

Firmy generują mnóstwo danych, co utrudnia ich obsługę i zarządzanie nimi. Tradycyjnie branża od dziesięcioleci korzysta z systemów RDBMS, ale wraz z pojawieniem się Big Data w XXI wieku, bazy danych NoSQL (Not only SQL) pojawiły się na rynku z myślą o niestrukturyzowanych i semistrukturyzowanych danych na dużą skalę.
W tym wpisie zamierzam skonfigurować klaster MongoDB.
MongoDB to darmowa i otwartoźródłowa dokumentowa baza danych NoSQL, która jest szeroko stosowana ze względu na wysoki poziom skalowalności i elastyczności, jaki zapewnia.
Aby wdrożyć MongoDB produkcyjnie, zaleca się korzystanie z zestawów replik (Replica Sets). Zestawy replik są odpowiednikiem konfiguracji Master/Slave w świecie relacyjnym dla MongoDB, ale w przeciwieństwie do niej są bardzo bezproblemowe w konfiguracji, ponieważ wszystko jest wbudowane. Więcej informacji na temat zestawów replik można znaleźć w definicji procesu replikacji w TutorialsPoint’s.
Planowanie klastra serwerów chmurowych MongoDB
Zamierzam utworzyć klaster składający się z 3 węzłów. Ważne jest, aby przydzielić im równe zasoby, ponieważ każdy z nich może stać się serwerem głównym (tj. master). Węzły te lub maszyny mogą działać na dowolnym systemie operacyjnym, ale w tym samouczku użyję systemu Ubuntu 18.04 LTS. Informacje o tym, jak podłączyć i skonfigurować preinstalowany obraz z biblioteki CloudSigma’s, można znaleźć w tym samouczku.
Ponieważ głównym celem stosowania zestawu replik (Replica Set) jest to, aby klaster przetrwał awarię pojedynczego węzła, bezcelowe byłoby, gdyby wszystkie serwery znajdowały się na tym samym hoście fizycznym. Na szczęście CloudSigma oferuje rozwiązanie o nazwie grupy dostępności. Oznacza to, że można nakazać systemowi pogrupowanie wszystkich trzech serwerów w różne grupy. Dzięki temu nigdy nie będą one znajdować się na tym samym hoście fizycznym. Więcej informacji na ten temat oraz o innych funkcjach bezpieczeństwa i ciągłości działania można znaleźć tutaj.
Ważne jest również użycie 64-bitowej wersji systemu Linux. Powód jest prosty: MongoDB nie działa dobrze na systemach 32-bitowych (więcej o tym tutaj).
Instalacja MongoDB w chmurze
Ta sekcja jest dość prosta. Możesz użyć jednego ze wstępnie skonfigurowanych obrazów Ubuntu 18.04 lub zainstalować go samodzielnie.
Konfiguracja procesora (CPU), pamięci RAM i dysku jest kwestią bardzo indywidualną i zależy od obciążenia. W przypadku mniejszej instalacji procesor 4 GHz, 4 GB pamięci RAM i dysk 10 GB (na system) powinny być wystarczające. Podczas podłączania dysków upewnij się, że używasz VirtIO. Jeśli użyjesz IDE, wydajność znacznie spadnie. Ponadto, ponieważ tworzysz zestaw replik (Replica Set), wszystkie węzły (i serwery aplikacji) muszą znajdować się w tej samej sieci VLAN.
W przeciwieństwie do wielu innych dostawców chmury, nie ma potrzeby konfigurowania pamięci masowej z RAID10 lub podobnym rozwiązaniem w celu poprawy wydajności. Jak donosi wielu naszych klientów, uzyskasz niesamowitą wydajność od samego początku, korzystając zarówno z dysków SSD, jak i magnetycznych w CloudSigma.
Nadal zalecam przechowywanie danych MongoDB na osobnym dysku. Powodem jest po prostu to, że w pewnym momencie może zajść potrzeba optymalizacji systemu plików, której nie chciałbyś przeprowadzać na całym systemie plików.
