

System i logowanie procesów to tylko dwie z najważniejszych zalet systemd. Gdy logi są rozproszone po całym systemie, obejmują wiele aplikacji i są obsługiwane przez różne procesy i demony, ich interpretacja może być trudna. Systemd zapewnia scentralizowane rozwiązanie do zarządzania wszystkimi logami procesów jądra i przestrzeni użytkownika w nośniku kompilacji znanym jako dziennik (journal). Więcej o systemd dowiesz się w naszym samouczku dotyczącym zarządzania usługami i jednostkami systemd za pomocą systemctl. Wszystkie komunikaty generowane przez usługi, initrd, jądra itp. w dzienniku są obsługiwane przez demona journal. Celem tego przewodnika jest pokazanie, jak uzyskiwać dostęp do danych dziennika i manipulować nimi za pomocą journalctl.
Podstawowe założenie
Niezależnie od tego, skąd pochodzi komunikat, jednym z głównych celów systemd jest umożliwienie scentralizowania ich zarządzania. Ponieważ wiele procesów rozruchowych i duża część zarządzania usługami są obsługiwane przez proces systemd, sposób kompilowania i uzyskiwania dostępu do logów powinien być ustandaryzowany. Zbierając dane ze wszystkich dostępnych źródeł do jednego wszechstronnego narzędzia, journald przechowuje je w formacie binarnym. Pozwala to na łatwy dostęp do danych w celu ich dynamicznej i prostej manipulacji.
To podejście ma kilka kluczowych zalet. Dzięki centralnemu miejscu gromadzenia wszystkich danych, administratorzy mogą filtrować i wyświetlać tylko te dane, których potrzebują. Na przykład można wyświetlić dane rozruchowe sprzed trzech uruchomień systemu. Może to również oznaczać sekwencyjne rejestrowanie wpisów z powiązanych usług i skuteczniejsze śledzenie problemów z komunikacją między nimi.
Dzięki binarnemu przechowywaniu dane mogą być wyświetlane w różnych formatach wyjściowych, w zależności od aktualnych potrzeb użytkownika. Na przykład dzienny log może być przeglądany w standardowym formacie syslog. Jeśli jednak chcesz przedstawić przerwy w świadczeniu usług w formie wykresu, wpis może zostać wyeksportowany jako JSON obiekt, co umożliwia jego współpracę z usługą tworzenia wykresów. Gdy zachodzi potrzeba zmiany formatu w zależności od sytuacji, konwersja nie jest wymagana, ponieważ dane są binarne i nie są zapisywane na dysku w formacie tekstowym.
W zależności od potrzeb, dziennik systemd można wdrożyć wraz z istniejącym syslogiem lub może on zastąpić jego funkcjonalność. Systemd może nawet uzupełniać istniejące mechanizmy logowania. Na przykład wiele usług w jednym systemie może mieć swoje skompilowane dane przeplatane w jednym systemie z dziennikiem systemd.
Ustawianie czasu systemowego
Systemd domyślnie wyświetla wyniki w czasie lokalnym, co jest zaletą binarnego logowania dziennika w kontekście sposobu przeglądania rekordów logów. Alternatywnie można je przeglądać w czasie UTC. Dlatego ważne jest, aby upewnić się, że strefa czasowa jest poprawnie skonfigurowana przed rozpoczęciem korzystania z logowania dziennika. W tym celu systemd jest wyposażony w narzędzie o nazwie timedatectl. Zaczynamy od sprawdzenia, jakie strefy czasowe są dostępne, wyświetlając listę za pomocą opcji list-timezones:
|
1 |
timedatectl list-timezones |
Po znalezieniu strefy czasowej odpowiadającej lokalizacji Twojego serwera, strefę czasową można ustawić za pomocą opcji set-timezone:
|
1 |
sudo timedatectl set-timezone zone |
Aby przetestować i zweryfikować, czy strefa czasowa jest teraz wyświetlana prawidłowo, możesz użyć polecenia timedatectl samodzielnie lub dodając „status”:
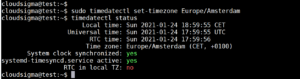
Pierwsza linia przedstawia czas lokalny. Ta linia powinna zawierać prawidłowy czas dla Twojego regionu.
