependencies.yml |
Spustenie tohto príkazu bude chvíľu trvať, potom uvidíte nasledujúci výstup:
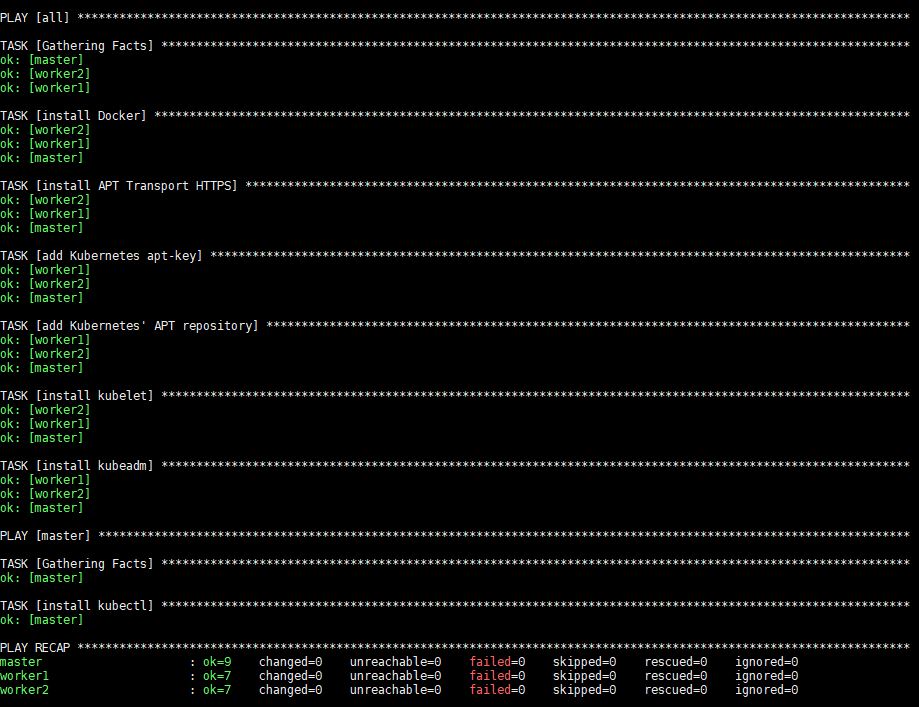
Po spustení budú Docker, kubeadm a kubelet nainštalované na všetkých vzdialených serveroch. Kubectl nie je povinný komponent a je potrebný iba na spúšťanie príkazov klastra. Jeho inštalácia iba na uzle master má v tomto kontexte zmysel, keďže budete spúšťať kubectl príkazy iba z uzla master. Upozorňujeme však, že kubectl príkazy je možné spustiť z ktoréhokoľvek z worker uzlov alebo z akéhokoľvek stroja, kde ich možno nainštalovať a nakonfigurovať tak, aby smerovali na cluster.
Všetky systémové závislosti sú teraz nainštalované. Nastavme master uzol a inicializujme cluster.
Krok 4 — Nastavenie Master uzla
V tomto kroku sa dozviete niekoľko konceptov, ako napríklad Pody a sieťové pluginy pre Pody keďže váš cluster bude po nastavení master uzla zahňať oboje.
Pody sú najmenšie, najzákladnejšie nasaditeľné objekty v Kubernetes. Pody obsahujú jeden alebo viac kontajnerov, napríklad kontajnery Docker. Keď Pod spúšťa viacero kontajnerov, tieto kontajnery sú spravované ako jeden celok a zdieľajú zdroje Podu.
Každý pod má svoju vlastnú IP adresu a pod na jednom uzle by mal mať prístup k podu na inom uzle pomocou IP adresy daného podu. Komunikácia medzi podmi je však zložitejšia. Vyžaduje si samostatný komponent, ktorý dokáže transparentne smerovať prevádzku z podu na jednom uzle do podu na druhom. Na túto funkciu sa používajú sieťové pluginy pre pody. K dispozícii je mnoho sieťových pluginov pre pody, ale my použijeme Flannel ako stabilnú a efektívnu možnosť.