Mając to na uwadze, najłatwiej jest po prostu dodać ten dysk po skonfigurowaniu serwerów. Na razie skupmy się na instalacji systemu. Jeśli instalujesz go samodzielnie (zamiast korzystać ze wstępnie skonfigurowanych systemów), zalecam naciśnięcie klawisza F4 w menu rozruchowym i wybranie opcji ‘Zainstaluj minimalną maszynę wirtualną’.
Tworzę 3 maszyny, każda o następującej specyfikacji:
- CPU: 4 GHz
- RAM: 4 GB
- SSD: 10 GB (Ubuntu 18.04 LTS), 20 GB (dodatkowy dysk)
Jak wskazano w sekcji dotyczącej dysków SSD, podłączam dysk o rozmiarze 10 GB z zainstalowanym systemem Ubuntu 18.04 LTS.
Ponadto podłączam do niego kolejny pusty dysk o rozmiarze 20 GB do przechowywania danych MongoDB. Rozmiar ten w dużej mierze zależy od sposobu użytkowania, ale w przypadku małego systemu 20 GB powinno prawdopodobnie wystarczyć. Ponieważ jednak czasami trudno jest przewidzieć, ile danych będziesz przechowywać, użyjemy LVM. Pozwoli to na proste dodanie kolejnego dysku w późniejszym czasie i rozszerzenie wolumenu bez konieczności zaczynania od nowa. Alternatywnie można użyć jednego dysku i zwiększyć jego rozmiar później za pomocąresize2fs.
Aby dodać dysk, przejdź do sekcji ‘Drives’, kliknij ikonę ‘Create a new drive’ na górze, nadaj nowemu dyskowi nazwę i ustaw jego rozmiar na 20 GB. Po zapisaniu przejdź do konkretnej maszyny, do której chcesz go podłączyć, i w sekcji dysków w szczegółach tej maszyny kliknij ‘Attach a drive’ i wybierz ten dysk.
Teraz, gdy masz już trzy maszyny, możesz przejść do montowania dodatkowego dysku dodanego do przechowywania danych MongoDB na każdej maszynie. Zalecam dodanie tego dysku jako partycji. Partycjonowanie pozwala systemowi operacyjnemu na oddzielne zarządzanie informacjami w każdym obszarze. Aby dodać dysk jako partycję, najpierw sprawdzę wszystkie dyski podłączone do naszej maszyny. W tym celu wykonam następujące polecenie:
|
1 |
fdisk -l |
Po wykonaniu tego polecenia otrzymam dane wyjściowe informujące o dyskach i urządzeniach w mojej maszynie.
