

Web scraping, web crawling, web harvesting alebo extrakcia webových dát sú synonymá označujúce proces dolovania dát z webových stránok na internete. Webové scrapery alebo webové crawlery sú nástroje, ktoré programovo prechádzajú webové stránky a extrahujú požadované dáta. Tieto dáta, ktoré zvyčajne predstavujú veľké súbory textu, sa môžu použiť na analytické účely, na pochopenie produktov alebo na uspokojenie zvedavosti o určitej webovej stránke.
Ak vás zaujíma, ako začať s web crawlingom, ukážeme vám základy web scrapingu na jednoduchom súbore dát. Tento návod by ste mali byť schopní sledovať bez ohľadu na úroveň vašich programátorských znalostí. Pre praktický príklad použijeme náš blog CloudSigma. Pokúsime sa získať informácie o návodoch na našej blogovej stránke. Kým sa dostanete k záveru tohto návodu, budete mať funkčný web scraper vytvorený pomocou Python 3, ktorý prechádza niekoľko stránok v našej sekcii blogu a následne zobrazuje dáta na vašej obrazovke.
S využitím znalostí z vytvorenia tohto základného web scrapera ho môžete ďalej rozširovať a vytvárať si vlastné web scrapery. Mala by to byť zábava, poďme na to!
Požiadavky
Toto je praktický návod, takže by ste mali mať lokálne vývojové prostredie pre Python 3, aby ste ho mohli bez problémov sledovať. Najprv si môžete prečítať náš návod, ako nainštalovať Python 3 a nastaviť lokálne programovacie prostredie na Ubuntu.
Scrapy
Web scraping zahŕňa dva kroky: prvým krokom je nájdenie a stiahnutie webových stránok, druhým krokom je ich prechádzanie a extrahovanie informácií z týchto webových stránok.
Existuje mnoho spôsobov a knižníc, ktoré sa dajú použiť na vytvorenie web scrapera od nuly v mnohých programovacích jazykoch. To však môže v budúcnosti priniesť problémy, keď sa váš web scraper stane komplexným, alebo keď budete potrebovať prechádzať viacero stránok s rôznymi nastaveniami a vzormi naraz. Môže byť pomerne náročnou úlohou prísť na to, ako transformovať získané dáta medzi rôznymi formátmi, ako sú CSV, XML alebo JSON.
Hoci niekto môže oceniť výzvu postaviť si vlastný web scraper od nuly, je lepšie nevymýšľať koleso a radšej ho postaviť na základe existujúcej knižnice, ktorá rieši všetky tieto problémy. Budeme používať Scrapy, knižnicu pre Python, spolu s Python 3 na implementáciu web scrapera v tomto návode. Scrapy je open-source nástroj a jedna z najpopulárnejších a najvýkonnejších knižníc na web scraping v Pythone. Scrapy bol vytvorený tak, aby zvládal niektoré z bežných funkcií, ktoré by mali mať všetky scrapery. Týmto spôsobom nemusíte zakaždým vymýšľať koleso, keď chcete implementovať web crawler. So Scrapy sa proces tvorby scrapera stáva jednoduchým a zábavným.
Scrapy je k dispozícii na PyPi, bežne známom ako pip – Python Package Index. PyPi je repozitár vlastnený komunitou, ktorý hostí väčšinu balíkov pre Python. Keď si nainštalujete a nastavíte Python 3 vo svojom lokálnom vývojovom prostredí, nainštaluje sa aj pip, ktorý môžete použiť na inštaláciu balíkov Pythonu.
Krok 1: Ako vytvoriť jednoduchý web scraper
Najprv pre inštaláciu Scrapy spustite nasledujúci príkaz:
|
1 |
pip install scrapy |
Voliteľne môžete postupovať podľa oficiálnych pokynov na inštaláciu Scrapy zo stránky s dokumentáciou. Ak ste úspešne nainštalovali Scrapy, vytvorte priečinok pre projekt s názvom podľa vlastného výberu:
|
1 |
mkdir cloudsigma-crawler |
Prejdite do priečinka a vytvorte hlavný súbor pre kód. Tento súbor bude obsahovať všetok kód pre tento návod:
|
1 |
touch main.py |
Ak chcete, môžete súbor vytvoriť pomocou textového editora alebo IDE namiesto vyššie uvedeného príkazu.