Ogólne przeglądanie logów
Polecenie journalctl umożliwia przeglądanie logów zebranych przez demona journald. Kiedy używasz journalctl, każdy wpis dziennika z systemu zostanie wyświetlony na ekranie, przy czym najstarsze wpisy znajdują się na górze. Pełna lista danych będzie jednak liczyć dziesiątki tysięcy linii.
|
1 |
journalctl |
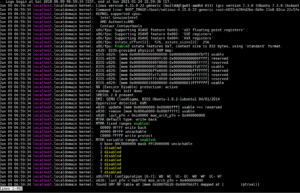
Osoby, które korzystały ze standardowego logowania syslog, uznają ten format za znajomy, ale należy pamiętać, że ta kompilacja danych pochodzi z wielu źródeł, w przeciwieństwie do metody syslog. Logi będą obejmować wczesny proces rozruchu, initrd i jądro, a także standardowe błędy aplikacji.
Teraz, gdy czas lokalny jest ustawiony, wszystkie wpisy będą zaczynać się od znaczników czasu w czasie lokalnym, co jest dostępne dla każdego logu aktualnie przechowywanego w systemie, a cała logika jest wyświetlana przy użyciu tych nowych informacji. Nie jesteś jednak ograniczony do czasu lokalnego. Używając flagi –utc, możesz wyświetlać znaczniki czasu również w formacie UTC:
|
1 |
journalctl --utc |
Filtrowanie dziennika według czasu
Dostępność tak dużej ilości danych jest fantastyczna, ale przeszukiwanie ich i przyswajanie, nie mówiąc już o psychicznym przetworzeniu, może być zniechęcającym zadaniem. Mając to na uwadze, przechodzimy do najważniejszej części funkcji journalctl: filtrowania.
Wyświetlanie logów z bieżącego rozruchu
Jeśli szukasz danych w dzienniku z ostatniego restartu, możesz użyć funkcji journalctl z flagą -b. Spowoduje to wyświetlenie wszystkich istotnych informacji z logów z ostatniego rozruchu systemu. To polecenie pozwoli Ci znaleźć i zarządzać informacjami najbardziej istotnymi dla bieżącego środowiska pracy:
|
1 |
journalctl -b |
Jeśli przeglądający zdecyduje się nie oceniać każdego wpisu z osobna, journalctl pokaże rozruchy z ponad jednego dnia, które zostaną wyświetlone w journalctl z wygodnymi separatorami „Reboot”. Pomaga to logicznie oddzielić informacje z różnych sesji rozruchowych w celu ich przejrzenia:
|
1 2 3 |
. . . -- Reboot -- . . . |
Informacje o poprzednich rozruchach
Choć wyświetlanie informacji o bieżącym rozruchu bywa najbardziej przydatne, istnieją sytuacje, w których pomocne okażą się informacje o poprzednich rozruchach. Journal zapisuje informacje o wielu wcześniejszych rozruchach, dzięki czemu journalctl może łatwo wyświetlić informacje z dowolnego okresu.
Niektóre dystrybucje wyłączają zapisywanie informacji o poprzednich rozruchach, podczas gdy inne mają tę opcję włączoną domyślnie. Włączenie trwałego zapisywania informacji o rozruchu można osiągnąć poprzez utworzenie katalogu do przechowywania dziennika, wpisując następujące polecenie:
|
1 |
sudo mkdir -p /var/log/journal |
Alternatywnie możesz edytować plik konfiguracyjny journal w następujący sposób:
|
1 |
sudo nano /etc/systemd/journald.conf |
Ustawienie opcji Storage= na „persistent” w sekcji [Journal] włączy trwałe logowanie:
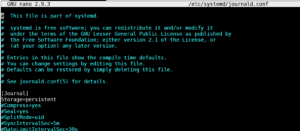
Po włączeniu tej opcji journalctl udostępnia pewne polecenia, które pomagają określić te rozruchy jako jednostki podziału. Aby wyświetlić rozruchy, które zostały zarejestrowane w journald, możesz użyć opcji –list-boots w journalctl:
|
1 |
journalctl --list-boots |
![]()
Jak pokazano, każdy rozruch zostanie wymieniony w osobnym wierszu, przy czym pierwsza kolumna odzwierciedla wcześniejsze rozruchy w kolejności od najstarszego do najnowszego. Jeśli potrzebne jest bardziej bezwzględne odniesienie, druga kolumna zawiera identyfikator rozruchu. Następnie wymienione są dwa określenia czasu. Informacje z pierwszej lub drugiej kolumny mogą być użyte do wyświetlenia informacji z dziennika dla konkretnego rozruchu. Na przykład możesz użyć flagi -b ze względnym wskaźnikiem rozruchu -1, aby wyświetlić informacje o przedostatnim rozruchu:
|
1 |
journalctl -b -1 |
Podobnie, identyfikator rozruchu z drugiej kolumny może być również użyty w ten sposób:
|
1 |
journalctl -b 54342de612174d269b66f1d5eb098abb |
Okna czasowe
Przeglądanie uruchomień (bootów) według identyfikatora to jedna z opcji, ale często bardziej przydatna jest możliwość odwoływania się do wcześniejszych uruchomień za pomocą okna czasowego w przeszłości, które niekoniecznie musi pokrywać się z konkretnymi uruchomieniami. Na przykład ma to znaczenie w sytuacji, gdy pracuje się z długo działającymi serwerami, które nie są często restartowane. Filtrowanie limitów czasowych można przeprowadzić przy użyciu dowolnych limitów czasowych. Spowoduje to wyświetlenie tylko informacji o restartach, które mieszczą się w określonym oknie czasowym. Parametry tego okna są określane za pomocą opcji –since i –until. Dostępnych jest kilka formatów opcji czasowych. Format bezwzględnej wartości czasu jest następujący:
|
1 |
RRRR-MM-DD GG:MM:SS |
Jeśli więc chcesz zobaczyć wszystkie uruchomienia od 10 stycznia 2015 r. o godzinie 17:15, wpisz następujące polecenie:
|
1 |
journalctl --since "2015-01-10 17:15:00" |
Jeśli którykolwiek z komponentów zostanie pominięty, zastosowane zostaną wbudowane wartości domyślne. Ponadto, jeśli data zostanie pominięta, domyślnie przyjmowana jest data bieżąca. Jeśli brakuje komponentu czasu, domyślną wartością jest północ (00:00:00). Jeśli pominiesz sekundy w komponencie czasu, domyślnie przyjmą one początek danej minuty (00):
|
1 |
journalctl --since "2015-01-10" --until "2015-01-11 03:00" |
Journal potrafi zrozumieć skróty związane z czasem, takie jak „today” (dzisiaj), „tomorrow” (jutro), „yesterday” (wczoraj) i „now” (teraz). Słowa takie jak „ago” (temu), w połączeniu z poprzedzającymi kwalifikatorami „-” i „+”, mogą być użyte do skonstruowania polecenia przypominającego zdanie:
|
1 |
journalctl --since yesterday |
Jeśli otrzymasz powiadomienie o przerwie w świadczeniu usługi, która rozpoczęła się o godzinie 9:00, i chcesz sprawdzić logi journala do stanu sprzed godziny, możesz to zrobić w następujący sposób:
|
1 |
journalctl --since 09:00 --until "1 hour ago" |
Jak widać, definiowanie elastycznego okna czasowego do przeglądania żądanych wpisów jest bardzo proste.
Filtrowanie według interesujących komunikatów
Oprócz filtrowania journala według ograniczeń czasowych, dane można również filtrować na podstawie interesującego nas komponentu usługi. Systemd udostępnia kilka metod, aby to zrobić.
Według jednostki (Unit)
Prawdopodobnie najbardziej użytecznym parametrem filtrowania jest interesująca nas jednostka (unit). Aby filtrować według jednostki, można skorzystać z opcji -u. Na przykład, jeśli chcesz zobaczyć wszystkie logi odnoszące się do jednostki Nginx, wpisz następujące polecenie:
|
1 |
journalctl -u nginx.service |
W rzeczywistości warto połączyć to z filtrem czasowym, aby wyświetlić interesujące linie. Jeśli chcesz sprawdzić powyższą usługę i jej dzisiejsze działanie, możesz wykonać następujące czynności:
|
1 |
journalctl -u nginx.service --since today |
Jest to szczególnie przydatne przy korzystaniu z możliwości journala do kompilowania rekordów z wielu jednostek, zwłaszcza tych współpracujących ze sobą. Jeśli proces Nginx jest połączony z jednostką PHP-FPM w celu przetwarzania zawartości dynamicznej, wpisy można scalić w porządku chronologicznym, określając obie jednostki:
|
1 |
journalctl -u nginx.service -u php-fpm.service --since today |
Może to znacznie pomóc w obserwowaniu interakcji między programami i ułatwić debugowanie całych systemów zamiast pojedynczych procesów.
