

Polecenie grep jest potężnym narzędziem do wyszukiwania wzorców w tekście. Jest ono fabrycznie zainstalowane w każdej dystrybucji Linux. Oto nasz poradnik, który omawia konfigurację stosu LAMP - Linux, Apache, MySQL i PHP.
Nazwa grep oznacza „global regular expression print” (globalne drukowanie wyrażeń regularnych). Narzędzie to wyszukuje określony wzorzec w danych wejściowych. W teorii brzmi to trywialnie. Jednak jego prawdziwa siła tkwi w sposobie definiowania wzorca. Ten przewodnik szczegółowo wyjaśnia, jak używać grep z wyrażeniami regularnymi do wykonywania złożonych wyszukiwań. Zaczynajmy!
Jak używać Grep
Samo polecenie grep nie jest skomplikowane. Wszystko, czego wymaga, to wzorzec i zawartość, w której ma zostać przeprowadzone wyszukiwanie. Oto jak wygląda podstawowa struktura polecenia grep:
|
1 |
grep <regex> <file> |
Wyszukiwanie tekstu
Najpierw pobierz przykładowy plik, na którym wykonasz operację. Pobierz GNU General Public License v3.0 (w formacie tekstowym). To całkiem spory plik tekstowy z dużą ilością słów i fraz. Jeśli używasz Ubuntu, możesz go znaleźć w poniższym pliku. Postępuj zgodnie z naszym poradnikiem dotyczącym szybkiej i łatwej instalacji Ubuntu.
|
1 |
curl -o gpl.txt https://www.gnu.org/licenses/gpl-3.0.txt |

Następnie możesz wykonać podstawowe wyszukiwanie tekstu za pomocą grep:
|
1 |
grep <pattern> <text_file> |
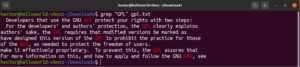
Możliwe jest przekierowanie wyjścia polecenia do grep:
|
1 |
cat gpl.txt | grep <pattern> |
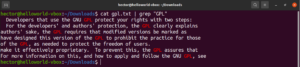
Wielkość liter
Domyślnie grep rozróżnia wielkość liter. W wielu sytuacjach optymalne może być ignorowanie wielkości liter. Aby wyłączyć rozróżnianie wielkości liter, użyj flagi „-i” lub „–ignore-case”:
|
1 2 3 |
$ grep -i <pattern> <file> $ grep --ignore-case <pattern> <flag> |
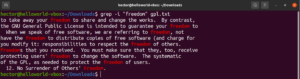
Odwrócenie dopasowania
Domyślnie grep wypisuje linie, w których znaleziono wzorzec. Odwrócenie dopasowania odnosi się do sytuacji, gdy nie chcesz widzieć linii pasujących do wzorca. Aby odwrócić dopasowanie, musisz użyć flagi „-v” lub „–invert-match”:
|
1 2 3 |
$ grep -v <pattern> <file> $ grep --invert-match <pattern> <file> |
Numer linii
Podczas uruchamiania grep na bardzo dużym pliku trudno jest śledzić lokalizację wyniku wyszukiwania. Aby ułatwić sprawę, grep posiada funkcję wyświetlania numeru linii. Aby włączyć numerowanie linii, użyj flagi „-n” lub „–line-number”:
|
1 2 3 |
grep -n <pattern> <file> grep --line-number <pattern> <file> |
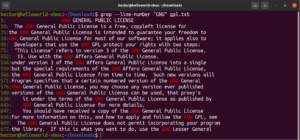
Możliwe jest łączenie wielu argumentów grep. Poniższe polecenie grep wykona odwrócone dopasowanie, jednocześnie drukując numery linii:
|
1 |
grep -nv <pattern> <file> |
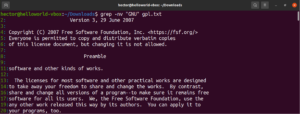
Wyrażenie regularne
Na początku tego przewodnika wspomnieliśmy, że grep oznacza „global regular expression print”. Termin „wyrażenie regularne” jest definiowany jako specjalny ciąg znaków opisujący wzorzec wyszukiwania. Wyrażenia regularne mają własną strukturę i reguły.
Istnieje wiele algorytmów i narzędzi do wyszukiwania ciągów znaków, które używają wyrażeń regularnych (w skrócie regex) do wyszukiwania i zamiany. Choć są one popularne, różne aplikacje i języki programowania implementują regex nieco inaczej. W tej sekcji przedstawimy kilka metod regex przy użyciu grep.
Dopasowanie dosłowne
W poprzednich przykładach grep wyszukiwał określony ciąg znaków w danym pliku tekstowym. W rzeczywistości grep wyszukiwał przy użyciu bardzo podstawowego wyrażenia regularnego. Wzorce regex, które definiują wyszukiwanie dokładnego dopasowania danego ciągu znaków, nazywane są „dosłownymi”. Nazwa ta wynika z faktu, że dopasowują one wzorzec dosłownie, znak po znaku.
Dopasowanie dosłowne działa ze znakami alfabetycznymi i numerycznymi (a także niektórymi znakami specjalnymi). Jednak w zależności od innych mechanizmów wyrażeń, zachowanie to może ulec zmianie:
|
1 |
grep "<string>" <file> |
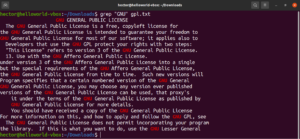
Dopasowanie kotwic
Kotwice to znaki specjalne, które określają, w którym miejscu linii musi znajdować się dopasowanie, aby było ono prawidłowe. Oto prosty przykład wyjaśniający to zagadnienie. Jeśli chcemy znaleźć tylko te linie, które zaczynają się od ciągu „GNU”, polecenie grep z wyrażeniem regularnym będzie wyglądać następująco. W tym przypadku znak „^” jest kotwicą określającą, że jedynymi prawidłowymi dopasowaniami są te na początku linii:
|
1 |
grep -n "^GNU" <file> |