Ďalej otvorte súbor a začnime vytvorením základného scrapera, ktorý používa Scrapy. Vytvoríme triedu v Pythone, ktorá rozširuje scrapy.Spider, základnú triedu spidera zo Scrapy. Táto trieda bude mať dva požadované atribúty definované nižšie:
- name — reťazcový názov na identifikáciu spidera (môžete zadať názov podľa vlastného výberu).
- start_urls — pole obsahujúce zoznam URL adries, z ktorých sa má začať prechádzanie. Začneme s jednou URL adresou.
Pridajte nasledujúci úryvok kódu do otvoreného súboru, aby ste vytvorili základného spidera:
|
1 2 3 4 5 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] |
Nižšie je vysvetlenie každého riadku kódu:
Prvý riadok importuje Scrapy, čo nám umožňuje používať rôzne triedy, ktoré tento balík poskytuje.
V ďalšom riadku rozširujeme triedu Spider poskytovanú knižnicou Scrapy a vytvárame podtriedu s názvom CloudSigmaCrawler. Rozšírením triedy (Spider) získame prístup k vlastnostiam triedy, ktoré teraz môžeme použiť v našom kóde. V tomto prípade má trieda Spider metódy a správanie, ktoré definujú, ako sledovať adresy URL a extrahovať dáta z webových stránok. Nevie však, ktoré adresy URL má sledovať alebo aké dáta má extrahovať. Jej rozšírením môžeme metódam poskytnúť požadované informácie. Ak sa chcete dozvedieť viac o vytváraní podtried a rozširovaní, čítajte ďalej Princípy objektovo orientovaného programovania.
V našom CloudSigmaCrawler definujeme požadované atribúty. Najprv pomenujeme nášho spidera cloudsigma_crawler. Potom poskytneme jednu počiatočnú URL adresu: https://blog.cloudsigma.com/blog/. Otvorenie tejto URL adresy vás presmeruje na 1. stránku blogu CloudSigma, ktorá obsahuje niektoré z mnohých návodov.
Je čas otestovať scraper. Máte niekoľko možností. Ak používate IDE, napríklad PyCharm community edition od JetBrains, pravdepodobne obsahuje tlačidlo, na ktoré stačí kliknúť a spustiť skript. Ďalšou možnosťou je postupovať typickým spôsobom spúšťania súborov Python z príkazového riadku: python cesta/k/suboru.py alebo py cesta/k/suboru.py. Ďalšou možnosťou je príkazový riadok Scrapy rozhranie. Scrapy prichádza s vlastným rozhraním príkazového riadku, ktoré pomáha pri spúšťaní scrapera. Pre spustenie scrapera zadajte nasledujúci príkaz:
|
1 |
scrapy runspider main.py |
V závislosti od nainštalovanej verzie knižnice Scrapy by ste mali vidieť výstup, ktorý vyzerá približne takto:
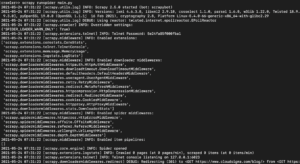
Ako môžete vidieť, výstup je pomerne dlhý, preto sme vybrali len niektoré časti. Tu je to, čo sa stalo po spustení príkazu:
- Scraper bol inicializovaný. Preto načítal ďalšie komponenty a rozšírenia, ktoré potrebuje na sledovanie a čítanie dát z URL adries.
- Použitím URL adresy uvedenej v zozname start_urls stiahol HTML zo stránky. Ide o podobný proces, akým prechádza prehliadač pri otváraní webových stránok.