Według identyfikatora grupy, procesu lub użytkownika
Wiele usług uruchamia wiele podprocesów (procesów potomnych) w celu wykonania określonej pracy. Jeśli dostępny jest identyfikator konkretnego procesu, można go również odfiltrować, określając pole _PID. Jeśli interesujący nas PID to 8088, można wykonać następujące czynności:
|
1 |
journalctl _PID=8088 |
Możesz również chcieć zobaczyć wpisy zarejestrowane dla konkretnej grupy lub konkretnego użytkownika. Można to osiągnąć za pomocą filtrów _GID i _UID. Jeśli serwer WWW działa jako użytkownik www-data, poniższe polecenie pozwoli znaleźć wymagany identyfikator:
|
1 |
id -u www-data |
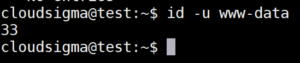
Używając tego identyfikatora, możesz następnie wyświetlić przefiltrowane wyniki journala:
|
1 |
journalctl _UID=33 --since today |
Systemd udostępnia wiele pól do celów filtrowania. Niektóre pola są stosowane przez journald na podstawie informacji zebranych z systemu w momencie rejestrowania, podczas gdy inne są przekazywane z aktualnie rejestrowanego procesu.
Prefiks _PID wskazuje, że informacje zostały zebrane z systemu w momencie rejestrowania. Dziennik automatycznie rejestruje i indeksuje PID podczas procesu logowania, aby umożliwić późniejsze filtrowanie. Aby dowiedzieć się więcej o dostępnych polach dziennika, możesz wpisać:
|
1 |
man systemd.journal-fields |
Omówimy niektóre z nich w dalszej części tego przewodnika, ale na razie wspomnimy o kilku innych przydatnych opcjach związanych z tymi polami. Jeśli chcesz zobaczyć wszystkie dostępne wartości dla konkretnego pola dziennika, możesz użyć opcji -F. Jeśli chcesz sprawdzić, jakie identyfikatory grup (GID) posiada dziennik systemd, możesz wykonać następujące polecenie:
|
1 |
journalctl -F _GID |
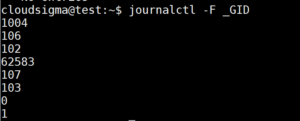
Może to pomóc w tworzeniu filtrów poprzez dostarczenie pełnej listy wartości, które zostały zapisane w polu identyfikatora grupy dziennika.
Według ścieżki komponentu
Filtrowanie można również przeprowadzić, podając ścieżkę. Jeśli ścieżka prowadzi do pliku wykonywalnego, wpisy w journalctl zostaną wyświetlone, jeśli dotyczą tego pliku wykonywalnego. Jeśli interesującym plikiem wykonywalnym jest „bash”, możesz wpisać:
|
1 |
journalctl /bin/bash |
Choć czasami nie jest to możliwe, jeśli jednostka (unit) pliku wykonywalnego jest dostępna, może to wygenerować czytelniejszą i bardziej informacyjną metodę filtrowania.
Wyświetlanie komunikatów jądra
Komunikaty jądra, zwykle znajdujące się w danych wyjściowych dmesg, można również pobrać z dziennika. Aby wyświetlić tylko te komunikaty, używamy flagi -k lub -dmesg jako części naszego polecenia:
|
1 |
journalctl -k |
Domyślnie wyświetlane będą komunikaty z bieżącego rozruchu, ale wcześniejsze rozruchy można określić za pomocą wspomnianej wcześniej flagi wyboru. Jeśli szukasz komunikatów sprzed pięciu rozruchów, wpisanie tego polecenia przyniesie pożądane rezultaty:
|
1 |
journalctl -k -b 5 |
Według priorytetu
Administratorzy systemu często wolą filtrować według priorytetu. Logi o niskim priorytecie, choć często przydatne do wglądu, mogą być mylące i zawierać wiele rozpraszaczy, co czyni je mniej przyswajalnymi podczas analizy. Użycie opcji -p w journalctl spowoduje wyświetlenie tylko komunikatów o określonym priorytecie, odfiltrowując wszystkie inne priorytety. Jeśli chcesz wyświetlić wpisy od poziomu błędu lub wyższego, wpisz następujące polecenie:
|
1 |
journalctl -p err -b |
To polecenie zwróci wszystkie komunikaty oznaczone jako błędy, alarmy, stany awaryjne lub krytyczne, przy czym dziennik korzysta ze standardowych poziomów komunikatów syslog. Poziomy priorytetów są zdefiniowane za pomocą wartości numerycznych, uszeregowanych od najwyższego do najniższego:
- 0: emerg
- 1: alert
- 2: crit
- 3: err
- 4: warning
- 5: notice
- 6: info
- 7: debug
Dowolnego z powyższych można używać zamiennie z opcją -p. Wybranie dowolnego z priorytetów opisanych powyżej spowoduje odfiltrowanie wszystkich priorytetów na tym poziomie i wyższych.
