
Plik CSV to plik tekstowy, który przechowuje dane w formacie tabelarycznym. W większości przypadków pliki CSV używają przecinków (,) jako separatora, stąd nazwa CSV (Comma Separated Values). Jest on używany w sytuacjach, gdy kompatybilność danych ma znaczenie, ponieważ pliki CSV można otworzyć za pomocą dowolnego edytora tekstu, arkusza kalkulacyjnego i innych specjalistycznych narzędzi. W rzeczywistości wiele języków programowania oferuje wbudowane wsparcie dla CSV.
W tym poradniku dowiemy się, jak używać CSV w przykładowej aplikacji Node.js.
CSV w Node.js
Node.js to otwartoźródłowe i wieloplatformowe środowisko uruchomieniowe JavaScript. Stało się jednym z najpopularniejszych backendów zasilających liczne usługi internetowe w całym Internecie. Nawet duże firmy, takie jak Netflix i Uber, używają Node.js do zasilania swoich usług.
Node.js posiada również liczne moduły, które można wdrożyć w celu dodania dodatkowych funkcjonalności do projektu. Jeśli chodzi o CSV, dostępnych jest wiele modułów, na przykład node-csv, fast-csv, oraz papaparse itp.
Jak sugeruje tytuł poradnika, użyjemy node-csv do odczytu plików CSV przy użyciu strumieni Node.js. Zademonstrujemy również pracę ze sparsowanymi danymi, na przykład przenoszenie danych do bazy danych SQLite.
Wymagania wstępne
-
Aby wykonać kroki przedstawione w tym poradniku, będziesz potrzebować następujących komponentów:
-
Odpowiednio skonfigurowany system Linux. Dowiedz się więcej o instalacji i konfiguracji serwera chmurowego Ubuntu na CloudSigma.
-
Dostęp do użytkownika niebędącego rootem z uprawnieniami sudo. Sprawdź zarządzanie uprawnieniami sudo za pomocą sudoers.
-
Odpowiedni edytor tekstu, na przykład Brackets, VS Code, Sublime Text, Vim/NeoVim, itp.
-
Inne oprogramowanie:
-
Node.js LTS
-
SQLite
-
Krok 1 – Instalacja wymaganego oprogramowania
Na potrzeby tego poradnika utworzyłem lekki serwer z systemem Ubuntu 22.04 LTS (połączony przez SSH):
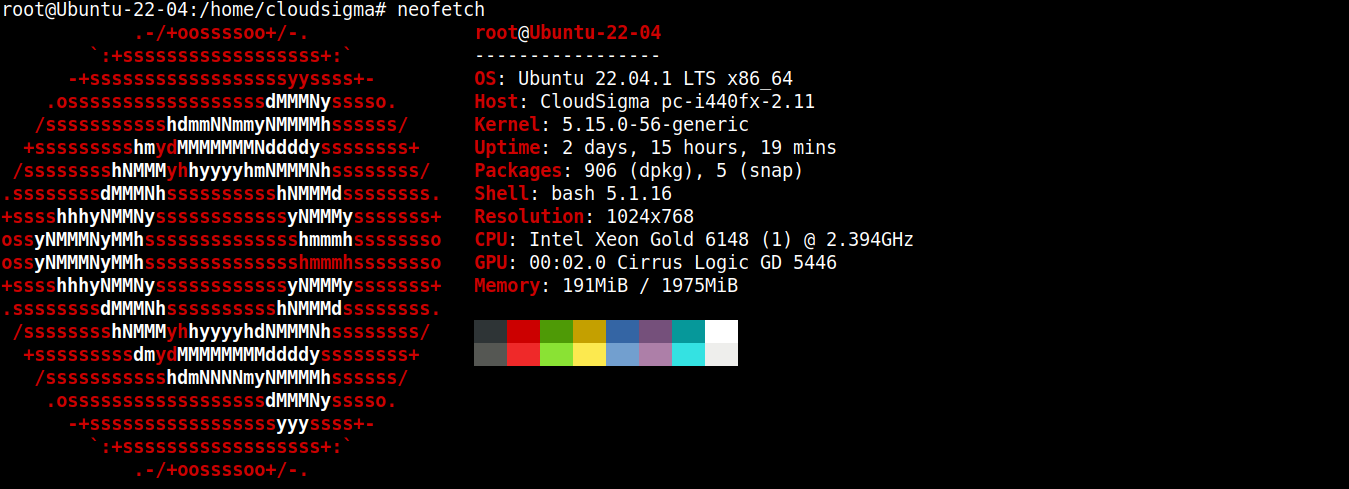
Teraz zainstalujemy na nim Node.js oraz SQLite.
-
Instalacja Node.js LTS
Node.js jest bezpośrednio dostępny w oficjalnych repozytoriach pakietów Ubuntu. Nie jest to jednak najnowsza wersja. Dlatego skorzystamy z zewnętrznego repozytorium (Nodesource) w celu pobrania najnowszych pakietów Node.js.