- Po stiahnutí HTML sa toto odovzdá metóde parse, ktorú sme ešte nedefinovali. Zatiaľ nič nerobí, preto spider jednoducho skončí bez akéhokoľvek spracovania. Správanie metódy parse definujeme v nasledujúcom kroku.
Krok 2: Ako extrahovať dáta zo stránky
V kroku 1 sme implementovali iba základný scraper, ktorý stiahne HTML stránku, ale potom nič nerobí. V tejto časti poskytneme pokyny na extrakciu dát. Na stránke CloudSigma Blog, z ktorej chceme extrahovať dáta, si môžete všimnúť niekoľko vecí, ako napríklad:
- Hlavička, ktorá sa nachádza na všetkých stránkach.
- Navigačné menu a pole vyhľadávacieho filtra.
- Samotný zoznam návodov vo formáte mriežky.
Zobrazenie zdrojového kódu HTML stránky, ktorú chcete scrapovať, vám poskytne všeobecnú predstavu o štruktúre stránky. To vám pomôže pri písaní scrapera. Zdrojový kód si môžete zobraziť kliknutím pravým tlačidlom myši na stránku a výberom možnosti Zobraziť zdrojový kód alebo stlačením klávesov Ctrl + U. Tu je úryvok zdrojového kódu:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
<body> <div id="x-iso-container" class="x-iso-container x-iso-container-posts cols-3"> <article id="post-51691" class="post-51691 post type-post status-publish format-standard has-post-thumbnail hentry category-blog-posts category-tutorials tag-apache tag-certbot tag-cloud-guide tag-cloud-tutorial tag-https tag-lets-encrypt tag-ssl tag-ssl-certification tag-tutorial tag-ubuntu"> <div class="entry-wrap"> <header class="entry-header"> <h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Permalink to: "Zabezpečenie Apache pomocou Let’s Encrypt na Ubuntu 18.04"">Zabezpečenie Apache pomocou Let’s Encrypt na Ubuntu 18.04</a> </h2> </header> <div class="entry-content excerpt"> <p>Bezpečnosť webových stránok a údajov sú témy, ktoré nemožno brať na ľahkú váhu. Vysoko citlivé informácie, ktoré zahŕňajú finančné záznamy a súkromné informácie zákazníkov, sa neustále prenášajú medzi počítačom používateľa a vašou webovou stránkou. Keď vezmete do úvahy túto skutočnosť, nie je ťažké pochopiť, prečo by nezabezpečené webové stránky mohli viesť k narušeniu bezpečnosti, ktoré by mohlo vážne poškodiť vaše podnikanie. Existuje … </p> <div><a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="more-link">Čítať viac</a></div> </div> </div> ... </article> </div> </body> |
Ako môžete vidieť, každý návod na blogu je uzavretý v HTML značke nazývanej <article>. Scrapovanie stránky bude zahŕňať dva kroky. Prvým krokom bude získanie každého návodu na blogu vyhľadaním častí stránky, ktoré obsahujú požadované údaje. Ďalším krokom je vytiahnutie požadovaných údajov z každého návodu identifikovaného pomocou HTML značky.
Scrapy identifikuje údaje, ktoré sa majú získať, na základe selektorov, ktoré poskytnete. Selektory môžeme použiť na nájdenie jedného alebo viacerých prvkov na stránke a získanie údajov v rámci týchto prvkov. Scrapy má podporu pre XPath a CSS selektory.