Modyfikowanie sposobu wyświetlania w dzienniku
Oprócz filtrowania w celu wyboru wpisów, mamy inne metody modyfikowania danych wyjściowych, dostosowujące wyświetlanie journalctl do naszych potrzeb.
Skracanie/Rozwijanie danych wyjściowych
Możemy dostosować widok naszych danych wyjściowych, określając, czy journalctl ma skracać czy rozwijać dane. Domyślnym zachowaniem journalctl jest pokazywanie pełnego wpisu, przy czym dłuższe wpisy wykraczają poza prawą krawędź ekranu. Możesz wyświetlić wpisy w całości, przewijając je za pomocą klawisza strzałki w prawo. Użytkownik może zamiast tego chcieć skrócić dane wyjściowe, z wielokropkiem oznaczonym na liniach, które w przeciwnym razie wykraczałyby poza ekran. W tym celu można użyć opcji –no-full:
|
1 |
journalctl --no-full |

Alternatywnie, możesz również zezwolić na wyświetlanie wszystkiego, niezależnie od długości lub obecności niedrukowalnych znaków, używając flagi -a:
|
1 |
journalctl -a |
Wyście do standardowego wyjścia
Domyślnie journalctl wyświetla dane wyjściowe w programie stronicującym (pager), ale jeśli chcesz manipulować danymi za pomocą narzędzi do edycji tekstu, prawdopodobnie potrzebujesz, aby dane wyjściowe były generowane do standardowego wyjścia. Możesz to osiągnąć za pomocą opcji –no-pager:
|
1 |
journalctl --no-pager |
W zależności od potrzeb użytkownika można to przekierować do pliku na dysku lub do narzędzia przetwarzającego.
Formaty wyjściowe
Dane są zawsze łatwiejsze do analizowania, gdy są prezentowane w bardziej przystępnym formacie. Dziennik (journal) oferuje wiele opcji wyświetlania przy użyciu kwalifikatora -o, po którym następuje konkretnie określony format.
Jeśli chcesz wyeksportować wpisy dziennika do formatu JSON, możesz to zrobić w następujący sposób:
|
1 |
journalctl -b -u nginx -o json |
![]()
Ta strategia jest szczególnie przydatna w przypadku narzędzi do analizowania składni (parserów). Format json-pretty może lepiej wyświetlać struktury danych przed przekazaniem ich do odbiorcy JSON:
|
1 |
journalctl -b -u nginx -o json-pretty |
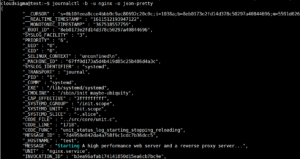
Istnieje kilka formatów, które można wykorzystać do wyświetlania:
- cat: Wyświetla tylko samo pole komunikatu (message).
- export: Format binarny odpowiedni do przesyłania lub tworzenia kopii zapasowych.
- json: Standardowy JSON z jednym wpisem na linię.
- json-pretty: JSON sformatowany pod kątem lepszej czytelności dla człowieka
- json-sse: Dane wyjściowe w formacie JSON opakowane tak, aby były zgodne ze zdarzeniami wysyłanymi przez serwer (server-sent events)
- short: Domyślny format wyjściowy w stylu syslog
- short-iso: Domyślny format rozszerzony o pokazywanie znaczników czasu zegara ściennego ISO 8601.
- short-monotonic: Domyślny format z monotonicznymi znacznikami czasu.
- short-precise: Domyślny format z precyzją mikrosekundową
- verbose: Pokazuje każde pole dziennika dostępne dla wpisu, w tym te zwykle ukryte wewnętrznie.
Powyższe opcje pozwalają na wyświetlanie dziennika w preferowanym formacie.