Podobnie, jeśli chcemy znaleźć tylko te linie, które kończą się ciągiem „works”, polecenie grep z wyrażeniem regularnym będzie wyglądać następująco. W tym przypadku znak „$” jest kotwicą określającą, że prawidłowe są tylko dopasowania na końcu linii:
|
1 |
grep -n "and$" <file> |
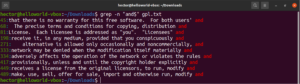
Dopasowanie dowolnego znaku
Podczas wyszukiwania tekstu może zajść potrzeba określenia, że w konkretnym miejscu może znajdować się dowolny znak. W wyrażeniach regularnych jest to wyrażane za pomocą kropki (.).
Spójrz na ten przykład. W pliku tekstowym licencji GNU GPL 3 słowa „accept” i „except” mają wspólną część „cept”. Ponadto oba słowa mają dwa znaki przed częścią „cept”. Poniższe polecenie grep dopasuje dowolne słowo, które ma dwa znaki przed częścią „cept”:
|
1 |
grep -n "..cept" <file> |
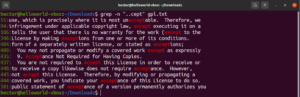
Zgodnie z tym wyrażeniem regularnym, inne słowa, takie jak suscept, unaccept, unexpected itp., również będą pasować.
Nawiasy kwadratowe
W wyrażeniach regularnych wyrażenia nawiasowe określają, że w danym miejscu może znajdować się dowolny znak zadeklarowany wewnątrz nawiasu. Spójrz na poniższy ciąg wyrażenia regularnego:
|
1 |
t[wo]o |
W praktyce prawidłowymi dopasowaniami będą słowa too oraz two:
|
1 |
grep -n "t[wo]o" <file> |
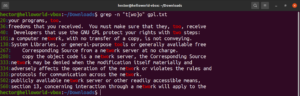
Wyrażenia nawiasowe dają wiele ciekawych możliwości. Można ich użyć, aby wskazać, że w określonym miejscu może znajdować się dowolny znak inny niż te zadeklarowane w nawiasie. Spójrz na poniższy ciąg wyrażenia regularnego. Dopasowanie będzie prawidłowe tylko wtedy, gdy przed „ode” znajdzie się dowolny znak inny niż „c”:
|
1 |
"[^c]ode" |
Uruchom je na pliku tekstowym licencji GPL-3:
|
1 |
grep -n "[^c]ode" <file> |

Oprócz wyników z pliku, innymi prawidłowymi dopasowaniami byłyby node, abode, anode itp. Wyrażenia nawiasowe mogą również opisywać zakres znaków. Poniższe wyrażenie regularne wskazuje, że dopasowanie jest prawidłowe, jeśli linia zaczyna się od wielkiej litery:
|
1 |
"^[A-Z]" |
Uruchom je na pliku tekstowym licencji GPL-3. Dopasowane zostaną wszystkie linie w pliku tekstowym:
|
1 |
grep -n "^[A-Z]" <file> |
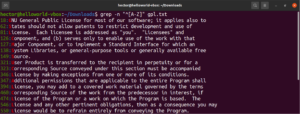
Dla ułatwienia istnieją pewne klasy znaków, które mają określone etykiety. W poprzednim przykładzie użyliśmy zakresu „A-Z” do zdefiniowania wielkich liter. Zamiast tego możemy również użyć „[:upper:]”. Wynik będzie taki sam:
|
1 |
grep -n "^[[:upper:]]" <file> |
Powtarzanie wzorca
W pewnych sytuacjach możesz chcieć dopasować określony wzorzec lub wyrażenie regularne zero lub więcej razy. Służy do tego metaznak gwiazdki (*). Poniższe wyrażenie regularne dopasuje wszystkie nawiasy zawierające wyłącznie litery i pojedyncze spacje między nimi. Zauważ, że deklaracje zestawów małych i wielkich liter oraz spacji są połączone bez żadnych znaków interpunkcyjnych:
|
1 |
"([a-zA-Z ]*)" |
Użyj tego wyrażenia regularnego w poleceniu grep:
|
1 |
grep -n "([A-Za-z ]*)" <file> |