Zo zdroja, ktorý sme si pozreli predtým, sa zdajú byť CSS selektory jednoduchšie. Preto to bude možnosť, pre ktorú sa rozhodneme, pretože nám pomôže nájsť všetky návody na stránke. V HTML zdrojovom kóde je každý návod špecifikovaný v rámci CSS triedy s názvom post. Názvy CSS tried sa zvyčajne identifikujú pomocou .class_name (bodka class_name). Pre náš CSS selektor teda použijeme .post. V našom zdrojovom kóde scrapera main.py odovzdáme triedu .post objektu response, takže váš súbor bude teraz vyzerať takto:
|
1 2 3 4 5 6 7 8 9 10 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): pass |
Tento útržok kódu získa všetky návody na stránke so špecifikovanými start_urls a prejde ich v cykle, aby extrahoval dáta. V ďalšom kroku budete chcieť tieto dáta extrahovať a zobraziť. Ak znova preskúmate zdrojový kód blogu CloudSigma, uvidíte, že názov každého návodu je uložený v značke <a>, ktorá sa nachádza v značke <h2>, napríklad:
|
1 2 3 4 5 |
<h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Trvalý odkaz na: "Zabezpečenie Apache pomocou Let’s Encrypt na Ubuntu 18.04"">Zabezpečenie Apache pomocou Let’s Encrypt na Ubuntu 18.04</a> </h2> |
Každý objekt návodu, cez ktorý prechádzame v cykle, obsahuje metódu CSS, ktorej môžeme odovzdať selektor na vyhľadanie a extrahovanie dcérskych prvkov. V tomto príklade chceme extrahovať názov, ktorý je uzavretý v značke <a>. Táto značka sa nachádza v značke <h2> vo vnútri triedy .entry-header vo vnútri triedy .entry-wrap. Tieto CSS selektory môžeme odovzdať metóde objektu na extrahovanie názvu, upravte kód tak, aby vyzeral takto:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), } |
Čiarka na konci za extract_first() nie je preklep, pretože pod túto sekciu budeme pridávať ďalší kód.
Medzi dôležité body, ktoré si treba všimnúť vo vyššie uvedenom zdrojovom kóde, patria:
- ::text pripojený k selektoru – toto je CSS pseudo-selektor, ktorý inštruuje kód, aby získal text vo vnútri značky a nie značku samotnú.
- volanie metódy extract_first() v rámci objektu – inštruuje kód, aby vybral iba prvý prvok, ktorý zodpovedá selektoru. Vďaka tomu získame reťazec namiesto zoznamu prvkov.
Potom súbor uložte a spustite kód zadaním nasledujúceho príkazu do terminálu:
|
1 |
scrapy runspider main.py |
Vo výstupe by ste mali vidieť názvy tutoriálov:
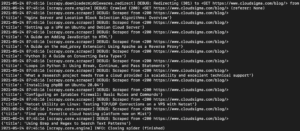
Môžeme to ďalej rozširovať pridávaním ďalších selektorov, aby sme získali ďalšie podrobnosti o tutoriáli, ako je URL adresa tutoriálu, hlavný obrázok a popisok.
Pozrime sa znova na HTML kód pre jeden tutoriál:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
<body> <div id="x-iso-container" class="x-iso-container x-iso-container-posts cols-3"> <article id="post-51691" class="post-51691 post type-post status-publish format-standard has-post-thumbnail hentry category-blog-posts category-tutorials tag-apache tag-certbot tag-cloud-guide tag-cloud-tutorial tag-https tag-lets-encrypt tag-ssl tag-ssl-certification tag-tutorial tag-ubuntu"> <div class="entry-featured"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="entry-thumb" title="Trvalý odkaz na: "Securing Apache with Let’s Encrypt on Ubuntu 18.04""> <img width="1000" height="522" src="data:image/svg+xml,%3Csvg%20xmlns='http://www.w3.org/2000/svg'%20viewBox='0%200%201000%20522'%3E%3C/svg%3E" class="attachment-entry-fullwidth size-entry-fullwidth wp-post-image" alt="Let’s Encrypt" loading="lazy" data-lazy-srcset="/media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04.jpg 1000w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-300x157.jpg 300w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-768x401.jpg 768w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-610x318.jpg 610w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-100x52.jpg 100w" data-lazy-sizes="(max-width: 1000px) 100vw, 1000px" data-lazy-src="/media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04.jpg"/> </a> </div> <div class="entry-wrap"> <header class="entry-header"> <h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Permalink to: "Zabezpečenie Apache pomocou Let’s Encrypt na Ubuntu 18.04"">Zabezpečenie Apache pomocou Let’s Encrypt na Ubuntu 18.04</a> </h2> </header> <div class="entry-content excerpt"> <p>Bezpečnosť webových stránok a dát sú témy, ktoré nemožno brať na ľahkú váhu. Veľmi citlivé informácie, ktoré zahŕňajú finančné záznamy a súkromné informácie zákazníkov, sa neustále prenášajú medzi počítačom používateľa a vašou webovou stránkou. Keď vezmete do úvahy túto skutočnosť, nie je ťažké pochopiť, prečo nezabezpečené webové stránky môžu viesť k úniku údajov, ktorý by mohol vážne poškodiť vaše podnikanie. Existuje … </p> <div><a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="more-link">Čítať viac</a></div> </div> </div> </article> </div> </body> |
Chceme sa pokúsiť extrahovať zvýraznené časti, t. j. URL adresu návodu, hlavný obrázok a popis.