Aktywne monitorowanie procesów
Dziennik umożliwia dostęp do funkcji monitorowania aktywnej lub niedawnej aktywności bez konieczności angażowania innego narzędzia. Możesz to zrobić za pomocą polecenia journalctl z funkcją „tail”.
-
Wyświetlanie ostatnich logów
Użycie opcji -n (która działa dokładnie tak samo jak polecenie tail -n) pozwoli na wyświetlenie określonej liczby rekordów:
|
1 |
journalctl -n |
Liczbę wpisów, które mają zostać wyświetlone, można określić, podając konkretną liczbę po kwalifikatorze -n:
|
1 |
journalctl -n 20 |
-
Śledzenie logów na bieżąco
Możesz również aktywnie śledzić logi w miarę ich zapisywania w systemie za pomocą flagi -f. Działa to w taki sam sposób jak polecenie tail -f:
|
1 |
journalctl -f |
Konserwacja dziennika
Logi zajmują miejsce. Warto to zbadać, potencjalnie w celu usunięcia niektórych starszych logów, aby zwolnić miejsce.
Sprawdzanie bieżącego użycia dysku
Flaga –disk-usage może pomóc określić, ile miejsca na dysku zajmują obecnie logi:
|
1 |
journalctl --disk-usage |

Usuwanie starych logów
W systemd od wersji 218 (i kolejnych) można zmniejszyć dziennik na dwa różne sposoby. Jednym z nich jest opcja –vacuum-size. Pozwala ona zmniejszyć dziennik poprzez wskazanie jego rozmiaru. Innymi słowy, starsze wpisy będą usuwane z dziennika, dopóki zajmowane miejsce nie osiągnie żądanego parametru:
|
1 |
sudo journalctl --vacuum-size=1G |
Opcja –vacuum-time pozwala zmniejszyć ilość miejsca zajmowanego przez dziennik poprzez wskazanie czasu granicznego – wszelkie wpisy starsze niż ten czas zostaną usunięte, natomiast te utworzone po określonym czasie zostaną zachowane. Jeśli chcesz zachować wpisy tylko z ostatniego roku kalendarzowego, możesz użyć:
|
1 |
sudo journalctl --vacuum-time=1years |
Ograniczenie rozrastania się dziennika
Możesz również ograniczyć ilość miejsca, jaką zajmie dziennik. Osiąga się to poprzez edycję pliku /etc/systemd.journald.conf. Wzrost dziennika można ograniczyć za pomocą dowolnej z następujących metod:
- SystemMaxUse=: Określa maksymalną przestrzeń dyskową, jaką dziennik może zająć w pamięci trwałej.
- SystemKeepFree=: Określa, ile wolnego miejsca należy pozostawić podczas dodawania wpisów dziennika do pamięci trwałej.
- SystemMaxFileSize=: Określa, jak duże mogą stać się pliki dziennika przed rotacją w pamięci trwałej.
- RuntimeMaxUse=: Określa, ile miejsca na dysku może być użyte w pamięci ulotnej (w obrębie systemu plików /run).
- RuntimeKeepFree=: Podczas zapisywania danych w pamięci ulotnej ta funkcja określa ilość miejsca, która musi być przeznaczona na inne cele (w obrębie systemu plików /run).
- RuntimeMaxFileSize=: Określa, ile miejsca może zająć pojedynczy plik dziennika w pamięci ulotnej (w obrębie systemu plików /run), zanim będzie musiał zostać zrotowany.
Wszystkie te opcje mogą pomóc kontrolować zużycie pamięci przez dziennik. Ważnym faktem, na który należy zwrócić uwagę, jest to, że opcje SystemMaxFileSize i RuntimeMaxFileSize będą dotyczyć zarchiwizowanych plików w celu osiągnięcia określonych limitów. Należy o tym pamiętać podczas interpretacji liczby plików po operacjach czyszczenia (vacuuming).
Podsumowanie
Ewidentnie widać, że dziennik systemd jest niezwykle użytecznym narzędziem, a większość jego zalet wynika ze scentralizowanej natury logów’ oraz ogromnej ilości rejestrowanych metadanych. Bogate funkcje dziennika można wykorzystać za pomocą polecenia journalctl, co ułatwia przeprowadzanie relacyjnego debugowania komponentów aplikacji, a także szczegółowej analizy systemu.
Udanego korzystania z komputera!
Komentarze
Brak komentarzy. Bądź pierwszy.