Używanie metaznaków jako znaków dosłownych
Do tej pory poznaliśmy różne metaznaki, takie jak gwiazdka (*), kropka (.), kotwice (^ i $), itp. Każdy z nich pełni unikalną funkcję w kontekście wyrażeń regularnych. Problem pojawia się, gdy muszą one zostać użyte jako znaki dosłowne, a nie metaznaki. W takich sytuacjach ukośnik wsteczny (\) przed metaznakiem oznacza, że ma on zostać użyty w sensie dosłownym, a nie jako metaznak. Spójrz na ten przykład wyrażenia regularnego. Dopasuje ono wszystkie linie, które zaczynają się od wielkiej litery i kończą kropką:
|
1 |
grep -n "^[A-Z].*\.$" <file> |
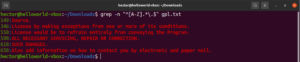
Alternacja
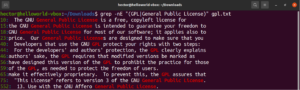
Używając wyrażeń nawiasowych, możemy określić różne możliwe opcje dopasowania pojedynczego znaku. Wyrażenia regularne oferują funkcję pozwalającą zrobić to samo ze słowami i frazami. Aby wskazać alternację, używa się znaku pionowej kreski (|). Opcje znajdują się wewnątrz nawiasów, a pionowa kreska oddziela je od siebie. Aby dopasowanie było prawidłowe, mogą istnieć dwie lub więcej możliwych opcji. Spójrz na poniższy przykład wyrażenia regularnego. Dopasuje ono zarówno „GPL”, jak i „General Public License”:
|
1 |
grep -nE "(GPL|General Public License)" <file> |
Kwantyfikatory
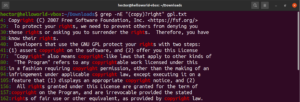
Używając metaznaku gwiazdki (*), byliśmy w stanie zdefiniować wzorzec powtarzający się zero lub więcej razy. Istnieje jednak więcej możliwości. Kwantyfikatory łatwiej wyjaśnić na przykładzie. Poniższe wyrażenie regularne określa, że zarówno „copyright”, jak i „right” są prawidłowymi dopasowaniami. Znak zapytania (?) oznacza, że część „copy” jest opcjonalna do dopasowania:
|
1 |
grep -nE "(copy)?right" <file> |
Kolejnym kwantyfikatorem jest symbol plusa (+). Zachowuje się on podobnie do gwiazdki. Jednak zdefiniowany wzorzec musi zostać dopasowany co najmniej raz. W poniższym przykładzie wyrażenie regularne dopasuje słowo „soft” z jednym lub kilkoma znakami niebędącymi białymi znakami:
|
1 |
grep -nE "soft[^[:space:]]+" <file> |
Określanie powtórzeń dopasowania
Możliwe jest określenie liczby powtórzeń dopasowania. Aby to zrobić, użyj nawiasów klamrowych ({}). Poniższe wyrażenie regularne dopasuje każde słowo, które zawiera minimum trzy samogłoski:
|
1 |
grep -nE "[aeiouAEIOU]{3}" <file> |

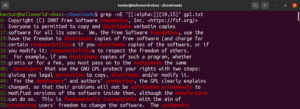
Ta funkcja pozwala również zdefiniować dolną i górną granicę długości dopasowania. W poniższym przykładzie wyrażenie regularne dopasuje dowolne słowo o długości od 10 do 15 znaków:
|
1 |
grep -nE "[[:alpha:]]{10,15}" <file> |
Podsumowanie
Przeszukiwanie plików tekstowych za pomocą grep jest bardzo wygodne. Wyrażenia regularne sprawiają, że wyszukiwanie za pomocą grep staje się ciekawsze i bardziej użyteczne. Pozwalają one również precyzyjnie dostosować wzorzec wyszukiwania do własnych potrzeb.
Choć przedstawiliśmy niektóre z powszechnych wyrażeń regularnych, to dopiero początek. Istnieją bardziej zaawansowane wyrażenia regularne, które oferują najwyższą kontrolę nad zachowaniem wyszukiwania. Oprócz grep, wyrażenia regularne są również szeroko stosowane przez inne narzędzia i języki programowania.
Miłej pracy z komputerem!
Komentarze
Brak komentarzy. Bądź pierwszy.