Dodaj repozytorium dla Node.js LTS:
|
1 |
curl -fsSL https://deb.nodesource.com/setup_lts.x | sudo -E bash - |
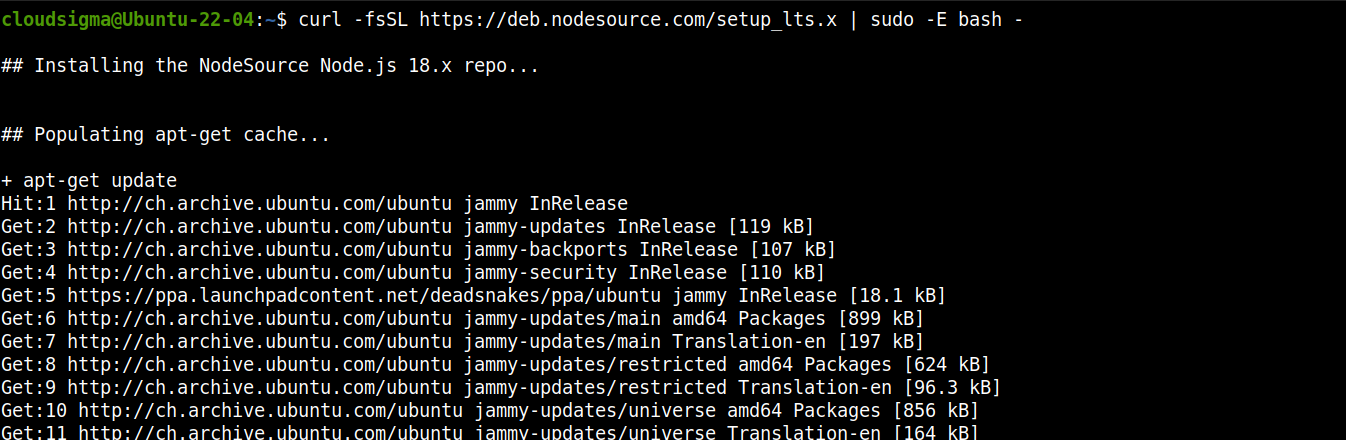
Teraz zainstaluj Node.js LTS:
|
1 |
sudo apt install nodejs -y |

-
Instalacja SQLite
Zainstalujemy SQLite bezpośrednio z repozytoriów pakietów Ubuntu. Uruchom następujące polecenia:
|
1 |
sudo apt install sqlite3 -y |

Krok 2 – Konfiguracja katalogu projektu
W tej sekcji przygotujemy dedykowany katalog dla naszego projektu. Będzie on zawierał wszystkie pliki projektu wraz z dodatkowymi modułami.
Utwórz nowy katalog:
|
1 |
mkdir -pv csv_practice |
Przejdź do katalogu:
|
1 |
cd csv_practice/ |
Następnie uruchom poniższe polecenie, aby zadeklarować katalog jako projekt npm :
|
1 |
npm init -y |
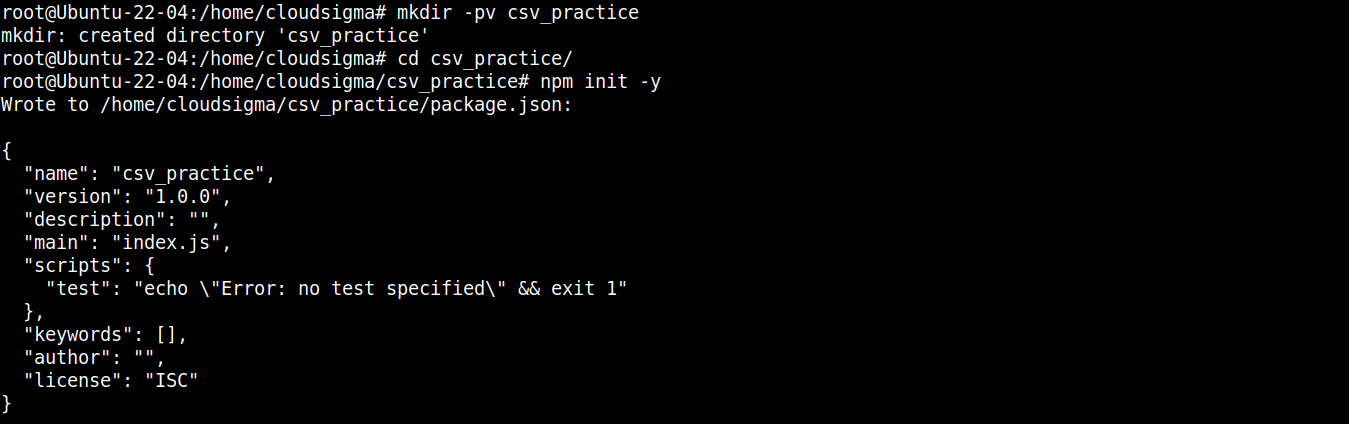
Po zainicjowaniu folderu projektu możemy rozpocząć instalację niezbędnych pakietów i modułów. Najpierw zainstalujemy node-csv:
|
1 |
npm install csv |

Moduł node-csv jest w rzeczywistości zbiorem kilku innych modułów: csv-generate, csv-parse (parsowanie plików CSV), csv-stringify (zapisywanie danych do CSV) oraz stream-transform.