- Z vyššie uvedeného úryvku kódu je zrejmé, že obrázok pre blog je uložený v atribúte data-lazy-src značky img vo vnútri značky <a> vo vnútri značky div na začiatku návodu k blogu. Na získanie tejto hodnoty môžeme použiť CSS selektor, rovnako ako sme to urobili pri názvoch návodov.
- Získanie URL adresy návodu je jednoduché, keďže máme značku <a> vo vnútri prvku <div>.
- Popis je uzavretý vo vnútri značky <p>, ktorá sa nachádza vo vnútri značky <div>.
Na získanie toho, čo chceme, použijeme CSS triedy. Upravme kód tak, aby vyzeral takto:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), 'caption': tutorial.css(CAPTION_SELECTOR).extract_first(), } |
Uložte zmeny a spustite kód pomocou nasledujúceho príkazu:
|
1 |
scrapy runspider main.py |
Vo výstupe uvidíte viac údajov, ako napríklad URL, obrázok a popis, ktoré sme pridali:

To je všetko pre prechádzanie jednej stránky. Ďalej sa pozrime na to, ako môžeme vytvoriť scraper, ktorý nasleduje odkazy.
Krok 3: Ako prechádzať viacero stránok
Až do tohto bodu sme vytvorili scraper, ktorý dokáže získať údaje z jednej stránky. My však chceme viac. Chcete spidera, ktorý dokáže nasledovať odkazy a programovo extrahovať údaje z viacerých stránok webu.
Ak prejdete na spodok stránky blogu CloudSigma, všimnete si odkazy na stránkovanie a malú šípku ukazujúcu doprava, ktorá označuje nasledujúcu stránku. Tu je ukážka HTML kódu:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<div class="x-pagination"> <ul class="center-list center-text"> <li><span class="pages">Stránka 1 z 45</span></li> <li></li> <li><span class="current">1</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/2/" class="single_page" title="2">2</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="single_page" title="3">3</a></li> <li><span class="expand">...</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/45/" class="last" title="Posledná stránka">45</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/2/" class="prev-next hidden-phone">→</a></li> </ul> </div> |
Ukážka zobrazuje niekoľko odkazov na navigáciu stránok v rámci značiek <li>, pod značkou <div> s triedou CSS .x-pagination. Zameriavame sa na odkaz ukazujúci na nasledujúcu stránku. Nachádza sa v značke <a> posledného <li> v značke <ul>.