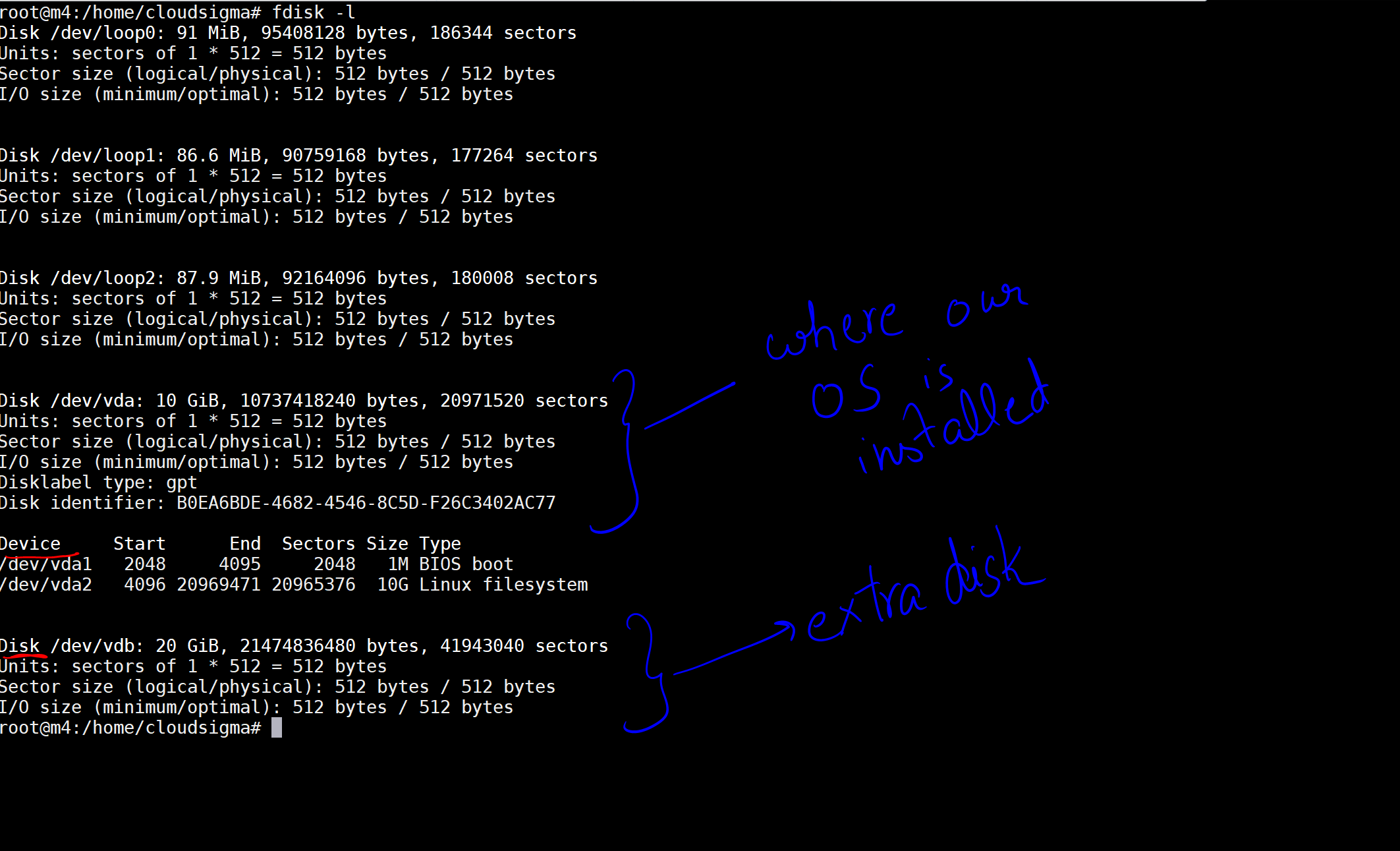
Na obrazku zaznaczyłem dysk 10 GB jako ten, na którym zainstalowany jest nasz system operacyjny. Następnie widoczny jest kolejny dysk o pojemności 20 GB, który został właśnie podłączony. Lokalizacja dysku to /dev/vdb. Możesz utworzyć partycję na tym dysku za pomocą następujących poleceń:
|
1 |
sudo fdisk /dev/vdb |
Otworzy to narzędzie fdisk, czyli narzędzie wiersza poleceń udostępniające funkcje partycjonowania dysku, w którym można tworzyć partycje na naszym dysku. Wyświetli ono monit “Command (m for help):”, w którym należy wpisać n aby utworzyć nową partycję, a następnie po prostu naciskać klawisz Enter, aby zaakceptować wartości domyślne. Po utworzeniu partycji wpisz w aby zapisać zmiany. Będzie to wyglądać następująco:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
Polecenie (m dla pomocy): <strong>n</strong> Typ partycji p główna (0 głównych, 0 rozszerzonych, 4 wolne) e rozszerzona (kontener na partycje logiczne) Wybierz (domyślnie p): Użycie domyślnej odpowiedzi p. Numer partycji (1-4, domyślnie 1): Pierwszy sektor (2048-41943039, domyślnie 2048): Ostatni sektor, +sektory lub +rozmiar{K,M,G,T,P} (2048-41943039, domyślnie 41943039): Utworzono a nową partycję 1 typu type 'Linux' i o rozmiarze 20 GiB. Polecenie (m dla pomocy): <strong>w</strong> Tabela partycji została zmienionabeen altered. Wywoływanie ioctl() w celu-ponownego odczytania tabeli partycji. Synchronizacja dysków. |
Utworzono nową partycję 1 typu ‘Linux’ o rozmiarze 20 GiB. Teraz, gdy partycja została utworzona, utwórzmy pulę LVM:
|
1 2 3 |
sudo pvcreate /dev/vdb1 sudo vgcreate mongodb /dev/vdb1 sudo lvcreate -n db -L 19.5g mongodb |
Wpisałem ‘19.5g’, ponieważ rozmiar mojej partycji to 20g. Następnie wykonaj poniższe polecenie, aby poznać nazwę dysku:
|
1 |
fdisk -l | grep mongo | awk '{print $2'} |
Następnie sformatuj dysk przy użyciu systemu plików ext4 za pomocą następującego polecenia:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