Następnie potrzebujemy modułu do komunikacji z SQLite. Poniższe polecenie zainstaluje moduł node-sqlite3:
|
1 |
npm install sqlite3 |

Komponentem, którego potrzebujemy do naszego projektu, jest plik CSV. Do celów demonstracyjnych użyjemy pliku CSV dotyczącego migracji w Nowej Zelandii:
|
1 |
wget https://www.stats.govt.nz/assets/Uploads/International-migration/International-migration-September-2021-Infoshare-tables/Download-data/international-migration-September-2021-estimated-migration-by-age-and-sex-csv.csv -O migration_data.csv |
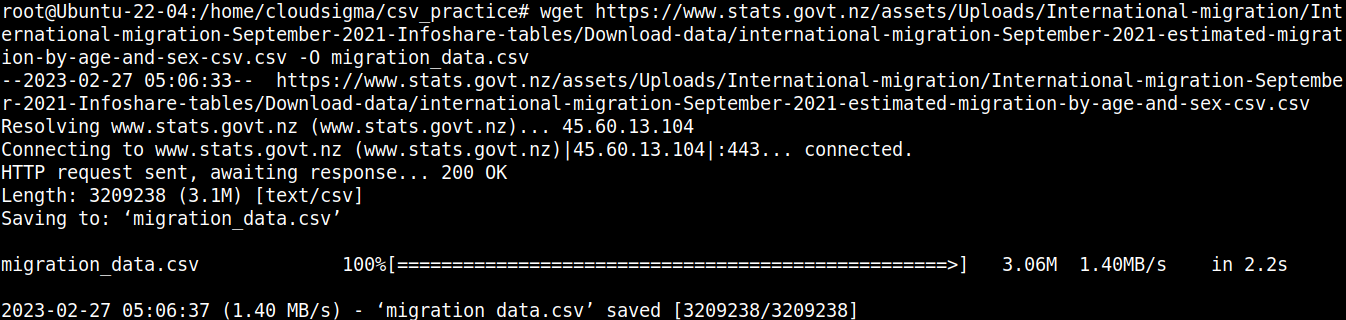
Rzućmy szybko okiem na zawartość pliku:
|
1 |
cat migration_data.csv | less |
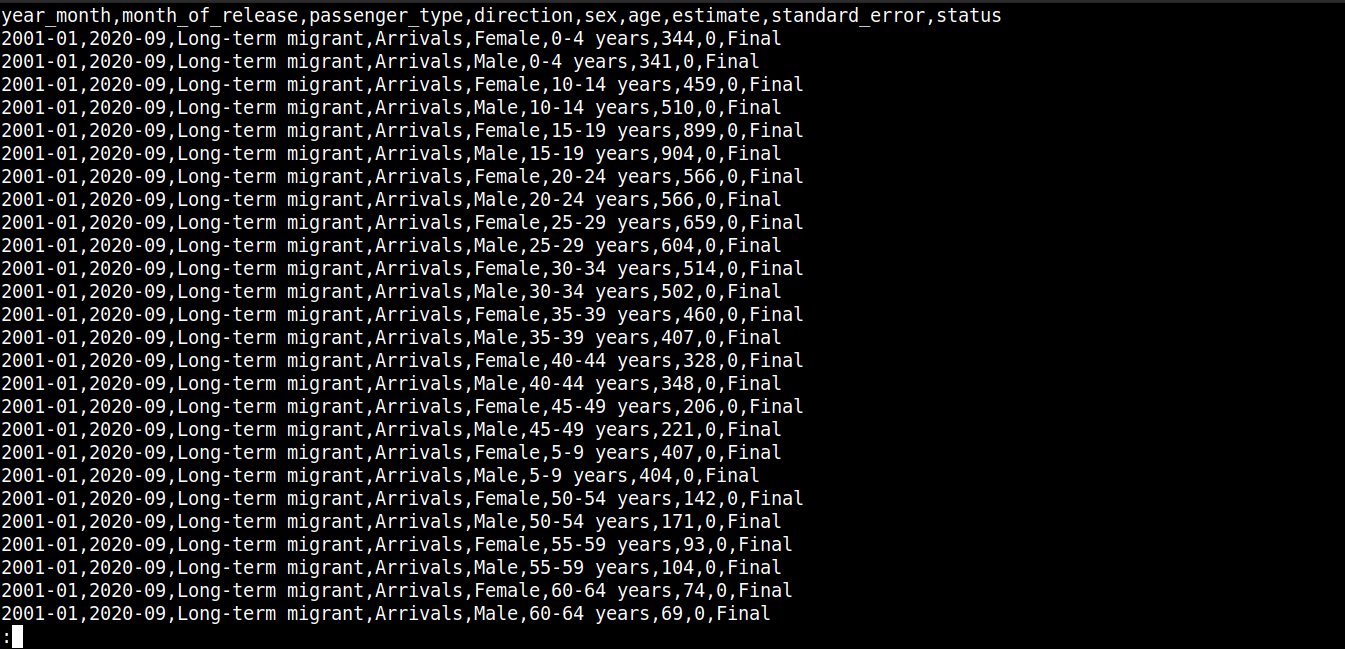
Tutaj,
-
Pierwsza linia opisuje nazwy kolumn.
-
Kolejne linie zawierają wartości dla tych pól.
-
Każdy wiersz jest oddzielony nową linią (\n).
-
Każdy punkt danych jest oddzielony przecinkiem (,).
Jednak format CSV nie ogranicza się do używania przecinków jako separatora. Inne popularne separatory to dwukropki (:), średniki (;) i tabulatory (\td).
Krok 3 – Odczytywanie CSV
W tej sekcji zademonstrujemy implementację przykładowego programu, który odczytuje i analizuje dane z pliku CSV.
Utwórz nowy plik JavaScript:
|
1 |
touch read_csv.js |
Otwórz plik w swoim ulubionym edytorze tekstu:
|
1 |
nano read_csv.js |
Najpierw zaimportujemy moduły fs oraz csv-parse:
|
1 2 |
const fs = require("fs"); const { parse } = require("csv-parse"); |
Tutaj,
-
Najpierw do zmiennej fs przypisywany jest obiekt fs, który zwraca metodę Node.js require() po zaimportowaniu modułu.
-
Następnie metoda parse jest wyodrębniana z obiektu zwróconego przez metodę require() do zmiennej parse przy użyciu składni destrukturyzacji.
Następnie dodamy kod do odczytu pliku CSV:
|
1 2 3 4 5 |
fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) |
Tutaj,
-
Wywołujemy createReadStream() z modułu fs i przekazujemy jako argument plik CSV, który chcemy odczytać. Następnie tworzy on strumień do odczytu, dzieląc większy plik na mniejsze części.
-
Po utworzeniu strumienia metoda pipe() przekazuje części danych strumienia do innego strumienia. Ten nowy strumień jest tworzony po wywołaniu metody parse() z modułu csv-module.
-
Moduł csv-module wdraża strumień transformujący do odczytu/zapisu, który pobiera porcję danych i przekształca ją w inną formę.
-
Metoda parse() przyjmuje obiekty z właściwościami. Obiekt ten dalej przetwarza przeanalizowane dane. W tym przypadku obiekt przyjmuje następujące właściwości:
-
delimiter: Znak separatora służący do rozdzielania wartości. W przypadku naszego docelowego pliku CSV jest to przecinek (,).