Odkaz ukazujúci na nasledujúcu stránku má triedu .prev-next v rámci značky <a>, ako je vidieť v ukážke vyššie. Ak sa však presuniete na nasledujúcu stránku, všimnete si tiež, že odkazy na predchádzajúcu a nasledujúcu stránku majú túto triedu CSS. Zvážte túto ukážku pre stránku 2:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<div class="x-pagination"> <ul class="center-list center-text"> <li><span class="pages">Strana 2 z 45</span></li> <li><a href="https://blog.cloudsigma.com/blog/" class="prev-next hidden-phone">←</a></li> <li><a href="https://blog.cloudsigma.com/blog/" class="single_page" title="1">1</a></li> <li><span class="current">2</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="single_page" title="3">3</a></li> <li><span class="expand">...</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/45/" class="last" title="Posledná strana">45</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="prev-next hidden-phone">→</a></li> </ul> </div> |
Ak použijeme metódu Scrapy extract_first(), bude fungovať na prvej stránke. Keď sa dostane na ďalšiu stránku, vyberie prvý odkaz s triedou .prev-next, ktorý vo vyššie uvedenom fragmente kódu ukazuje na prvú stránku. To spôsobí slučku. Preto použijeme metódu Scrapy extract(). Táto metóda extrahuje všetky prvky zodpovedajúce prípadu použitia a vloží ich do poľa. Z tohto poľa môžeme vybrať posledný prvok, ktorý bude obsahovať skutočný odkaz ukazujúci na ďalšiu stránku. Upravte svoj kód tak, aby vyzeral takto:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), } NEXT_PAGE_SELECTOR = '.x-pagination > ul.center-list > li > a.prev-next::attr("href")' next_page = response.css(NEXT_PAGE_SELECTOR).extract() if next_page: yield scrapy.Request( response.urljoin(next_page[-1]), callback=self.parse ) |
Poďme si prejsť kód pre výber next_page.
Najprv definujeme selektor pre odkazy na nasledujúcu a predchádzajúcu stránku. Potom použijeme metódu extract() na extrahovanie URL adries a ich vloženie do poľa. Premenná next_page bude pole s dvoma prvkami ako:
|
1 |
next_page = [prev_page_url, next_page_url] |
Keďže prechádzame na nasledujúcu stránku, vyberieme posledný prvok v poli. Next_page[-1] vyberie posledný prvok v poli.
Blok if skontroluje, či premenná next_page niečo obsahuje, a potom zavolá metódu scrapy.Request(). V našom kóde inštruujeme túto metódu, aby prešla stránku s poskytnutou URL adresou a odovzdala ju späť metóde parse(), aby sme ju mohli analyzovať na extrahovanie údajov a zopakovať proces pre nasledujúcu stránku. Tento proces sa opakuje, kým nenájde odkaz na nasledujúcu stránku, respektíve ak blok zlyhá, tak sa zastaví.
Uložte svoj kód a spustite ho. Všimnete si, že iterácia pokračuje v prechádzaní stránok v cykle, ako nachádza ďalšie stránky na scrapovanie. Takto by ste definovali scraper, ktorý sleduje odkazy na webovej stránke. Náš príklad je pomerne jednoduchý. Prejdeme len na stránku, nájdeme odkaz na nasledujúcu stránku a proces zopakujeme. V iných prípadoch použitia môžete chcieť sledovať značky alebo odkazy, ktoré ukazujú na externé zdroje a podobne. Tu je kompletný zdrojový kód pre základný web scraper v jazyku Python 3:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), 'caption': tutorial.css(CAPTION_SELECTOR).extract_first(), } NEXT_PAGE_SELECTOR = '.x-pagination > ul.center-list > li > a.prev-next::attr("href")' next_page = response.css(NEXT_PAGE_SELECTOR).extract() if next_page: yield scrapy.Request( response.urljoin(next_page[-1]), callback=self.parse ) |
Záver
V tomto návode sme vytvorili jednoduchý web scraper, ktorý dokáže prechádzať blog CloudSigma adresár a zobraziť niektoré informácie o blogových návodoch len v približne 27 riadkoch kódu.
To je samozrejme možné vďaka tomu, že sme ho postavili na pythonovskej knižnici Scrapy. Toto je len základ, ktorý by vám mal pomôcť vytvoriť zložitejšie scrapery, ktoré sledujú viac tagov, výsledky vyhľadávania na webových stránkach a ďalšie. Môžete si pozrieť oficiálnu dokumentáciu Scrapy pre viac informácií o práci so Scrapy.
Príjemnú prácu s počítačom!
Komentáre
Zatiaľ žiadne komentáre. Buďte prvý.