Vytvorenie Playbooku
Vytvorte Ansible playbook s názvom master.yml na vašom lokálnom stroji:
|
1 |
nano ~/kube-cluster/master.yml |
Ďalej musíte do súboru pridať nasledujúci play na inicializáciu clustera a inštaláciu Flannelu:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
- hosts: master become: yes tasks: - name: inicializovaťthe cluster shell: kubeadm init --pod-network-cidr=10.244.0.0/16 >> cluster_initialized.txt args: chdir: $HOME creates: cluster_initialized.txt become: yes become_user: root - name: vytvoriť .adresár kube become: yes become_user: ubuntu file: path: $HOME/.kube state: directory mode: 0755 - name: skopírovať admin.conf do používateľskej 's kube konfigurácie copy: src: /etc/kubernetes/admin.conf dest: /home/ubuntu/.kube/config remote_src: yes owner: ubuntu - name: nainštalovať sieť pre Pody become: yes become_user: ubuntu shell: kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/2140ac876ef134e0ed5af15c65e414cf26827915/Documentation/kube-flannel.yml >> pod_network_setup.txt args: chdir: $HOME creates: pod_network_setup.txt |
Tu je rozbor tohto play:
- Prvá úloha v tomto play nastaví cluster spustením
kubeadm init. Na špecifikovanie privátnej podsiete, ktorá bude priradená IP adresám podov, odovzdáme argument--pod-network-cidr=10.244.0.0/16. Flannel predvolene používa vyššie uvedenú podsieť. Toto používame na to, aby sme povedalikubeadm, aby použil rovnakú podsieť. - Druhá úloha slúži na vytvorenie adresára
.kubev/home/ubuntu. V tomto adresári budú uložené konfiguračné informácie, ako sú súbory kľúčov správcu, ktoré sú potrebné na pripojenie ku clusteru, a adresa API clustera. - Tretia úloha slúži na skopírovanie súboru
/etc/kubernetes/admin.conf, ktorý bol vygenerovaný zkubeadm initdo domovského adresára vášho používateľa bez oprávnení root. To vám umožní použiťkubectlna prístup k novovytvorenému clusteru. - Posledná úloha spustí
kubectl applyna inštaláciuFlannel.kubectl apply -f descriptor.[yml|json]je syntax, ktorou hovorímekubectl, aby vytvoril objekty popísané v súboredescriptor.[yml|json]. Súborkube-flannel.ymlobsahuje popisy objektov potrebných na nastavenieFlannelv clusteri.
Teraz, po pridaní textu, musíte súbor uložiť a zatvoriť.
Spustenie Playbooku
Potom musíte spustiť náš playbook jednoduchým spustením na lokálnych strojoch:
|
1 |
ansible-playbook -i hosts ~/kube-cluster/master.yml |
Vykonanie tohto príkazu bude nejaký čas trvať, po ktorom uvidíte nasledujúci výstup:
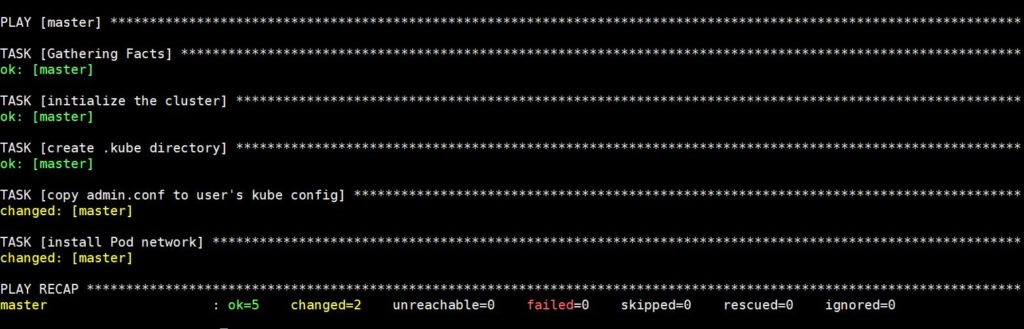
Teraz sa doň pripojte cez SSH pomocou nasledujúceho príkazu, aby ste skontrolovali stav hlavného uzla:
|
1 |
ssh ubuntu@master_ip |
Po vstupe do hlavného uzla vykonajte:
|
1 |
kubectl get nodes |
Teraz uvidíte nasledujúci výstup:

Po získaní vyššie uvedeného výstupu môžete vyhlásiť, že všetky úlohy nastavenia boli na hlavnom uzle dokončené a ten môže začať prijímať pracovné uzly a vykonávať úlohy, keďže prechádza do stavu Ready. Teraz môžete pridať pracovné uzly zo svojho lokálneho stroja.