-
from_line: Numer linii, od której parser rozpocznie analizę. Przy podanej wartości 2 parser pominie linię 1 i rozpocznie od linii 2. Dzięki temu unikamy włączenia nazw kolumn do przeanalizowanych danych.
-
Następnie dołączymy zdarzenie strumieniowe za pomocą metody on() z Node.js:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) .on("end", function () { console.log("finished"); }) .on("error", function (error) { console.log(error.message); }); |
Tutaj,
-
Po wyemitowaniu określonego zdarzenia, zdarzenie strumieniowe pozwala metodzie na skonsumowanie porcji danych.
-
Gdy dane przeanalizowane przez metodę parse() są gotowe do skonsumowania, wyzwalane jest zdarzenie data.
-
Aby uzyskać dostęp do danych, przekazujemy funkcję wywołania zwrotnego do metody on(), która przyjmuje parametr row.
-
Parametr row to porcja danych w postaci tablicy (wynik analizy).
-
Na koniec dane są zapisywane w konsoli za pomocą console.log().
Aby zakończyć program, dodamy dodatkowe zdarzenia strumieniowe do obsługi błędów i wyświetlenia komunikatu o powodzeniu, gdy wszystkie dane z pliku CSV zostaną skonsumowane. Zaktualizuj kod w następujący sposób:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) .on("end", function () { console.log("finished"); }) .on("error", function (error) { console.log(error.message); }); |
Tutaj,
-
Zdarzenie end jest emitowane, gdy wszystkie dane w pliku CSV zostaną skonsumowane. Powoduje to wywołanie metody console.log(), która wypisuje komunikat o sukcesie.
-
Zdarzenie error jest emitowane w przypadku napotkania błędu podczas parsowania danych CSV. Powoduje to wywołanie metody console.log() metody, która wypisuje komunikat o błędzie.
Ostateczny kod powinien wyglądać następująco:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
const fs = require("fs"); const { parse } = require("csv-parse"); fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) .on("end", function () { console.log("finished"); }) .on("error", function (error) { console.log(error.message); }); |
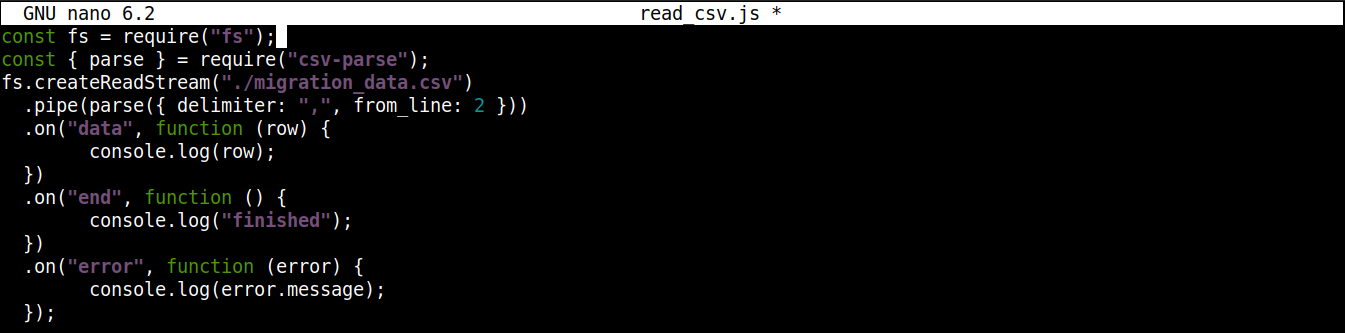
Zapisz plik i zamknij edytor. Jesteśmy teraz gotowi do uruchomienia programu. Uruchom go za pomocą Node.js:
|
1 |
node read_csv.js |
Dane wyjściowe powinny wyglądać mniej więcej tak:

Zauważ, że dane są konsumowane, transformowane i wypisywane w konsoli. Ponieważ jest to proces ciągły, będzie to wyglądać tak, jakby dane były pobierane, a nie wypisywane wszystkie naraz.
Krok 4 – Przenoszenie danych CSV do bazy danych
Do tej pory nauczyliśmy się, jak parsować plik CSV za pomocą node-csv. Ta sekcja zademonstruje przenoszenie sparsowanych danych do bazy danych (SQLite).
Utwórz nowy plik JavaScript do interakcji z bazą danych:
|
1 |
touch csv-to-sqlite3.js |
Teraz otwórz plik w edytorze tekstu:
|
1 |
nano csv-to-sqlite3.js |
![]()
Nasz program rozpoczniemy od następującego kodu:
|
1 2 3 |
const fs = require("fs"); const sqlite3 = require("sqlite3").verbose(); const filepath = "./population.db"; |

Tutaj,
-
W pierwszej linii importujemy fs moduł.
-
W trzeciej linii zmienna filepath zawiera ścieżkę do bazy danych SQLite.
-
W tym momencie baza danych jeszcze nie istnieje. Będzie ona jednak niezbędna podczas pracy z node-sqlite3.