sudo mkfs.ext4 /dev/mapper/mongodb-db Wynik: root@m4:/home/cloudsigma# sudo mkfs.ext4 /dev/mapper/mongodb-db mke2fs 1.44.1 (24-Mar-2018) Tworzenie systemu plików z 5217280 4k blokami i 1305600 i-węzłami System plików UUID: 695a62e6-021d-4fc0-945c-cc51a92d86da Superblok kopie zapasowe przechowywane na blokach: 32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208, 4096000 Alokowanie grup tabel: gotowe Zapisywanie i-węzłów tabel: gotowe Tworzenie kroniki (32768 bloków): gotowe Zapisywanie superbloków i systemu plików rozliczeniowych informacji: gotowe |
Następnie utwórzmy miejsce do zamontowania dysku oraz folder, w którym będą przechowywane dane MongoDB.
|
1 |
sudo mkdir -p /mongodb/data |
Aby dodać wpis do fstab dotyczący nowego dysku, który ma zostać zamontowany, możesz bezpośrednio użyć poniższego polecenia:
|
1 |
echo -e "` blkid | grep mongodb | awk {'print $2'}`\t/mongodb\text4 auto,noexec,rw,sync,nouser\t0\t0" >> /etc/fstab |
W tym poleceniu, blkid zwraca identyfikator UUID – unikalny identyfikator uniwersalny (Universally Unique Identifier) każdego dysku. Tutaj wyodrębniam za pomocą grep ten dla dysku MongoDB i łączę ten UUID odpowiednio z lokalizacją folderu montowania, typem systemu plików i innymi opcjami dla dysku. Dodaję tę linię do /etc/fstab. Jeśli tego nie zrobisz, podczas montowania dysku wystąpi błąd. Wpis wygląda następująco:
UUID=”695a62e6-021d-4fc0-945c-cc51a92d86da” /mongodb ext4 auto,noexec,rw,sync,nouser 0 0
Teraz możesz zamontować dysk w lokalizacji /mongodb:
|
1 |
sudo mount /mongodb |
Instalacja MongoDB
Po przygotowaniu systemu przejdźmy do instalacji MongoDB. Chociaż Ubuntu oferuje wersję MongoDB we własnym repozytorium, zalecam korzystanie z oficjalnej wersji MongoDB. Powodem jest to, że repozytorium Ubuntu jest dość mocno opóźnione pod względem wydań, więc jeśli chcesz w pełni wykorzystać możliwości MongoDB, musisz sięgnąć po oficjalne wydania.