Krok 5 — Nastavenie pracovných uzlov
Po nastavení hlavného uzla môžeme prejsť k ďalšiemu kroku, ktorým je nastavenie pracovných uzlov. Pridanie pracovných uzlov do clustera možno vykonať jednoducho spustením jediného príkazu na každom pracovnom serveri. Tento príkaz obsahuje dôležité informácie, ako je IP adresa, port API servera hlavného uzla a zabezpečený token. Mali by ste však vziať na vedomie, že nie všetky uzly sa budú môcť pripojiť ku clusteru – ku clusteru sa budú môcť pripojiť iba tie uzly, ktoré odovzdajú zabezpečený token.
Vytvorenie playbooku
Tento príkaz vám pomôže prejsť späť do vášho pracovného priestoru a vytvoriť playbook s názvom workers.yml:
|
1 |
nano ~/kube-cluster/workers.yml |
Pridaním nasledujúceho textu do súboru pridáte pracovné uzly do clustera:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
- hosts: master become: yes gather_facts: false tasks: - name: získať pripojovací príkaz shell: kubeadm token create --print-join-command register: join_command_raw - name: nastaviť pripojovací príkaz set_fact: join_command: "{{ join_command_raw.stdout_lines[0] }}" - hosts: workers become: yes tasks: - name: pripojiť sa ku clusteru shell: "{{ hostvars['master'].join_command }} >> node_joined.txt" args: chdir: $HOME creates: node_joined.txt |
Tu je to, čo playbook robí. Vo vyššie uvedenom kóde sú dve časti (plays):
- Prvá časť (play) sa používa na získanie príkazu na pripojenie, ktorý je potrebné spustiť na pracovných uzloch. Formát príkazu bude:
kubeadm join --token sha256:<hash><token><master-ip>:<master-port> --discovery-token-ca-cert-hash sha256:<hash>;. Úloha potrebuje získať správny token a hodnoty hash. Akonáhle získa správny vstup, úloha ho nastaví ako fakt (fact), aby k týmto informáciám mala prístup druhá časť (play). - Druhá časť (play) je napísaná iba na vykonanie jednej úlohy – urobiť z dvoch pracovných uzlov súčasť klastra jednoduchým spustením príkazu na pripojenie na všetkých pracovných uzloch.
Po pridaní textu musíte súbor uložiť a zatvoriť.
Spustenie playbooku
Potom musíme spustiť náš playbook spustením nasledujúceho príkazu na pracovných strojoch:
|
1 |
ansible-playbook -i hosts ~/kube-cluster/workers.yml |
Vykonanie tohto príkazu bude nejaký čas trvať, po ktorom uvidíte nasledujúci výstup:
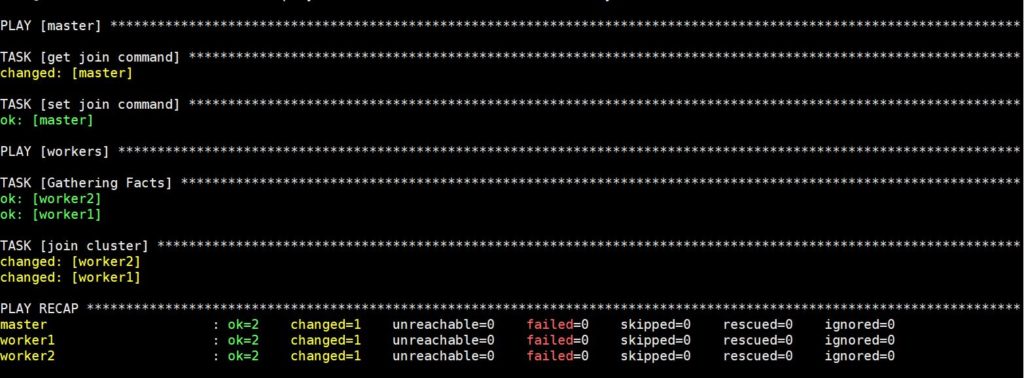
Teraz je váš Kubernetes klaster plne nastavený a funkčný, pričom pracovné uzly sú pripravené na spúšťanie záťaže. Pred prechodom na ďalší krok overme, či klaster funguje podľa plánu.