Następnie dodaj poniższe linie, aby nawiązać połączenie z bazą danych SQLite:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
function connectToDatabase() { if (fs.existsSync(filepath)) { return new sqlite3.Database(filepath); } else { const db = new sqlite3.Database(filepath, (error) => { if (error) { return console.error(error.message); } console.log("Connected to the database successfully"); }); return db; } } |
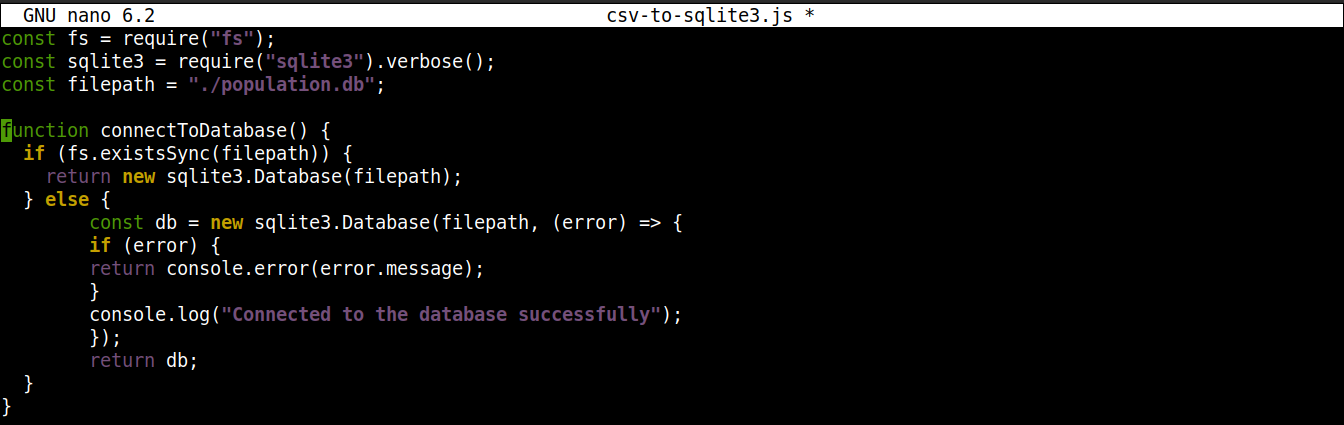
Tutaj,
-
Metoda connectoToDatabase() nawiązuje połączenie z bazą danych.
-
Wewnątrz connectToDatabase(), wywołujemy metodę existsSync() z modułu fs wewnątrz instrukcji warunkowej if. Instrukcja if sprawdza istnienie bazy danych w określonej lokalizacji.
-
Jeśli wynik warunku to true, wtedy klasa Database() modułu node-sqlite3 jest inicjowana. Po nawiązaniu połączenia funkcja zwraca obiekt i kończy działanie.
-
Jeśli wynik warunku to false (baza danych nie istnieje), wówczas wykonanie kodu przejdzie do bloku else. Tam klasa Database() zostanie zainicjowana z dwoma argumentami: ścieżką do pliku bazy danych oraz funkcją zwrotną (callback).
-
Zasadniczo baza danych zostanie utworzona, jeśli nie istnieje. Jeśli jednak podczas procesu tworzenia wystąpi jakikolwiek błąd, ustawi on obiekt error i wyświetli komunikat o błędzie.
Następnie wprowadzimy kod do utworzenia tabeli, jeśli baza danych nie istnieje:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
const fs = require("fs"); const sqlite3 = require("sqlite3").verbose(); const filepath = "./population.db"; function connectToDatabase() { if (fs.existsSync(filepath)) { return new sqlite3.Database(filepath); } else { const db = new sqlite3.Database(filepath, (error) => { if (error) { return console.error(error.message); } createTable(db); console.log("Connected to the database successfully"); }); return db; } } function createTable(db) { db.exec(` CREATE TABLE migration ( year_month VARCHAR(10), month_of_release VARCHAR(10), passenger_type VARCHAR(50), direction VARCHAR(20), sex VARCHAR(10), age VARCHAR(50), estimate INT ) `); } module.exports = connectToDatabase(); |
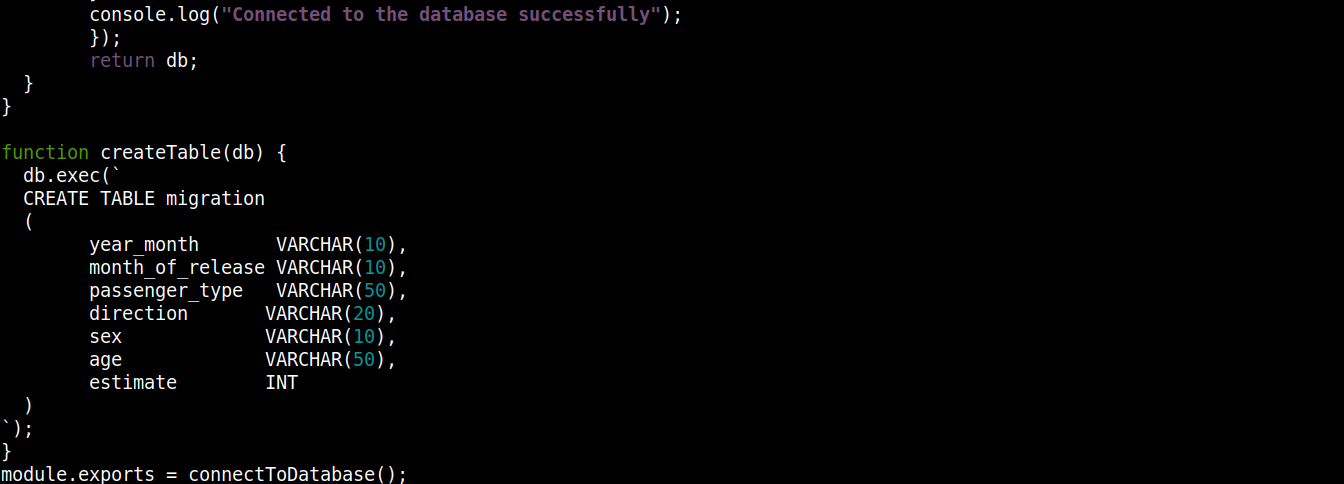
Tutaj,
-
Funkcja connectToDatabase() wywołuje funkcję createTable() , która przyjmuje obiekt przechowywany w db jako argument.
-
Na zewnątrz connectToDatabase(), zdefiniowaliśmy funkcję createTable() , która przyjmuje obiekt połączenia db jako parametr.
-
Metoda exec() na obiekcie db przyjmuje instrukcję SQL jako argument. W ramach tej instrukcji SQL zdefiniowaliśmy utworzenie tabeli migration z 7 kolumnami, z których każda odpowiada nagłówkom kolumn w pliku migration_data.csv .