Ponieważ MongoDB oferuje własne repozytorium, możesz po prostu dodać je do swojego systemu, a następnie zainstalować MongoDB w normalny sposób. Oto kroki, które należy wykonać:
Najpierw zaimportuj klucz publiczny używany przez system zarządzania pakietami:
|
1 |
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 9DA31620334BD75D9DCB49F368818C72E52529D4 |
Następnie tworzę plik listy. Będzie on zawierał repozytorium, w którym znajduje się MongoDB, aby Twój system mógł go stamtąd pobrać:
|
1 |
echo "deb [ arch=amd64 ] https://repo.mongodb.org/apt/ubuntu bionic/mongodb-org/4.0 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-4.0.list |
Teraz aktualizuję lokalną bazę danych pakietów, aby uwzględnić zmiany.
|
1 |
sudo apt-get update |
Teraz mogę po prostu zainstalować pakiet za pomocą następującego polecenia:
|
1 |
sudo apt-get install -y mongodb-org |
Zainstalowałem MongoDB na każdej z maszyn.
|
1 |
sudo service mongod start |
Teraz MongoDB działa, a dane na utworzonym dysku są gotowe. Jeśli spodziewane jest duże obciążenie i/lub duża liczba połączeń, może być konieczne zwiększenie wartości ulimit.
Jeśli chcesz uzyskać lepszy wgląd w swoje dane, możesz również zarejestrować się w usłudze MongoDB MMS, która jest bezpłatną usługą monitorowania w chmurze dla MongoDB.
Tworzenie zestawu replik (Replica Set) dla chmury MongoDB
Teraz utwórzmy zestaw replik. Wcześniej musisz upewnić się, że każda z maszyn może komunikować się z pozostałymi. W tym celu dodaj te wpisy w /etc/hosts
|
1 2 3 |
IP-1 m1.mongo.cluster m1 IP-2 m2.mongo.cluster m2 IP-3 m3.mongo.cluster m3 |
W celu weryfikacji możesz spróbować spingować maszyny za pomocą nazwy hosta. Jeśli więc IP mojej maszyny 1 to IP-1, powiedzmy 213.189.123.12, to zamiast pisać
|
1 |
ping 123.189.123.12 |
napiszę,
|
1 2 3 |
ping m1.mongo.cluster lub ping m1. |
Jeśli aktywowałeś zaporę sieciową (co naprawdę powinieneś zrobić), upewnij się, że węzły mogą wysyłać i odbierać ruch TCP na portach 28017 i 27017 na interfejsie wewnętrznym.
Teraz na każdej z maszyn uruchom usługę mongod za pomocą następujących poleceń.
Na maszynie m1,
|
1 |
mongod --dbpath /mongodb/data --replSet rs0 --bind_ip localhost,m1.mongo.cluster |
Następnie na maszynie m2,
|
1 |
mongod --dbpath /mongodb/data --replSet rs0 --bind_ip localhost,m2.mongo.cluster |
Na maszynie m3,
|
1 |
mongod --dbpath /mongodb/data --replSet rs0 --bind_ip localhost,m3.mongo.cluster |
Tutaj,
mongod to nazwa usługi
dbpath to lokalizacja katalogu naszej bazy danych
replSet to nazwa naszej grupy replikacji. Powinna być taka sama dla każdej z maszyn w tej samej grupie replikacji
bind_ip to nazwa hosta maszyny, na której go uruchamiasz.
Po uruchomieniu usługi mongod przejdź do serwera głównego (w moim przypadku wybrałem m1) i uruchom mongo.
|
1 |
mongo |
Uruchomi to terminal MongoDB. W terminalu zainicjuj replicaSet za pomocą poniższego polecenia. Utworzy to replicaSet z domyślną konfiguracją:
|
1 |
rs.initiate() |
Teraz dodajmy pozostałe dwie maszyny jako repliki za pomocą następujących poleceń:
|
1 2 |
rs.add("m2.mongo.cluster") rs.add("m3.mongo.cluster") |
Możesz monitorować status za pomocą polecenia:
|
1 |
rs.status() |
To naprawdę wszystko. Twój klaster MongoDB powinien już działać w błyskawicznie szybkiej chmurze CloudSigma.
Komentarze
Brak komentarzy. Bądź pierwszy.