Krok 6 — Overenie klastra
Môžu nastať prípady, kedy klaster počas nastavovania zlyhá. Môže to byť spôsobené sieťovou chybou medzi riadiacim uzlom (master) a pracovným uzlom (worker), alebo problémom s uzlom. Preto musíme pred plánovaním aplikácií klaster overiť a uistiť sa, že nedochádza k žiadnym poruchám. Na to budete musieť skontrolovať aktuálny stav klastra z riadiaceho uzla (master), aby ste sa uistili, že uzly sú pripravené. Ak uzly nie sú pripravené alebo sa odpojíte, môžete obnoviť spojenie pomocou nasledujúceho príkazu:
|
1 |
ssh ubuntu@master_ip |
Na získanie stavu klastra použite nasledujúce príkazy:
|
1 |
kubectl get nodes |
Vykonanie tohto príkazu bude nejaký čas trvať, po ktorom uvidíte nasledujúci výstup:

Musíte skontrolovať, či sú všetky uzly, ktoré sú súčasťou klastra, v stave ready (pripravené). Ak má niekoľko uzlov Not Ready ako STATUS, ukazuje to, že pracovné uzly ešte nedokončili svoje nastavenie. Pred opätovným spustením kubectl get nodes a kontrolou aktualizovaného výstupu by ste mali počkať ďalších päť až desať minút. Ak niektoré uzly stále zobrazujú Not Ready ako svoj stav, mali by ste skontrolovať predchádzajúce kroky a znova spustiť príkazy. Iba ak majú uzly pre STATUS hodnotu Ready, sú súčasťou klastra a sú pripravené na spúšťanie záťaže. Po úspešnom vykonaní 6. kroku je váš klaster overený. Teraz naplánujme ukážkovú aplikáciu Nginx v klastri.
Krok 7 — Spustenie aplikácie v klastri
Vytvorenie nasadenia (Deployment)
Po úspešnom vytvorení klastra môžete do svojho klastra nasadiť akúkoľvek kontajnerizovanú aplikáciu. Ak sa nachádzate v riadiacom uzle (master), môžete pre iné kontajnerizované aplikácie použiť nasledujúce príkazy nižšie. Ďalej spustite nasledujúci príkaz na vytvorenie nasadenia (deploymentu) s názvom nginx :
|
1 |
kubectl create deployment nginx --image=nginx |
Musíte zmeniť názov Docker obrazu (image) a všetky príslušné príznaky (ako sú porty a zväzky). Aby sme zachovali známe prostredie, môžete nasadiť Nginx pomocou deploymentov a služieb (services), aby ste videli, ako sa dajú aplikácie nasadzovať do klastra.
A Kubernetes deployment je objekt prostriedku v Kubernetes, ktorý poskytuje deklaratívne aktualizácie pre aplikácie. Deployment vám umožňuje opísať životný cyklus aplikácie, ako je obraz kontajnera, repliky a stratégia aktualizácie. Deployment zabezpečuje, že požadovaný počet podov beží a je neustále k dispozícii. Ak pod počas životnosti klastra spadne, znova ho vytvorí. Proces aktualizácie je tiež kompletne zaznamenávaný a verziovaný s možnosťami pozastavenia, pokračovania a vrátenia zmien na predchádzajúce verzie. Vyššie uvedený príkaz na vytvorenie deploymentu s názvom Nginx vám pomôže nasadiť pod s jedným kontajnerom z Docker obrazu Nginx v Docker registri.
Nastavenie Node Portu
Ďalej musíme vytvoriť NodePort. NodePort je otvorený port na každom uzle vášho klastra. Kubernetes transparentne smeruje prichádzajúcu prevádzku na NodePort do vašej služby, aj keď vaša aplikácia beží na inom uzle. Na tento účel môžeme použiť tento príkaz na vytvorenie prostriedku NodePort s názvom Nginx, ktorý aplikáciu verejne sprístupní:
|
1 |
kubectl expose deploy nginx --port 80 --target-port 80 --type NodePort |
Služba (service) je ďalší objekt Kubernetes zodpovedný za sprístupnenie rozhrania pre tieto pody, čo umožňuje sieťový prístup buď zvnútra klastra, alebo medzi externými procesmi a službou. Môže byť definovaná ako abstrakcia nad podom, ktorá poskytuje jedinú IP adresu a DNS názov, prostredníctvom ktorých je možné k podom pristupovať. So službou je veľmi jednoduché spravovať konfiguráciu vyrovnávania záťaže.