-
Na koniec wywołujemy connectToDatabase() metodę i eksportując zwracany przez nią obiekt połączenia, abyśmy mogli go użyć w innych plikach.
Zapisz plik i zamknij edytor.
Następnie utworzymy kolejny program, aby wstawić sparsowane dane do bazy danych:
|
1 |
nano insert_data.js |
Wprowadź następujący kod w insert_data.js:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
const fs = require("fs"); const { parse } = require("csv-parse"); const db = require("./csv-to-sqlite3"); fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { db.serialize(function () { db.run( `INSERT INTO migration VALUES (?, ?, ? , ?, ?, ?, ?)`, [row[0], row[1], row[2], row[3], row[4], row[5], row[6]], function (error) { if (error) { return console.log(error.message); } console.log(`Row inserted, ID: ${this.lastID}`); } ); }); }); |
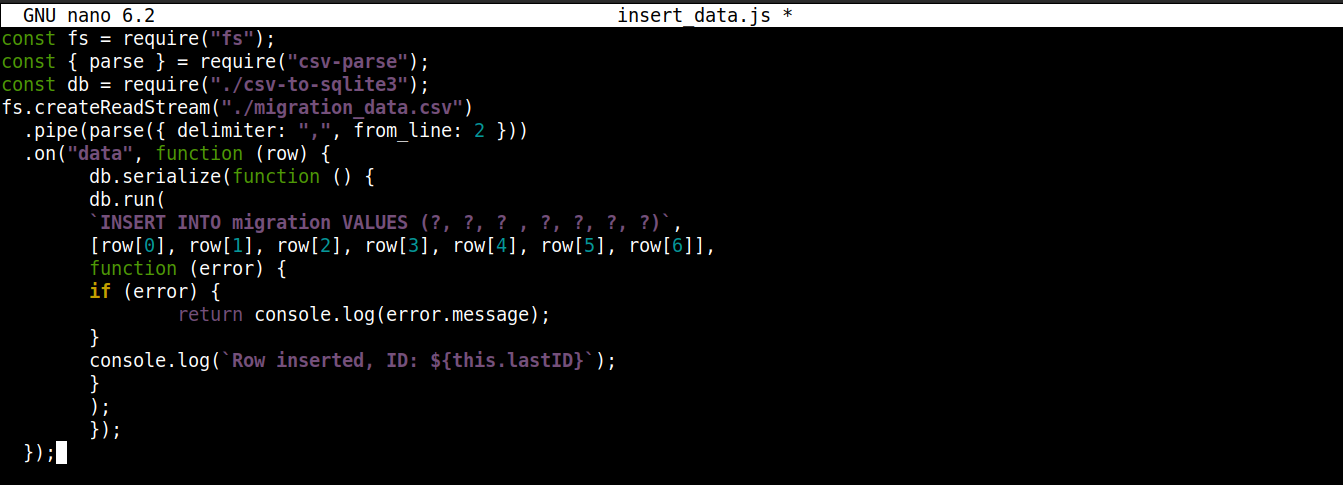
Tutaj,
-
Przechowujemy obiekt połączenia uzyskany z csv-to-sqlite3.js w zmiennej db.
-
Wewnątrz wywołania zwrotnego zdarzenia data (dołączonego do strumienia modułu fs), wywołujemy serialize() metodę na obiekcie połączenia. Zapewnia ona, że jedna instrukcja SQL zakończy wykonywanie przed rozpoczęciem kolejnej, co zapobiega wyścigom w bazie danych (jednoczesnemu uruchamianiu konkurencyjnych operacji przez system).
-
Metoda serialize() przyjmuje trzy argumenty:
-
Pierwszym argumentem jest instrukcja SQL.
-
Drugim argumentem jest tablica.
-
Trzecim argumentem jest wywołanie zwrotne, które jest uruchamiane, gdy dane zostaną pomyślnie lub niepomyślnie wstawione do bazy danych.
-
Jesteśmy gotowi do uruchomienia programu. Uruchom insert_data.js za pomocą Node.js:
|
1 |
node insert_data.js |
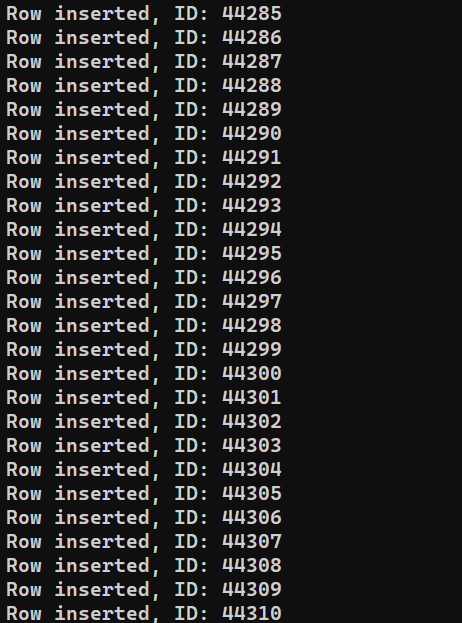
W zależności od wydajności systemu proces może zająć trochę czasu. Jednak po jego zakończeniu dane wyjściowe powinny wyglądać mniej więcej tak:
Krok 5 – Zapisywanie danych do pliku CSV
Po ostatniej sekcji mamy bazę danych zawierającą wszystkie rekordy, które sparsowaliśmy z migration_data.csv. W tej sekcji odczytamy dane z bazy danych i zapiszemy je w osobnym pliku CSV.
Utwórz nowy plik JavaScript, aby zapisać program:
|
1 |
nano write_csv.js |
Najpierw dodaj następujące linie, aby zaimportować fs oraz csv-stringify wraz z obiektem połączenia z bazą danych z csv-to-sqlite3.js:
|
1 2 3 |
const fs = require("fs"); const { stringify } = require("csv-stringify"); const db = require("./csv-to-sqlite3"); |
Następnie dodamy zmienną zawierającą nazwę pliku CSV, do którego będą zapisywane dane, wraz ze strumieniem zapisu:
|
1 2 3 4 5 6 7 8 9 10 11 |
const filename = "saved_from_db.csv"; const writableStream = fs.createWriteStream(filename); const columns = [ "year_month", "month_of_release", "passenger_type", "direction", "sex", "age", "estimate", ]; |
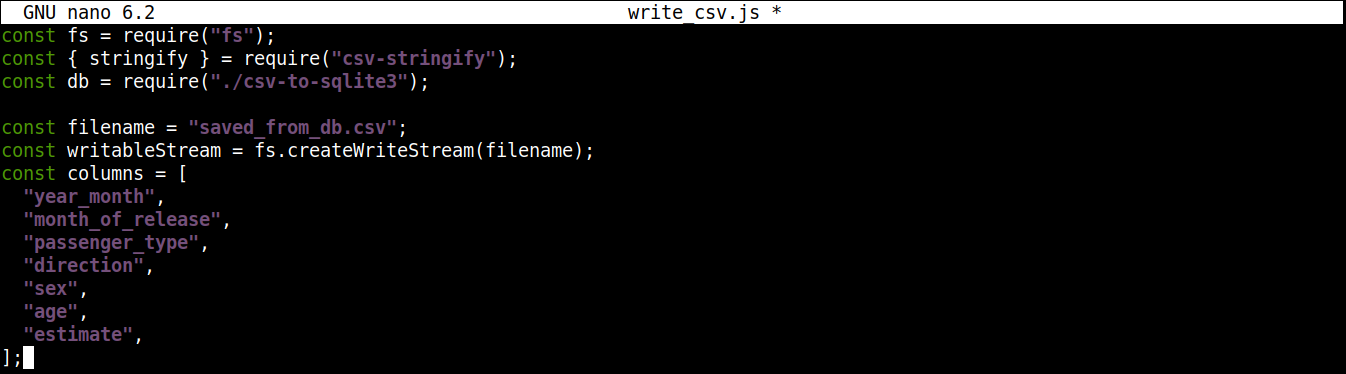
Tutaj,
-
Metoda createWriteStream() przyjmuje jako argument nazwę pliku, do którego ma nastąpić zapis. Nazwiemy ten plik saved_from_db.csv.
-
Zmienna column przechowuje tablicę zawierającą wszystkie nazwy nagłówków dla danych CSV.
Następnie dodaj poniższe linie kodu, aby odczytać dane z bazy danych i zapisać je do saved_from_db.csv:
|
1 2 3 4 5 6 7 8 9 10 11 |
const stringifier = stringify({ header: true, columns: columns }); db.each(`select * from migration`, (error, row) => { if (error) { return console.log(error.message); } stringifier.write(row); }); stringifier.pipe(writableStream); console.log("finished writing to CSV"); |
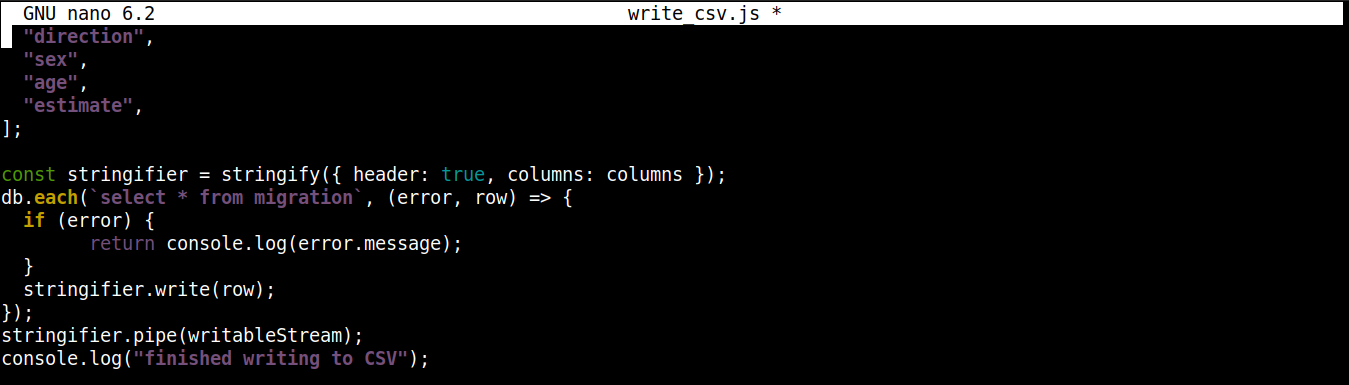
Tutaj,
-
Wywołujemy metodę stringify() z obiektem jako argumentem. Powoduje to powstanie strumienia transformującego (transform stream), który konwertuje dane z obiektu na format CSV. Obiekt przekazany do stringify() ma dwie właściwości:
-
header: Przyjmuje wartość logiczną (Boolean). Jeśli wartość wynosi true, generowany jest nagłówek.
-
columns: Przyjmuje tablicę zawierającą nazwy kolumn, które mają zostać zapisane w pierwszym wierszu pliku CSV, jeśli header wynosi true.
-
-
Metoda each() z obiektu połączenia csv-to-sqlite3 jest wywoływana z dwoma argumentami: instrukcją SQL (odczytującą dane z bazy danych) i funkcją wywołania zwrotnego (obsługującą sukces/błąd).
-
Przy każdej iteracji each(), pipe() (ze strumienia stringifier) zaczyna przesyłać dane partiami do strumienia zapisu writableStream. Każda partia danych jest następnie zapisywana do saved_from_db.csv.
-
Po zapisaniu wszystkich danych do pliku CSV na ekranie konsoli zostanie wyświetlony komunikat o sukcesie.