Spustite nasledujúci príkaz:
|
1 |
kubectl get services |
Týmto sa vypíše text podobný nasledujúcemu:

Po získaní výstupu Kubernetes automaticky priradí náhodný port, ktorý je väčší ako 30000, pričom sa zároveň uistí, že priradený port už nie je obsadený inou službou. Tretí riadok vyššie uvedeného výstupu vám pomôže zistiť port, na ktorom Nginx beží.
Ak chcete overiť, či to funguje, navštívte http://worker_1_ip:nginx_port alebo http://worker_2_ip:nginx_port cez prehliadač na vašom lokálnom počítači. Uvidíte známu uvítaciu stránku Nginx.
Odstránenie deploymentu
Ak chcete odstrániť aplikáciu Nginx, musíte najprv vymazať službu nginx z hlavného uzla:
|
1 |
kubectl delete service nginx |
Ak chcete overiť, že aplikácia je definitívne vymazaná, musíte spustiť tento príkaz:
|
1 |
kubectl get services |
Dostanete nasledujúci výstup:

Potom musíte vymazať deployment pomocou nasledujúceho príkazu:
|
1 |
kubectl delete deployment nginx |
Tento príkaz môžete použiť na overenie, či je deployment definitívne vymazaný:
|
1 |
kubectl get deployments |
![]()
Záver:
Tento návod vám pomôže správne nastaviť klaster na Ubuntu 18.04 pomocou nástrojov Kubeadm a Ansible. Teraz, keď je váš klaster nastavený, môžete jednoducho začať nasadzovať vlastné aplikácie a služby.
Tu je zoznam odkazov s ďalšími podrobnosťami, ktoré vás procesom prevedú:
- Dockerizácia aplikácií – Tento odkaz obsahuje príklady, ktoré vás navedú, ako spúšťať aplikácie pomocou Dockeru. Napríklad dockerizácia PostgreSQL, služby CouchDB atď.
- Prehľad podov – Tento odkaz zobrazuje podrobnosti o tom, ako používať pod, ako pody fungujú a ako súvisia s inými objektmi Kubernetes. Pody sú dôležitou súčasťou Kubernetes, takže ich pochopenie vám pomôže uspieť vo vašej úlohe.
- Prehľad deploymentov – Pomôže vám dozvedieť sa viac o deploymentoch. Deployment poskytuje deklaratívne aktualizácie pre pody (Pods) a ReplicaSety. Dozviete sa, ako aktualizovať, preklápať a vracať späť deployment.
- Prehľad služieb - Tento odkaz vás prevedie službami, ktoré sú ďalším často používaným objektom v klastroch Kubernetes. Služba v Kubernetes je abstrakcia, ktorá definuje logickú sadu podov a pravidlá, podľa ktorých k nim môžete pristupovať. Pochopenie typov služieb a možností, ktoré ponúkajú, je nevyhnutné pre beh bezstavových aj stavových aplikácií.
Okrem toho sa pozrite na naše ďalšie návody zamerané na Docker a Kubernetes, ktoré nájdete na našom blogu:
- Zoznámenie sa s Kubernetes
- Vyčistenie Docker prostriedkov – obrazy, kontajnery a zväzky
- Ako spustiť Docker na CloudSigma (s CloudInit) Aktualizované
- Inštalácia a nastavenie Docker na CentOS 7
- Ako nainštalovať & prevádzkovať Docker na Ubuntu vo verejnom cloude
Existuje tiež mnoho ďalších dôležitých konceptov, ako napríklad Zväzky, Ingressy, a Secrets ktoré môžete použiť pri nasadzovaní produkčných aplikácií.
Príjemnú prácu!
Komentáre
Zatiaľ žiadne komentáre. Buďte prvý.