Ostateczny kod powinien wyglądać następująco:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
const fs = require("fs"); const { stringify } = require("csv-stringify"); const db = require("./csv-to-sqlite3"); const filename = "saved_from_db.csv"; const writableStream = fs.createWriteStream(filename); const columns = [ "year_month", "month_of_release", "passenger_type", "direction", "sex", "age", "estimate", ]; const stringifier = stringify({ header: true, columns: columns }); db.each(`select * from migration`, (error, row) => { if (error) { return console.log(error.message); } stringifier.write(row); }); stringifier.pipe(writableStream); console.log("zakończono zapisywanie do CSV"); |
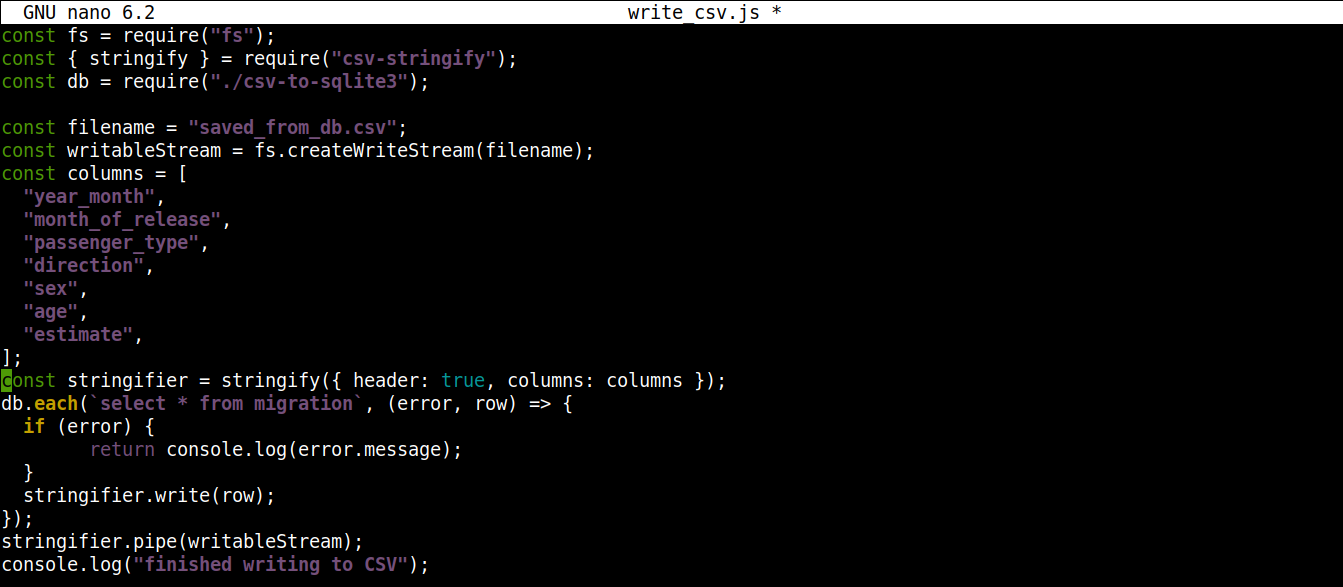
Zapisz plik i zamknij edytor. Możemy teraz uruchomić program za pomocą Node.js:
|
1 |
node write_csv.js |
Aby potwierdzić, czy dane zostały pomyślnie wyeksportowane, sprawdź zawartość saved_from_db.csv:
|
1 |
cat saved_from_db.csv | less |
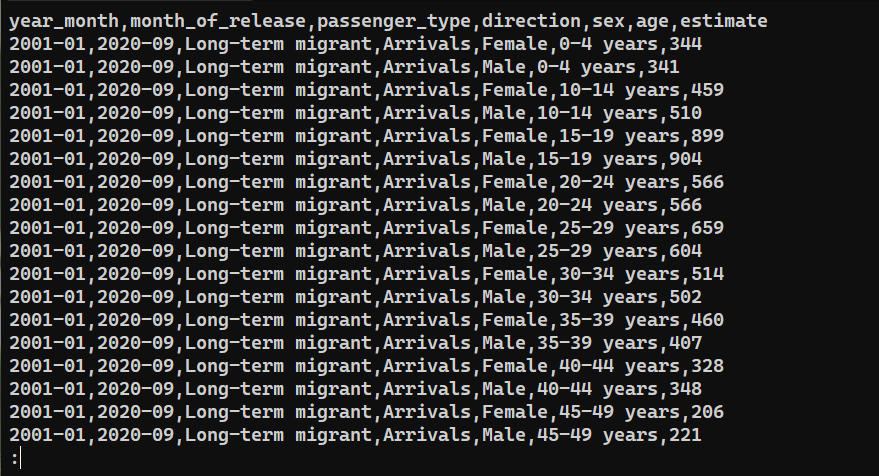
Podsumowanie
W tym poradniku zademonstrowaliśmy pracę z plikami CSV w Node.js przy użyciu modułów node-csv i node-sqlite3. Utworzyliśmy wiele programów do realizacji różnych zadań, na przykład analizowania danych z pliku CSV, wprowadzania danych do bazy danych SQLite oraz zapisywania danych do nowego pliku CSV.
Ten poradnik demonstruje tylko niewielką część możliwości node-csv modułu. Dowiedz się więcej o wszystkich jego funkcjach na stronie CSV Project. Aby dowiedzieć się więcej o node-sqlite3, zapoznaj się z oficjalną dokumentacją w serwisie GitHub. Innym modułem wartym wspomnienia jest event-stream ułatwiający pracę ze strumieniami.
Chcesz dalej rozwijać swój projekt Node.js? Oto kilka poradników dotyczących Node.js, z którymi warto się zapoznać:
-
Jak wdrożyć aplikację Node.js (Express.js) za pomocą Dockera na Ubuntu 20.04
-
Konfiguracja aplikacji Node.js: Jak wykonywać zadania produkcyjne na Ubuntu 20.04 z Node.js
Miłego kodowania!
Komentarze
Brak komentarzy. Bądź pierwszy.